Quellcode, Bytecode, Debugging
Andere Sprachen: English Español Français 日本語 한국어 Português 中文
Beim Debuggen von Java-Programmen haben Entwickler oft den Eindruck, dass sie direkt mit dem Quellcode interagieren. Das ist nicht überraschend – Javas Werkzeuge machen einen so ausgezeichneten Job darin, die Komplexität zu verbergen, dass es fast so wirkt, als existiere der Quellcode zur Laufzeit.
Wenn du gerade mit Java anfängst, erinnerst du dich wahrscheinlich an diese Diagramme, die zeigen, wie der Compiler Quellcode in Bytecode transformiert, der dann von der JVM ausgeführt wird. Du fragst dich vielleicht auch: Wenn das so ist, warum untersuchen und durchschreiten wir den Quellcode und nicht den Bytecode? Woher weiß die JVM etwas über unseren Quellcode?
Dieser Artikel unterscheidet sich ein wenig von meinen früheren Beiträgen zum Debugging. Anstatt mich darauf zu konzentrieren, wie man ein bestimmtes Problem debuggt, wie eine nicht reagierende App oder ein Speicherleck, erkundet er, wie Java und Debugger hinter den Kulissen funktionieren. Bleib dran – wie immer sind ein paar nützliche Tricks enthalten.

Bytecode
Beginnen wir mit einer kurzen Wiederholung. Die Diagramme, die in Java-Büchern und Leitfäden zu finden sind, sind tatsächlich korrekt – die JVM führt Bytecode aus.
Betrachte die folgende Klasse als Beispiel:
package dev.flounder;
public class Calculator {
int sum(int a, int b) {
return a + b;
}
}Beim Kompilieren wird die sum()-Methode in folgenden Bytecode umgewandelt:
int sum(int, int);
descriptor: (II)I
flags: (0x0000)
Code:
stack=2, locals=3, args_size=3
0: iload_1
1: iload_2
2: iadd
3: ireturn
Du kannst den Bytecode deiner Klassen mit dem javap -v-Befehl untersuchen,
der im JDK enthalten ist. Wenn du IntelliJ IDEA verwendest, kannst du dies auch aus der IDE tun:
Nach dem Erstellen deines Projekts wählst du eine Klasse aus und klickst dann auf
View | Show Bytecode.

Da Class-Dateien binär sind, wäre es nicht informativ, ihren Rohinhalt zu zitieren.
Für die Lesbarkeit folgen die Beispiele in diesem Artikel dem Format der javap -v-Ausgabe.
Bytecode besteht aus einer Reihe kompakter plattformunabhängiger Anweisungen. Im obigen Beispiel:
iload_1undiload_2laden die Variablen auf den Operandenstapeliaddaddiert den Inhalt des Operandenstapels und hinterlässt einen einzelnen Ergebniswert daraufireturngibt den Wert vom Operandenstapel zurück
Zusätzlich zu den Anweisungen enthalten Bytecode-Dateien auch Informationen über die Konstanten, die Anzahl der Parameter, lokale Variablen und die Tiefe des Operandenstapels. Das ist alles, was die JVM benötigt, um ein Programm auszuführen, das in einer JVM-Sprache wie Java, Kotlin oder Scala geschrieben wurde.
Debug-Informationen
Da Bytecode völlig anders aussieht als dein Quellcode, wäre es ineffizient, ihn beim Debuggen zu referenzieren. Aus diesem Grund zeigen die Oberflächen von Java-Debuggern – wie JDB (der mit dem JDK gelieferte Konsolen-Debugger) oder der in IntelliJ IDEA – den Quellcode anstelle von Bytecode. Dies ermöglicht es dir, den Code zu debuggen, den du geschrieben hast, ohne an den zugrunde liegenden ausgeführten Bytecode denken zu müssen.
Zum Beispiel könnte deine Interaktion mit JDB so aussehen:
Initializing jdb ...
> stop at dev.flounder.Calculator:5
Deferring breakpoint dev.flounder.Calculator:5.
It will be set after the class is loaded.
