Solução de Problemas de Lentidão do Depurador
Outras línguas: English Español Français Deutsch 日本語 한국어 中文
Geralmente, a sobrecarga do depurador Java é mínima. No entanto, ainda pode incorrer em custos de tempo de execução significativos em determinadas circunstâncias. Em um cenário especialmente azarado, o depurador pode até congelar completamente a VM.

Vamos examinar as razões por trás desses problemas e suas possíveis soluções.

Eu estou usando IntelliJ IDEA. Os detalhes específicos apresentados neste artigo podem variar em outras IDEs, e alguns dos recursos mencionados podem não estar disponíveis lá. No entanto, a estratégia geral de solução de problemas ainda deve ser aplicada.
Diagnóstico da causa
Antes de explorar as soluções, é sábio identificar o problema. As razões mais comuns para o depurador desacelerar o aplicativo incluem:
- Pontos de interrupção do método
- Avaliação de expressões com muita frequência
- Avaliação de expressões que são computacionalmente pesadas
- Depuração remota com alta latência
O IntelliJ IDEA elimina as suposições nesta etapa, fornecendo estatísticas detalhadas sob a aba Overhead do depurador:

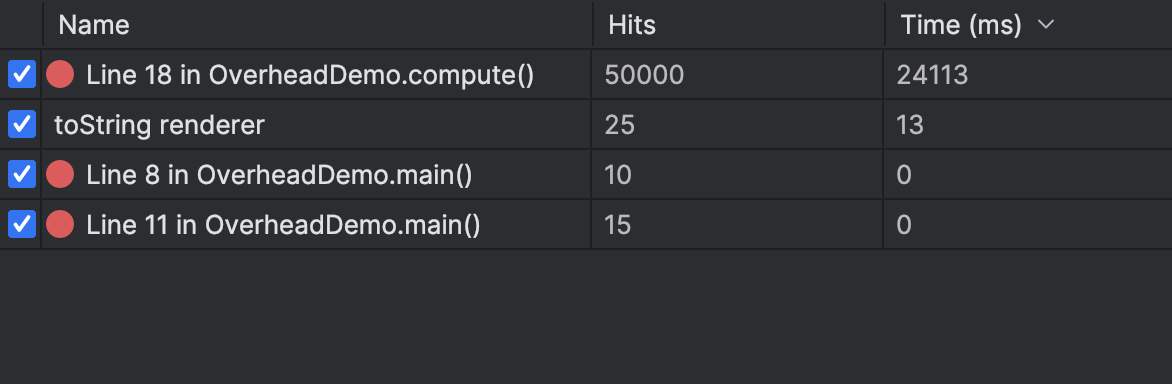
Para acessá-lo, selecione Overhead na aba Layout Settings. Ele mostrará a lista de breakpoints e recursos do depurador. Contra cada breakpoint ou recurso, você verá quantas vezes ele foi usado e a quantidade de tempo que levou para executar.

Se você decidir desligar temporariamente um recurso que consome recursos, você pode fazer isso desmarcando a caixa correspondente na aba Overhead.
Uma vez que identificamos a fonte da lentidão, vamos olhar para as causas mais comuns e como resolvê-las.
Pontos de interrupção do método
Ao usar pontos de interrupção do método no Java, você pode experimentar quedas de desempenho, dependendo do depurador que você está usando. Isso ocorre porque o recurso correspondente fornecido pelo Java Debug Interface é notavelmente lento.
Por esse motivo, o IntelliJ IDEA oferece pontos de interrupção do método emulados. Eles funcionam exatamente como os pontos de interrupção do método real, mas muito mais rápidos. Este recurso envolve um truque nos bastidores: em vez de definir pontos de interrupção do método real, a IDE os substitui por pontos de interrupção de linha regulares dentro todas as implementações do método em todo o projeto.
