Duplikatfinder für Text: Anforderungen
Andere Sprachen: English Español Français 日本語 한국어 Português 中文

Es ist eine Weile her, seit ich die Einführung zum Duplikatfinder-Projekt veröffentlicht habe, daher ist es höchste Zeit, Fortschritte dazu zu liefern. Bevor wir anfangen, den Programmcode zu schreiben, ist es sinnvoll, zuerst die Anforderungen festzulegen. Ein guter Weg, dies zu tun, ist das Schreiben von Tests. Die Tests werden uns nicht nur helfen, schneller zu entwickeln, sondern auch sicherstellen, dass der Code der Spezifikation entspricht.

Anforderungen
In diesem Abschnitt habe ich meine Vorstellung von den Kernfunktionen des Duplikatfinders formuliert. Diese funktionieren gut für meine Anwendungsfälle. Da jedoch jedes Projekt unterschiedliche Bedürfnisse haben könnte, würde ich mich freuen, deine Ideen zu hören und umzusetzen.
Erkennung sowohl exakter als auch unscharfer Übereinstimmungen
Das Duplikaterkennungstool sollte in der Lage sein, sowohl exakte als auch unscharfe Übereinstimmungen mit Granularität bis hin zu einzelnen Zeichen zu finden. Zum Beispiel sollte es die folgenden Texte als ähnlich identifizieren:
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.Zusätzlich sollte bei unscharfen Duplikaten der Grad der Ähnlichkeit messbar sein. Dies würde es uns ermöglichen, die Duplikatpaare schnell zu bewerten und sie danach zu sortieren, wie ähnlich sich die Textfragmente sind.
Sprachunabhängig
Angesichts der Vielzahl potenzieller Zielsprachen wäre es schön, so viele wie möglich zu unterstützen. Einige Ansätze könnten separate Wartung für jede hinzugefügte Sprache erfordern, was überhaupt nicht skalierbar ist und viele Ressourcen benötigt. Idealerweise sollte das Tool eine Heuristik oder einen sprachunabhängigen Algorithmus für Kompatibilität mit jeder gängigen Sprache verwenden.
Konfigurierbar
Die Kriterien zur Identifizierung von Duplikaten sollten anpassbar sein, mit Einstellungen wie:
- die Länge der analysierten Textfragmente
- die Anzahl der Duplikate
- der Grad der Ähnlichkeit
Generell gilt: Je länger und häufiger ein Abschnitt wiederholt wird, desto vorteilhafter ist es, ihn zu deduplizieren. Es hängt jedoch letztendlich von der jeweiligen Anwendung ab, daher wäre es schön, Kontrolle über diese Schwellenwerte zu haben.
Definitionen
Mit den grundlegenden Anforderungen geklärt, ist es Zeit, Code-Definitionen aufzustellen. In dieser Phase benötigen wir:
- die grundlegende Texteinheit, die potenzielle Duplikate repräsentieren wird
- die Schnittstelle für den Duplikatfinder
Der Code in diesem Kapitel muss nicht vollständig sein und jeden zukünftigen Anwendungsfall abdecken – wir können jederzeit für Anpassungen zurückkommen.
Chunk
Wenn es um eine Texteinheit geht, welche Details sind für uns wichtig? Für unsere Zwecke würde ich beim Text, den ein Fragment enthält, dem Pfad zur enthaltenden Datei, seiner Zeilennummer und dem Typ des Elements bleiben – falls die Quelle nicht nur reiner Text ist:
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)Diese Definition berücksichtigt einige Nuancen nicht. Zum Beispiel könnten wir das
content -Feld weglassen.
Das würde uns etwas RAM sparen, aber der Kompromiss wäre die Geschwindigkeit beim Zugriff auf den Inhalt des Elements,
weil dann das Programm ihn jedes Mal von der Festplatte lesen müsste, anstatt nur einmal.
Wir kämpfen gerade nicht um Performance, daher ist eine potenziell suboptimale Wahl in Ordnung.
Schnittstelle
Wir haben noch keine Implementierung, also programmieren wir gegen eine Schnittstelle. Die Schnittstelle definiert, was unsere Funktion als Eingabe nehmen und was sie als Ausgabe zurückgeben soll, wobei die Interna der Funktion abstrahiert werden. Dies erstellt effektiv einen Vertrag, der es uns ermöglicht, Tests jetzt zu schreiben, ohne den eigentlichen Algorithmus zu programmieren. In Zukunft wird die Schnittstelle auch alternative Implementierungen mit den bestehenden Tests und dem Client-Code kompatibel machen.