> run
run dev/flounder/Main
Set uncaught java.lang.Throwable
Set deferred uncaught java.lang.Throwable
VM Started: Set deferred breakpoint dev.flounder.Calculator:5
Breakpoint hit: "thread=main", dev.flounder.Calculator.sum(), line=5 bci=0
> locals
Method arguments:
a = 1
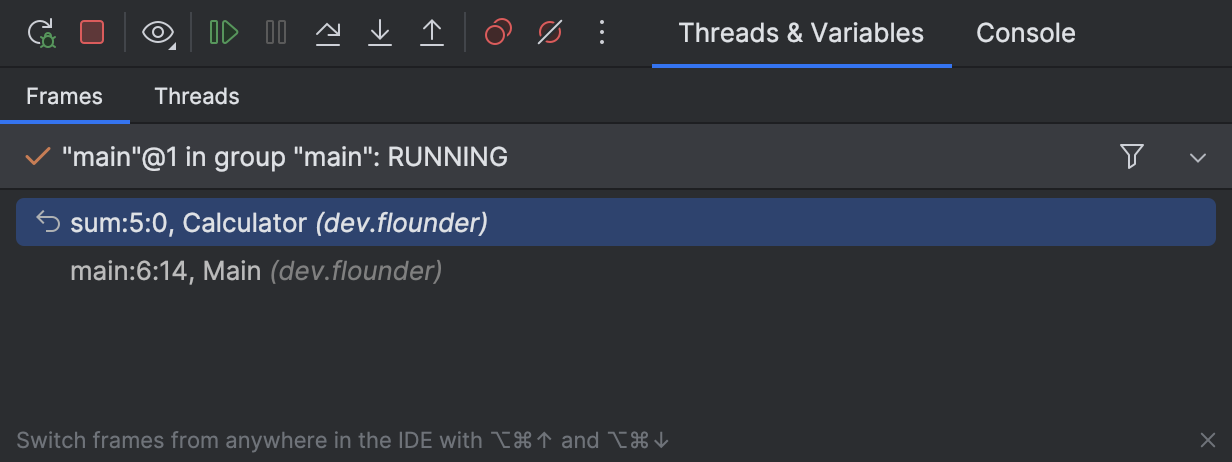
