Anwendungen mit KI lokalisieren
Andere Sprachen: English Español Français 日本語 한국어 Português 中文
Ob Sie darueber nachdenken, Ihr Projekt zu lokalisieren, oder einfach nur lernen moechten, wie das geht - KI koennte ein guter Anfang sein. Sie bietet einen kosteneffizienten Einstiegspunkt fuer Experimente und Automatisierungen.
In diesem Beitrag werden wir ein solches Experiment durchfuehren. Wir werden:
- eine Open-Source-Anwendung auswaehlen
- die Voraussetzungen pruefen und implementieren
- die Uebersetzungsphase mit KI automatisieren

Wenn Sie noch nie mit Lokalisierung zu tun hatten und es lernen moechten, koennte es eine gute Idee sein, hier zu beginnen. Abgesehen von einigen technischen Details ist der Ansatz weitgehend universell, und Sie koennen ihn auch in anderen Projekttypen anwenden.
Wenn Sie bereits mit den Grundlagen vertraut sind und nur die KI in Aktion sehen moechten, koennen Sie direkt zu Texte uebersetzen springen oder meinen Fork klonen, um die Commits zu ueberpruefen und die Ergebnisse zu bewerten.
Das Projekt holen
Eine Anwendung nur fuer ein Lokalisierungsexperiment zu erstellen, waere uebertrieben, also forken wir ein Open-Source-Projekt. Ich habe Spring Petclinic gewaehlt, eine Beispiel-Webanwendung, die verwendet wird, um das Spring-Framework fuer Java zu praesentieren.
gh repo fork https://github.com/spring-projects/spring-petclinic --clone=trueWenn Sie Spring noch nicht verwendet haben, koennten einige Code-Snippets ungewohnt aussehen, aber wie bereits erwaehnt, ist diese Diskussion technologieunabhaengig. Die Schritte sind im Wesentlichen gleich, unabhaengig von Sprache und Framework.
Internationalisierung
Bevor eine Anwendung lokalisiert werden kann, muss sie internationalisiert werden.
Internationalisierung (auch i18n geschrieben) ist der Prozess der Anpassung von Software zur Unterstuetzung verschiedener Sprachen. Er beginnt normalerweise damit, die UI-Texte in spezielle Dateien auszulagern, die ueblicherweise als Resource Bundles bezeichnet werden.
Resource Bundles enthalten die Textwerte fuer verschiedene Sprachen:
en.json:
{
"greeting": "Hello!",
"farewell": "Goodbye!"
}es.json:
{
"greeting": "¡Hola!",
"farewell": "¡Adiós!"
}Damit diese Werte ihren Weg zur Benutzeroberflaeche finden, muss die UI explizit programmiert werden, diese Dateien zu verwenden.
Dies beinhaltet typischerweise eine Internationalisierungsbibliothek oder ein eingebautes Sprachfeature, dessen Zweck es ist, UI-Texte durch die korrekten Werte fuer eine gegebene Locale zu ersetzen. Beispiele fuer solche Bibliotheken sind i18next (JavaScript), Babel (Python) und go-i18n (Go).
Java unterstuetzt Internationalisierung von Haus aus, daher muessen wir dem Projekt keine zusaetzlichen Abhaengigkeiten hinzufuegen.
Die Quellen untersuchen
Java verwendet Dateien mit der Endung .properties , um lokalisierte Texte fuer die Benutzeroberflaeche zu speichern.
Gluecklicherweise gibt es bereits einige davon im Projekt. Hier ist zum Beispiel, was wir fuer Englisch und Spanisch haben:
welcome=Welcome
required=is required
notFound=has not been found
duplicate=is already in use
nonNumeric=must be all numeric
duplicateFormSubmission=Duplicate form submission is not allowed
typeMismatch.date=invalid date
typeMismatch.birthDate=invalid datewelcome=Bienvenido
required=Es requerido
notFound=No ha sido encontrado
duplicate=Ya se encuentra en uso
nonNumeric=Sólo debe contener numeros
duplicateFormSubmission=No se permite el envío de formularios duplicados
typeMismatch.date=Fecha invalida
typeMismatch.birthDate=Fecha invalidaDas Auslagern von UI-Texten ist nicht etwas, das alle Projekte standardmaessig tun. Einige Projekte haben diese Texte moeglicherweise direkt in der Anwendungslogik fest kodiert.

Das Auslagern von UI-Texten ist eine gute Praxis mit Vorteilen ueber die Internationalisierung hinaus. Es macht den Code wartbarer und foerdert Konsistenz in UI-Meldungen. Wenn Sie ein Projekt starten, sollten Sie i18n so frueh wie moeglich implementieren.
