IntelliJ IDEA selbst profilen
Andere Sprachen: English Español Français 日本語 한국어 Português 中文
Genau wie der vorherige Beitrag wird auch dieser etwas meta sein. Offensichtlich kannst du IntelliJ IDEA verwenden, um einen anderen Prozess zu profilen, aber wusstest du, dass IntelliJ IDEA sich selbst profilen kann?

Das könnte nützlich sein, wenn du ein IntelliJ IDEA-Plugin schreibst und Probleme im Zusammenhang mit der Leistung des Plugins beheben musst. Unabhängig davon, ob du ein Plugin-Autor bist, könnte dieses Szenario für dich interessant sein, weil die Profiling-Strategie, die ich behandeln werde, nicht exklusiv für IntelliJ IDEA ist – du kannst sie verwenden, um ähnliche Engpässe in anderen Projekttypen und mit anderen Werkzeugen zu beheben.
Das Problem
In diesem Beitrag werden wir einen ziemlich interessanten Performance-Engpass betrachten, auf den ich vor ein paar Jahren gestoßen bin.
Während ich an einem Nebenprojekt in IntelliJ IDEA arbeitete, bemerkte ich, dass
das Finden von Tests (Navigate | Test) für Klassen mit bestimmten kurzen Namen, wie A ,
überraschend langsam war und oft 2 Minuten oder länger dauerte.

Das Vorhandensein des Engpasses schien nicht von der Größe des Projekts abzuhängen –
selbst in Projekten, die nur aus einer einzigen Klasse namens A bestanden,
dauerte die Navigation immer noch sehr lange.
Ich habe noch nie Verzögerungen im Zusammenhang mit dieser Funktion erlebt, selbst im riesigen
IntelliJ IDEA-Monorepo, also schien die Verlangsamung in einem fast leeren Projekt besonders merkwürdig.
Warum passierte das? Und, noch wichtiger, wie geht man ähnliche Probleme an, solltest du auf sie in deinem Projekt stoßen?
Umgebung nachstellen
Ich habe diesen Artikel ursprünglich für den internen Gebrauch bei JetBrains geschrieben, aber die Idee, ihn zu veröffentlichen, kam mir erst kürzlich. Glücklicherweise ist der Artikel mit der Zeit nicht gut gealtert, und das Problem scheint auf den aktuellen Versionen von IntelliJ IDEA und neuerer Hardware nicht mehr reproduzierbar zu sein.
Da ich die Verlangsamung auf meinem Arbeitssetup nicht reproduzieren konnte, fand ich mich dabei wieder, meinen alten Laptop abzustauben und eine frühere Version von IntelliJ IDEA darauf zu installieren. Wenn du der Untersuchung in deiner IDE folgen möchtest, stelle sicher, dass du das IntelliJ IDEA Community Edition-Repo klonst, da dies die Navigation und das Debuggen für dich erleichtert.
Lass uns auch sicherstellen, dass wir ein leeres Projekt mit der folgenden Klasse darin haben:
public class A {
public static void main(String[] args) {
System.out.println("I like tests");
}
}IntelliJ Profiler
Wie du bereits weißt, hat IntelliJ IDEA einen integrierten JVM-Profiler. Du kannst Anwendungen mit angehängtem Profiler starten. Alternativ kannst du den Profiler an einen bereits laufenden Prozess anhängen, was wir jetzt tun werden.
Gehe dazu zum Profiler Tool-Fenster und finde den entsprechenden Prozess dort. Wenn du deine IDE nicht in der Liste siehst, stelle sicher, dass du Show Development Tools im Menü neben Process aktivierst. Wenn du auf einen Prozess klickst, schlägt IntelliJ IDEA die integrierten Performance-Analyse-Werkzeuge vor, die es dir ermöglichen:
- CPU-Nutzung und Speicherallokationen zu profilen
- JVM-Heap zu analysieren
- Thread-Dumps zu erfassen
- Echtzeit-Ressourcenverbrauch zu überwachen
All diese Werkzeuge werden in der Dokumentation behandelt, und in diesem Beitrag werden wir uns speziell auf den Profiler konzentrieren.
