RAG + Semantisches Markup
Andere Sprachen: English Español Français 日本語 한국어 Português 中文
Die Bedeutung von Dokumentation unterscheidet sich zwischen Softwareprojekten, aber selbst die wichtigste Dokumentation spielt eine inhaerent unterstuetzende Rolle. Sie ist nichts, worauf sich ein Programm verlaesst, um korrekt zu funktionieren. Selbst wenn Dokumentation Daten mit dem Programm teilt, bleibt die Verbindung unidirektional. Benutzerorientierte Dokumentation spiegelt das Produkt wider und aendert nicht die Art, wie das Produkt funktioniert.
Der Hauptgrund dafuer ist rein technologischer Natur. Wir koennten neue Funktionen und Fehlerbehebungen implementieren, indem wir einfach Dokumentation schreiben - wenn Anweisungen in natuerlicher Sprache spezifisch genug sein koennten und Computer ausgezeichnet darin waeren, sie zu interpretieren. Klingt vertraut, oder?
Waehrend die Debatte darueber fortgesetzt wird, ob das vollstaendige Programmieren in natuerlicher Sprache moeglich sein wird, geht es bei dieser potenziellen Veraenderung eigentlich um die Zugaenglichkeit der Softwareentwicklung, anstatt eine neuartige Art einzufuehren, wie Programme arbeiten. Letztendlich wuerden wir immer noch dieselben Binaerdateien erhalten, jetzt mit einem zusaetzlichen, zugegebenermassen bemerkenswerten, Compiler involviert.
Kann KI Funktionen auf eine andere Weise antreiben? Heute moechte ich eine der neuesten KI-getriebenen Funktionen in JetBrains IDEs behandeln, die die Verarbeitung natuerlicher Sprache direkt nutzt und einen Grossteil unserer Dokumentation in ein aeusserst nuetzliches Entwicklungs-Asset verwandelt.

Aktionssuche
Ab Version 2024.3 hat AI Assistant in JetBrains IDEs Zugriff auf IDE-Aktionen und hilft dir, die richtige Aktion fuer das vorliegende Problem zu finden. Zusaetzlich kann es diese Aktion fuer dich ausfuehren:

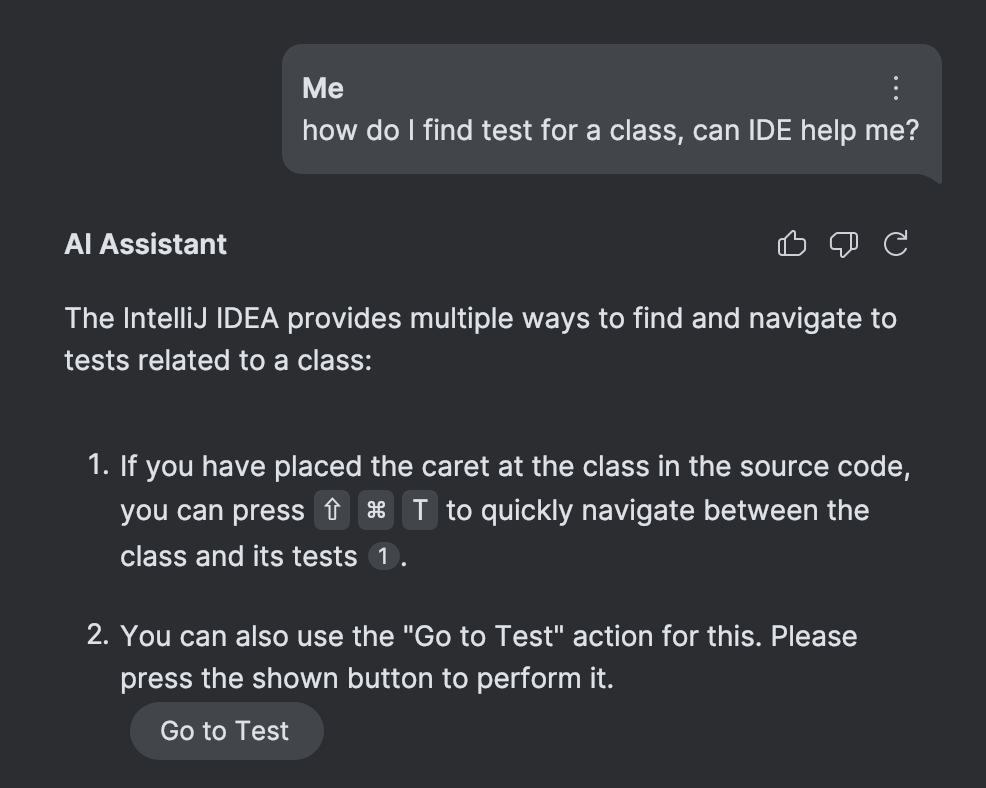
Wie bereits erwaehnt, wird diese Funktion durch Dokumentation angetrieben. Waehrend guter alter Code sicherlich eine Rolle spielt, basiert die Auswahl der richtigen Aktion ausschliesslich auf einer fortgeschrittenen Form von RAG (Retrieval-Augmented Generation)
- ohne die Notwendigkeit fuer zahlreiche LLM-Funktionen oder spezielle Zuordnungen.
Bevor wir zu den Details uebergehen, lassen wir kurz das Konzept von RAG Revue passieren.
RAG
Retrieval-Augmented Generation (RAG) ist eine Technik, die haeufig verwendet wird, um die Praezision und Fundierung von LLM-Antworten zu verbessern. Sie ist besonders effektiv, wenn LLMs Antworten zu Themen geben muessen, die ueber ihre Trainingsdaten hinausgehen, und zu Fakten, die sich haeufig aendern, was Fine-Tuning unpraktisch macht.
