O Que Está Errado com createDirectories()? - Guia de Perfil de CPU
Outras línguas: English Español Français Deutsch 日本語 한국어 中文
Às vezes sua aplicação funciona, mas você deseja aumentar a performance aumentando a sua produtividade ou reduzindo a latência. Outras vezes, você só quer saber como o código se comporta em tempo de execução, determinar onde estão os pontos de maior exigência, ou descobrir como um framework opera internamente.
Este é um caso de uso perfeito para os criadores de perfil (profilers). Eles oferecem uma visão aérea de grandes blocos de execução, o que ajuda a ver problemas em grande escala.

Muitas pessoas acreditam que não precisam aprender a criar perfis, desde que não estejam escrevendo aplicativos de alta carga. No exemplo, veremos como podemos nos beneficiar da criação de perfis mesmo ao lidar com aplicativos muito simples.
Aplicação de exemplo
Digamos que temos o seguinte programa:
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.*;
import java.util.concurrent.TimeUnit;
public class CountEvents {
public static int update(Deque<Long> events, long nanos, long interval) {
events.add(nanos);
events.removeIf(aTime -> aTime < nanos - interval);
return events.size();
}
public static void main(String[] args) throws IOException {
long start = System.nanoTime();
int total = 100_000;
long interval = TimeUnit.MILLISECONDS.toNanos(100);
int[] count = new int[total];
Deque<Long> collection = new ArrayDeque<>();
for (int counter = 0; counter < count.length; counter++) {
count[counter] = update(collection, System.nanoTime(), interval);
Path p = Paths.get("./a/b");
Files.createDirectories(p);
}
long spent = System.nanoTime() - start;
//noinspection OptionalGetWithoutIsPresent
System.out.println("Average count: " + (int) (Arrays.stream(count).average().getAsDouble()) + " op");
System.out.println("Spent time: " + TimeUnit.NANOSECONDS.toMillis(spent) + " ms");
}
}O programa tenta repetidamente criar um caminho no sistema de arquivos usando o método createDirectories()
do NIO2. Então medimos a produtividade usando um benchmark improvisado.
Toda vez que uma tarefa é executada, a lógica do benchmark armazena o carimbo de tempo atual em uma coleção e remove todos os carimbos de tempo que apontam para um horário
anterior ao tempo atual menos algum intervalo.
Isso torna possível encontrar quantos eventos ocorreram durante esse intervalo de tempo apenas consultando a coleção.
Esse benchmark é suposto para nos ajudar a avaliar o desempenho do método createDirectories() .
Quando executamos o programa, constatamos que os números são suspeitamente baixos:
Average count: 6623 op
Spent time: 1462 msVamos criar um perfil e ver o que está errado.
Obter um snapshot

Estou usando o IntelliJ Profiler porque ele está bem integrado com a IDE e remove o incômodo de configurar tudo. Se você não tem o IntelliJ IDEA Ultimate, você pode usar outro profiler. Neste caso, os passos podem ser um pouco diferentes.
Primeiro, precisamos coletar os dados de criação de perfil, que também são chamados de snapshot. Nesta fase, o profiler é executado ao lado do programa coletando informações sobre sua atividade. Os profilers usam diferentes técnicas para alcançar isso, como instrumentar entradas e saídas de métodos. O IntelliJ Profiler faz isso, coletando periodicamente as informações da pilha de todas as threads em execução no aplicativo.
Para anexar o profiler do IntelliJ IDEA, escolha uma configuração de execução que você normalmente usaria para rodar a aplicação, e selecione Profile no menu.
Quando a aplicação termina de rodar, uma janela popup aparecerá, nos convidando para abrir o snapshot. Se descartarmos o popup por engano, o snapshot ainda estará disponível na janela de ações do Profiler.
Vamos abrir o relatório e ver o que há nele.
Analisar o snapshot
A primeira coisa que vemos após abrir o relatório é o gráfico de chamas. Esta é essencialmente uma síntese de todas as pilhas amostradas. Quanto mais amostras com a mesma pilha o profiler coletou, mais esta pilha cresce no gráfico de chamas. Portanto, a largura da moldura é aproximadamente equivalente à parcela de tempo gasto neste estado.