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}Hier ist die Bedeutung der Parameter, die die Schnittstelle akzeptiert:
-
root– der Ordner mit dem zu analysierenden Inhalt -
minSimilarity– der minimale Prozentsatz der Ähnlichkeit, damit zweiChunk-Objekte als Duplikate betrachtet werden -
minLength– minimalecontent-Länge, damit einChunkanalysiert wird -
minDuplicates– minimale Anzahl von Duplikaten, damit ein Cluster von Duplikaten gemeldet wird -
fileExtensions– Dateierweiterungs-Maske zum Herausfiltern irrelevanter Dateien
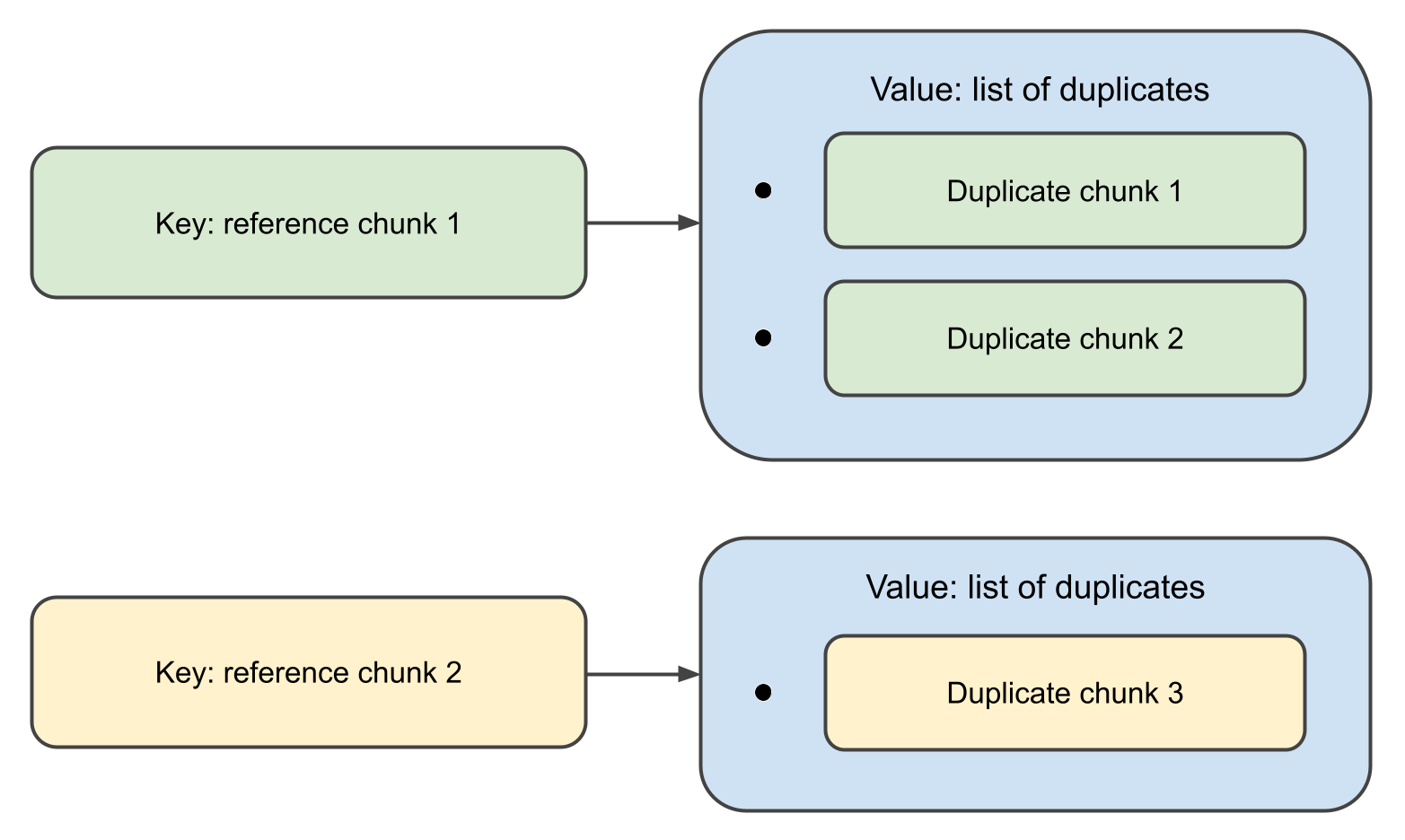
Wenn die Funktion abgeschlossen ist, gibt sie eine Map zurück,
bei der die Schlüssel Chunk -Objekte sind und die zugehörigen Werte Listen ihrer Duplikate.
Tatsächlich ist die obige Definition unnötig ausführlich. Eine Schnittstelle nur für eine einzige Funktion und ein paar Aufrufer einzuführen, ist zu viel. Kotlin hat eine elegante Art, dies mit First-Class-Funktionen zu handhaben:
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()Diese Deklaration bedeutet, dass der Duplikatfinder eine Funktion ist, die
Path, DuplicateFinderOptions nimmt und
Map<Chunk, List<Chunk>> ausgibt,
und dass die Funktion selbst noch nicht implementiert ist.
Das ist vielleicht nicht der beste Stil für große Projekte, aber in kleineren wie unserem
funktioniert es großartig.
Testdaten
Da der Duplikatfinder mit Textdaten arbeiten soll, werden die Tests auch einige Texte zum Analysieren benötigen. Das bedeutet, wir müssen einige Beispiele vorbereiten, die unscharfe Duplikate enthalten. Fangen wir mit den Duplikaten an:
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes."Die Idee hinter FUZZY_MATCH_TEMPLATE
ist, dass wir es verwenden werden, um die tatsächlichen unscharfen Übereinstimmungen programmatisch zu erzeugen:
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)Als nächstes generieren wir einen Text, der aus zufälligen englischen Wörtern besteht:
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}Schließlich injizieren wir zufällig EXACT_MATCH
und fuzzyMatches in den generierten Text:
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}Tests
Wie bereits erwähnt, ist das Hauptziel der Tests in dieser Phase, die Spezifikation zu definieren, also verschwenden wir nicht zu viel Zeit mit der Perfektionierung der Test-Suite. Stattdessen schreiben wir gerade genug, um sicherzustellen, dass der zukünftige Code den Anforderungen entspricht.
Dies ist der Code der Testklasse:
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }Nächste Schritte
Wir haben die Anforderungen etabliert, indem wir die Schnittstelle definiert und die Tests geschrieben haben. Im nächsten Beitrag der Serie werden wir den eigentlichen Algorithmus implementieren und sehen, wie gut er funktioniert. Bis bald!