In ihrer gaengigsten Form besteht die Technik darin, einen Index ueber der Dokumentation zu pflegen. In diesem Index spiegelt der Schluessel die Bedeutung eines Dokumentelements wider, dargestellt durch Embeddings, und der Wert entspricht dem Inhalt des Elements oder einer Referenz auf das Element selbst. Dank der numerischen Darstellung der Schluessel koennen die entsprechenden Elemente semantisch verglichen und abgerufen werden mit Methoden wie Kosinusaehnlichkeit oder k-naechste Nachbarn (KNN).
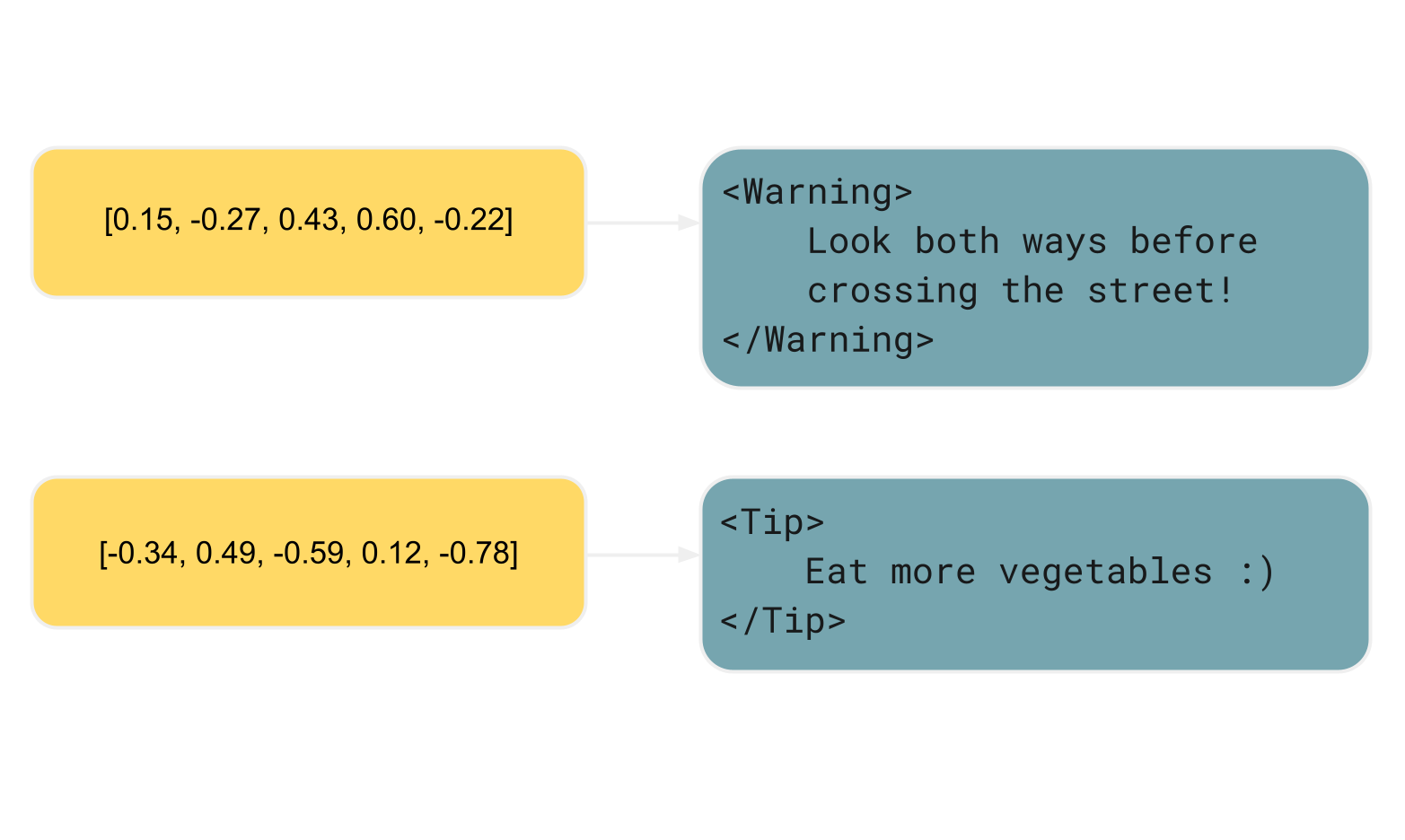
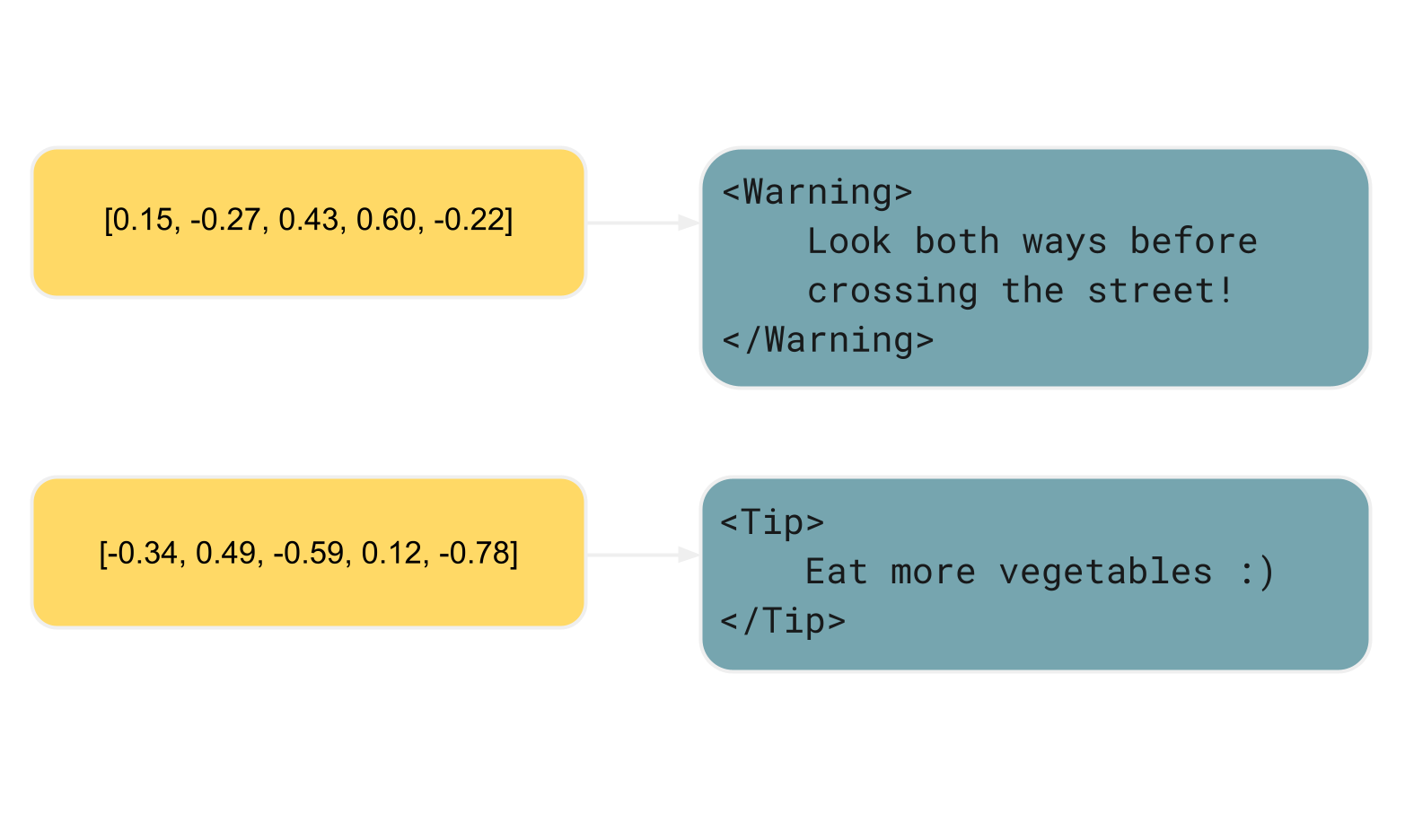
Folgendes passiert, wenn du in einem RAG-unterstuetzten KI-Chat etwas fragst:
How do I change font size?Das System durchsucht zuerst den Index, und wenn das erfolgreich ist, fuegt es die Ergebnisse dem Prompt hinzu. Zum Beispiel:
How do I change font size?
Here's supplementary information that might help you answer the question:
-> the search results are inserted here <-Mit diesem Ansatz kann die richtige Antwort wahrscheinlich aus den bereitgestellten ergaenzenden Informationen abgeleitet werden, was zu einer fundierteren und genaueren Antwort des LLM fuehrt. Aus der Perspektive des Endbenutzers mag es so erscheinen, als ob das Modell intelligenter geworden waere, waehrend das Modell in Wirklichkeit unveraendert bleibt - der einzige Unterschied liegt im Prompt.
Schauen wir uns nun an, wie wir diesen Ansatz verbessern koennen.
Semantisches Markup
Wenn du technische Dokumentation schreibst, bist du wahrscheinlich mit dem Konzept des semantischen Markups vertraut:
Mit semantischem Markup gibst du die “Bedeutung” hinter jedem Element an