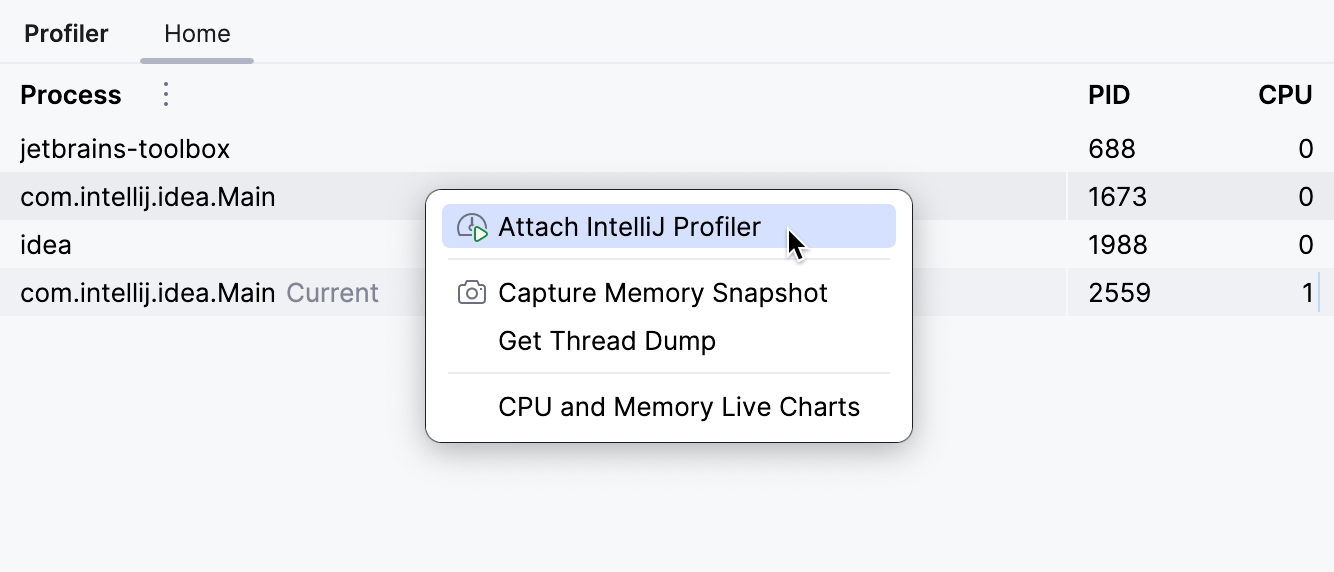
Wir müssen den Profiler anhängen, bevor das Problem auftritt. Wenn das Problem beispielsweise als Ergebnis des Aufrufens einer API auftritt, hänge zuerst den Profiler an den Prozess an und reproduziere dann die Ereignisse, die das Problem verursachen.

Idealerweise sollten wir den Profiler direkt vor dem Reproduzieren des Problems anhängen. Wenn deine Anwendung mit etwas anderem beschäftigt ist, als nur auf Eingaben zu warten, hilft dieser Ansatz, die Anzahl irrelevanter Samples zu minimieren.
Je nachdem, wie lange der problematische Code zur Ausführung braucht, kann es auch sinnvoll sein, das Problem mehrmals zu reproduzieren, damit der Profiler mehr Samples für die Analyse sammeln kann. Dies wird das Problem im resultierenden Bericht deutlicher hervortreten lassen.
Wenn du den Profiler abhängst oder den Prozess beendest, öffnet IntelliJ IDEA automatisch den resultierenden Snapshot.
Bericht analysieren
Um die Snapshots zu analysieren, stehen dir mehrere Ansichten zur Verfügung. Du kannst Aufrufbäume untersuchen, Statistiken für bestimmte Methoden, CPU-Last pro Thread, GC-Aktivität und mehr.
