RAG + Markup Semántico
Otros idiomas: English Français Deutsch 日本語 한국어 Português 中文
La importancia de la documentación difiere entre los proyectos de software, pero incluso la documentación más importante juega un papel inherentemente auxiliar. No es algo en lo que se base un programa para funcionar correctamente. Incluso cuando la documentación comparte datos con el programa, la conexión sigue siendo unidireccional. La documentación orientada al usuario refleja el producto y no cambia la forma en que funciona el producto.
La razón principal de esto es puramente tecnológica. Podríamos implementar nuevas características y soluciones simplemente escribiendo documentación - si las instrucciones en lenguaje natural pudieran ser lo suficientemente específicas, y las computadoras fueran excelentes para interpretarlas. ¿Suena familiar, verdad?
Mientras continúa el debate sobre si será posible programar completamente en lenguaje natural, este cambio potencial en realidad se trata de la accesibilidad del desarrollo de software, en lugar de introducir alguna forma novedosa de operar los programas. En última instancia, seguiríamos obteniendo los mismos binarios, ahora con un compilador adicional, ciertamente notable, involucrado.
¿Puede la IA impulsar características de una manera diferente? Hoy, me gustaría cubrir una de las características recientes impulsadas por la IA en JetBrains IDEs, que aprovecha el procesamiento de lenguaje natural directamente, convirtiendo gran parte de nuestra documentación en un recurso de desarrollo enormemente útil.

Búsqueda de acciones
A partir de la versión 2024.3, AI Assistant en JetBrains IDEs tiene acceso a las acciones de la IDE y te ayuda a encontrar la acción correcta para el problema en cuestión. Además, puede ejecutar esta acción por ti:

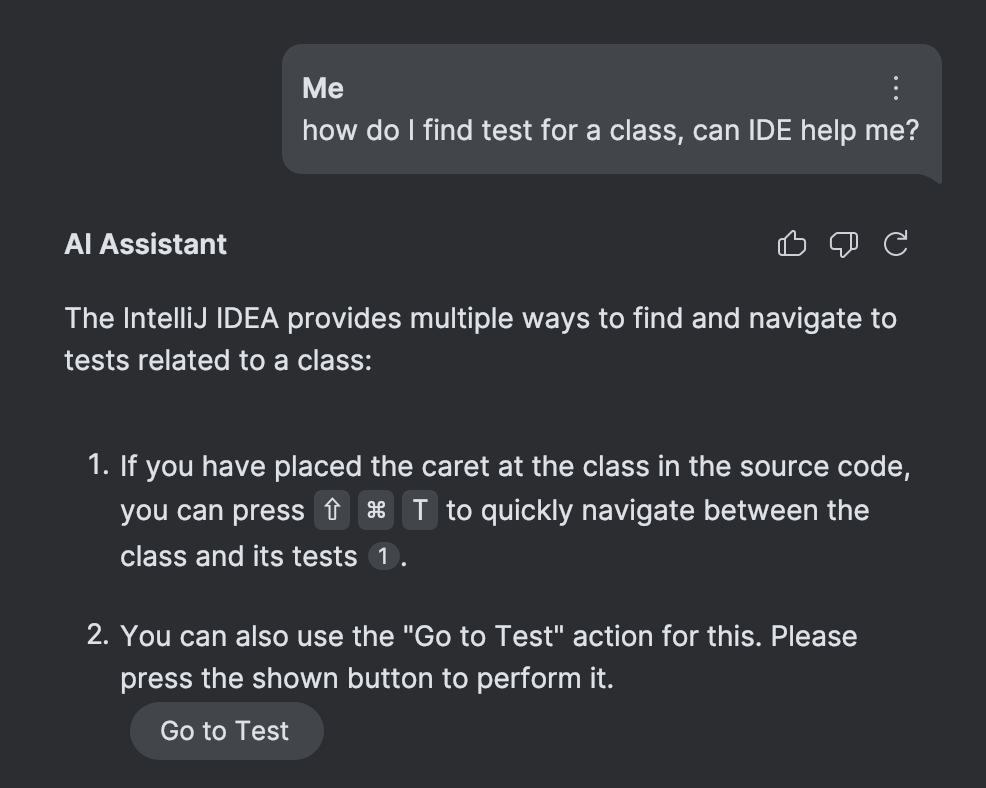
Como se mencionó anteriormente, esta característica está impulsada por la documentación. Aunque el buen código antiguo ciertamente juega un papel, la selección de la acción correcta se basa exclusivamente en una forma avanzada de RAG (generación aumentada por recuperación) – sin la necesidad de numerosas funciones LLM o mapeos especiales.
Antes de pasar a los detalles, volvamos brevemente a revisar el concepto de RAG.
RAG
Generación aumentada por recuperación (RAG) es una técnica que se utiliza comúnmente para mejorar la precisión y conexión de las respuestas de LLM. Es especialmente efectivo cuando se requiere que las LLM den respuestas sobre temas que van más allá de sus datos de entrenamiento y hechos que cambian con frecuencia, haciendo que la puesta a punto sea poco práctica.
En su forma más común, la técnica consiste en mantener un índice sobre la documentación. En este índice, la clave refleja el significado de un elemento del documento, representado por embeddings, y el valor corresponde al contenido del elemento o a una referencia al propio elemento. Gracias a la representación numérica de las claves, los elementos correspondientes pueden ser comparados y recuperados semánticamente utilizando métodos como similaridad de coseno o k-vecinos más cercanos (KNN).
