テキスト用重複ファインダー
他の言語: EnglishEspañolFrançaisDeutsch한국어Português中文
大規模チームで技術文書を作成したことのある人であれば、コンテンツの重複問題は確実に認識しているでしょう。 最良のツールと実践を用いても、重複は基本的には克服が難しい。
プロジェクトが大きくなるにつれて、重複コンテンツが発生し始めます。 これは、多数の類似した製品や機能を含む大規模プロジェクトに特に当てはまります。
<p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p><TroubleshootingNote/><p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>
<!-- same meaning, slightly different wording-->
<p>
In case of problems, consult the troubleshooting guide
or contact support
</p>重複に反対する考え方は、一般的に DRY原則 として知られています。 これは主にプログラミングと関連していますが、ドキュメンテーションでも同じ性質が高く評価されています。
プロジェクト紹介
現代の著作ツールは通常、コンテンツの再利用機能を持っており、技術的制約はそれほど心配する必要はありません。 一方、実際の問題は、重複を見つけることにあります。 何かを再利用可能な部分に抽出する前に、何を抽出するかを知る必要があります。
プログラマーであれば、IDEが重複コードをハイライトしてくれるかもしれません:
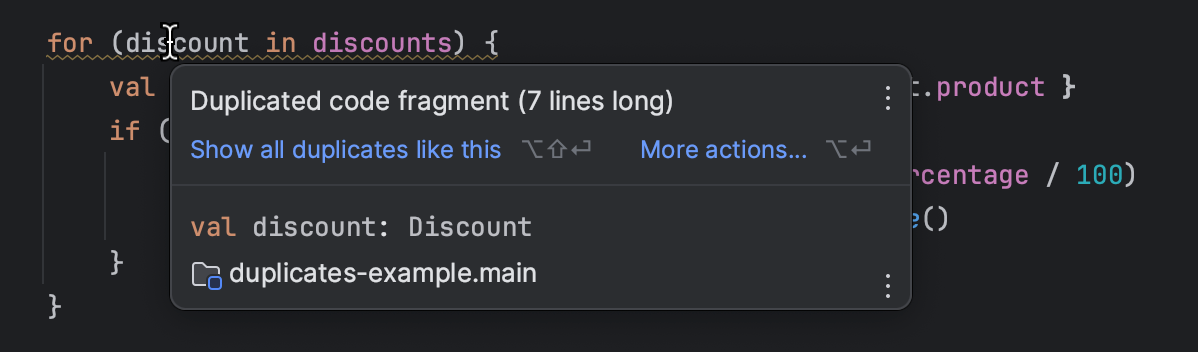
残念ながら、この機能はドキュメンテーションには適しておらず、 抽象構文木(AST)の比較に依存しています。 このアプローチはテキストにはあまり適していません。
私が進行中のプロジェクトの一つは、ドキュメンテーションのための重複ファインダーを実装することです。 このツールは、非完全マッチ、または「ぼやけた」マッチを素早く見つける能力があります。例えば、 上記の悪い例です。
現状
この文章を書いている時点で、プロジェクトは進行中ですが、すでに動作するプロトタイプがあります:
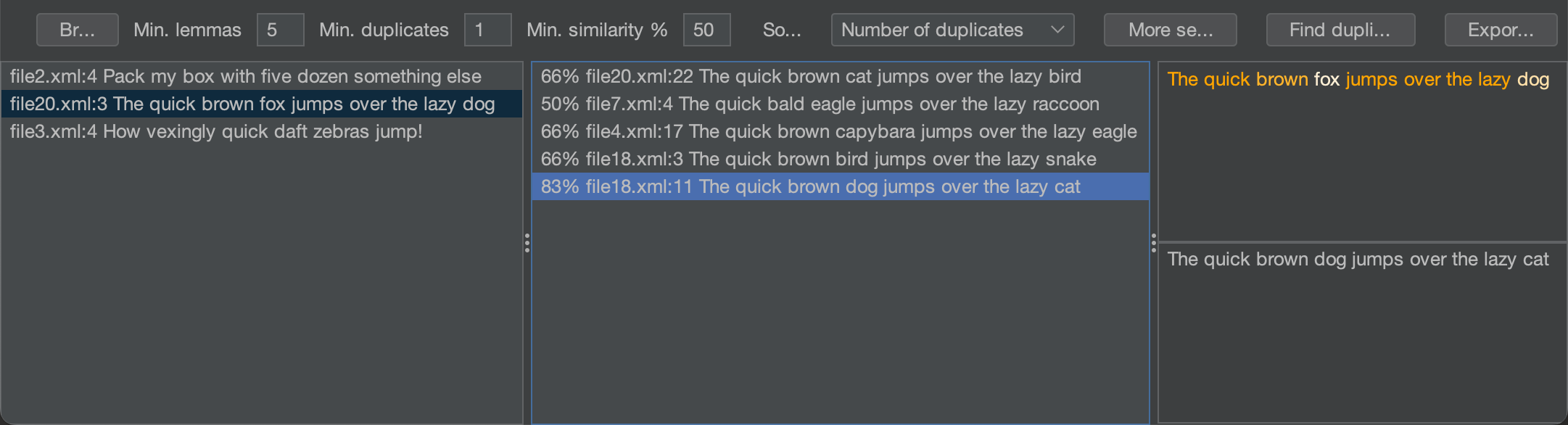
このアルゴリズムは、私のMBP M1で~6kのソースファイルを持つプロジェクトを分析するのに30秒未満しかかかりませんし、エディタで入力するとすぐに重複をハイライトするように改善する予定です。
プロトタイプはすでに、私と私の同僚が実際のプロジェクトで多くの重複を見つけるのに役立ちましたので、結果や今後の改善に非常に期待しています。
What’s next
次のポストでは、アルゴリズムを一歩ずつ説明し、パフォーマンスを評価するためのベンチマークを行います。 もしプログラミングが好きなら、一緒にコードを書いてみることができます。
あるいは、進行を追いかけて、プロジェクトが完成したときに最終的な製品を使用することもできます。 完了したら、この機能はWriterside、 私の同僚が作成した素晴らしい著作ツールで利用可能になります。
プロジェクトの説明が皆さんに共鳴し、ウォークスルーが役立つことを願っています。
次の投稿でお会いしましょう!