b = 2IntelliJ IDEA zeigt die Debug-relevanten Informationen im Editor und im Debug Tool-Fenster an:
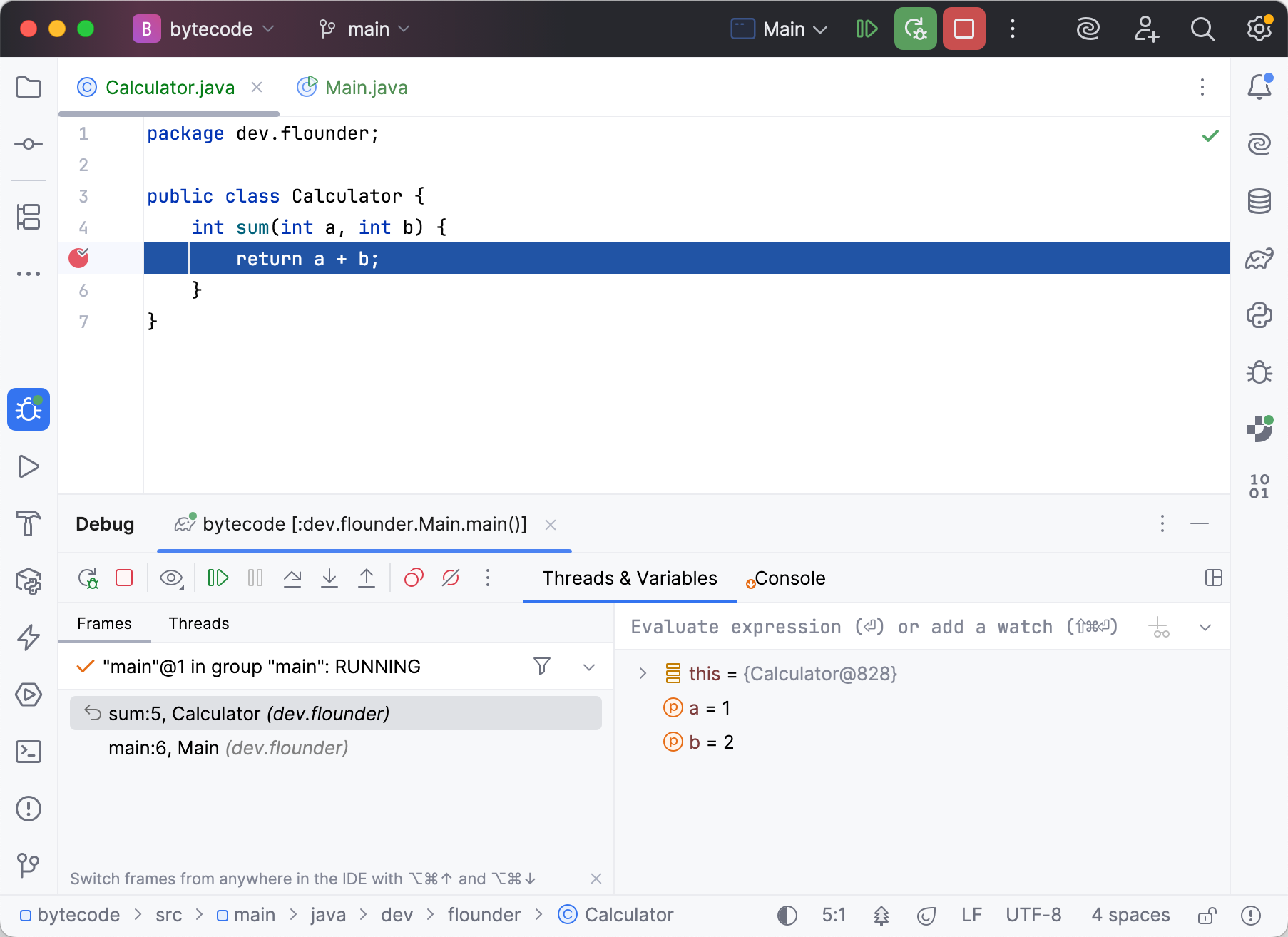
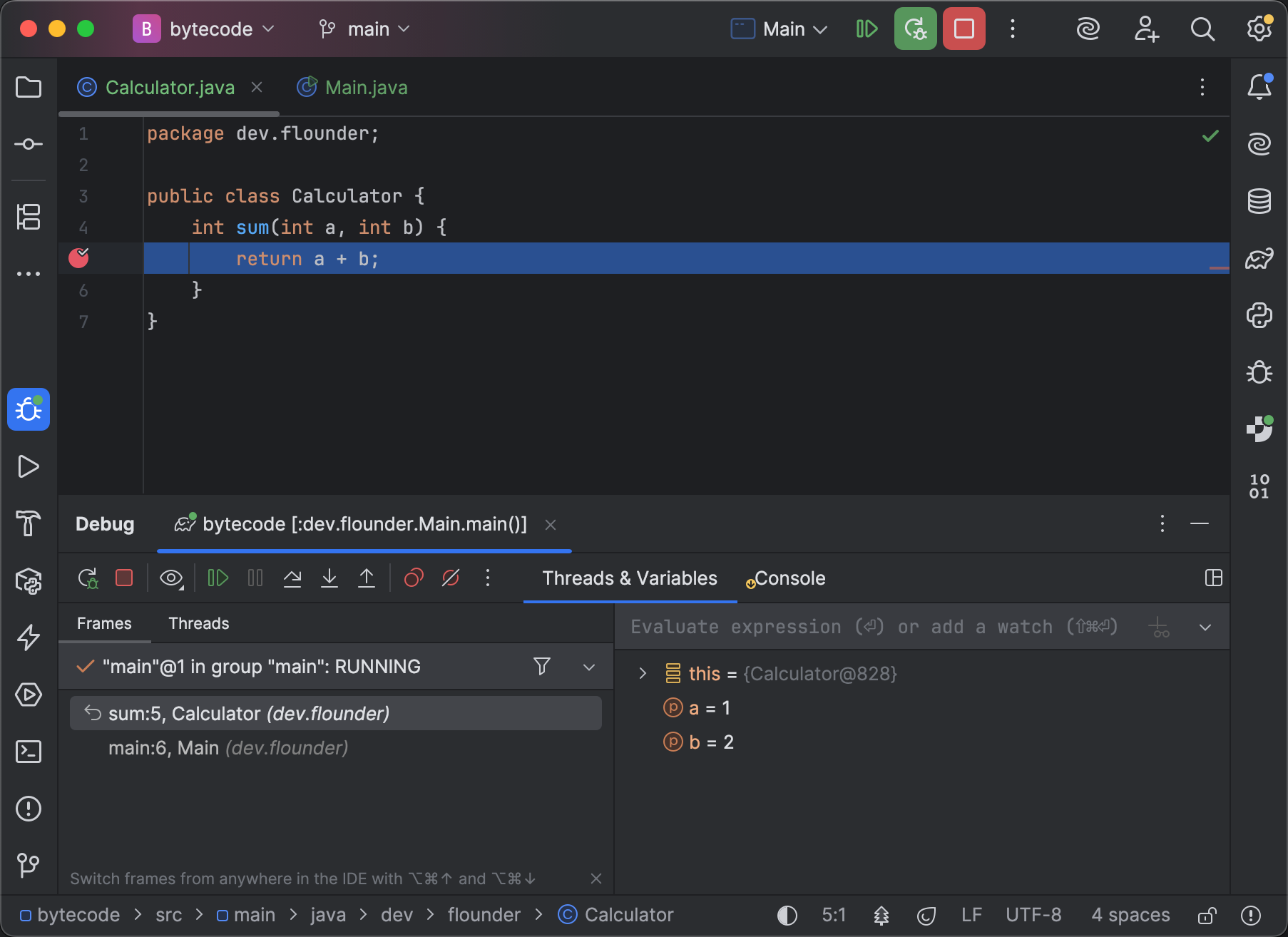
Wie du siehst, verwenden beide Debugger die korrekten Variablennamen und referenzieren gültige Zeilen aus unserem obigen Code-Snippet.