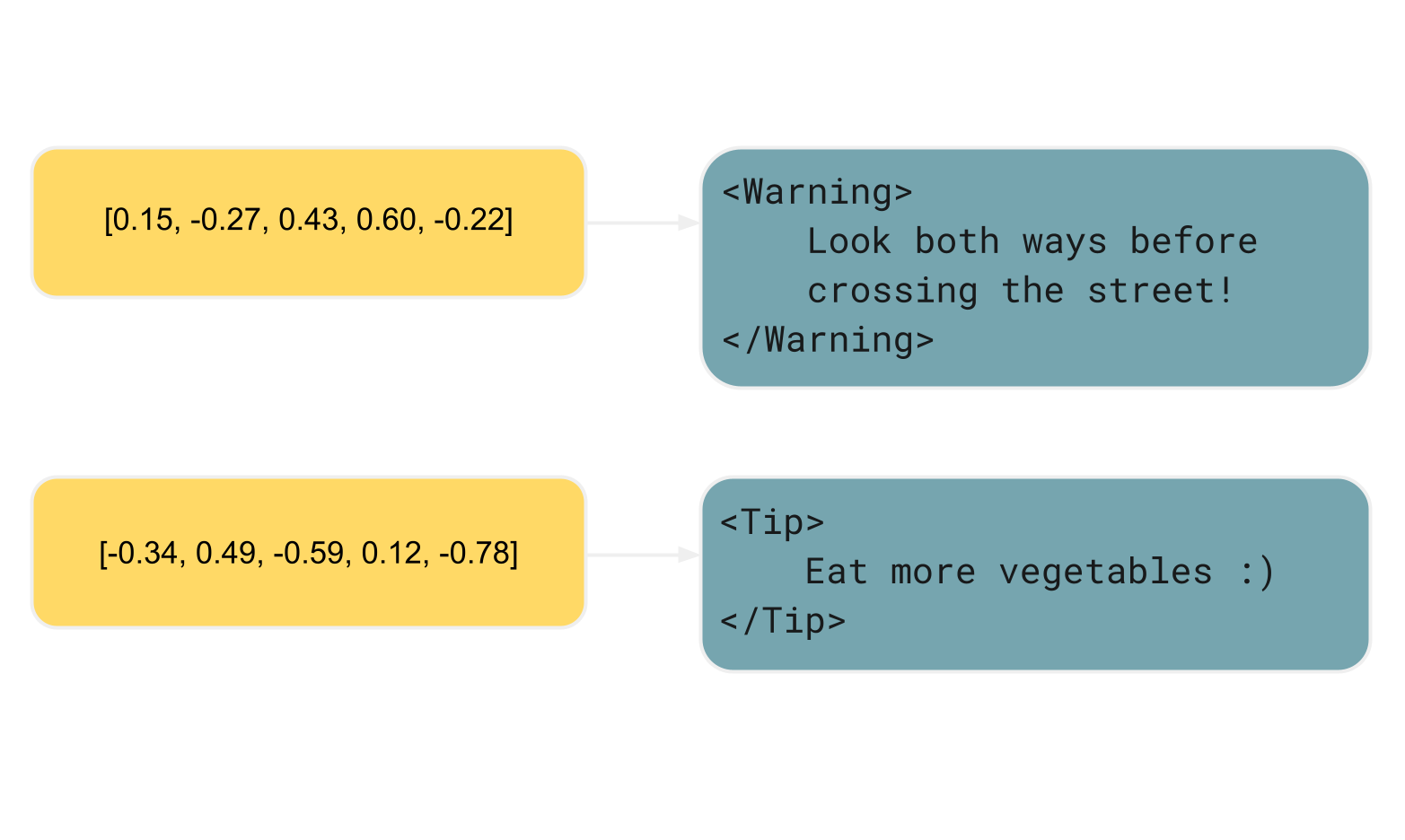
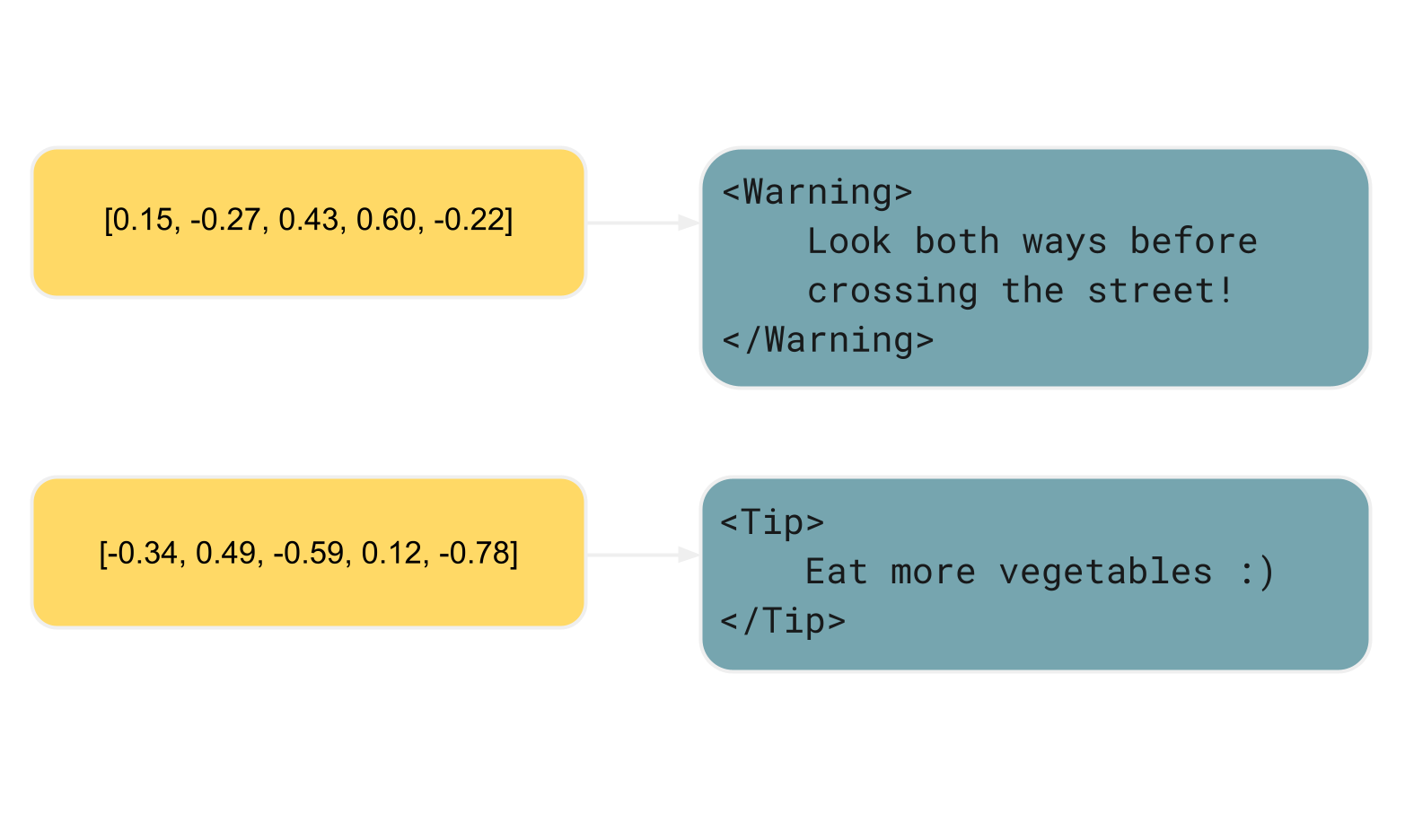
Esto es lo que sucede cuando haces una pregunta en un chat de IA asistido por RAG:
How do I change font size?El sistema primero busca en el índice, y si eso tiene éxito, añade los resultados a la instrucción. Por ejemplo:
How do I change font size?
Here's supplementary information that might help you answer the question:
-> the search results are inserted here <-Con este enfoque, es probable que la respuesta correcta pueda inferirse de la información complementaria proporcionada, resultando en una respuesta más informada y precisa del LLM. Desde la perspectiva del usuario final, puede parecer que el modelo se volvió más inteligente, mientras que en realidad el modelo permanece sin cambios – la única diferencia radica en la instrucción.
Ahora veamos cómo podemos mejorar este enfoque.
Markup semántico
Si escribes documentación técnica, probablemente estés familiarizado con el concepto de markup semántico:
Con el markup semántico especificas el “significado” detrás de cada elemento
Por ejemplo, Markdown no es semántico. En Markdown, operas con elementos comunes de documentos como encabezados, párrafos, listas, etc., además de algunas propiedades tipográficas. Esta sintaxis describe una estructura de alto nivel y le dice al procesador cómo renderizar el documento. Lo que no indica es el propósito, o el significado, de varios elementos dentro del documento.
Aquí hay un breve ejemplo. Los asteriscos indican al procesador que debe poner en cursiva la frase, similar
a lo que <i> significa en HTML:
*Look both ways before crossing the street!*En contraste, MDX, un superset de Markdown, tiene propiedades semánticas. MDX te permite definir elementos personalizados, que a menudo representan componentes de la interfaz de usuario y pueden comunicar el propósito previsto del contenido:
<Warning>
Look both ways before crossing the street!