Zum Beispiel ist Markdown nicht semantisch. In Markdown arbeitest du mit gaengigen Dokumentelementen wie Ueberschriften, Absaetzen, Listen und so weiter, neben einigen typografischen Eigenschaften. Diese Syntax skizziert eine uebergeordnete Struktur und sagt dem Prozessor, wie das Dokument gerendert werden soll. Was sie nicht sagt, ist der Zweck oder die Bedeutung verschiedener Elemente innerhalb des Dokuments.
Hier ist ein kurzes Beispiel. Die Sternchen zeigen dem Prozessor an, dass er den Satz kursiv setzen soll, aehnlich
wie <i> in HTML:
*Look both ways before crossing the street!*Im Gegensatz dazu hat MDX, eine Obermenge von Markdown, semantische Eigenschaften. MDX ermoeglicht es dir, benutzerdefinierte Elemente zu definieren, die oft fuer UI-Komponenten stehen und den beabsichtigten Zweck des Inhalts kommunizieren koennen:
<Warning>
Look both ways before crossing the street!
</Warning>Im Unterschied zu reinem Markdown abstrahiert dieses spezifische MDX-Beispiel den visuellen Aspekt und konzentriert sich stattdessen auf den
Zweck des Inhalts.
Als Dokumentationsautoren sind wir weniger besorgt darueber, ob <Warning>
Kursivschrift verwenden oder anderweitig aus dem regulaeren Text hervorstechen sollte.
Sein Stil ist an einem separaten Ort definiert, wie innerhalb der Komponente selbst oder in einem CSS-Stylesheet.
Eine solche Trennung der Belange
macht die Codebasis leichter wartbar und ermoeglicht es dir, das Styling zentralisiert
basierend auf der Bedeutung des Inhalts zu aendern.
Eine perfekte Uebereinstimmung?
Bei JetBrains erstellen wir unsere Dokumentation mit Writerside. Dieses Tool unterstuetzt sowohl Markdown als auch semantisches XML als Quellformate fuer Dokumentation. Das Beispiel unten zeigt eine typische Dokumentstruktur, geschrieben in Writersides semantischem XML:
<chapter title="Testing" id="testing">
... some content ...