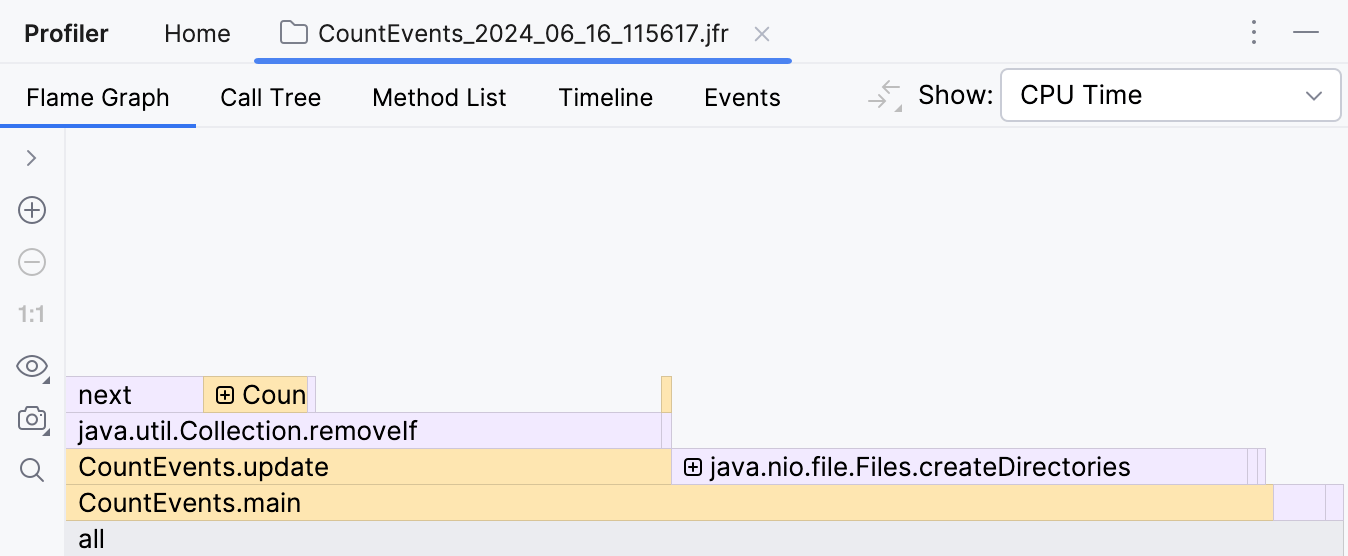
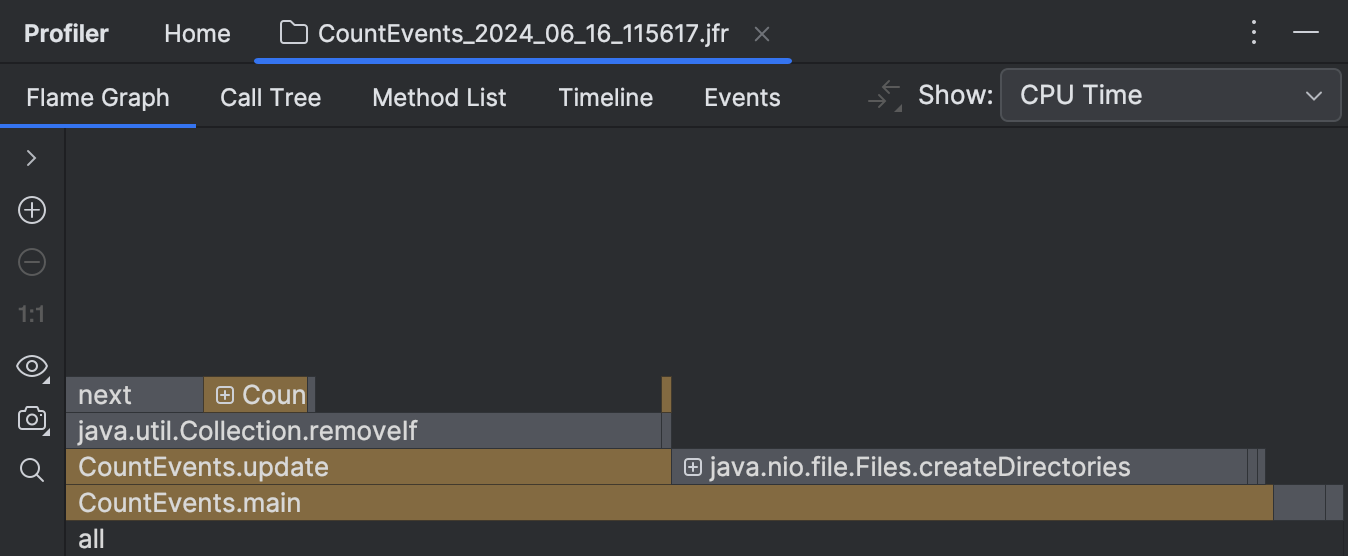
Para nossa surpresa, o método createDirectories() não foi responsável pela maior parte do tempo de execução.
Nosso benchmark caseiro levou aproximadamente o mesmo tempo para ser executado!
Além disso, se olharmos para a moldura acima, vemos que isso é principalmente por causa do
método removeIf() ,
que representa quase todo o tempo de seu chamador, o update() .