Testlauf
Fuegen wir eine Moeglichkeit hinzu, die Locale ueber URL-Parameter zu aendern. Dies ermoeglicht uns zu testen, ob alles vollstaendig ausgelagert und in mindestens eine Sprache uebersetzt ist.
Um dies zu erreichen, fuegen wir die folgende Klasse hinzu, um den Locale-Parameter zu verwalten:
import java.util.Locale;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public LocaleResolver localeResolver() {
SessionLocaleResolver slr = new SessionLocaleResolver();
slr.setDefaultLocale(Locale.US);
return slr;
}
@Bean
public LocaleChangeInterceptor localeChangeInterceptor() {
LocaleChangeInterceptor lci = new LocaleChangeInterceptor();
lci.setParamName("lang");
return lci;
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(localeChangeInterceptor());
}
}Jetzt, da wir verschiedene Locales testen koennen, starten wir den Server und vergleichen die Startseite fuer verschiedene Locale-Parameter:
- http://localhost:8080 – Standard-Locale
- http://localhost:8080/?lang=es – Spanisch
- http://localhost:8080/?lang=ko – Koreanisch
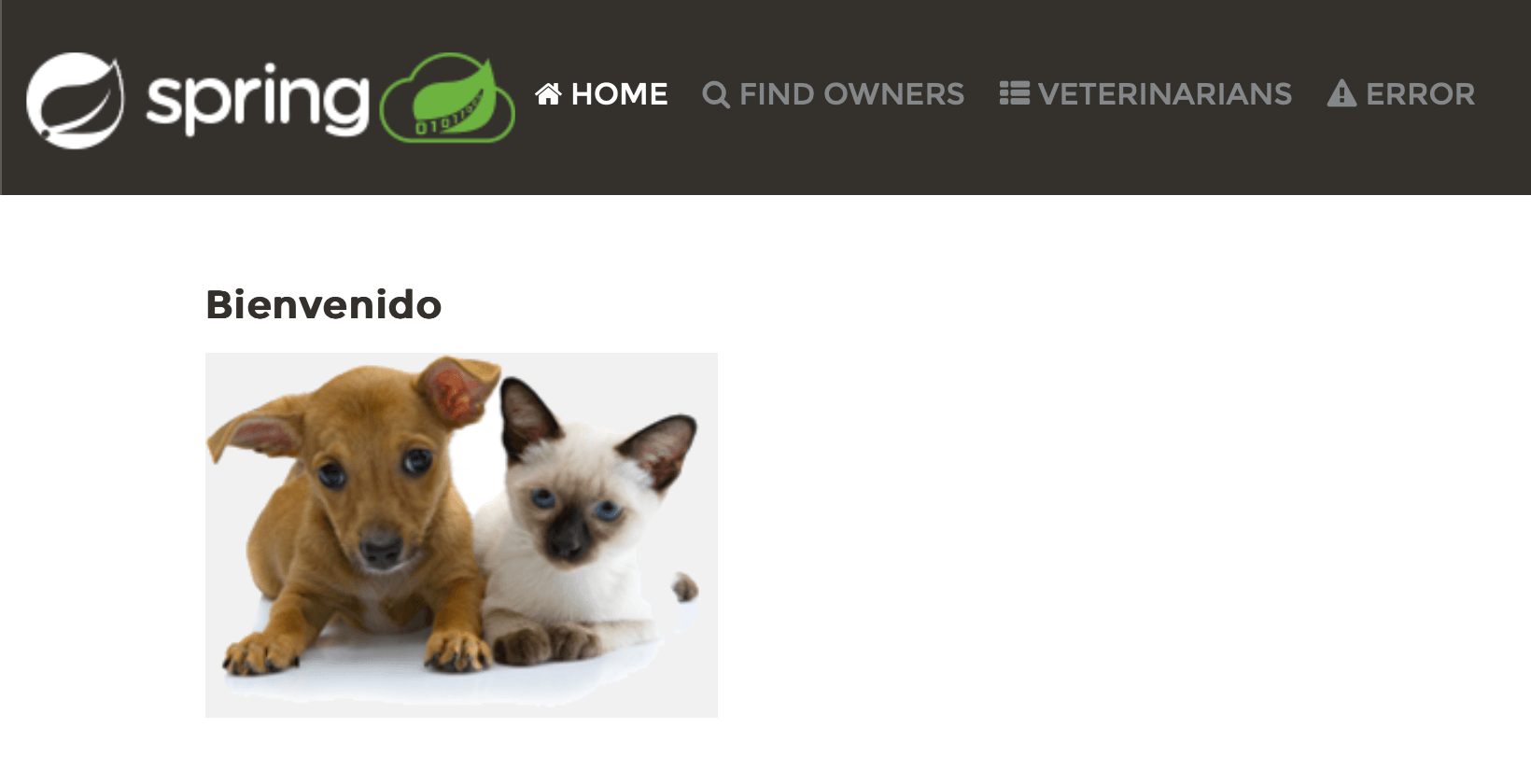
Das Aendern der Locale spiegelt sich in der UI wider, was gute Nachrichten sind. Es scheint jedoch, dass die Aenderung der Locale nur einen Teil der Texte betroffen hat. Fuer Spanisch hat sich Welcome zu Bienvenido geaendert, aber die Links im Header blieben gleich, und die anderen Seiten sind immer noch auf Englisch. Das bedeutet, wir haben etwas Arbeit vor uns.