Für das vorliegende Problem beginnen wir mit der Timeline-Ansicht, um zu sehen, ob wir etwas Ungewöhnliches entdecken:
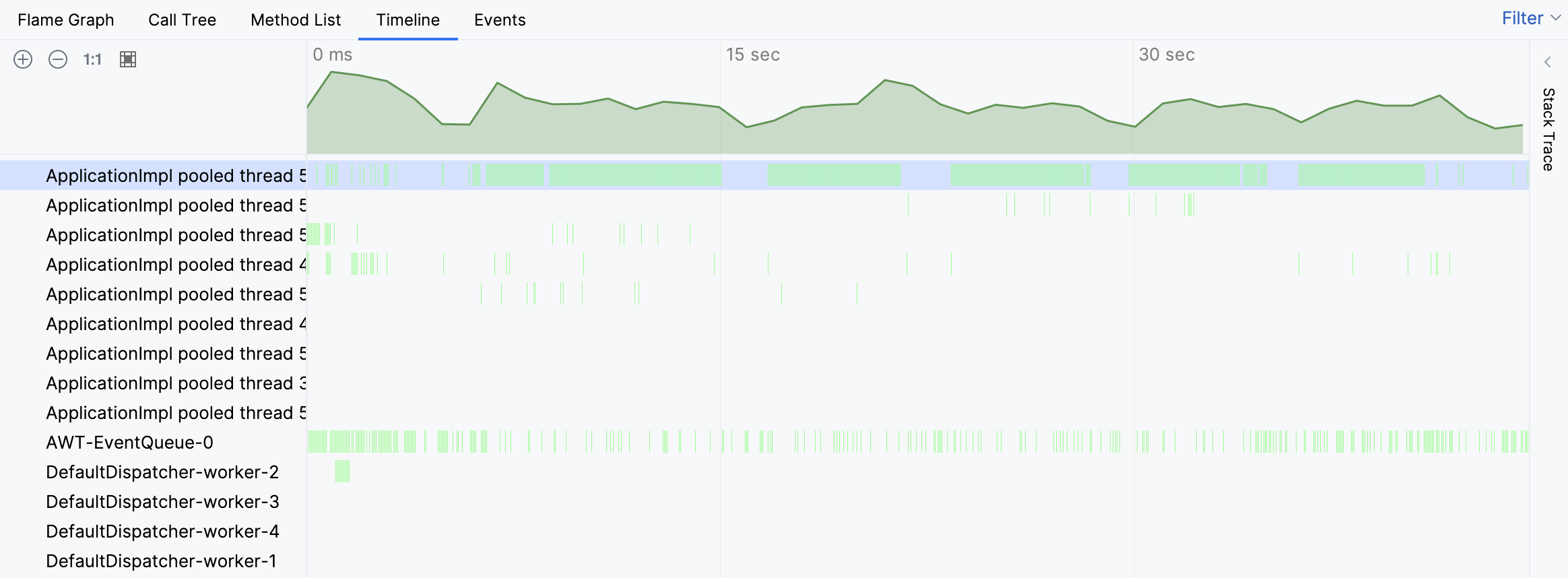
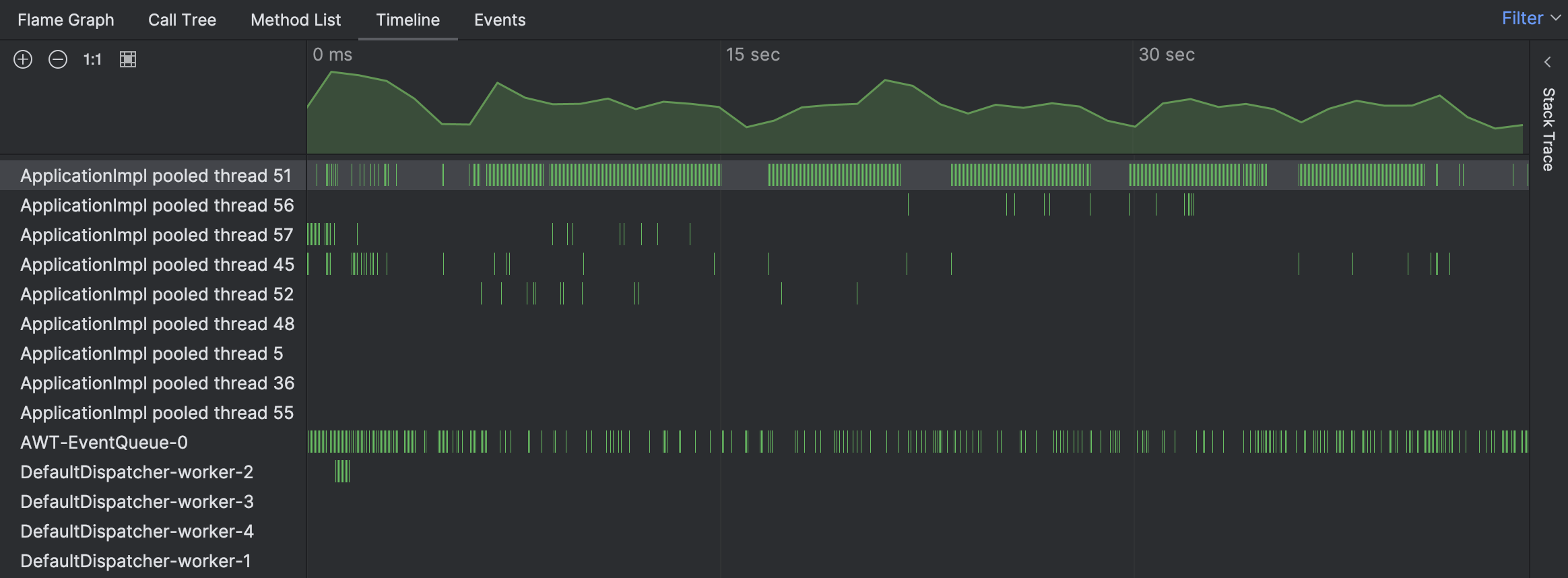
Tatsächlich zeigt die Timeline, dass einer der Threads außerordentlich beschäftigt war. Die grünen Balken entsprechen den Samples, die für einen bestimmten Thread gesammelt wurden. Durch Klicken auf einen dieser Balken können wir den entsprechenden Stack-Trace für das Sample sehen.