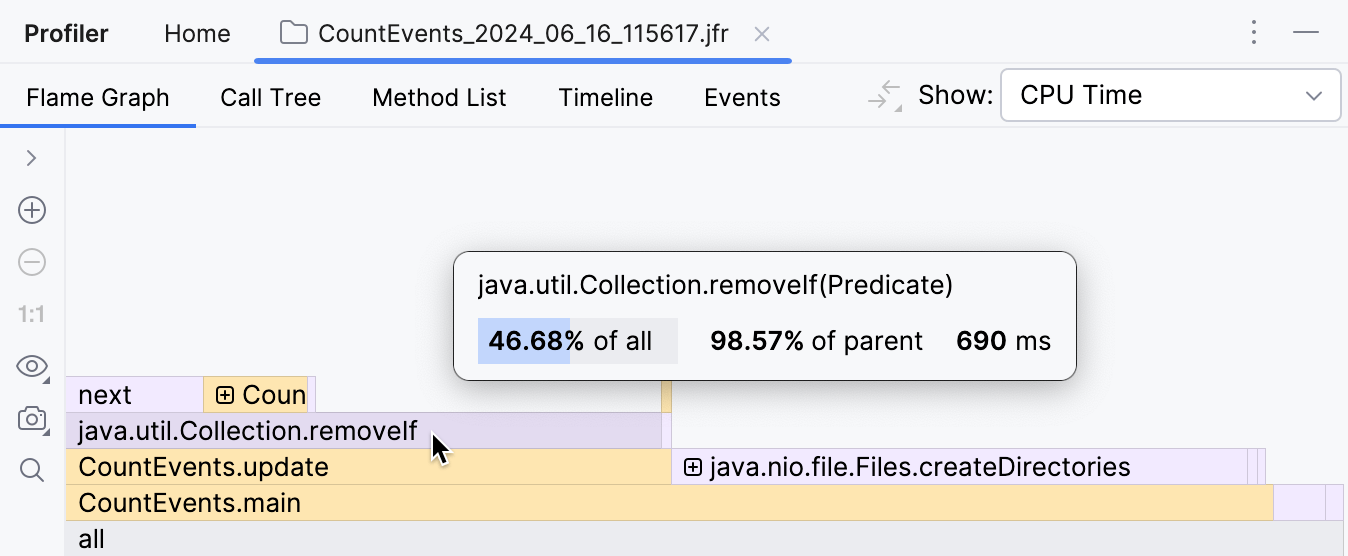
Isso claramente precisa ser investigado.

Juntamente com ferramentas tradicionais, como o gráfico de chamas, O IntelliJ Profiler fornece dicas de desempenho diretamente no editor, que funcionam muito bem para referência rápida e cenários simples:

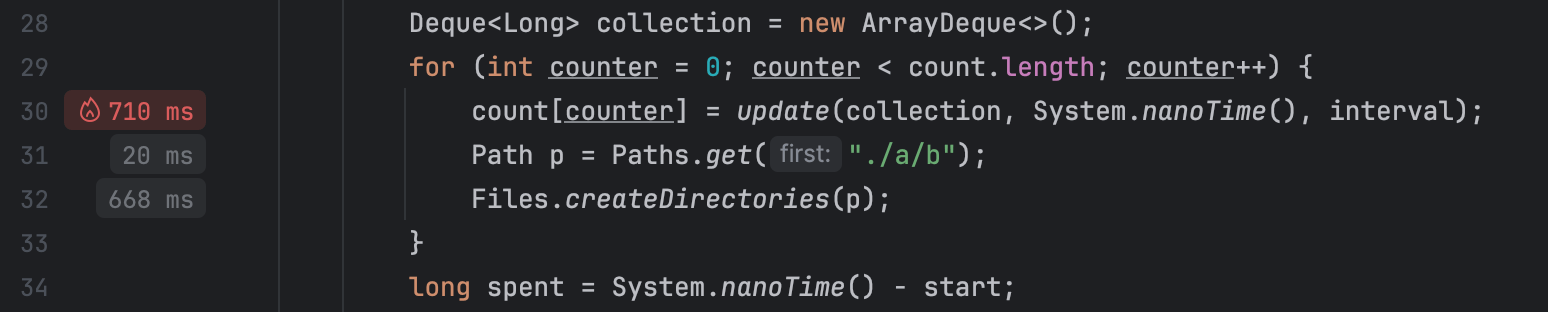
Otimizar o benchmark
Parece que o código responsável por remover eventos da fila está fazendo trabalho extra.
Como estamos usando uma coleção ordenada, e os eventos são adicionados em ordem cronológica,
podemos ter certeza de que todos os elementos sujeitos à remoção estão sempre no início da fila.