</Warning>A diferencia del Markdown estándar, este específico ejemplo de MDX abstrae el aspecto visual y se centra en el
propósito del contenido en su lugar.
Como escritores de documentación, nos preocupa menos si <Warning>
debe usar cursiva o destacarse del texto regular.
Su estilo se define en un lugar separado, como dentro del propio componente o en una hoja de estilos CSS.
Esta separación de preocupaciones
hace que el código sea más fácil de mantener y te permite cambiar el estilo de manera centralizada
en función del significado del contenido.
¿Una pareja perfecta?
En JetBrains, creamos nuestra documentación usando Writerside. Esta herramienta admite tanto Markdown como XML semántico como formatos fuente para la documentación. El ejemplo a continuación muestra una estructura de documento típica escrita en el XML semántico de Writerside:
<chapter title="Testing" id="testing">
... some content ...
<procedure title="Navigate to tests" type="choices">
<p>
When at a symbol declaration, you can navigate to the corresponding
tests by doing one of the following:
</p>
<step>
From the main menu, select <ui-path>Navigate | Test</ui-path>.
</step>
<step>
Press <shortcut key="GotoTest"/>.
</step>
</procedure>
... more content ...
</chapter>Notarás que hay algo de información meta en el fragmento proporcionado. Ya es valioso por las razones mencionadas anteriormente, pero nada nos impide darle un uso adicional.
Considera la etiqueta <shortcut> ,
que representa una combinación de teclas dependiente de la plataforma.
Esta etiqueta es parte de una capa de indirección que permite
administrar y validar menciones de atajos de una manera centralizada.
Para insertar un atajo dentro de un documento, usas la etiqueta <shortcut>
junto con el ID de acción correspondiente de esta manera: <shortcut key="CoolAction"> .
Durante el proceso de compilación, la herramienta valida y transforma los elementos <shortcut>
en las combinaciones de teclas reales para los mapas de teclas disponibles.