Templates anpassen
Das Spring Petclinic-Projekt generiert Seiten mit Thymeleaf-Templates, also schauen wir uns die Template-Dateien an.
Tatsaechlich sind einige der Texte fest kodiert, also muessen wir den Code anpassen, um stattdessen auf die Resource Bundles zu verweisen.
Gluecklicherweise hat Thymeleaf gute Unterstuetzung fuer Java .properties -Dateien,
sodass wir Verweise auf die entsprechenden Resource Bundle Keys direkt im Template einbauen koennen:
<h2>Find Owners</h2><h2 th:text='#{heading.find.owners}'>Find Owners</h2>heading.find.owners=Find OwnersDer zuvor fest kodierte Text ist immer noch da, dient aber jetzt als Fallback-Wert, der nur verwendet wird, wenn es einen Fehler beim Abrufen einer ordnungsgemaess lokalisierten Meldung gibt.
Die restlichen Texte werden auf aehnliche Weise ausgelagert; jedoch gibt es mehrere Stellen, die besondere Aufmerksamkeit erfordern. Zum Beispiel kommen einige der Warnungen von der Validierungs-Engine und muessen ueber Java-Annotationsparameter angegeben werden:
@Column(name = "first_name")
@NotBlank
private String firstName;@Column(name = "first_name")
@NotBlank(message = "{field.validation.notblank}")
private String firstName;An einigen Stellen muss die Logik geaendert werden:
<h2>
<th:block th:if="${pet['new']}">New </th:block>Pet
</h2>Im obigen Beispiel verwendet das Template eine Bedingung. Wenn das new -Attribut vorhanden ist, wird New zum UI-Text hinzugefuegt.
Folglich ist der resultierende Text entweder New Pet oder Pet, abhaengig vom Vorhandensein des Attributs.
Dies kann die Lokalisierung fuer einige Locales beeintraechtigen, wegen der Uebereinstimmung
zwischen Substantiv und Adjektiv. Zum Beispiel waere das Adjektiv auf Spanisch
Nuevo oder Nueva ,
abhaengig vom Geschlecht des Substantivs, und die bestehende Logik beruecksichtigt diese Unterscheidung nicht.
Eine moegliche Loesung fuer diese Situation ist, die Logik noch ausgefeilter zu gestalten. Es ist generell eine gute Idee, komplizierte Logik wo moeglich zu vermeiden, also habe ich mich stattdessen fuer die Entkopplung der Zweige entschieden:
<h2>
<th:block th:if="${pet['new']}" th:text="#{pet.new}">New Pet</th:block>
<th:block th:unless="${pet['new']}" th:text="#{pet.update}">Pet</th:block>
</h2>Separate Zweige werden auch den Uebersetzungsprozess und die zukuenftige Wartung der Codebasis vereinfachen.
Das New Pet-Formular hat auch einen Trick. Sein Type-Dropdown wird erstellt, indem die Sammlung von Tierarten an das selectField.html -Template uebergeben wird:
<input th:replace="~{fragments/selectField :: select (#{pet.type}, 'type', ${types})}" />Im Gegensatz zu den anderen UI-Texten sind die Tierarten Teil des Datenmodells der Anwendung. Sie werden zur Laufzeit aus einer Datenbank bezogen. Die dynamische Natur dieser Daten verhindert, dass wir die Texte direkt in ein Property Bundle extrahieren koennen.
Es gibt wieder mehrere Moeglichkeiten, damit umzugehen. Eine Moeglichkeit ist, den Property Bundle Key im Template dynamisch zu konstruieren:
<option th:each="item : ${items}"
th:value="${item}"
th:text="${item}">dog</option><option th:each="item : ${items}"
th:value="${item}"
th:text="#{'pettype.' + ${item}}">dog</option>Bei diesem Ansatz rendern wir nicht direkt cat in der UI, sondern stellen pettype. voran, was zu
pettype.cat fuehrt. Wir verwenden dann diesen String als Schluessel, um den lokalisierten UI-Text abzurufen:
pettype.bird=bird
pettype.cat=cat
pettype.dog=dogpettype.bird=pájaro
pettype.cat=gato
pettype.dog=perro
Sie haben vielleicht bemerkt, dass wir gerade das Template einer wiederverwendbaren Komponente geaendert haben. Da wiederverwendbare Komponenten dazu gedacht sind, mehrere Clients zu bedienen, ist es nicht korrekt, Client-Logik hineinzubringen.