Se substituirmos removeIf() por um loop que quebra uma vez que começa a iterar através de
eventos que não vai remover, podemos potencialmente melhorar o desempenho:
// events.removeIf(aTime -> aTime < nanos - interval);
while (events.peekFirst() < nanos - interval) {
events.removeFirst();
}Vamos mudar o código, em seguida, criar o perfil de nossa aplicação novamente e olhar para o resultado:
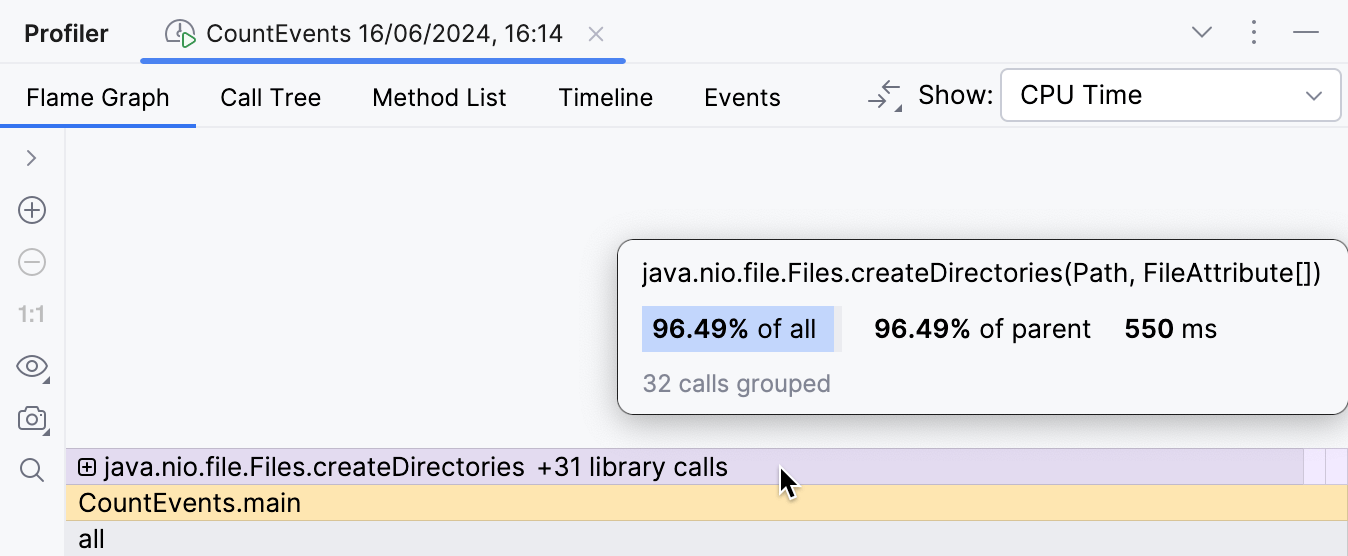
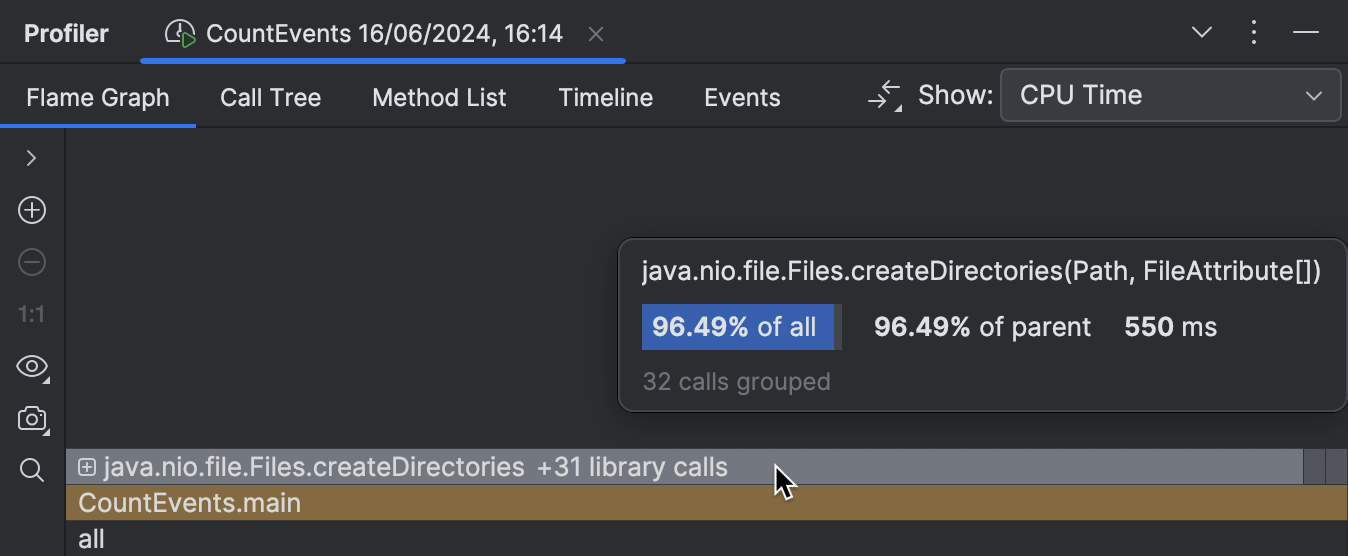
O overhead da lógica do benchmark agora é mínimo como deveria ser,
e a moldura do método createDirectories() agora ocupa aproximadamente 95% de
todo o tempo de execução.
A melhoria também é visível na saída do console:
Average count: 14788 op
Spent time: 639 msCriação de perfil nativa
Tendo resolvido o problema no benchmark, poderíamos parar aqui e nos congratular.
Mas o que está acontecendo com nosso método createDirectories() ?
Ele é muito lento?
Parece haver pouca margem para otimização aqui, uma vez que este é um método de biblioteca, e não temos controle sobre a sua implementação. Ainda assim, o profiler pode nos dar uma dica.
Expandindo as molduras da biblioteca dobradas, podemos inspecionar o que está acontecendo no interior.