Este enfoque sincroniza los atajos entre la documentación y el producto, además de dar a los usuarios de la documentación la flexibilidad de elegir su mapa de teclas preferido. Para ver esto en acción, visita ayuda de IntelliJ IDEA y observa cómo los atajos cambian en el texto dependiendo del mapa de teclas seleccionado en el menú Shortcuts:
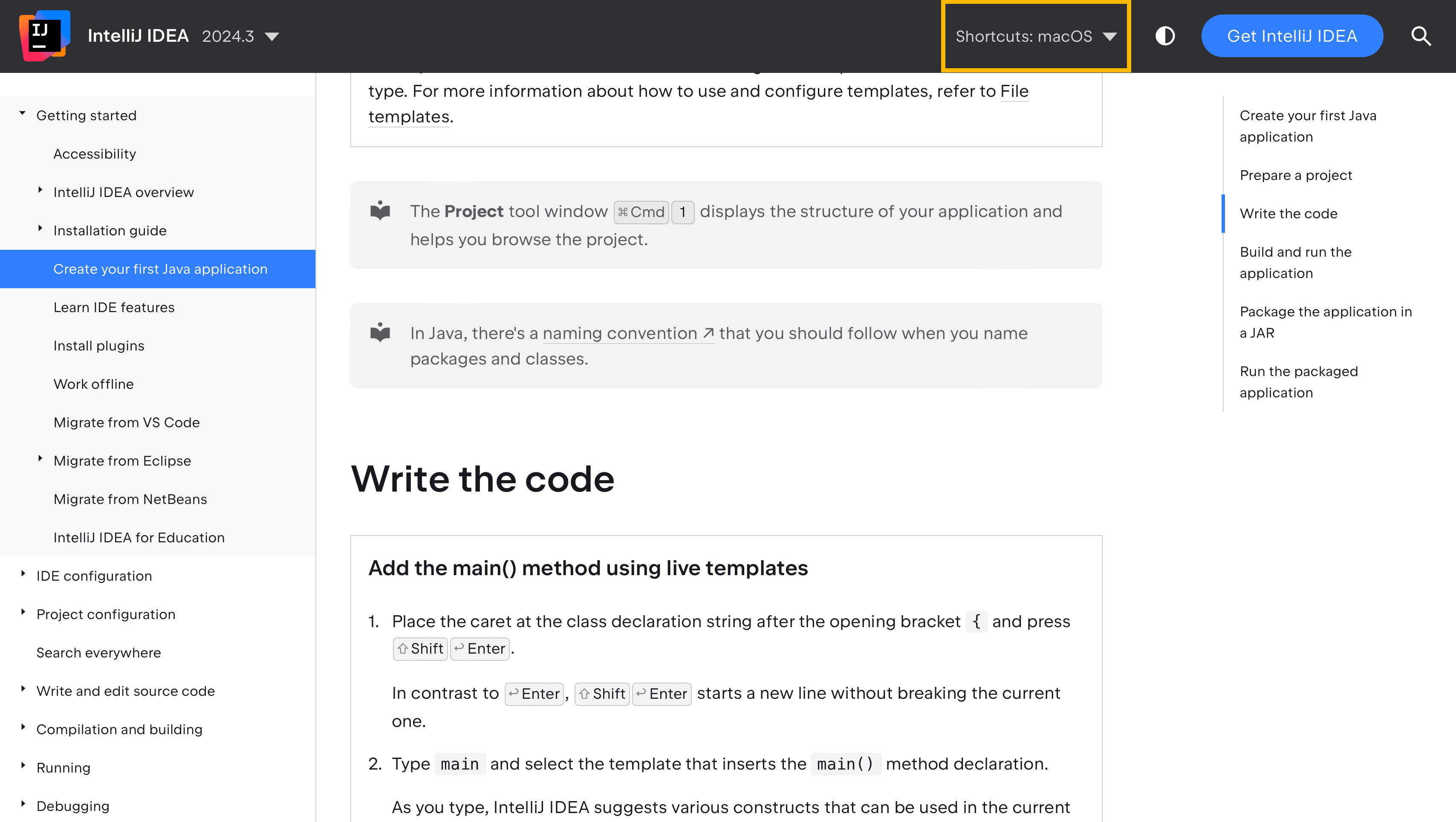
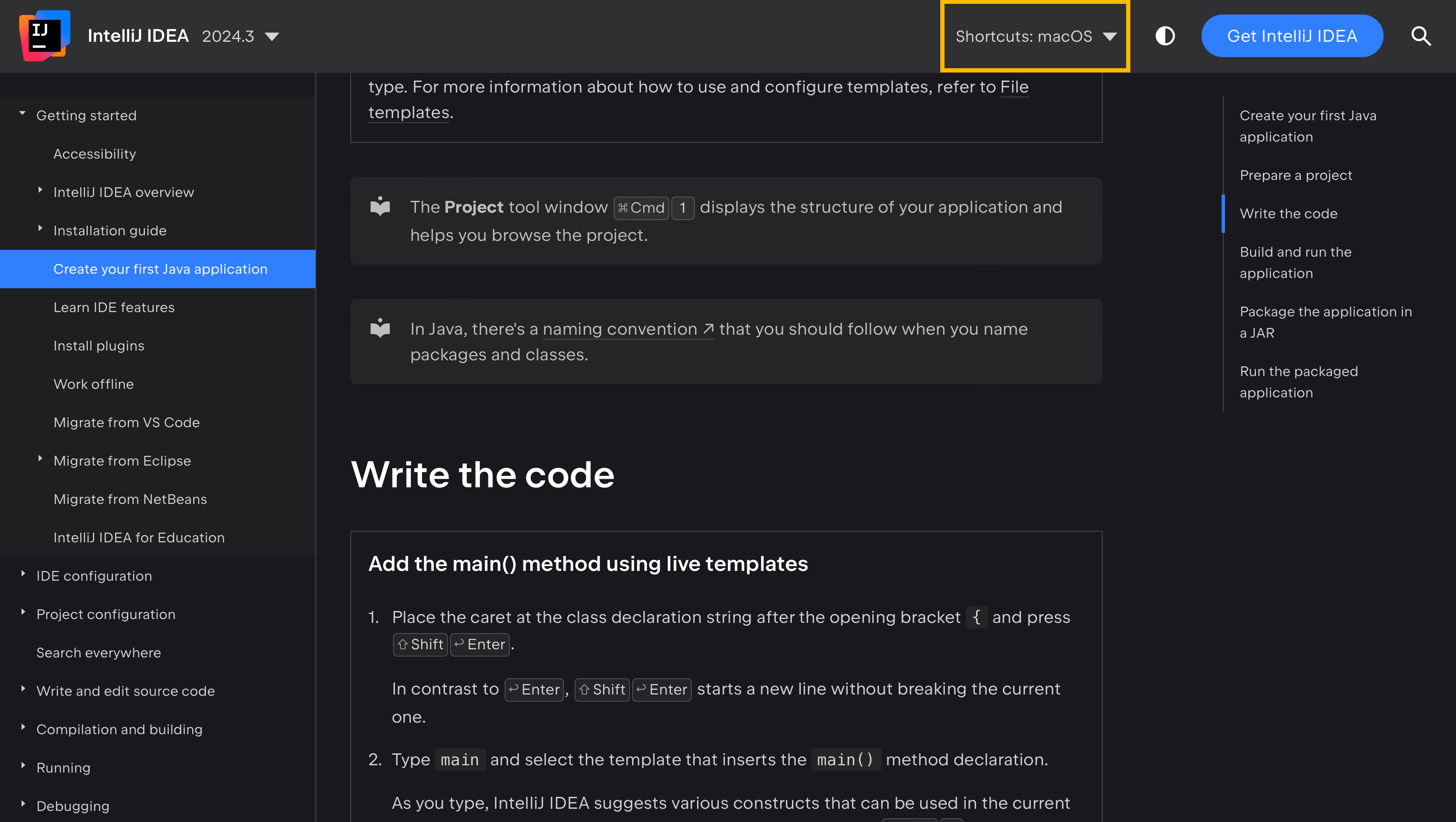