In diesem speziellen Fall wird die Dropdown-Listen-Komponente an Tierarten gebunden, was fuer jeden problematisch ist, der sie fuer etwas anderes verwenden moechte.
Dieser Fehler war von Anfang an da - siehe dog als Standardtext der Optionen.
Wir haben diesen Fehler nur weiter verbreitet.
Dies sollte in echten Projekten nicht getan werden und erfordert Refactoring.
Natuerlich gibt es noch mehr Projektcode zu internationalisieren; jedoch entspricht der Rest groesstenteils den obigen Beispielen. Fuer eine vollstaendige Ueberpruefung aller meiner Aenderungen koennen Sie gerne die Commits in meinem Fork untersuchen.
Fehlende Schluessel hinzufuegen
Nachdem alle UI-Texte durch Verweise auf Property Bundle Keys ersetzt wurden, muessen wir sicherstellen, dass alle diese neuen Schluessel eingefuehrt werden. Wir muessen zu diesem Zeitpunkt nichts uebersetzen, nur die Schluessel und Originaltexte zur messages.properties -Datei hinzufuegen.
IntelliJ IDEA hat gute Thymeleaf-Unterstuetzung. Es erkennt, wenn ein Template auf eine fehlende Property verweist, sodass Sie die fehlenden ohne viel manuelles Pruefen entdecken koennen:
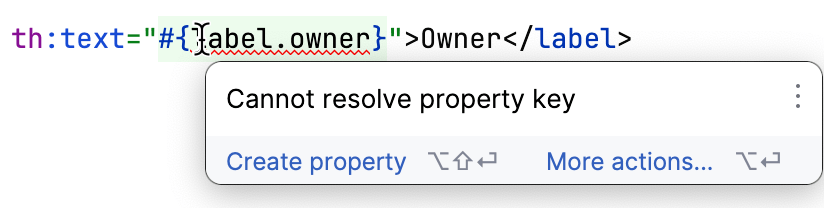
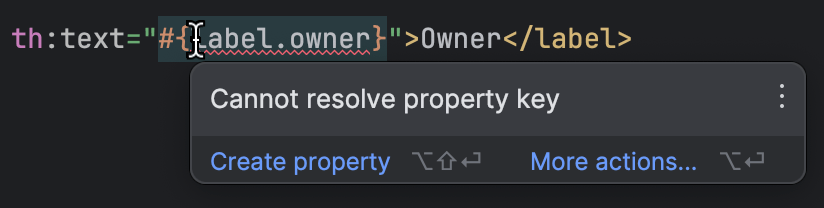
Mit allen Vorbereitungen abgeschlossen kommen wir zum interessantesten Teil der Arbeit. Wir haben alle Schluessel, und wir haben alle Werte fuer Englisch. Woher bekommen wir die Werte fuer die anderen Sprachen?
Texte uebersetzen
Fuer die Uebersetzung der Texte werden wir ein Skript erstellen, das einen externen Uebersetzungsdienst verwendet. Es gibt viele verfuegbare Uebersetzungsdienste und viele Moeglichkeiten, ein solches Skript zu schreiben. Ich habe die folgenden Entscheidungen fuer die Implementierung getroffen:
- Python als Programmiersprache, weil sie es ermoeglicht, kleine Aufgaben wirklich schnell zu programmieren
- DeepL als Uebersetzungsdienst. Urspruenglich hatte ich geplant, OpenAIs GPT3.5 Turbo zu verwenden, aber da es nicht streng genommen ein Uebersetzungsmodell ist, erfordert es zusaetzlichen Aufwand, den Prompt zu konfigurieren. Ausserdem sind die Ergebnisse tendenziell weniger stabil, daher habe ich einen dedizierten Uebersetzungsdienst gewaehlt, der mir als erstes in den Sinn kam
Ich habe keine umfangreiche Recherche betrieben, daher sind diese Entscheidungen etwas willkuerlich. Experimentieren Sie gerne und finden Sie heraus, was am besten zu Ihnen passt.