Da die Laufzeitumgebung keinen Zugriff auf die Quelldateien hat, muss sie diese Daten anderswo sammeln. Hier kommen die Debug-Informationen ins Spiel. Debug-Informationen (auch als Debug-Symbole bezeichnet) sind kompakte Daten, die den Bytecode mit den Quellen der Anwendung verknüpfen. Sie werden während der Kompilierung in die .class-Dateien eingefügt.
Es gibt drei Arten von Debug-Informationen:
In den folgenden Kapiteln werde ich jede Art von Debug-Information kurz erklären und wie der Debugger sie verwendet.
Zeilennummern
Zeilennummerninformationen werden im Attribut LineNumberTable innerhalb der Bytecode-Datei gespeichert und sehen so aus:
LineNumberTable:
line 5: 0
line 6: 2Die obige Tabelle sagt dem Debugger Folgendes:
- Zeile 5 enthält die Anweisung bei Offset 0
- Zeile 6 enthält die Anweisung bei Offset 2
Diese Art von Debug-Information hilft externen Werkzeugen, wie Debuggern oder Profilern, die genaue Zeile zu verfolgen, an der das Programm im Quellcode ausgeführt wird.
Wichtig ist, dass Zeilennummerninformationen auch für Quellverweise in Exception-Stack-Traces verwendet werden. Im folgenden Beispiel habe ich Code aus meinem anderen Tutorial sowohl mit als auch ohne Zeilennummerninformationen kompiliert. Hier sind die Stack-Traces, die von den resultierenden Executables erzeugt wurden:
Exception in thread "main" java.lang.NumberFormatException: For input string: ""
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
at java.base/java.lang.Integer.parseInt(Integer.java:672)
at java.base/java.lang.Integer.parseInt(Integer.java:778)
at dev.flounder.Airports.parse(Airports.java:53)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
at java.base/java.util.Iterator.forEachRemaining(Iterator.java:133)
at java.base/java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1939)
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499)
at java.base/java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
at java.base/java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.base/java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:596)
at dev.flounder.Airports.main(Airports.java:39)Exception in thread "main" java.lang.NumberFormatException: For input string: ""
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
at java.base/java.lang.Integer.parseInt(Integer.java:672)
at java.base/java.lang.Integer.parseInt(Integer.java:778)
at dev.flounder.Airports.parse(Airports.java)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
at java.base/java.util.Iterator.forEachRemaining(Iterator.java:133)
at java.base/java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1939)
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499)
at java.base/java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
at java.base/java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.base/java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:596)
at dev.flounder.Airports.main(Airports.java)Das ohne Zeilennummerninformationen kompilierte Executable erzeugte einen Stack-Trace, dem Zeilennummern für die Aufrufe fehlen, die meinem Projektcode entsprechen. Die Aufrufe aus der Standardbibliothek und den Abhängigkeiten enthalten immer noch Zeilennummern, da sie separat kompiliert wurden und nicht betroffen waren.
Neben Stack-Traces könntest du auf eine ähnliche Situation stoßen, in der Zeilennummern beteiligt sind, zum Beispiel im Frames-Tab von IntelliJ IDEA:

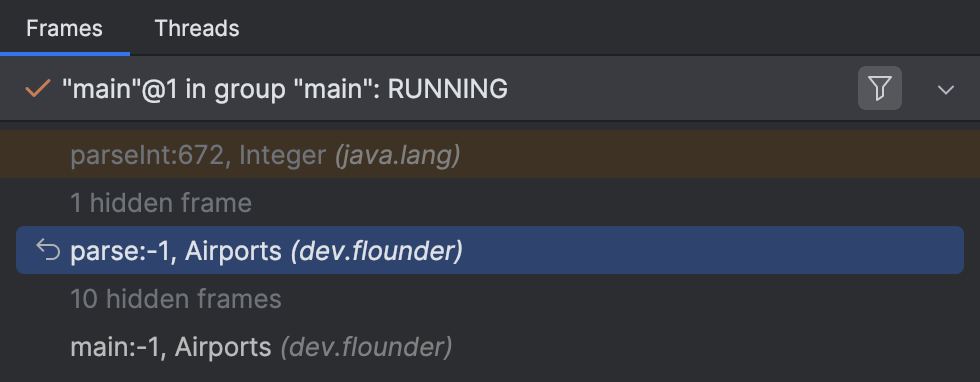
Wenn du also -1 anstelle tatsächlicher Zeilennummern siehst und das nicht magst,
stelle sicher, dass dein Programm mit Zeilennummerninformationen kompiliert wurde.