Ese es el propósito principal de la etiqueta <shortcut> .
¿Cómo puede ser útil esta etiqueta en términos de mejorar RAG?
El uso más sencillo es mostrar atajos específicos de la plataforma en el chat de IA, al igual que en la página de ayuda:

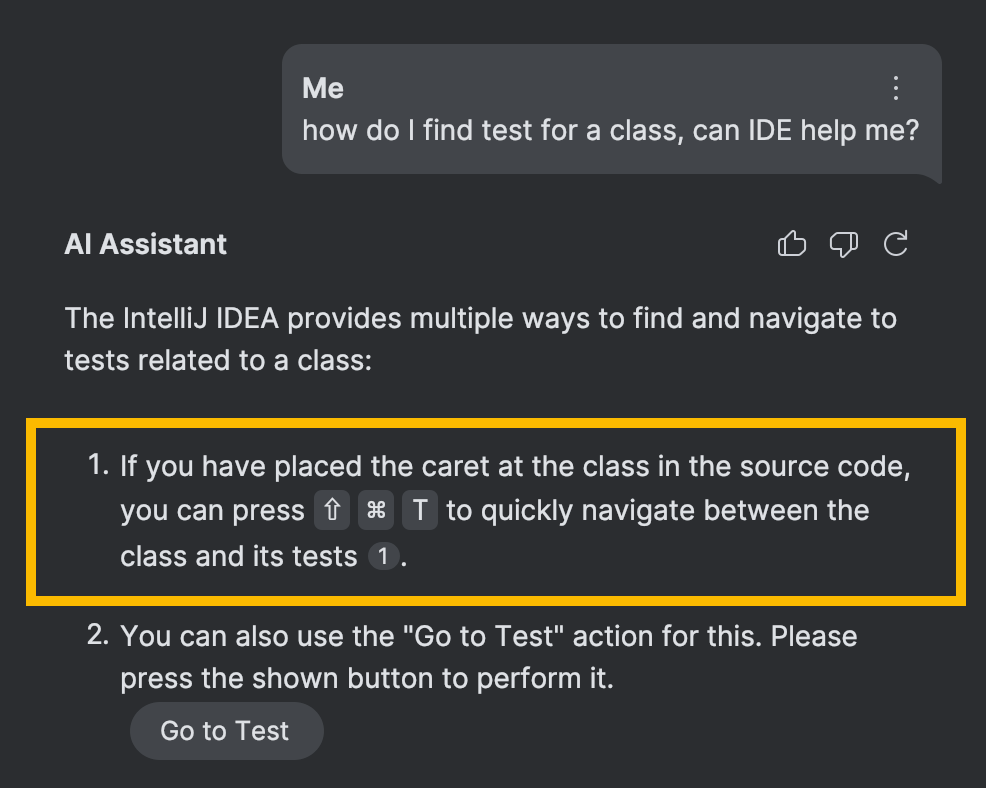
Sin embargo, hay una parte más interesante en esto. Similar a la construcción de índices para recuperar hechos e instrucciones, es posible construir índices que permiten la búsqueda de IDs de acción.