Wenn Sie das Skript unten verwenden moechten, muessen Sie ein Konto bei DeepL erstellen
und Ihren persoenlichen API-Schluessel dem Skript ueber die DEEPL_KEY -Umgebungsvariable uebergeben
Dies ist das Skript:
import os
import requests
import json
deepl_key = os.getenv('DEEPL_KEY')
properties_directory = "../src/main/resources/messages/"
def extract_properties(text):
properties = {}
for line in text:
line = line.strip()
if line and not line.startswith('#') and '=' in line:
key_value = line.split('=')
key = key_value[0].strip()
value = key_value[1].strip()
if key and value:
properties[key] = value
return properties
def missing_properties(properties_file, properties_checklist):
with open(properties_file, 'r') as f:
text = f.readlines()
present_properties = extract_properties(text)
missing = {k: v for k, v in properties_checklist.items() if k not in present_properties.keys()}
return missing
def translate_property(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'DeepL-Auth-Key {deepl_key}',
'User-Agent': 'LocalizationScript/1.0'
}
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()["translations"][0]["text"]
def populate_properties(file_path, properties_checklist, target_lang):
with open(file_path, 'a+') as file:
properties_to_translate = missing_properties(file_path, properties_checklist)
for key, value in properties_to_translate.items():
new_value = translate_property(value, target_lang)
property_line = f"{key}={new_value}\n"
print(property_line)
file.write(property_line)
with open(properties_directory + 'messages.properties') as base_properties_file:
base_properties = extract_properties(base_properties_file)
languages = [