Por padrão, todos os pontos de interrupção do método no IntelliJ IDEA são emulados:
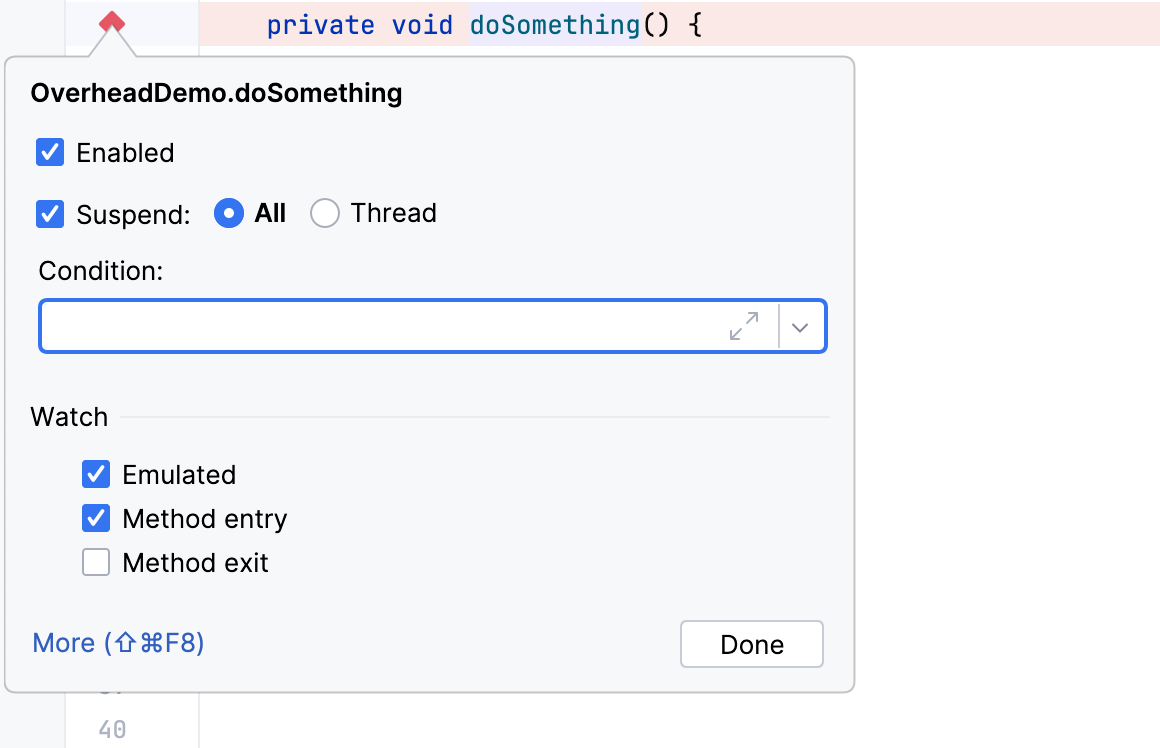
Se você está usando um depurador que não tem esse recurso, e você encontra problemas de desempenho com pontos de interrupção do método, você pode fazer o mesmo truque manualmente. Visitar todas as implementações do método pode ser tedioso, mas também pode economizar tempo durante a depuração.
‘Processing classes for emulated method breakpoints’ demorando muito
Se um método tem um grande número de implementações, a definição um ponto de interrupção de método nele pode levar algum tempo. Nesse caso, o IntelliJ IDEA e o Android Studio mostrarão um diálogo dizendo Processing classes for emulated method breakpoints.
Se isso demorar muito para você, considere usar um ponto de interrupção de linha em vez disso. Alternativamente, você pode trocar algum desempenho de tempo de execução desmarcando a caixa de seleção Emulated nas configurações do ponto de interrupção.
Pontos de interrupção condicionais em código quente
Definir um ponto de interrupção condicional em um código quente pode retardar drasticamente uma sessão de depuração, dependendo de quantas vezes esse código é executado.