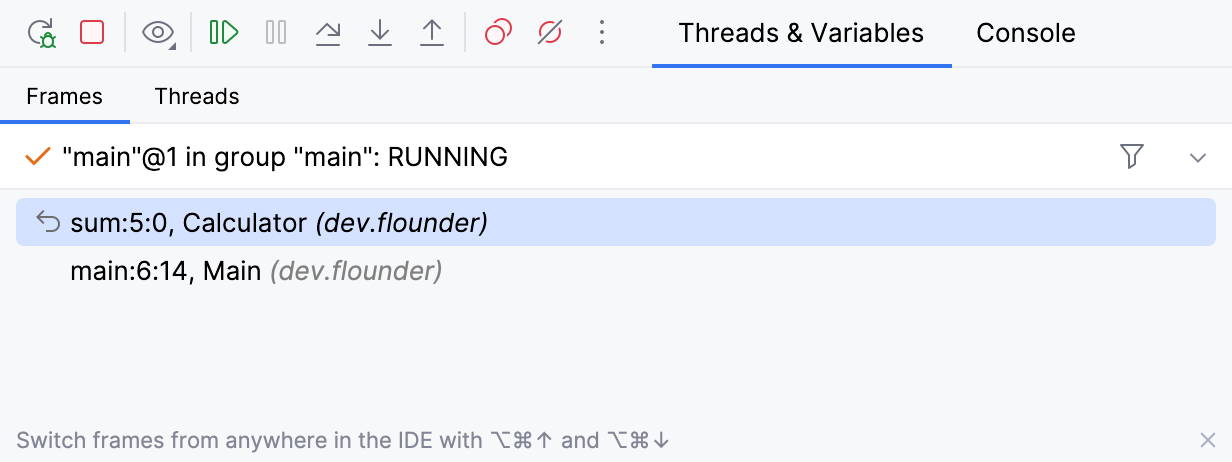
Du kannst den Bytecode-Offset direkt im Frames-Tab von IntelliJ IDEA anzeigen.
Füge dafür den folgenden Registry-Schlüssel hinzu:
debugger.stack.frame.show.code.index=true
Variablennamen
Wie Zeilennummerninformationen werden Variablennamen in Class-Dateien gespeichert. Die Variablentabelle für unser Beispiel sieht wie folgt aus:
LocalVariableTable:
Start Length Slot Name Signature
0 4 0 this Ldev/flounder/Calculator;
0 4 1 a I
0 4 2 b ISie enthält die folgenden Informationen:
- Start: Der Bytecode-Offset, an dem der Gültigkeitsbereich dieser Variable beginnt.
- Length: Die Anzahl der Anweisungen, während derer diese Variable im Gültigkeitsbereich bleibt.
- Slot: Der Index, an dem diese Variable für die Suche gespeichert wird.
- Name: Der Name der Variable, wie er im Quellcode erscheint.
- Signature: Der Datentyp der Variable, ausgedrückt in Javas Typsignatur-Notation.
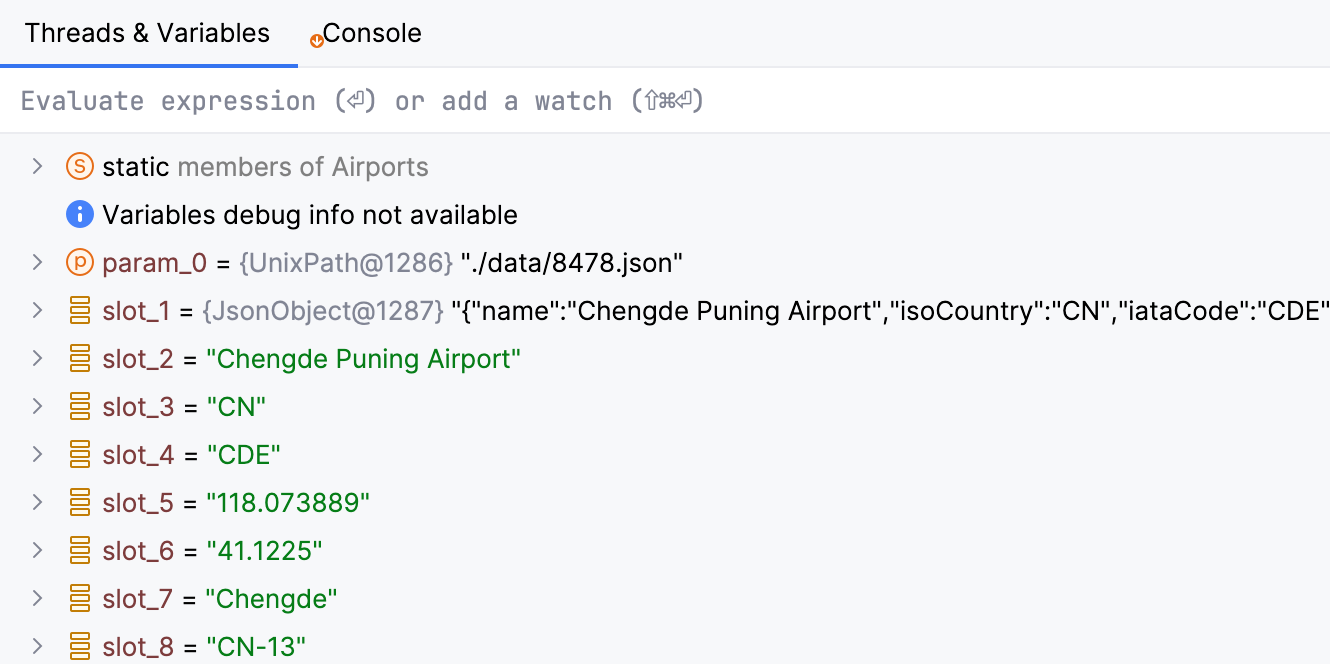
Wenn Variablen in den Debug-Informationen fehlen, funktioniert möglicherweise einige Debugger-Funktionalität nicht wie erwartet,
und du wirst slot_1, slot_2 usw. anstelle der tatsächlichen Variablennamen sehen.
Quelldateinamen
Diese Art von Debug-Information gibt an, welche Quelldatei verwendet wurde, um die Klasse zu kompilieren. Wie Zeilennummerninformationen beeinflusst ihre Anwesenheit in den Class-Dateien nicht nur externe Werkzeuge, sondern auch die Stack-Traces, die dein Programm generiert.
Exception in thread "main" java.lang.NumberFormatException: For input string: ""
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
at java.base/java.lang.Integer.parseInt(Integer.java:672)
at java.base/java.lang.Integer.parseInt(Integer.java:778)
at dev.flounder.Airports.parse(Airports.java:53)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
at java.base/java.util.Iterator.forEachRemaining(Iterator.java:133)
at java.base/java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1939)
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499)
at java.base/java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
at java.base/java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.base/java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:596)