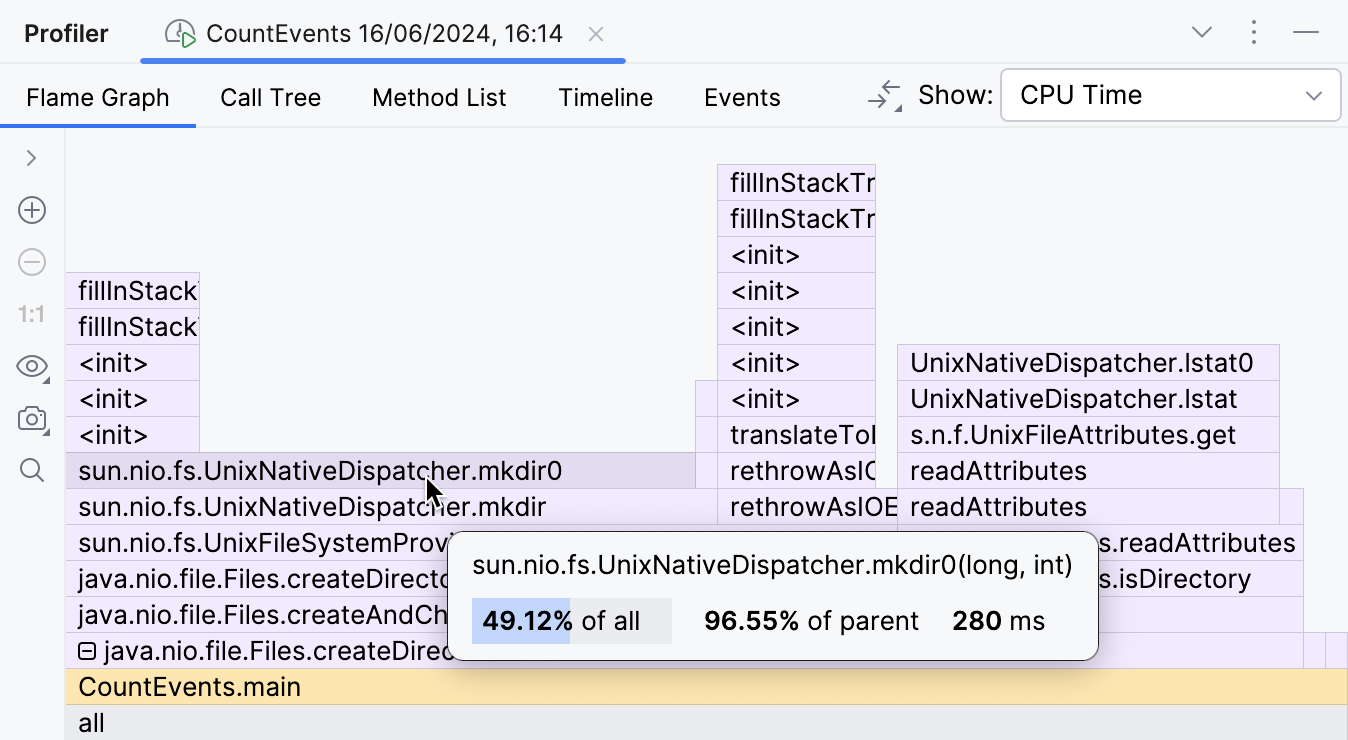
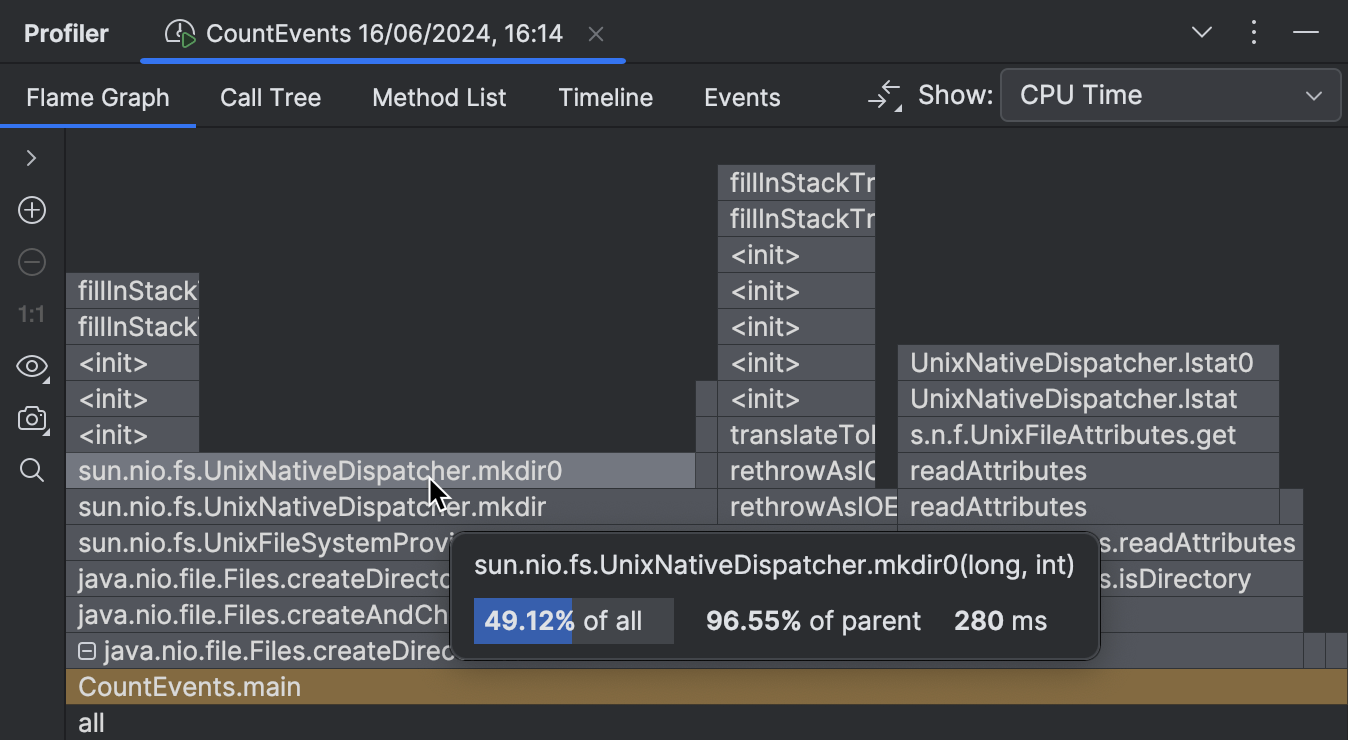
Esta parte do gráfico de chamas mostra que o principal contribuinte para o tempo de execução de
createDirectories() é
sun.nio.fs.UnixNativeDispatcher.mkdir0 .