<procedure title="Navigate to tests" type="choices">
<p>
When at a symbol declaration, you can navigate to the corresponding
tests by doing one of the following:
</p>
<step>
From the main menu, select <ui-path>Navigate | Test</ui-path>.
</step>
<step>
Press <shortcut key="GotoTest"/>.
</step>
</procedure>
... more content ...
</chapter>Dir wird auffallen, dass es einige Meta-Informationen im bereitgestellten Snippet gibt. Diese sind bereits wertvoll aus den oben genannten Gruenden, aber nichts hindert uns daran, sie zusaetzlich zu nutzen.
Betrachte das <shortcut> -Tag,
das eine plattformabhaengige Tastenkombination darstellt.
Dieses Tag ist Teil einer Indirektionsschicht, die es ermoeglicht,
Tastenkuerzel-Erwaehungen zentralisiert zu verwalten und zu validieren.
Um ein Tastenkuerzel innerhalb eines Dokuments einzufuegen, verwendest du das <shortcut> -Tag
zusammen mit der entsprechenden Aktions-ID so: <shortcut key="CoolAction"> .
Waehrend des Build-Prozesses validiert und transformiert das Tool die <shortcut> -Elemente
in die tatsaechlichen Tastenkombinationen fuer die verfuegbaren Tastaturbelegungen.
Dieser Ansatz synchronisiert die Tastenkuerzel zwischen Dokumentation und Produkt und gibt den Dokumentationsbenutzern die Flexibilitaet, ihre bevorzugte Tastaturbelegung zu waehlen. Um dies in Aktion zu sehen, besuche IntelliJ IDEA Hilfe und beachte, wie sich die Tastenkuerzel im Text aendern, abhaengig von der ausgewaehlten Tastaturbelegung im Shortcuts-Menue:
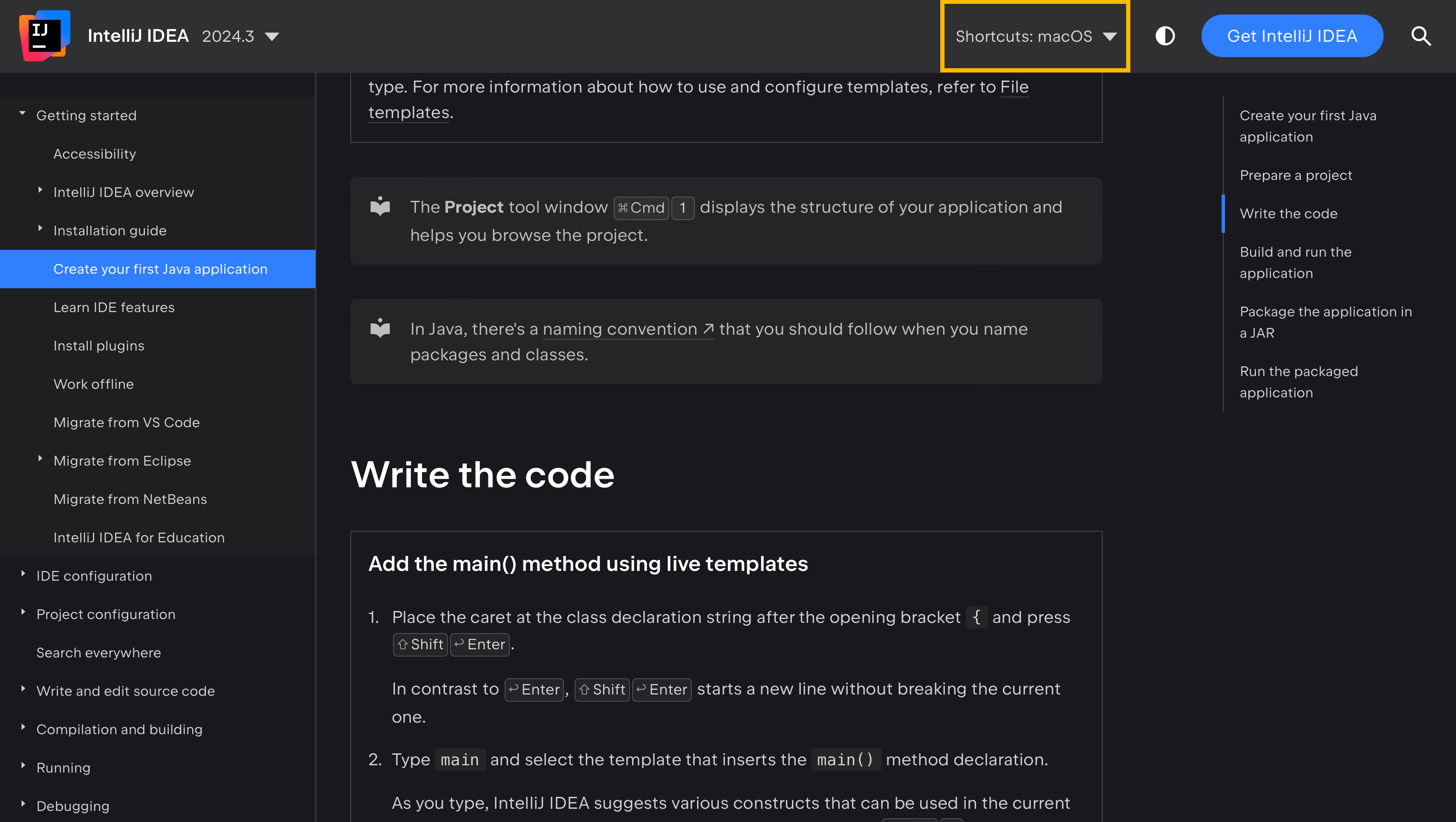
Das ist der primaere Zweck des <shortcut> -Tags.
