テキスト向け重複検出器: 要件
他の言語: EnglishEspañolFrançaisDeutsch한국어Português中文
重複検出プロジェクトへのイントロを公開してからしばらく時間が経ちましたので、その進捗状況をお知らせする時が来たようです。 プログラムコードを書き始める前に、まずは要件を明確にすることが重要です。 これを行ういい方法は、テストを書くことです。 テストは私たちがより迅速に開発を進めるだけでなく、コードが仕様に沿っていることも保証します。
要件
本セクションでは、重複検出の核心となる機能についての私の考えをまとめています。 これらの機能は、私のアプリケーションにとって非常に有効です。 しかし、各プロジェクトは異なるニーズを持つ可能性があるため、皆さんのアイデアを聞いて実装することも喜んで行います。
完全一致とファジー一致の両方を検出
重複検出ツールは、完全一致とファジー一致の両方を個別の記号までの粒度で見つける能力が必要です。 例えば、以下のテキストを類似していると特定するべきです:
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.さらに、ファジーな重複の場合、類似性の程度を測定できることが望ましいです。 これにより、重複ペアを迅速に評価し、テキストの断片が互いにどれだけ似ているかによってそれらを並べ替えることができます。
言語に依存しない
対象となる言語の多様性を考えると、できるだけ多くの言語をサポートすることが望ましいです。 一部のアプローチでは、追加される言語ごとに個別にメンテナンスが必要になる場合があり、これは全くスケーラビリティがなく、多くのリソースを必要とします。 理想的には、ツールは何らかのヒューリスティックや言語に依存しないアルゴリズムを使用し、一般的な任意の言語と互換性を持つべきです。
可設定
重複を識別するための基準は調整可能であるべきであり、設定は以下のようなものです:
- 分析されるテキスト断片の長さ
- 重複の数
- 類似度の程度
基本的に、セクションが長くて頻繁に繰り返されるほど、それを重複排除することが有益です。 しかし、これは具体的なアプリケーションによるため、これらのしきい値を自由に設定できると良いでしょう。
定義
基本的な要件が整理されたところで、コードの定義を整える時です。 この段階では、以下のものが必要です:
この章のコードは、将来の全ての使用ケースを網羅する必要はありません。 必要に応じて後から調整を行うこともできます。
チャンク
テキストの単位となるものについて、どの詳細が重要でしょうか? 我々の目的のために、フラグメントが含むテキスト、そのフラグメントが含まれるファイルへのパス、行番号、そして要素の型(ソースが単純なテキストでない場合)を基本としましょう:
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)この定義は一部のニュアンスを考慮に入れていません。たとえば、 content フィールドを省略する可能性があります。
これによりRAMを節約することができますが、トレードオフは要素のコンテンツにアクセスする速度となります。それぞれのプログラムはコンテンツをディスクから読み込む必要があります。我々は現在、パフォーマンスを求めていないので、潜在的に最適でない選択でも問題ありません。
インターフェース
まだ実装がないので、インターフェースに対してプログラムを書きます。 インターフェースは関数が入力として何を受け取り、出力として何を返すべきかを定義し、関数の内部を抽象化します。 これは効果的に契約を作り、テストをすぐに書くことができ、実際のアルゴリズムのコードを書く必要はありません。 将来的には、インターフェースは既存のテストとクライアントコードと互換性のある代替実装を可能にします。