Uma grande parte desta moldura não tem nada em cima dela.
Isso é referido como o self-time do método e indica que não há código Java além desse ponto.
Pode haver código nativo, no entanto.
Como estamos tentando criar um diretório, que requer a chamada da API do sistema operacional,
podemos esperar que o self-time do método mkdir seja dominado por chamadas nativas.
O UnixNativeDispatcher no nome da classe parece confirmar isso.
Vamos habilitar a criação de perfil nativa Settings | Build, Execution, Deployment | Java Profiler | Collect native calls:
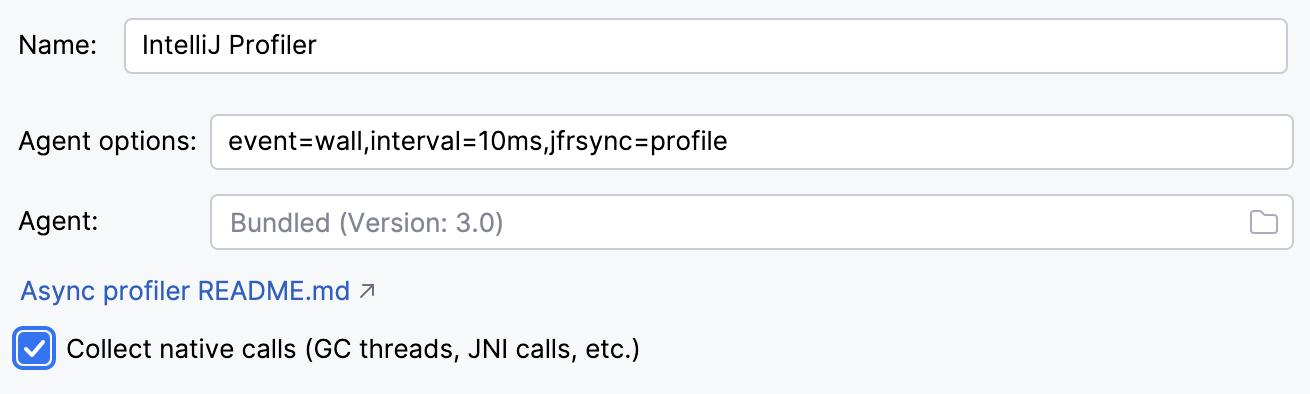
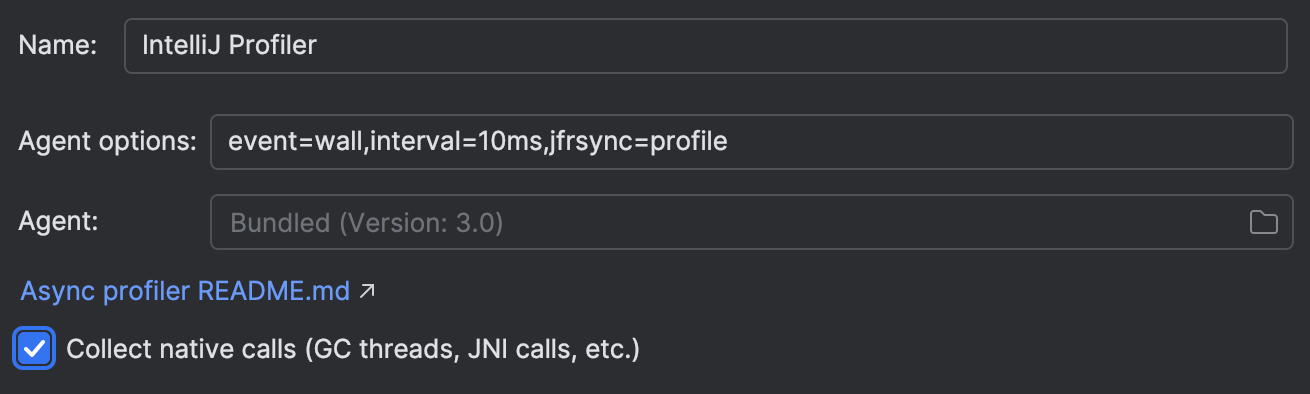
Executar novamente a aplicação com a criação de perfil nativa ativada mostra-nos a imagem completa:

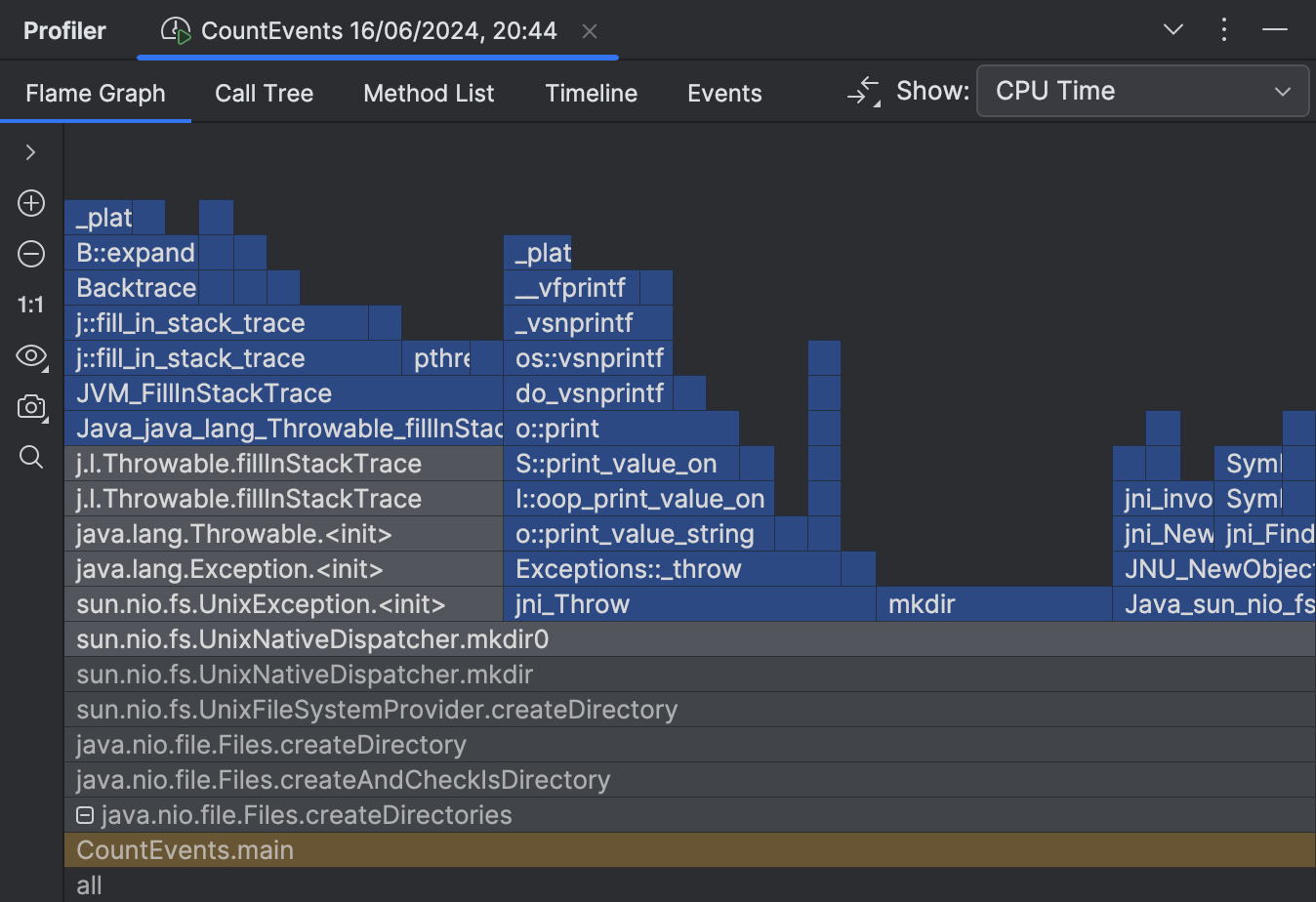
Aqui está o problema. A documentação para o método createDirectories() diz:
Creates a directory by creating all nonexistent parent directories first.
Unlike the createDirectory method,
an exception is not thrown if the directory could not be created because it already exists.
A descrição é válida a partir da perspectiva de Java, pois não levanta quaisquer excepções de Java. No entanto, ao tentar criar uma diretoria que já existe, as exceções são lançadas ao nível do sistema operacional. Isso leva a um desperdício significativo de recursos em nosso cenário.
Vamos tentar evitar isso e envolver a chamada para createDirectories()
em uma verificação Files.exists() :
Path p = Paths.get("./a/b");
if (!Files.exists(p)) {
Files.createDirectories(p);
}O programa se torna muito mais rápido!