Wie kann dieses Tag in Bezug auf die Verbesserung von RAG nuetzlich sein?
Die naheliegendste Verwendung ist die Anzeige plattformspezifischer Tastenkuerzel im KI-Chat, aehnlich wie auf der Hilfeseite:

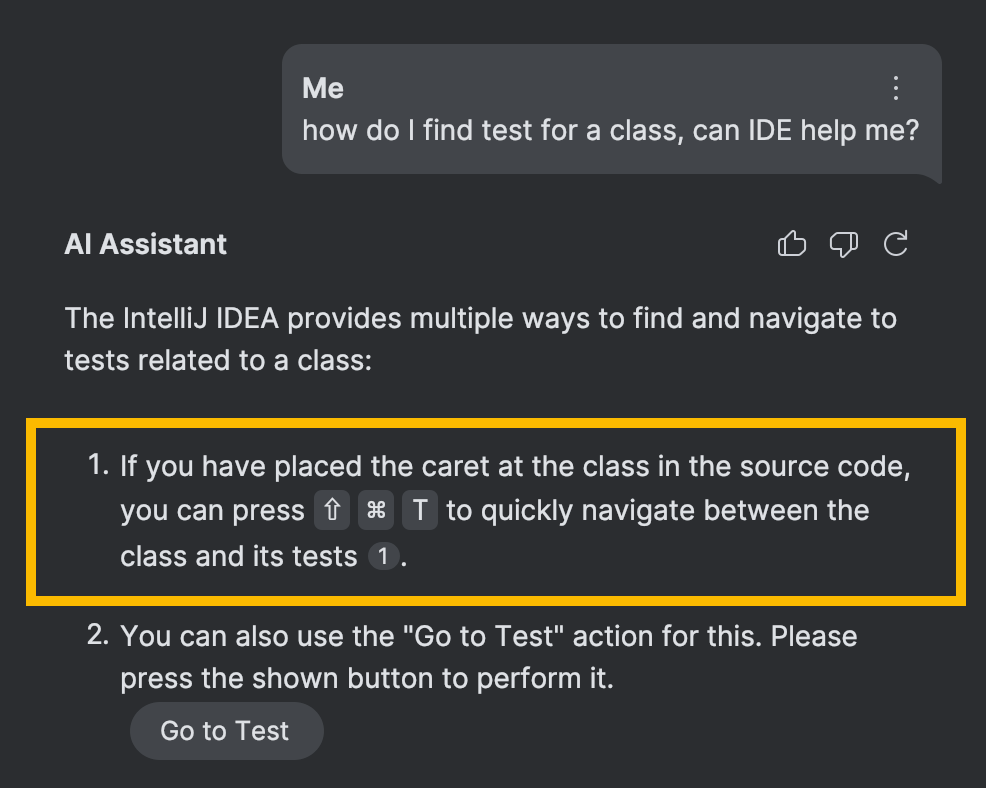
Es gibt jedoch einen interessanteren Teil. Aehnlich wie beim Aufbau von Indizes zum Abrufen von Fakten und Anweisungen ist es moeglich, Indizes zu erstellen, die das Nachschlagen von Aktions-IDs ermoeglichen.
Im einfacheren RAG-Szenario, das zuvor besprochen wurde, haben wir die Embeddings aus demselben Element generiert, das zum Abrufen vorgesehen ist. Fuer den Aktions-ID-Index verwenden wir jedoch die folgende Struktur:
- Die Schluessel sind die Embeddings, die aus den Elementen abgeleitet werden, die ein