at dev.flounder.Airports.main(Airports.java:39)Exception in thread "main" java.lang.NumberFormatException: For input string: ""
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
at java.base/java.lang.Integer.parseInt(Integer.java:672)
at java.base/java.lang.Integer.parseInt(Integer.java:778)
at dev.flounder.Airports.parse(Unknown Source)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
at java.base/java.util.Iterator.forEachRemaining(Iterator.java:133)
at java.base/java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1939)
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499)
at java.base/java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
at java.base/java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.base/java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:596)
at dev.flounder.Airports.main(Unknown Source)Ohne Quelldateinamen werden die entsprechenden Stack-Trace-Aufrufe als Unknown Source markiert.
Compiler-Flags
Als Entwickler hast du die Kontrolle darüber, ob Debug-Informationen in deine Executables aufgenommen werden sollen
und wenn ja, welche Arten. Du kannst dies mit dem -g-Compiler-Argument verwalten, wie folgt:
javac -g:lines,vars,sourceHier ist die Syntax:
| Befehl | Ergebnis |
javac | Kompiliert die Anwendung mit Zeilennummern und Quelldateinamen (Standard für die meisten Compiler) |
javac -g | Kompiliert die Anwendung mit allen verfügbaren Debug-Informationen: Zeilennummern, Variablen und Quelldateinamen |
javac -g:lines,source | Kompiliert die Anwendung mit den angegebenen Arten von Debug-Informationen – Zeilennummern und Quelldateinamen in diesem Beispiel |
javac -g:none | Kompiliert die Anwendung ohne Debug-Informationen |
Standardwerte können zwischen Compilern variieren. Einige von ihnen schließen Debug-Informationen vollständig aus, es sei denn, sie werden anders angewiesen.
Wenn du ein Build-System wie Maven oder Gradle verwendest, kannst du dieselben Optionen über Compiler-Argumente übergeben. Zum Beispiel:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.11.0</version>
<configuration>
<compilerArgs>
<arg>-g:vars,lines</arg>
</compilerArgs>
</configuration>
</plugin>tasks.compileJava {
options.compilerArgs.add("-g:vars,lines")
}Warum Debug-Informationen entfernen?