# configure languages here
"nl", "es", "fr", "de", "it", "pt", "ru", "ja", "zh", "fi"
]
for language in languages:
populate_properties(properties_directory + f"messages_{language}.properties", base_properties, language)
Das Skript extrahiert die Schluessel aus dem Standard-Property-Bundle ( messages.properties ) und sucht nach deren Uebersetzungen in den locale-spezifischen Bundles. Wenn es feststellt, dass einem bestimmten Schluessel eine Uebersetzung fehlt, fordert das Skript die Uebersetzung von der DeepL-API an und fuegt sie dem Property Bundle hinzu.
Ich habe 10 Zielsprachen angegeben, aber Sie koennen die Liste aendern oder Ihre bevorzugten Sprachen hinzufuegen, solange DeepL sie unterstuetzt.
Das Skript kann weiter optimiert werden, um die Texte in Batches von 50 zur Uebersetzung zu senden. Ich habe das hier nicht getan, um die Dinge einfach zu halten.
Spaeter habe ich das Skript aktualisiert, um ein LLM mit strukturierter Ausgabe zu verwenden. Sie koennen die Ergebnisse hier ansehen.
Das Skript ausfuehren
Das Ausfuehren des Skripts ueber 10 Sprachen dauerte bei mir etwa 5 Minuten. Das Nutzungs-Dashboard zeigt 8348 Zeichen an, was 0,16 Euro gekostet haette, wenn wir einen kostenpflichtigen Plan haetten.
Als Ergebnis erscheinen die folgenden Dateien:
- messages_fi.properties
- messages_fr.properties
- messages_it.properties
- messages_ja.properties
- messages_nl.properties
- messages_pt.properties
- messages_ru.properties
- messages_zh.properties
Ausserdem werden fehlende Properties hinzugefuegt zu:
- messages_de.properties
- messages_es.properties
Aber was ist mit den eigentlichen Uebersetzungen? Koennen wir sie schon sehen?
Die Ergebnisse pruefen