En el escenario RAG más simple discutido anteriormente, generamos las embeddings a partir del mismo elemento destinado a la recuperación. Para el índice de ID de acción, utilizaremos la siguiente estructura:
- las claves son las embeddings derivadas de los elementos que envuelven una etiqueta
<shortcut> - los valores son los IDs de acción dentro de la etiqueta
<shortcut>correspondiente
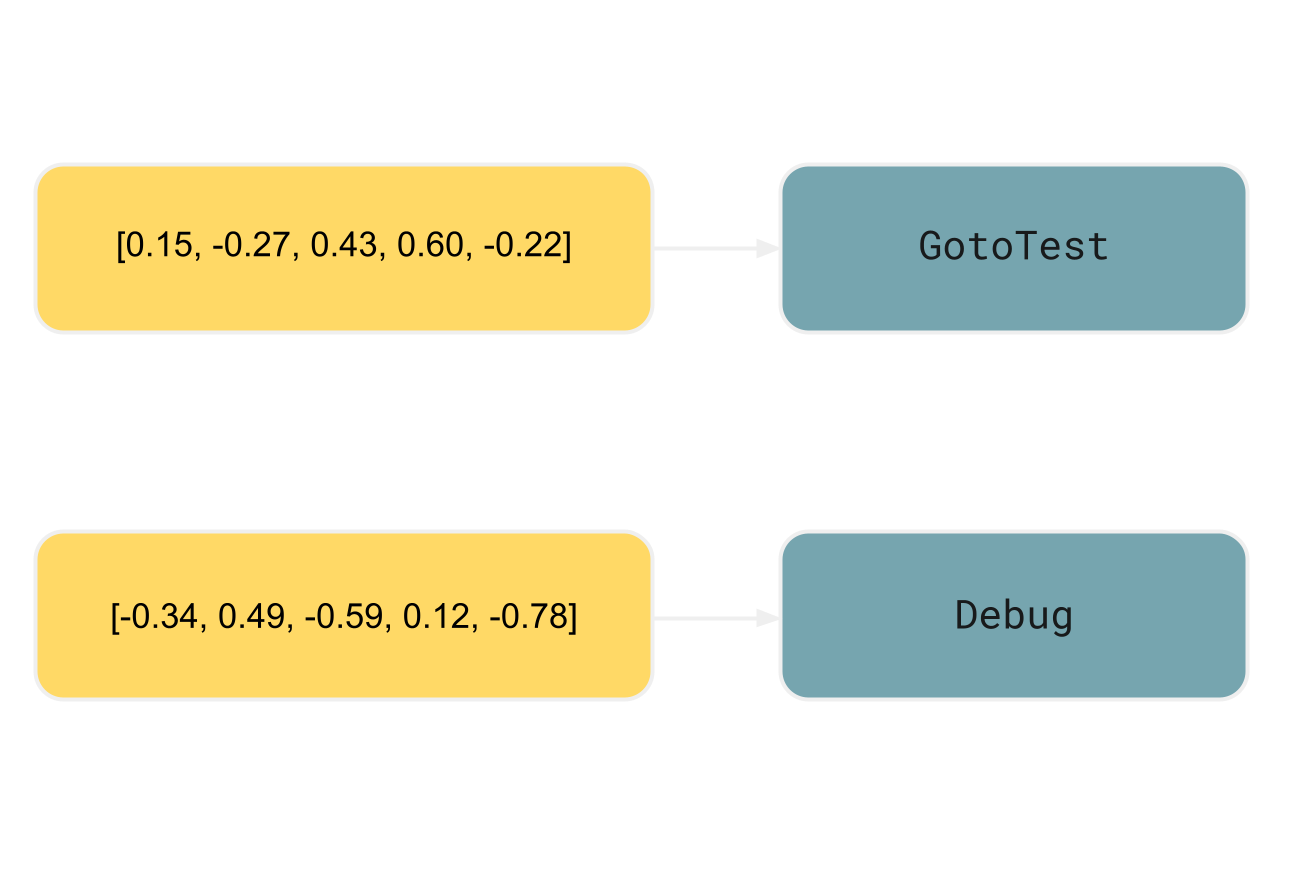
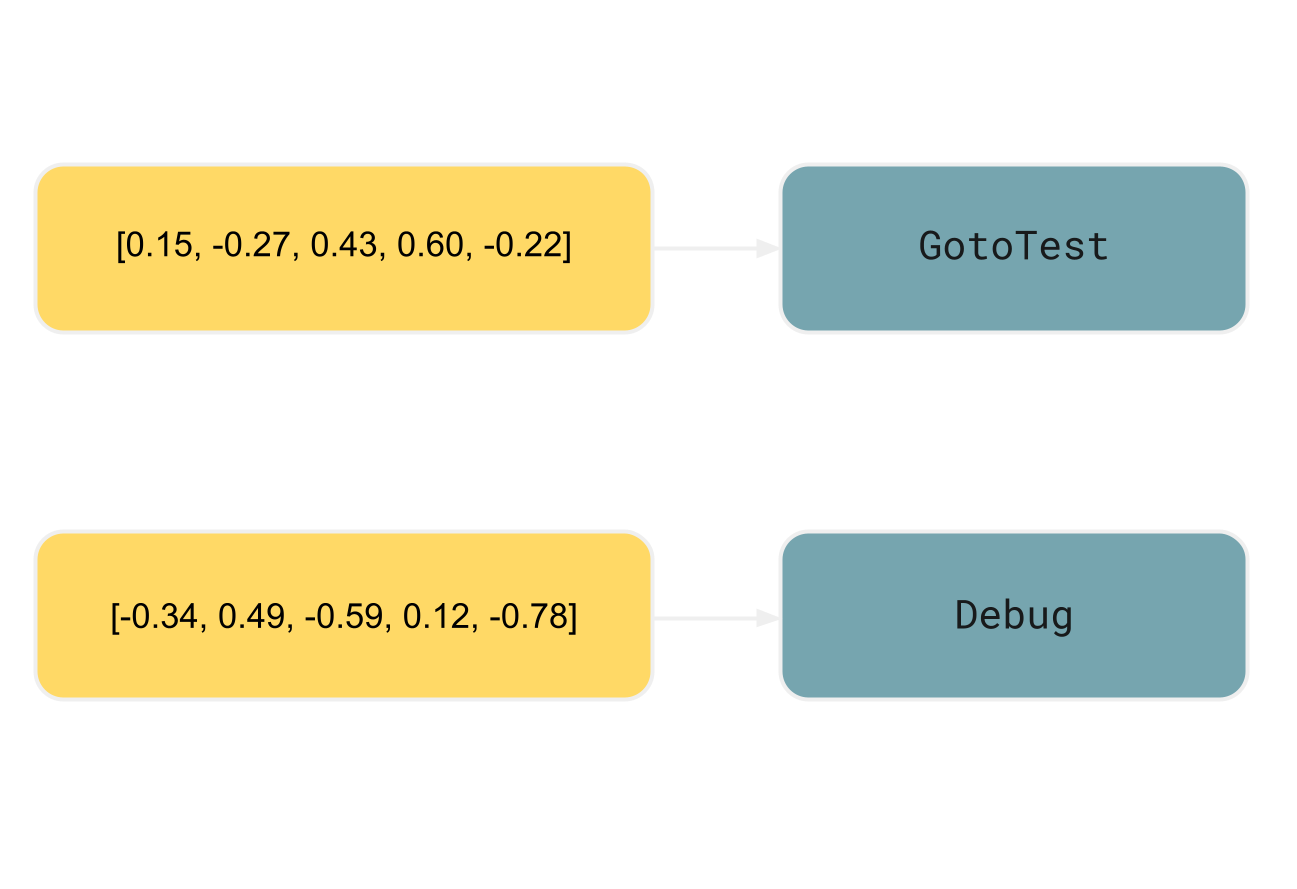
En el ejemplo, el elemento envolvente
para <shortcut key="GotoTest"/>
sería <step>
o incluso todo el <procedure> :
<procedure title="Navigate to tests" type="choices">
<p>
When at a symbol declaration, you can navigate to the corresponding
tests by doing one of the following:
</p>
<step>
From the main menu, select <ui-path>Navigate | Test</ui-path>.
