Duplikatfinder für Text
Andere Sprachen: English Español Français 日本語 한국어 Português 中文

Jeder, der an technischer Dokumentation in einem großen Team gearbeitet hat, ist sicherlich mit dem Problem der Inhaltsduplizierung vertraut. Selbst mit den besten Werkzeugen und Praktiken ist Duplizierung grundsätzlich schwer zu überwinden.

Mit wachsender Projektgröße werden duplizierte Inhalte auftreten. Dies gilt besonders für große Projekte mit vielen ähnlichen Produkten oder Funktionen.
<p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p><TroubleshootingNote/><p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>
<!-- same meaning, slightly different wording-->
<p>
In case of problems, consult the troubleshooting guide
or contact support
</p>Die Idee, die gegen Duplizierung spricht, ist allgemein bekannt als DRY-Prinzip. Obwohl es hauptsächlich mit Programmierung assoziiert wird, ist dieselbe Eigenschaft in der Dokumentation hoch geschätzt.
Projektvorstellung
Moderne Autorenwerkzeuge haben typischerweise Funktionen zur Inhaltswiederverwendung, wodurch technische Einschränkungen weniger ein Problem sind. Das eigentliche Problem liegt jedoch im Aufspüren von Duplikaten. Bevor du etwas in einen wiederverwendbaren Baustein extrahierst, musst du wissen, was du extrahieren sollst.
Wenn du Programmierer bist, könnte deine IDE duplizierten Code für dich hervorheben:
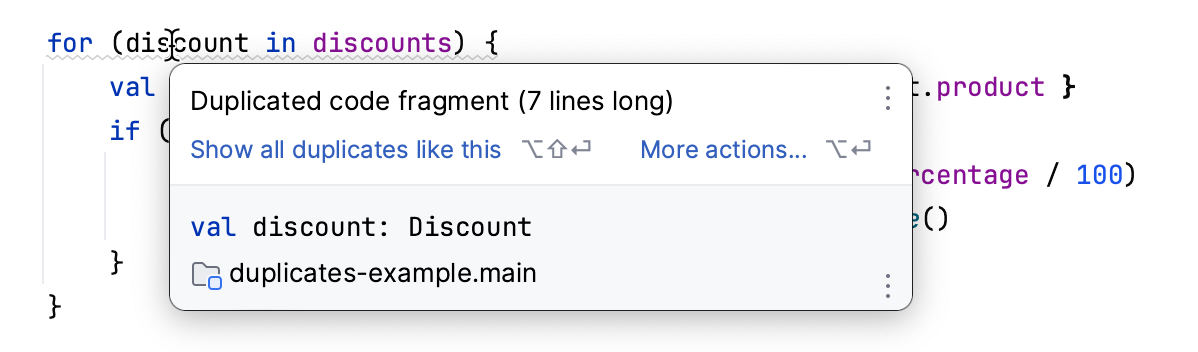
Leider ist dieselbe Funktion nicht für Dokumentation geeignet, da sie auf dem Vergleich abstrakter Syntaxbäume (AST) beruht. Dieser Ansatz funktioniert nicht gut mit Text.
Eines meiner laufenden Projekte ist die Implementierung eines Duplikatfinders für Dokumentation. Das Tool wird in der Lage sein, schnell nicht-exakte, oder unscharfe, Übereinstimmungen zu finden, wie das schlechte Beispiel oben.
Aktueller Status
Zum Zeitpunkt dieses Schreibens ist das Projekt WIP, aber es gibt bereits einen funktionierenden Prototyp:
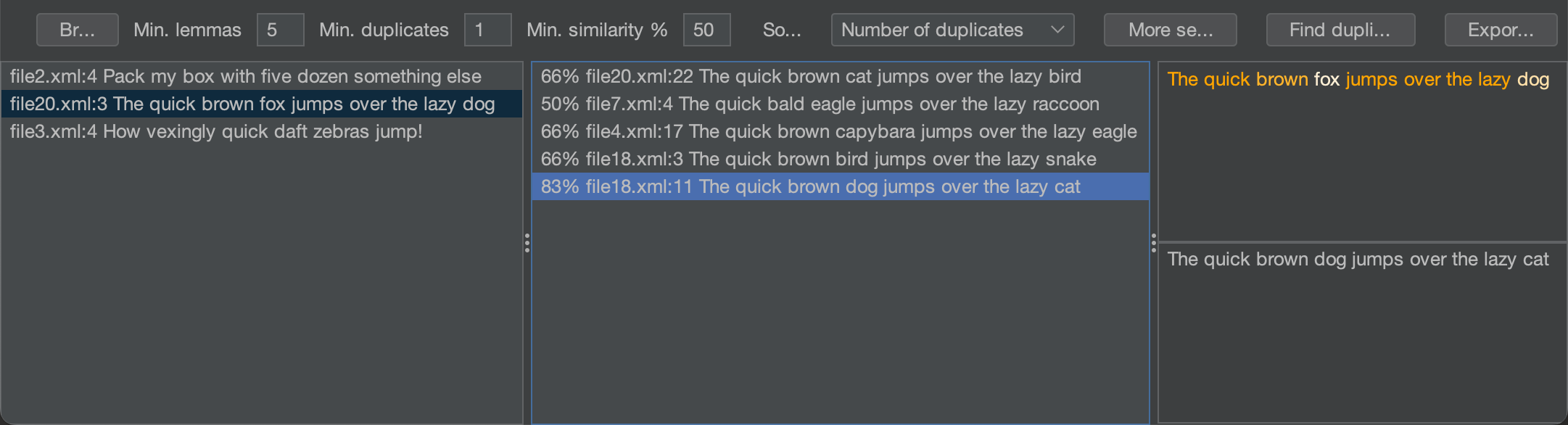
Der Algorithmus braucht weniger als 30 Sekunden, um ein Projekt mit ~6k Quelldateien auf meinem MBP M1 zu analysieren, und ich plane, ihn so zu verbessern, dass er Duplikate sofort hervorhebt, während du im Editor tippst.
Der Prototyp hat mir und meinen Kollegen bereits geholfen, viele Duplikate in echten Projekten zu finden, daher bin ich ziemlich enthusiastisch über die Ergebnisse und zukünftigen Verbesserungen.
Was kommt als Nächstes
In den folgenden Beiträgen werde ich den Algorithmus Schritt für Schritt darlegen und Benchmarks durchführen, um seine Leistung zu bewerten. Wenn du dich für Programmierung interessierst, bist du eingeladen, mitzuprogrammieren.
Alternativ kannst du den Fortschritt im Auge behalten und das fertige Produkt verwenden, wenn das Projekt abgeschlossen ist. Sobald fertig, wird diese Funktion in Writerside verfügbar sein, einem großartigen Autorenwerkzeug, das von meinen Kollegen entwickelt wurde.
Ich hoffe, dass die Projektbeschreibung bei dir Anklang findet und dass du die Anleitung nützlich findest.
Wir sehen uns in den nächsten Beiträgen!