Starten wir die Anwendung neu und testen sie mit verschiedenen lang -Parameterwerten. Zum Beispiel:
- http://localhost:8080/?lang=es
- http://localhost:8080/?lang=nl
- http://localhost:8080/?lang=zh
- http://localhost:8080/?lang=fr
Persoenlich finde ich es sehr befriedigend, jede Seite korrekt lokalisiert zu sehen. Wir haben etwas Aufwand investiert, und jetzt zahlt es sich aus:

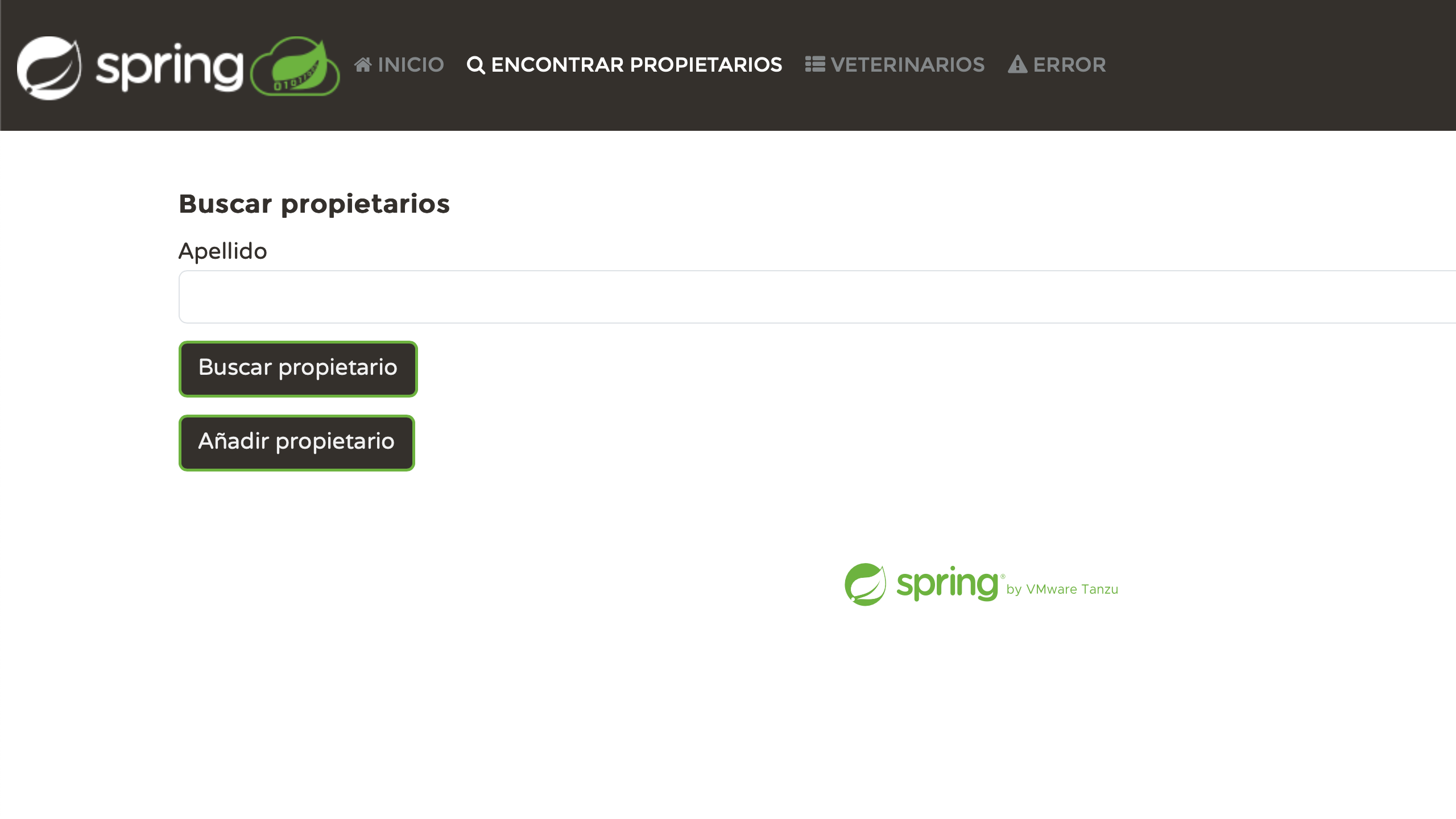
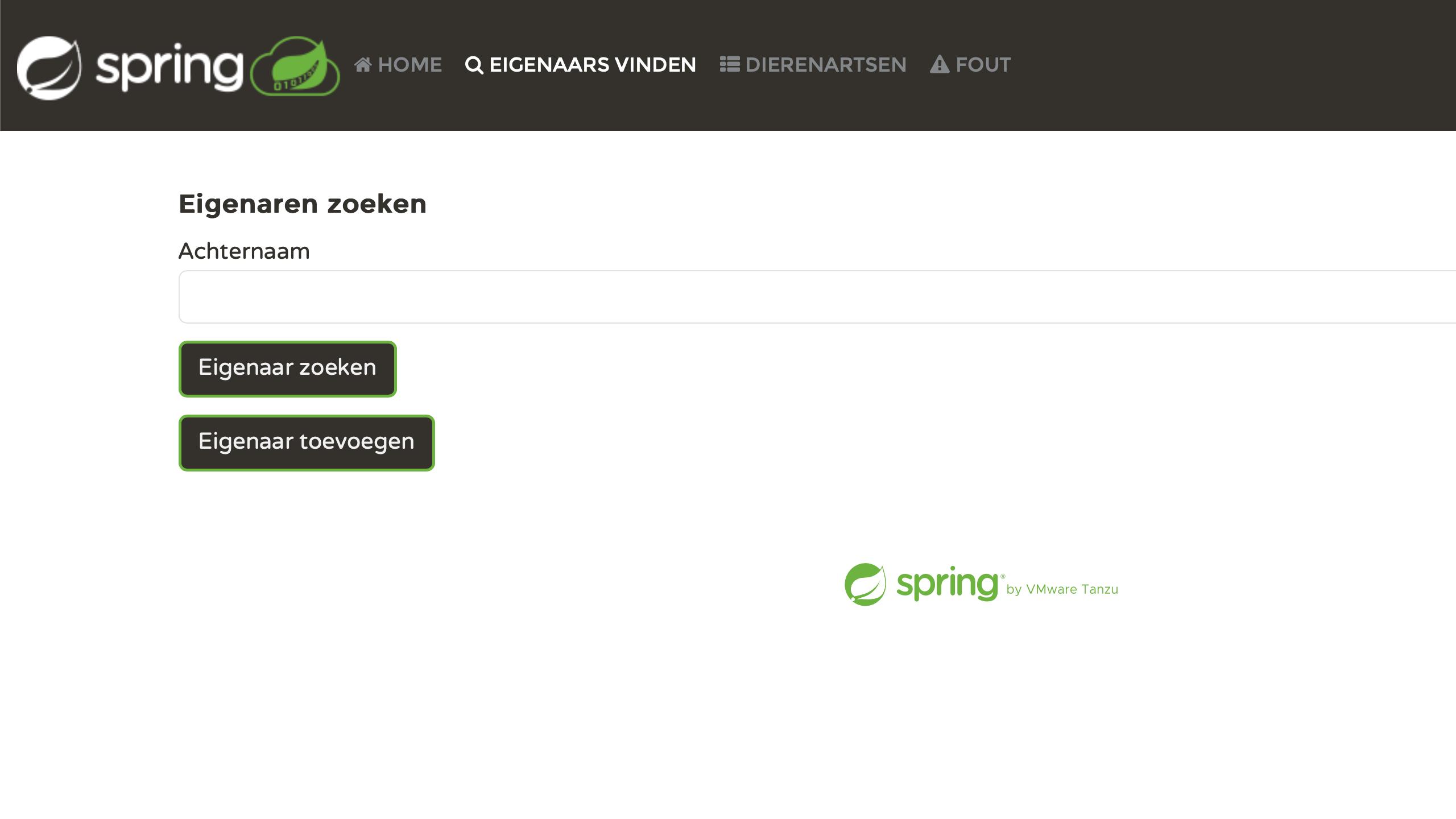

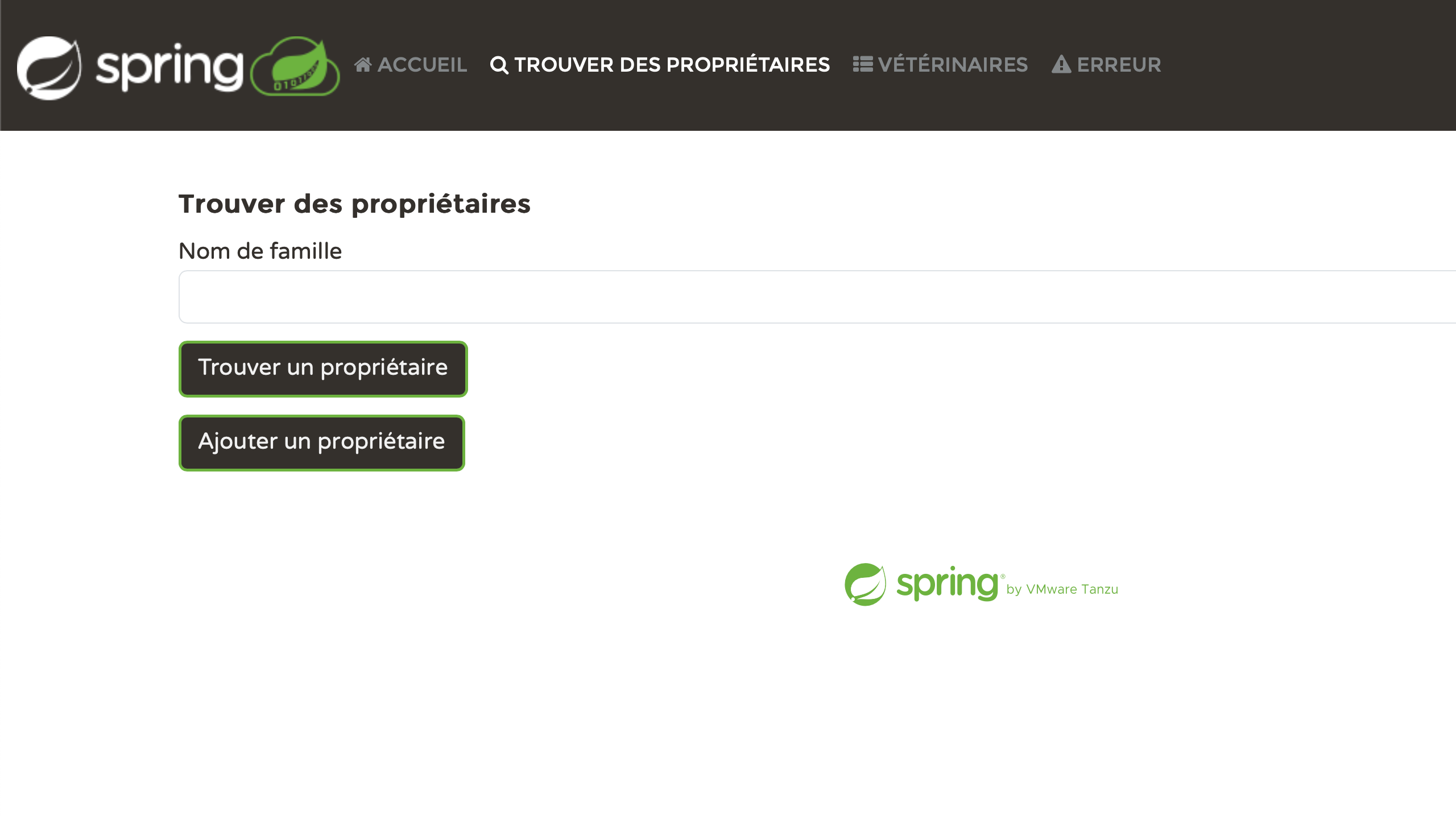
Probleme beheben
Die Ergebnisse sind beeindruckend. Wenn Sie jedoch genauer hinschauen, koennten Sie Fehler entdecken, die durch fehlenden Kontext entstehen. Zum Beispiel:
visit.update = Visit Visit kann sowohl ein Substantiv als auch ein Verb sein. Ohne zusaetzlichen Kontext produziert der Uebersetzungsdienst
in einigen Sprachen eine falsche Uebersetzung.
Dies kann entweder durch manuelle Bearbeitung oder durch Anpassung des Uebersetzungs-Workflows behoben werden. Eine moegliche Loesung ist, Kontext in .properties -Dateien mittels Kommentaren bereitzustellen:
# Noun. Heading. Displayed on the page that allows the user to edit details of a veterinary visit
visit.update = VisitWir koennen dann das Uebersetzungsskript anpassen, um solche Kommentare zu parsen und sie mit dem
context -Parameter zu uebergeben:
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True,
'context': context
}Je tiefer wir graben und je mehr Sprachen wir beruecksichtigen, desto mehr Dinge werden wir finden, die verbessert werden muessen. Dies ist ein iterativer Prozess.