</step>
<step>
Press <shortcut key="GotoTest"/>.
</step>
</procedure>El contexto importa
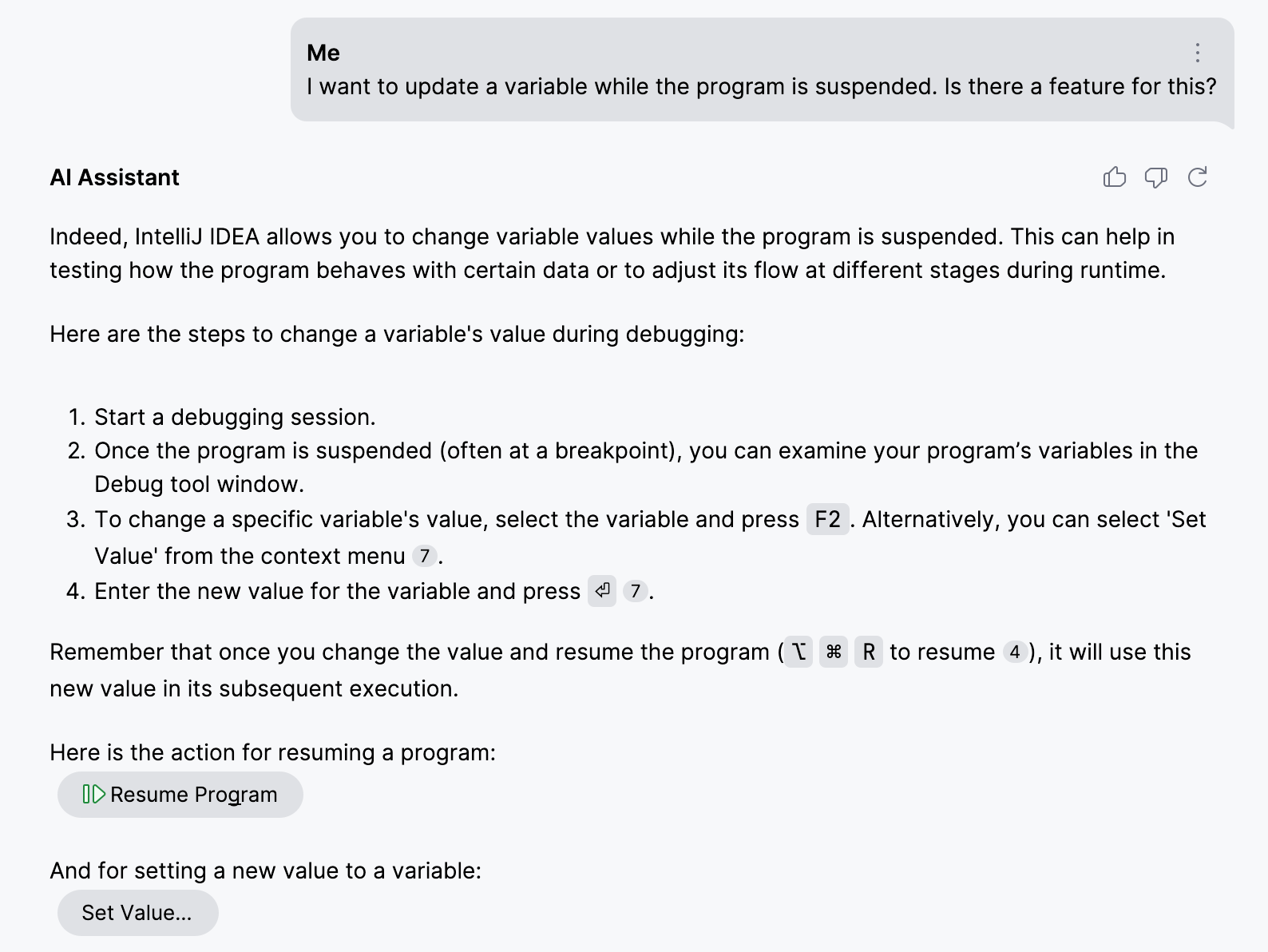
Para demostrar la importancia de indexar el contenido del elemento envolvente, usemos como ejemplo la función Set Value de IntelliJ IDEA. Esta función te permite actualizar variables mientras el programa está suspendido en modo de depuración.