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}インターフェースが受け付けるパラメータの意味は次の通りです:
-
root– 分析するコンテンツがあるフォルダ -
minSimilarity– 2つのChunkオブジェクトが重複とみなされるための最小類似性のパーセンテージ -
minLength–Chunkの分析対象とするための最小contentの長さ -
minDuplicates– 重複のクラスタが報告されるための最小の重複数 -
fileExtensions– 関連のないファイルをフィルタリングするためのファイル拡張子マスク
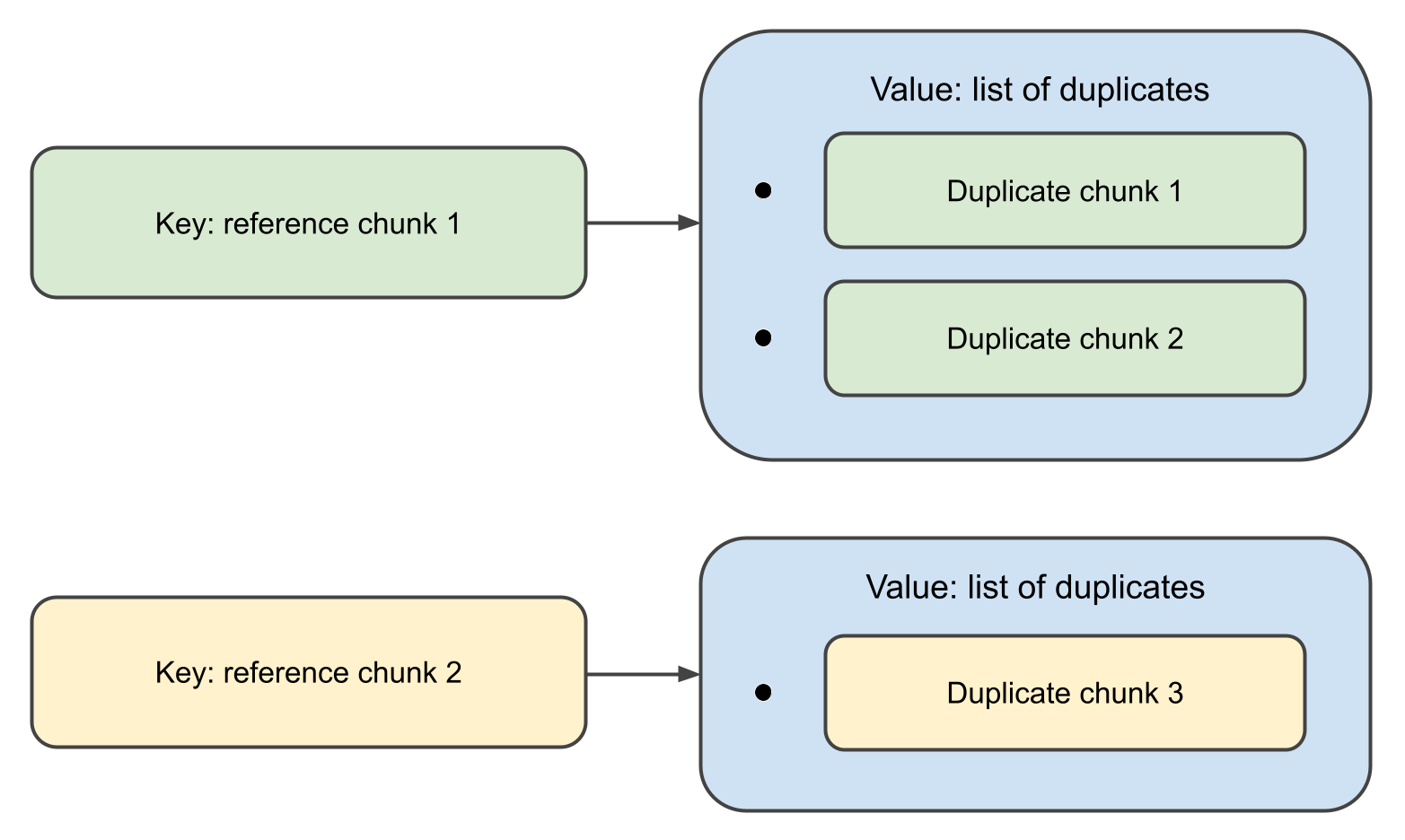
関数が完了すると、マップを返します、
ここでキーは Chunk オブジェクト、関連する値はその重複のリストです。
実際には、上記の定義は不必要に詳細です。 1つの関数といくつかの呼び出しのためだけにインターフェースを導入することは過剰です。 Kotlinには、第一級関数を活用してこの問題をエレガントに解決する方法があります:
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()この宣言は、重複検出は Path, DuplicateFinderOptions を入力として受け取り、出力として
Map<Chunk, List<Chunk>> を出力する関数であり、その関数自体はまだ実装されていないことを意味します。
このスタイルは大型のプロジェクトでは最適でないかもしれませんが、私たちのような小型のものではとても便利です。
テストデータ
重複検出がテキストデータで動作するものであるため、テストも分析するテキストが必要になります。 これは、ファジーな重複を含む例をいくつか準備する必要があるということです。まず最初に重複を準備しましょう:
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes." FUZZY_MATCH_TEMPLATE の背後にあるアイデアは、それを使用してプログラムで実際のファジーマッチを生成することです:
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)次に、ランダムな英語の単語から成るテキストを生成します:
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}最後に、生成されたテキストにランダムに EXACT_MATCH と fuzzyMatches を挿入します:
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}テスト
すでに述べたように、この段階でのテストの主要な目標は仕様を定義することなので、テストスイートの完璧化に多くの時間を費やすことはしません。 その代わりに、未来のコードが要件を満たしていることを確保するために必要な程度に留めましょう。
テストクラスのコードは以下の通りです:
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }次のステップ
インターフェースを定義し、テストを書くことで要件を確立しました。 このシリーズの次の投稿で、実際のアルゴリズムを実装し、そのパフォーマンスを見てみます。 またお会いしましょう!