Wenn es eine Sache gibt, die in diesem Prozess unverzichtbar ist, dann ist es Ueberpruefung und Testen. Unabhaengig davon, ob wir die Automatisierung verbessern oder ihre Ausgabe bearbeiten, werden wir es fuer notwendig halten, Qualitaetskontrolle und Bewertung durchzufuehren.
Ausserhalb des Umfangs
Spring Petclinic ist ein einfaches, aber realistisches Projekt, genau wie die Probleme, die wir gerade geloest haben. Natuerlich bringt die Lokalisierung viele Herausforderungen mit sich, die ausserhalb des Umfangs dieses Artikels liegen, darunter:
- Anpassung von Templates an die Grammatikregeln der Zielsprache
- Waehrungs-, Datums- und Zahlenformate
- Verschiedene Lesemuster wie RTL
- Anpassung der UI fuer unterschiedliche Textlaengen
Jedes dieser Themen verdient einen eigenen Artikel. Wenn Sie mehr lesen moechten, wuerde ich diese Themen gerne in separaten Beitraegen behandeln.
Zusammenfassung
Gut, jetzt, da wir die Lokalisierung unserer Anwendung abgeschlossen haben, ist es Zeit, darueber nachzudenken, was wir gelernt haben:
- Lokalisierung geht nicht nur um das Uebersetzen von Texten - sie betrifft auch verwandte Assets, Subsysteme und Prozesse
- Waehrend KI in einigen Lokalisierungsphasen sehr effizient ist, bleiben menschliche Aufsicht und Tests notwendig, um die besten Ergebnisse zu erzielen
- Die Qualitaet automatischer Uebersetzungen haengt von verschiedenen Faktoren ab, einschliesslich der Verfuegbarkeit von Kontext und, im Fall von LLMs, einem richtig geschriebenen Prompt
Ich hoffe, dieser Artikel hat Ihnen gefallen, und ich wuerde mich ueber Ihr Feedback freuen! Wenn Sie Folgefragen haben oder den Ansatz besprechen moechten, zoegern Sie nicht, sich zu melden.
Ich freue mich darauf, Sie in zukuenftigen Beitraegen zu sehen!