Wie wir gerade gesehen haben, ermöglichen Debug-Symbole den Debugging-Prozess, was während der Entwicklung praktisch ist. Aus diesem Grund werden Debug-Symbole normalerweise in Entwicklungs-Builds eingefügt. In Produktions-Builds werden sie oft ausgeschlossen; dies hängt jedoch letztendlich von der Art des Projekts ab, an dem du arbeitest.
Hier sind ein paar Dinge, die du berücksichtigen solltest:
Sicherheit
Da ein Debugger verwendet werden kann, um dein Programm zu manipulieren, macht das Einschließen von Debug-Informationen deine Anwendung etwas anfälliger für Hacking und Reverse Engineering, was für einige Anwendungen unerwünscht sein kann.
Obwohl das Fehlen von Debug-Symbolen es etwas schwieriger machen könnte, mit einem Debugger in dein Programm einzugreifen, schützt es nicht vollständig davor. Debugging bleibt auch mit teilweisen oder fehlenden Debug-Informationen möglich, sodass dies allein eine entschlossene Person nicht davon abhält, auf die Interna deines Programms zuzugreifen. Wenn du dir also Sorgen über das Risiko von Reverse Engineering machst, solltest du zusätzliche Maßnahmen ergreifen, wie z.B. Code-Obfuskation.
Executable-Größe
Je mehr Informationen ein Executable enthält, desto größer wird es. Wie viel größer genau, hängt von verschiedenen Faktoren ab. Die Größe einer bestimmten Class-Datei kann leicht von der Anzahl der Anweisungen und der Größe des Konstantenpools dominiert werden, was es unpraktisch macht, eine universelle Schätzung zu geben. Um jedoch zu demonstrieren, dass der Unterschied erheblich sein kann, experimentierte ich mit Airports.java, das wir früher zum Vergleichen von Stack-Traces verwendet haben. Die Ergebnisse sind 4.460 Bytes ohne Debug-Informationen im Vergleich zu 5.664 Bytes mit ihnen.
In den meisten Fällen schadet das Einschließen von Debug-Symbolen nicht. Wenn jedoch die Executable-Größe ein Problem ist, wie es oft bei eingebetteten Systemen der Fall ist, möchtest du Debug-Symbole möglicherweise aus deinen Binärdateien ausschließen.
Quellen für das Debugging hinzufügen
Typischerweise befinden sich die erforderlichen Quellen in deinem Projekt, sodass die IDE keine Probleme haben wird, sie zu finden. Es gibt jedoch weniger häufige Situationen – zum Beispiel, wenn der für das Debugging benötigte Quellcode außerhalb deines Projekts liegt, wie beim Einsteigen in eine von deinem Code verwendete Bibliothek.
In diesem Fall musst du Quelldateien manuell hinzufügen: entweder indem du sie unter einem Sources Root platzierst oder indem du sie als Abhängigkeit angibst. Während des Debuggings wird IntelliJ IDEA diese Dateien automatisch erkennen und mit den von der JVM ausgeführten Klassen abgleichen.
Wenn das Projekt fehlt
In den meisten Fällen würdest du eine Anwendung in derselben IDE erstellen, starten und debuggen, unter Verwendung des Originalprojekts. Aber was ist, wenn du nur wenige Quelldateien haben und das Projekt selbst fehlt?
Hier ist ein minimales Debugging-Setup, das funktioniert:
- Erstelle ein leeres Java-Projekt
- Füge die Quelldateien unter einem Sources Root hinzu oder gib sie als Abhängigkeit an
- Starte die Zielanwendung mit dem Debug-Agenten. In Java geschieht dies typischerweise durch Hinzufügen einer VM-Option, wie:
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005- Erstelle eine Remote JVM Debug Run Configuration mit den korrekten Verbindungsdetails. Verwende diese Run Configuration, um den Debugger an die Zielanwendung anzuhängen.
Mit diesem Setup kannst du ein Programm debuggen, ohne auf das Originalprojekt zugreifen zu müssen. IntelliJ IDEA wird die verfügbaren Quellen mit den Laufzeitklassen abgleichen und dir erlauben, sie in einer Debugging-Sitzung zu verwenden. Auf diese Weise bietet selbst eine einzelne Projekt- oder Bibliotheksklasse einen Einstiegspunkt für das Debugging.