Considere a seguinte ilustração:
public class Loop {
public static final int ITERATIONS = 100_000;
public static void main(String[] args) {
var start = System.currentTimeMillis();
var sum = 0;
for (int i = 0; i < ITERATIONS; i++) {
sum += i;
}
var end = System.currentTimeMillis();
System.out.println(sum);
System.out.printf("The loop took: %d ms\n", end - start);
}
}const val ITERATIONS = 100_000
fun main() = measureTimeMillis {
var sum = 0
for (i in 0 until ITERATIONS) {
sum += i
}
println(sum)
}.let { println("The loop took: $it ms") }Vamos colocar um breakpoint em sum += i e especificar
false como a condição.
Isso basicamente significará que o depurador nunca deverá parar neste breakpoint.
Ainda assim, toda vez que esta linha for executada,
o depurador terá que avaliar false .
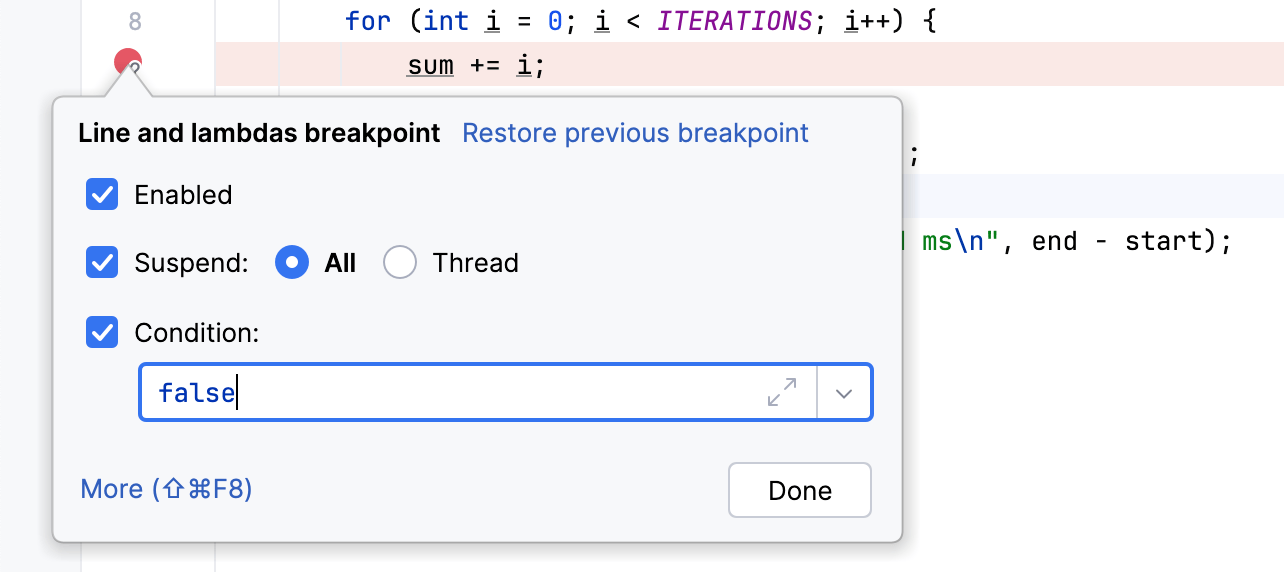
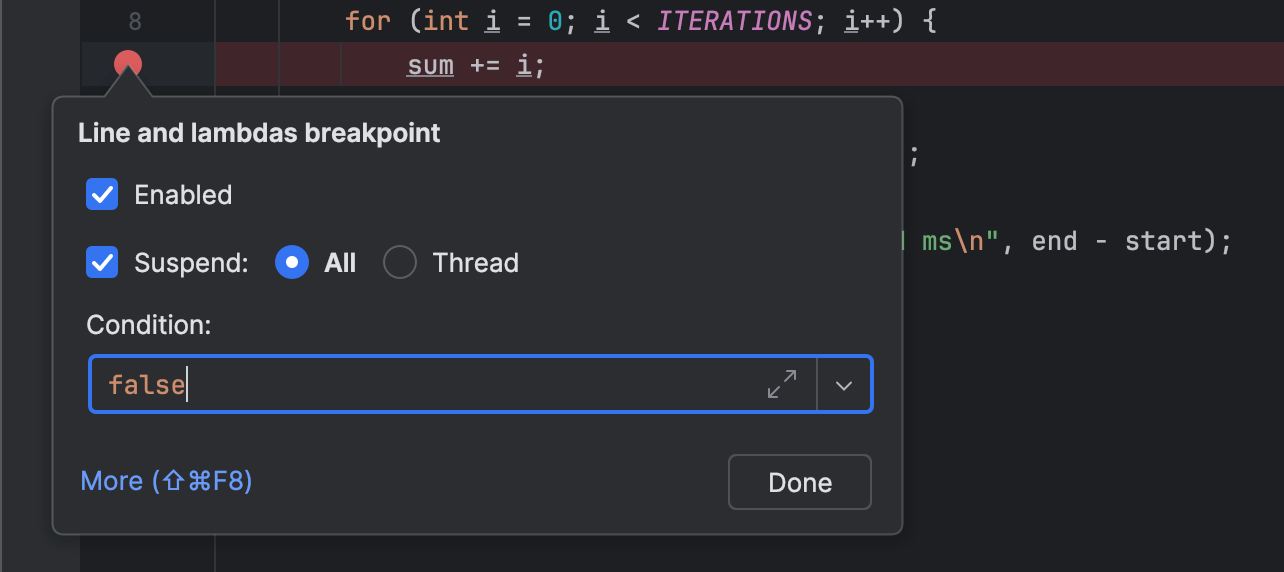
No meu caso, os resultados de rodar este código com e sem o breakpoint foram 39 ms e 29855 ms respectivamente.
Notavelmente, mesmo com apenas 100 mil iterações, a diferença ainda é enorme!
Pode parecer surpreendente que a avaliação de uma condição aparentemente trivial como false
demore tanto tempo.
Isso ocorre porque o tempo decorrido não se deve apenas ao cálculo do resultado da expressão.
Também envolve o manuseio dos eventos do depurador e a comunicação com a interface do depurador.
A solução é simples. Você pode integrar a condição diretamente no código do aplicativo:
public class Loop {
public static final int ITERATIONS = 100_000;
public static void main(String[] args) {
var start = System.currentTimeMillis();
var sum = 0;
for (int i = 0; i < ITERATIONS; i++) {
if (false) { // condition goes here
System.out.println("break") // breakpoint goes here
}
sum += i;
}
var end = System.currentTimeMillis();
System.out.println(sum);
System.out.printf("The loop took: %d ms\n", end - start);
}
}fun main() = measureTimeMillis {
var sum = 0
for (i in 0 until ITERATIONS) {
if (false) { // condition goes here
println("break") // breakpoint goes here
}
sum += i
}
println(sum)
}.let { println("The loop took: $it ms") }Com esta configuração, a VM executará diretamente o código da condição, e pode até mesmo otimizá-lo. O depurador, por outro lado, só entrará em ação ao atingir o breakpoint. Embora não seja necessário na maioria dos casos, essa mudança pode economizar tempo quando você precisa suspender o programa condicionalmente no meio de um caminho quente.
A técnica descrita funciona perfeitamente com classes com código-fonte disponível. No entanto, com o código compilado, como bibliotecas, o truque pode ser mais difícil de realizar. Este é um caso de uso especial, que abordarei em uma discussão separada.
Avaliação implícita
Além dos recursos onde você especifica as expressões você mesmo, como condições de breakpoint e watches, também existem recursos que avaliam as expressões implicitamente para você.