<shortcut>-Tag umschliessen - Die Werte sind die Aktions-IDs innerhalb des entsprechenden
<shortcut>-Tags
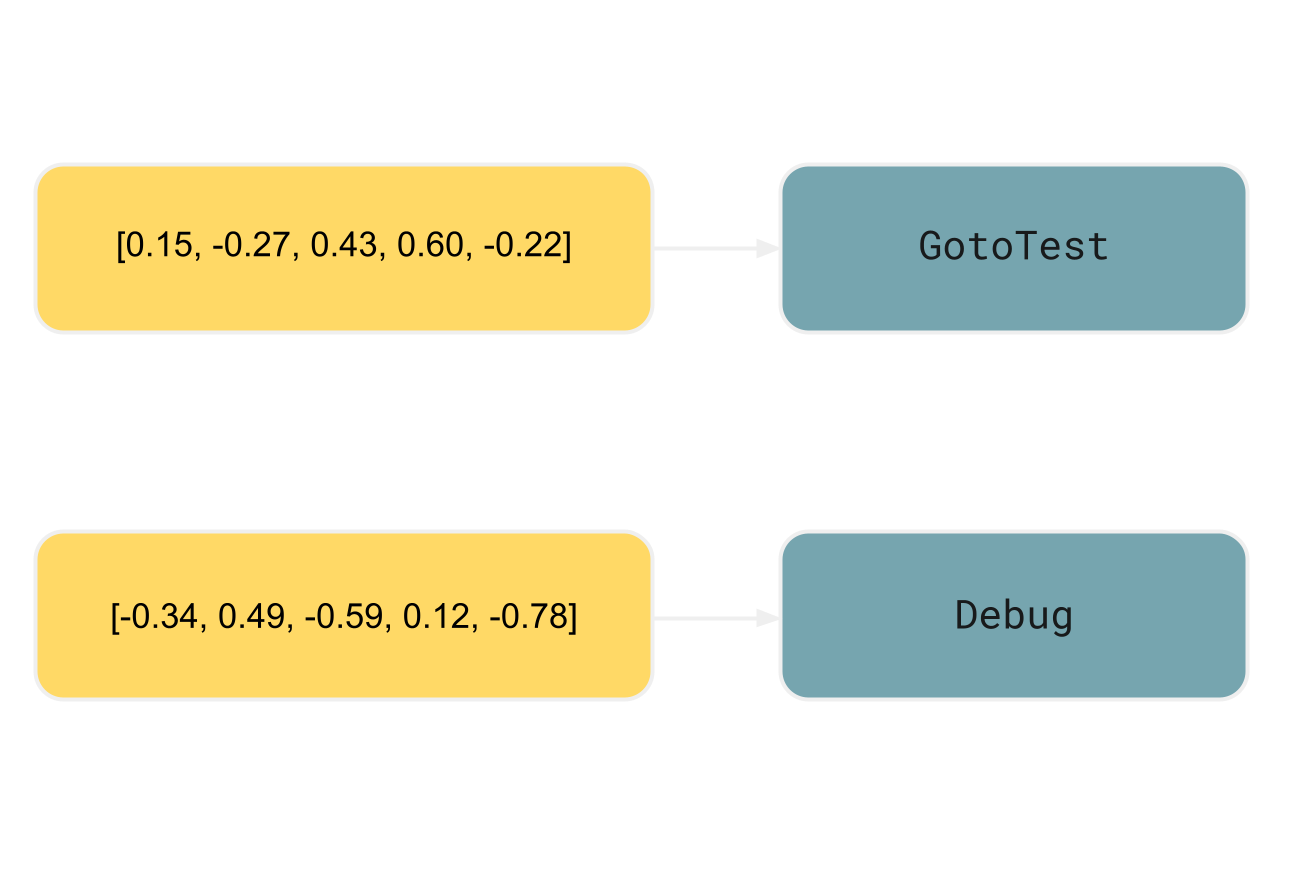
Im Beispiel waere das umschliessende Element
fuer <shortcut key="GotoTest"/>
<step>
oder sogar die gesamte <procedure> :
<procedure title="Navigate to tests" type="choices">
<p>
When at a symbol declaration, you can navigate to the corresponding
tests by doing one of the following:
</p>
<step>
From the main menu, select <ui-path>Navigate | Test</ui-path>.
</step>
<step>
Press <shortcut key="GotoTest"/>.
</step>
</procedure>Kontext ist wichtig
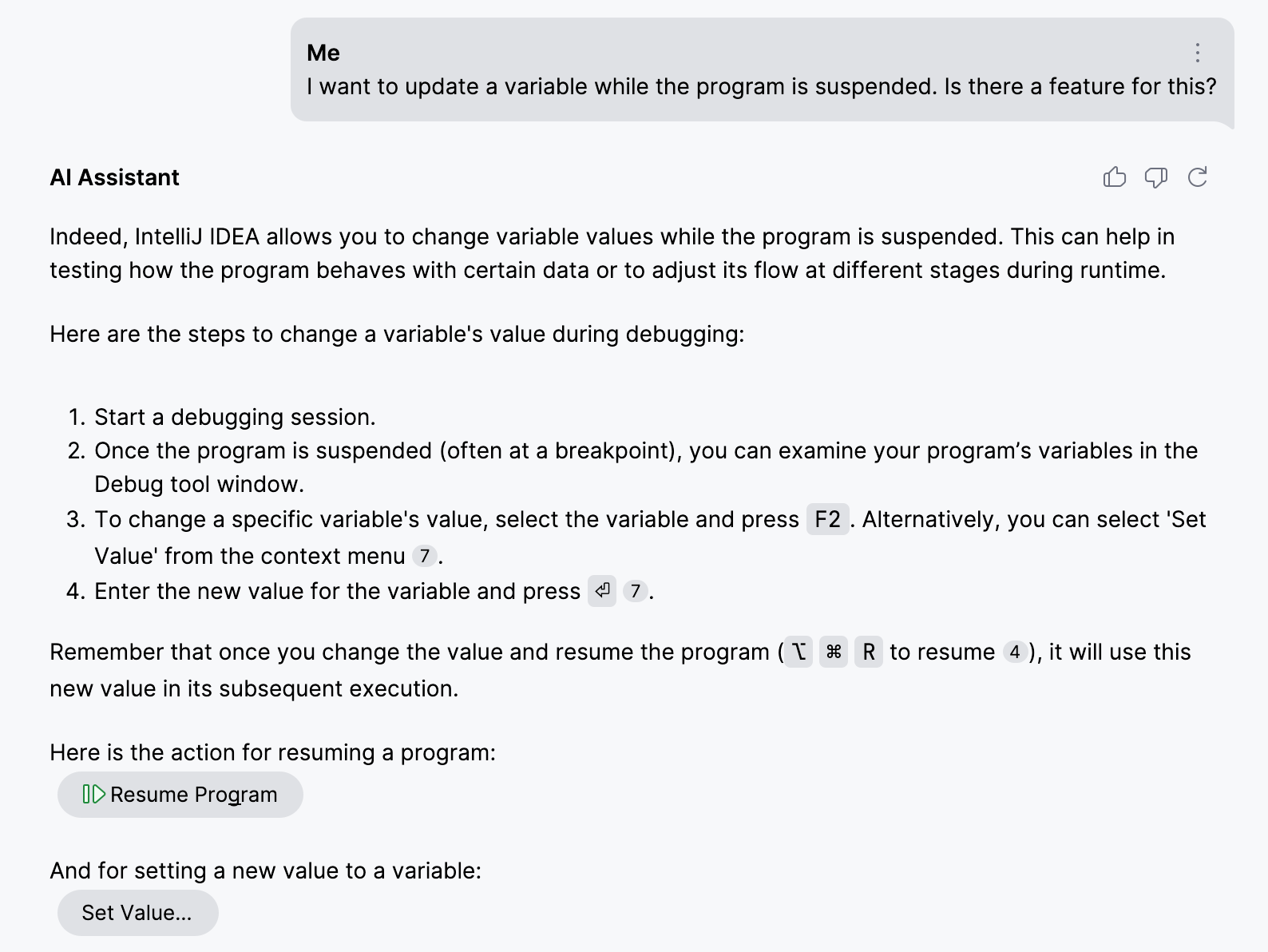
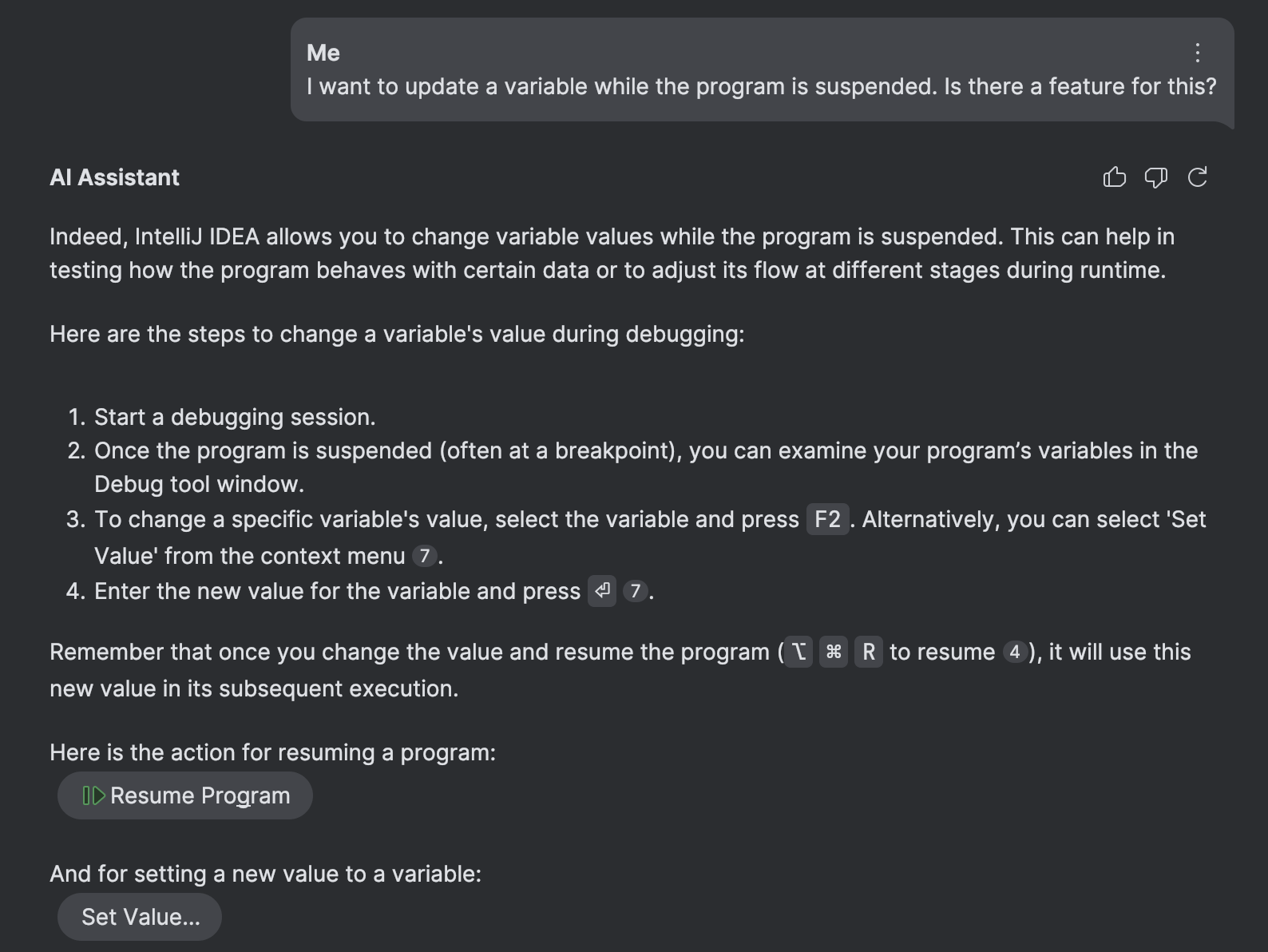
Um die Wichtigkeit der Indexierung des Inhalts des umschliessenden Elements zu demonstrieren, verwenden wir IntelliJ IDEAs Set Value-Funktion als Beispiel. Diese Funktion ermoeglicht es dir, Variablen zu aktualisieren, waehrend das Programm im Debug-Modus angehalten ist.
Die ID fuer die entsprechende Aktion ist SetValue .
Diese ID allein ist jedoch nicht besonders beschreibend.
Da SetValue und viele andere IDs ziemlich generische Wortkombinationen in der Programmierung sind,
wuerde eine semantische Suche, die ausschliesslich auf diesen IDs basiert, zu einem
inakzeptablen Anteil sowohl an falsch positiven als auch an falsch negativen Ergebnissen fuehren.
Ohne zusaetzlichen Kontext im Index
wird die Aufgabe praktisch unmoeglich.