Für ein praktisches Beispiel schau dir Mit dem Debugger den Gottmodus zusammenbasteln an, wo wir diese Technik verwenden, um das Verhalten eines Programms zu ändern, ohne auf seinen Quellcode zuzugreifen
Quellenabweichung
Eine verwirrende Situation, auf die du beim Debugging stoßen könntest, ist, wenn deine Anwendung an einer leeren Zeile angehalten erscheint oder die Zeilennummern im Frames-Tab nicht mit denen im Editor übereinstimmen:
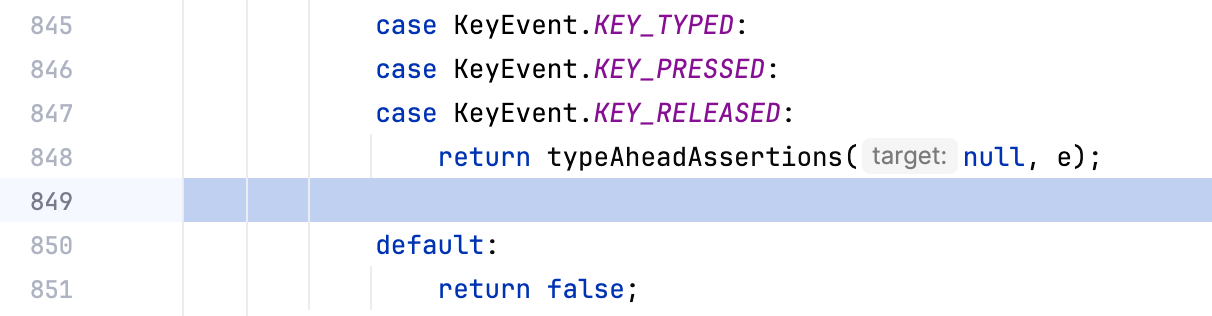
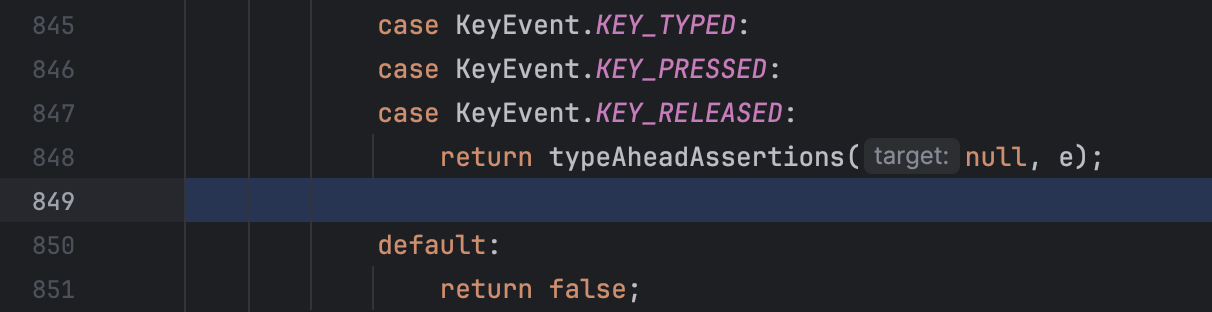
Dies tritt beim Debuggen von dekompiliertem Code (den wir in einem anderen Artikel besprechen werden) oder wenn der Quellcode nicht vollständig mit dem Bytecode übereinstimmt, den die JVM ausführt, auf.
Da die einzige Verbindung zwischen Bytecode und einer bestimmten Quelldatei der Name der Datei und ihrer Klassen ist, muss sich der Debugger auf diese Information verlassen, unterstützt durch einige Heuristiken. Dies funktioniert gut für die meisten Situationen; jedoch kann die Version der Datei auf der Festplatte von der abweichen, die zum Kompilieren der Anwendung verwendet wurde. Im Fall einer teilweisen Übereinstimmung wird der Debugger die Diskrepanzen identifizieren und versuchen, sie auszugleichen, anstatt frühzeitig abzubrechen. Je nach Umfang der Unterschiede kann dies nützlich sein, zum Beispiel wenn die einzige Quelle, die du hast, keine genaue Übereinstimmung ist.
Im glücklichen Szenario, in dem du die exakte Version der Quellen anderswo hast, kannst du dieses Problem beheben, indem du sie zum Projekt hinzufügst und die Debug-Sitzung neu startest.
Fazit
In diesem Artikel haben wir die Verbindung zwischen Quelldateien, Bytecode und dem Debugger erkundet. Obwohl dies nicht streng erforderlich für die tägliche Programmierung ist, kann ein klareres Bild davon, was unter der Haube passiert, dir ein stärkeres Verständnis des Ökosystems geben und gelegentlich bei nicht-standardmäßigen Situationen und Konfigurationsproblemen helfen. Ich hoffe, du fandest die Theorie und Tipps nützlich!
Es gibt noch viele weitere Themen, die in dieser Serie behandelt werden, also bleib dran für das nächste. Wenn es etwas Bestimmtes gibt, das du behandelt sehen möchtest, oder wenn du Ideen und Feedback hast, würde ich gerne von dir hören!