Aqui está um exemplo:
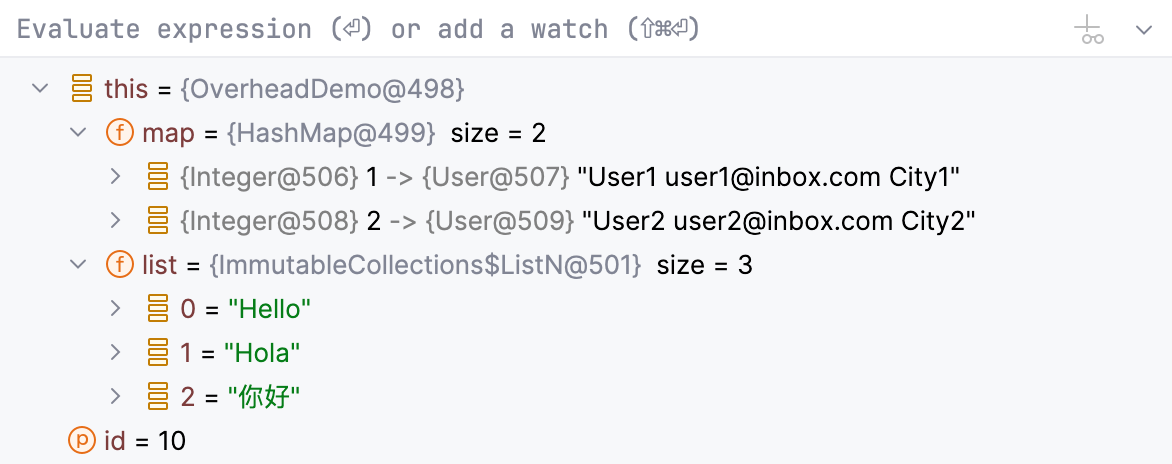
Sempre que você suspende um programa, o depurador exibe os valores das variáveis que estão disponíveis no contexto atual. Alguns tipos podem ter estruturas complexas que são difíceis de visualizar e navegar. Para sua conveniência, o depurador os transforma usando expressões especiais, chamadas renderers.
Os renderers podem ser triviais como toString() ou mais complexos, como aqueles
que transformam o conteúdo das coleções. Eles podem ser integrados ou personalizados.
O depurador da IntelliJ IDEA é muito flexível na forma como exibe seus dados. Ele até permite que você especifique a configuração do renderer através de anotações para fornecer representações consistentes da classe quando vários contribuidores estão trabalhando no mesmo projeto.
Para aprender mais sobre como configurar o formato de exibição dos dados, consulte a documentação da IntelliJ IDEA.
Normalmente, a sobrecarga trazida pelos renderizadores de depuração é desprezível,
mas o impacto depende finalmente do caso de uso específico.
De fato, se algumas das suas implementações de toString() contiverem código para mineração de criptografia,
o depurador terá dificuldade em mostrar o valor toString() para essa classe!
Se a renderização de uma determinada classe se mostrar lenta, você pode desativar o renderer correspondente. Como uma alternativa mais flexível, você pode tornar o renderer sob demanda. Os renderers sob demanda só serão executados quando você solicitar explicitamente para mostrar o resultado deles.
Alta latência nas sessões de depuração remota
Do ponto de vista técnico, depurar um aplicativo remoto não é diferente de uma sessão de depuração local. De qualquer maneira, a conexão é estabelecida via socket - estamos excluindo o modo de memória compartilhada dessa discussão - e o depurador nem mesmo está ciente de onde a JVM hospedeira está sendo executada.
No entanto, um fator que pode ser distinguindo para a depuração remota é a latência da rede. Certos recursos do depurador realizam várias rodadas de rede cada vez que são usados. Combinado com alta latência, isso pode levar a uma degradação de desempenho considerável.
Se esse for o caso, pense em rodar o projeto localmente, pois isso pode economizar tempo. Caso contrário, você pode se beneficiar temporariamente de desativar alguns dos recursos avançados.
Conclusão
Neste artigo, aprendemos como corrigir os problemas mais comuns que causam lentidão no depurador. Embora às vezes a IDE cuidará disso para você, acredito que é importante compreender os mecanismos subjacentes. Isso te torna mais flexível, eficiente e criativo no seu dia-a-dia de depuração.
Espero que você tenha achado essas dicas e truques úteis. Como sempre, seu feedback é muito apreciado! Fique à vontade para me contatar em X, LinkedIn, ou Telegram.
Boa depuração!