Average count: 50000 op
Spent time: 87 msAgora é aproximadamente 16 vezes mais rápido do que era originalmente. Este tratamento de exceção era realmente caro! Os resultados podem variar dependendo do hardware e do ambiente, mas eles devem ser impressionantes de qualquer maneira.
Diferença de snapshots
Se você estiver usando o IntelliJ Profiler, há uma ferramenta útil que permite comparar visualmente dois snapshots. Para uma explicação detalhada e passos, eu recomendo se referir à documentação. Aqui está uma breve descrição dos resultados que a diferença mostra:

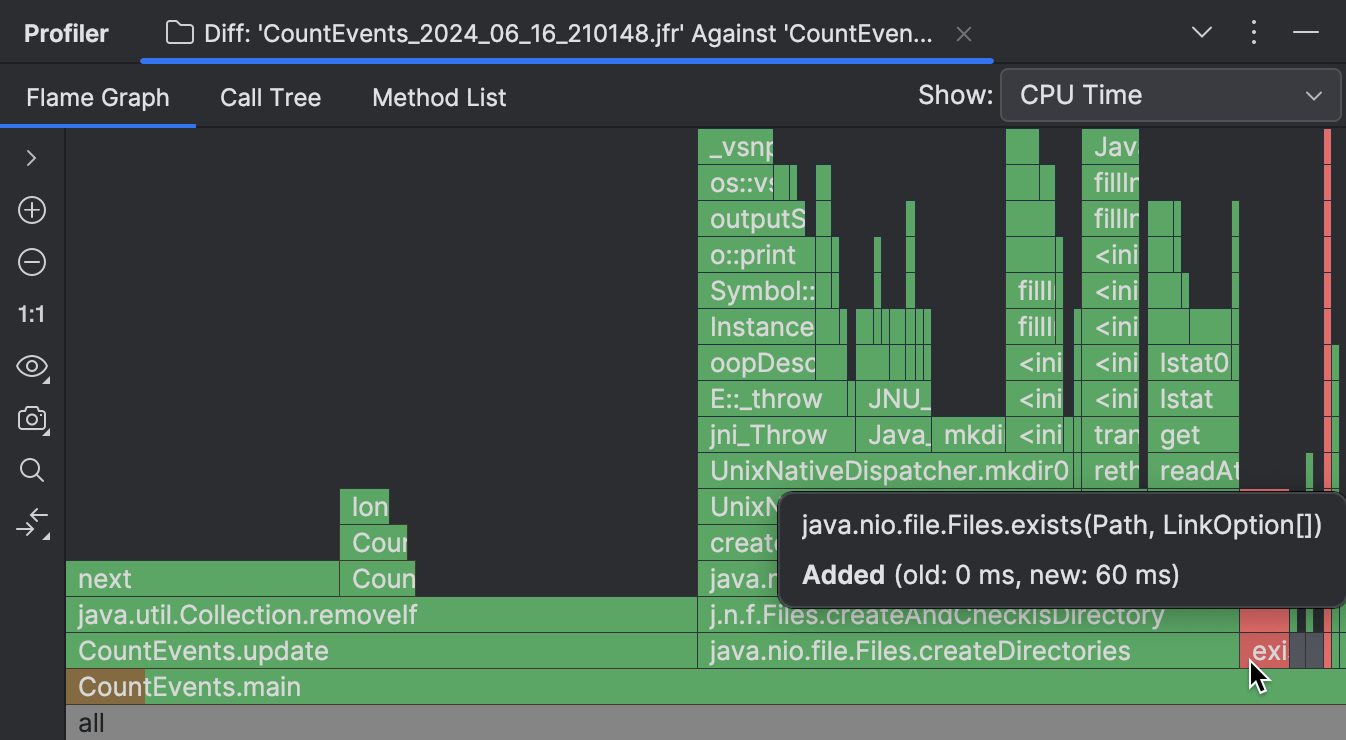
As molduras que faltam no novo snapshot são realçadas em verde, enquanto as novas são coloridas de vermelho. Se uma moldura tem várias cores, isso significa que a moldura está presente em ambos os snapshots, mas seu tempo de execução geral mudou.
Como visível na captura de tela acima, a grande maioria das operações inicialmente realizadas pelo nosso programa
eram desnecessárias, e fomos capazes de eliminá-las.
CountEvents.update() está completamente verde, o que significa
que nossa primeira mudança resultou em uma melhoria quase completa no tempo de execução do método.
Adicionando Files.exists() não foi uma melhoria de 100%, mas isso
removeu efetivamente createDirectories() do snapshot,
adicionando apenas 60 ms ao tempo de execução do programa.
Conclusão
Neste cenário, usamos um profiler para detectar e corrigir um problema de performance. Também testemunhamos como mesmo uma API bem conhecida pode ter implicações que afetam seriamente os tempos de execução de um programa Java. Isso nos mostra por que a criação de perfil é uma habilidade útil, mesmo se você não estiver otimizando para milhões de transações por segundo.
Nos próximos artigos, consideraremos mais casos de uso e técnicas de criação de perfil. Fique ligado!