El ID para la acción correspondiente es SetValue .
Sin embargo, este ID en sí no es particularmente descriptivo.
Dado que SetValue y muchos otros ID son combinaciones de palabras bastante genéricas en programación,
una búsqueda semántica basada únicamente en estos ID dará como resultado una
cuota inaceptable tanto de falsos positivos como de negativos.
Sin incluir contexto adicional en el índice,
la tarea se vuelve prácticamente imposible.
En contraste, al establecer la relación entre el ID de acción y el contenido circundante, proporcionamos al Asistente de IA detalles sobre la funcionalidad exacta, sus casos de uso comunes y limitaciones. Esta información aumenta significativamente la precisión de la recuperación:
La parte del cliente
Finalmente, una vez que AI Assistant tiene el ID de acción correcto, puede sugerir esta acción y incluso mostrar un botón para invocarlo directamente desde el chat:

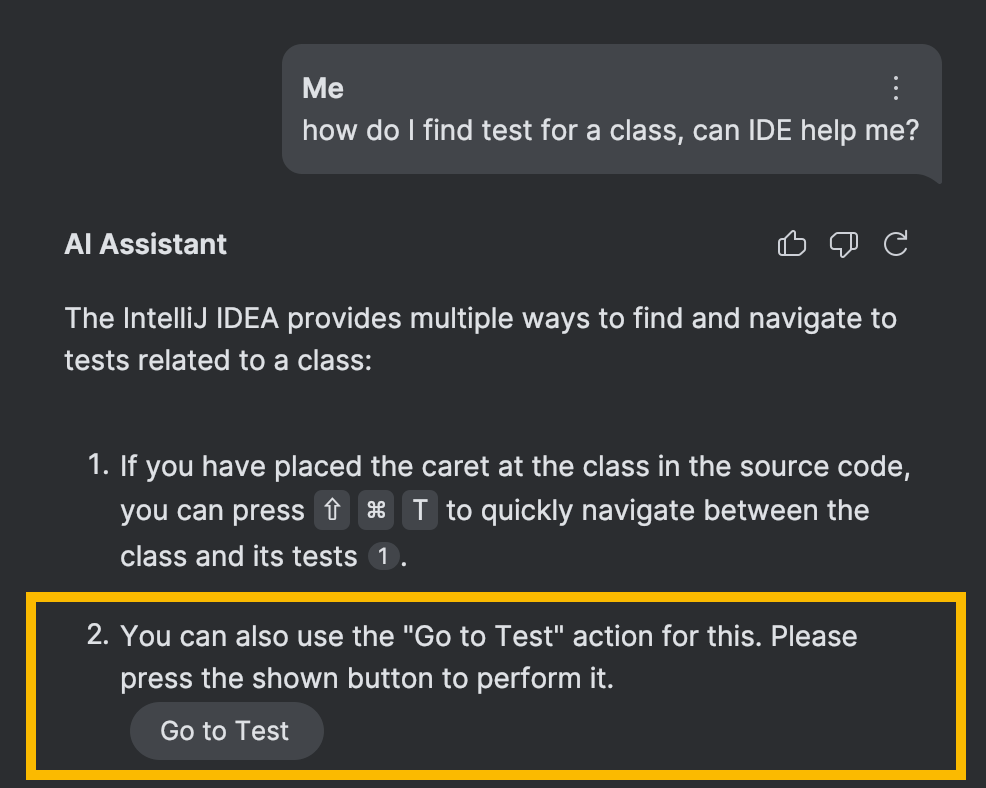
Por supuesto, esta parte es un poco más compleja que simplemente agregar un botón a la interfaz. Dado que las acciones de la IDE dependen del contexto, se deben implementar comprobaciones adicionales, pero este tema es muy específico para el desarrollo de la Plataforma IntelliJ y amerita una discusión separada por sí solo.
Otros elementos de markup
En este post, nos hemos centrado principalmente en la característica de ‘búsqueda de acciones’, que funciona recuperando
IDs de acción de la etiqueta <shortcut> de Writerside.
Sin embargo, puedes aplicar los mismos principios a muchos otros tipos de elementos dentro del markup semántico.
Solo un rápido ejemplo usando el elemento ui-path. Este elemento denota series de elementos de la interfaz de usuario, como elementos de menú, que uno necesita navegar para acceder a la funcionalidad descrita.
<step>
Open the IDE settings (<shortcut key="ShowSettings"/>),
then navigate to <ui-path>Tools | Terminal</ui-path>.
</step>Tiene mucho sentido proporcionar rutas largas en la ayuda web, porque la navegación directa desde una página web al producto normalmente no es práctica. Por otro lado, cuando un usuario pregunta sobre esto en el producto, no hay ninguna razón para no mostrar la página de configuración correspondiente de inmediato:


Resumen
Hace un tiempo, muchos imaginaron el concepto de Web 3.0. La idea era mover toda la web al markup semántico, para que las máquinas pudieran usarla igual que las personas. Aunque esto no ocurrió, es interesante cómo las mismas ideas están volviendo a ser relevantes, ahora desde la perspectiva de herramientas y técnicas modernas.
La característica que cubrí en este artículo es solo un ejemplo de cómo puedes aprovechar tus buenas prácticas existentes, como el markup semántico, con los sistemas de Gen AI. Hay muchas más por explorar. Si estás particularmente interesado en RAG, aquí hay una excelente colección de tutoriales sobre generación aumentada por recuperación.
¿Te gustó el artículo? ¿Te gusta experimentar con Gen AI? A pesar de que mi blog no tiene una sección de comentarios, aún estaría feliz de escuchar tu perspectiva y casos de uso, así que no dudes en comunicarte usando los contactos en el pie de página.
¡Nos vemos pronto!