Im Gegensatz dazu stellen wir durch die Herstellung der Beziehung zwischen der Aktions-ID und dem umgebenden Inhalt dem AI Assistant Details ueber die genaue Funktionalitaet, ihre gaengigen Anwendungsfaelle und Einschraenkungen bereit. Diese Informationen erhoehen die Genauigkeit des Abrufs erheblich:
Der Client-Teil
Sobald AI Assistant die richtige Aktions-ID hat, kann es diese Aktion vorschlagen und sogar eine Schaltflaeche anzeigen, um sie direkt aus dem Chat aufzurufen:

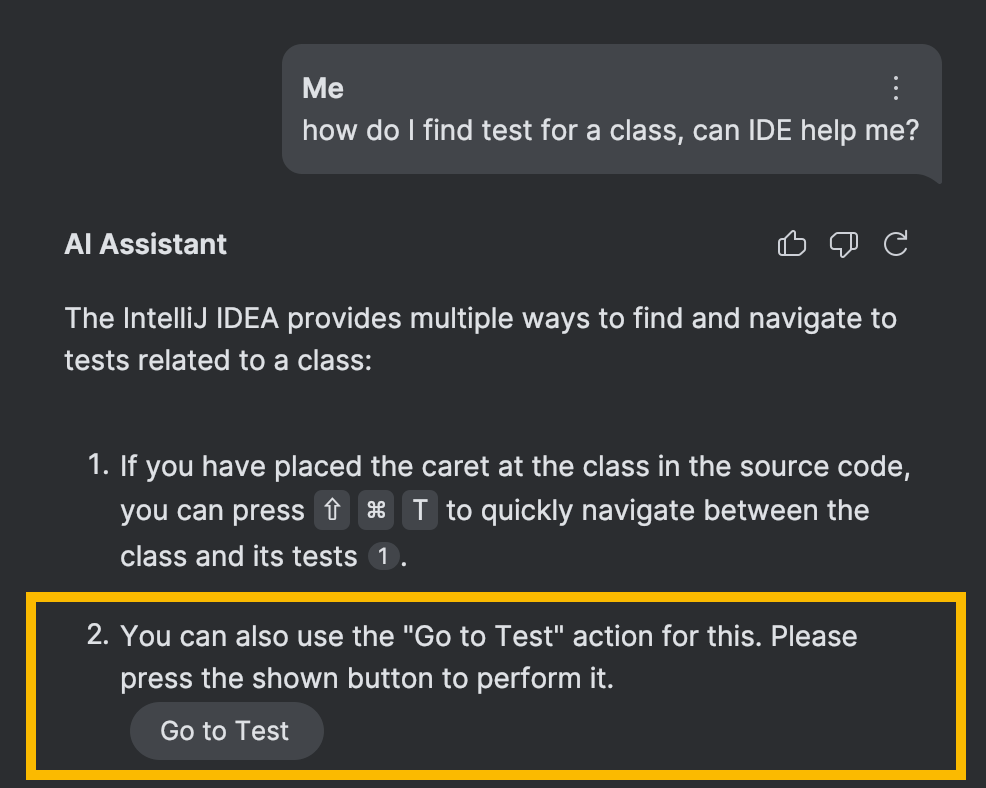
Natuerlich ist dieser Teil etwas komplexer als einfach eine Schaltflaeche zur Benutzeroberflaeche hinzuzufuegen. Da IDE-Aktionen kontextabhaengig sind, muessen zusaetzliche Pruefungen implementiert werden, aber dieses Thema ist sehr spezifisch fuer die Entwicklung der IntelliJ Platform und verdient eine eigene separate Diskussion.
Andere Markup-Elemente
In diesem Beitrag haben wir uns hauptsaechlich auf die ‘Aktionssuche’-Funktion konzentriert, die durch das Abrufen von
Aktions-IDs aus Writersides <shortcut> -Tag funktioniert.
Du kannst jedoch dieselben Prinzipien auf viele andere Elementtypen innerhalb des semantischen Markups anwenden.
Nur ein kurzes Beispiel mit dem ui-path-Element. Dieses Element bezeichnet Reihen von UI-Elementen, wie Menuepunkte, durch die man navigieren muss, um auf die beschriebene Funktionalitaet zuzugreifen.
<step>
Open the IDE settings (<shortcut key="ShowSettings"/>),
then navigate to <ui-path>Tools | Terminal</ui-path>.
</step>Es macht durchaus Sinn, lange Pfade in der Web-Hilfe anzugeben, weil direkte Navigation von einer Webseite zum Produkt typischerweise nicht praktisch ist. Andererseits, wenn ein Benutzer darueber im Produkt fragt, gibt es keinen Grund, die entsprechende Einstellungsseite nicht sofort anzuzeigen:


Zusammenfassung
Vor einiger Zeit hatten viele das Konzept von Web 3.0 vor Augen. Die Idee war, das gesamte Web auf semantisches Markup umzustellen, damit Maschinen es genauso nutzen koennten wie Menschen. Obwohl dies nicht passierte, ist es interessant, wie dieselben Ideen wieder relevant werden, jetzt aus der Perspektive moderner Tools und Techniken.
Die Funktion, die ich in diesem Artikel behandelt habe, ist nur ein Beispiel dafuer, wie du deine bestehenden guten Praktiken, wie semantisches Markup, mit Gen-KI-Systemen nutzen kannst. Es gibt viele weitere zu erkunden. Wenn du besonders an RAG interessiert bist, hier ist eine ausgezeichnete Sammlung von Tutorials zur Retrieval-Augmented Generation.
Hat dir der Artikel gefallen? Experimentierst du gerne mit Gen-KI? Obwohl mein Blog keinen Kommentarbereich hat, wuerde ich mich trotzdem freuen, von deiner Perspektive und deinen Anwendungsfaellen zu hoeren, also zoegere nicht, mich ueber die Kontakte in der Fusszeile zu erreichen.
Bis bald!