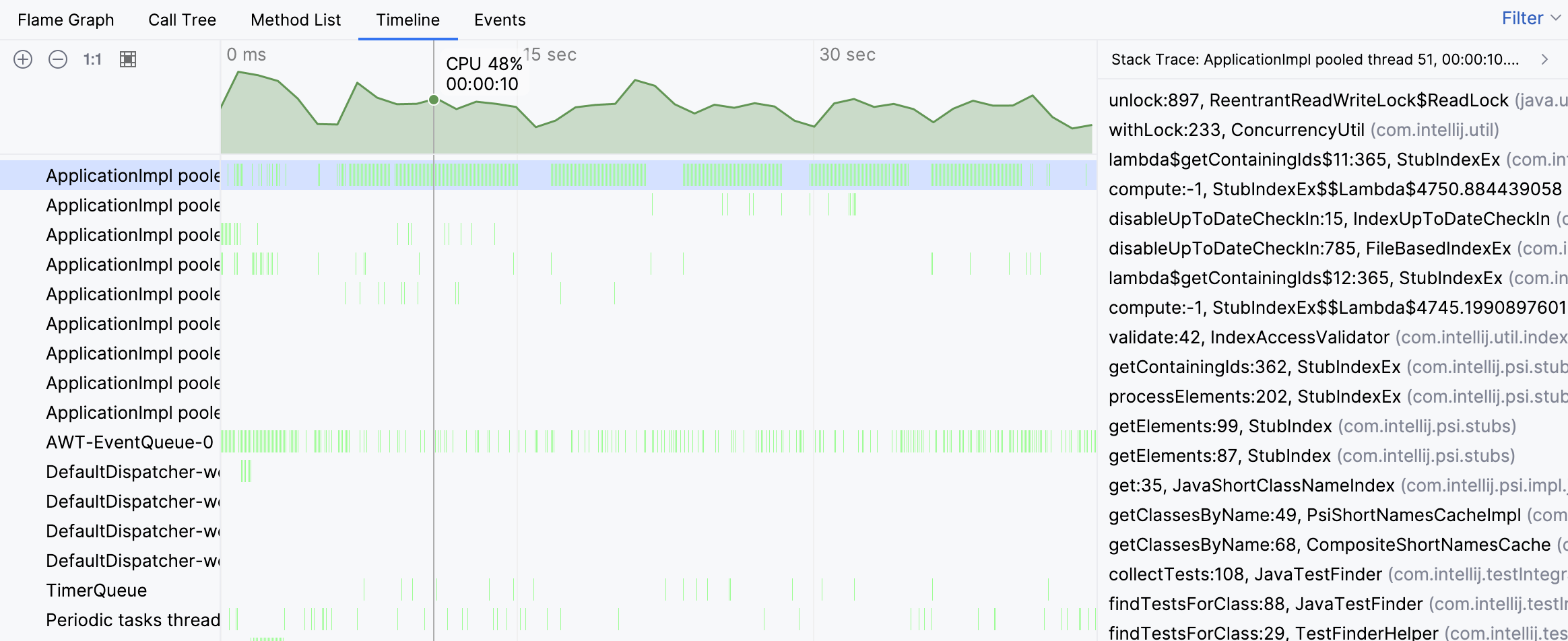
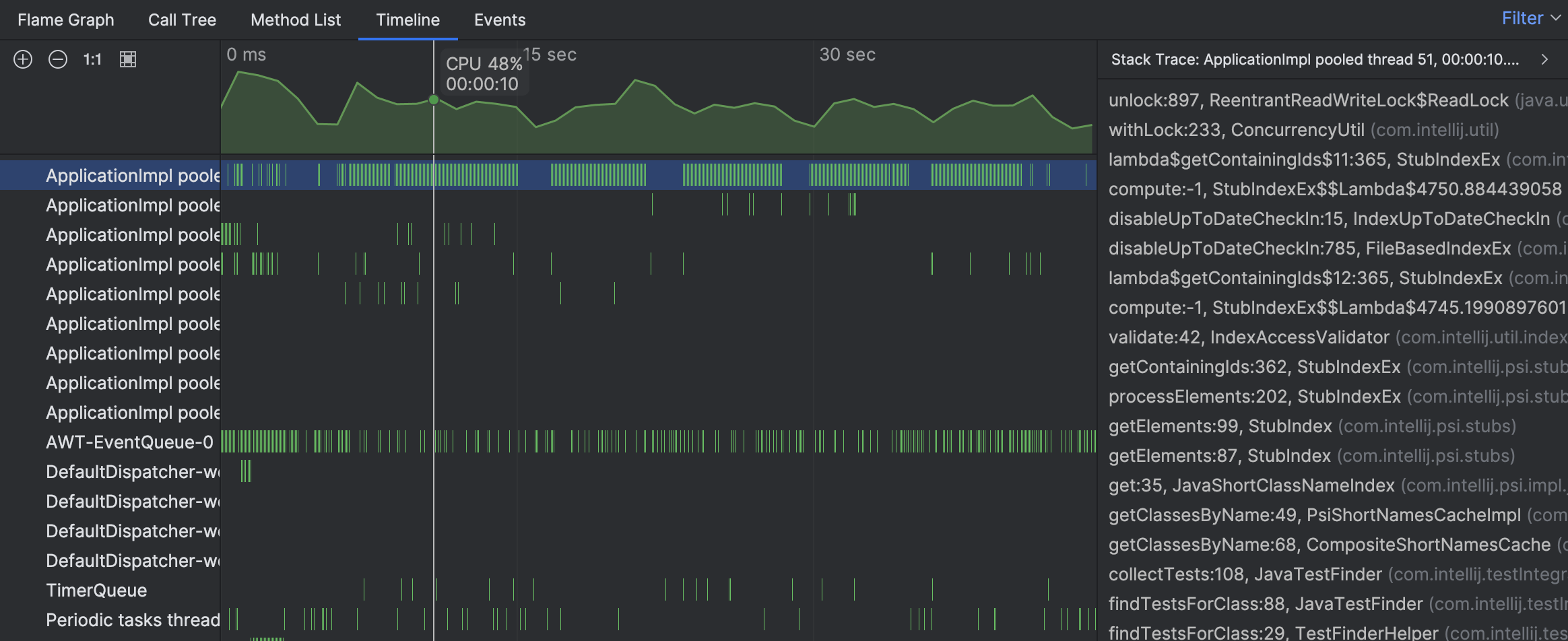
Die Stack-Traces aus einzelnen Samples deuten darauf hin, dass die Aktivität des Threads mit dem Finden von Tests zusammenhängt. Wir sehen jedoch immer noch nicht das große Bild. Navigieren wir zum beschäftigten Thread im Flame-Graph:

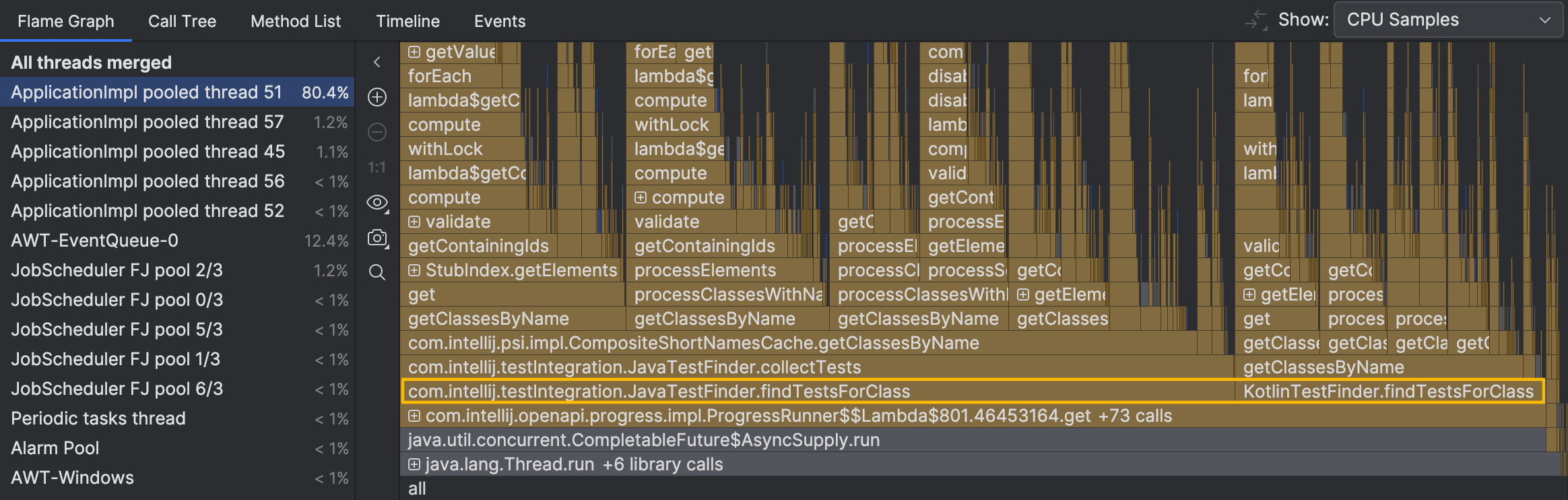
Die Methoden, die für uns von Interesse sein könnten,
JavaTestFinder.findTestsForClass() und KotlinTestFinder.findTestsForClass() ,
befinden sich direkt am unteren Rand des Graphen.
Wir berücksichtigen nicht die eingeklappten Methoden darunter, da sie keine signifikante Eigenzeit oder Verzweigung haben.
Sie steuern den Ablauf, anstatt intensive Berechnungen durchzuführen.
Um zu verifizieren, ob diese Methoden tatsächlich mit der Verlangsamung zusammenhängen,
können wir einen nicht-problematischen Fall profilen:
nach Tests für eine Klasse mit einem realistischeren Namen suchen, zum Beispiel
ClassWithALongerName .
Dann werden wir sehen, was mit diesen Methoden passiert, indem wir die Diff-Ansicht verwenden.


Der neuere Snapshot enthält 93-95% weniger Samples
mit JavaTestFinder.findTestsForClass()
und KotlinTestFinder.findTestsForClass() .
Die Laufzeit der anderen Methoden unterscheidet sich nicht so sehr.
Es scheint, als wären wir auf dem richtigen Weg.
Die nächste Frage ist, warum das passiert. Lass uns versuchen, das mit dem Debugger herauszufinden.
Warum so ein großer Unterschied?
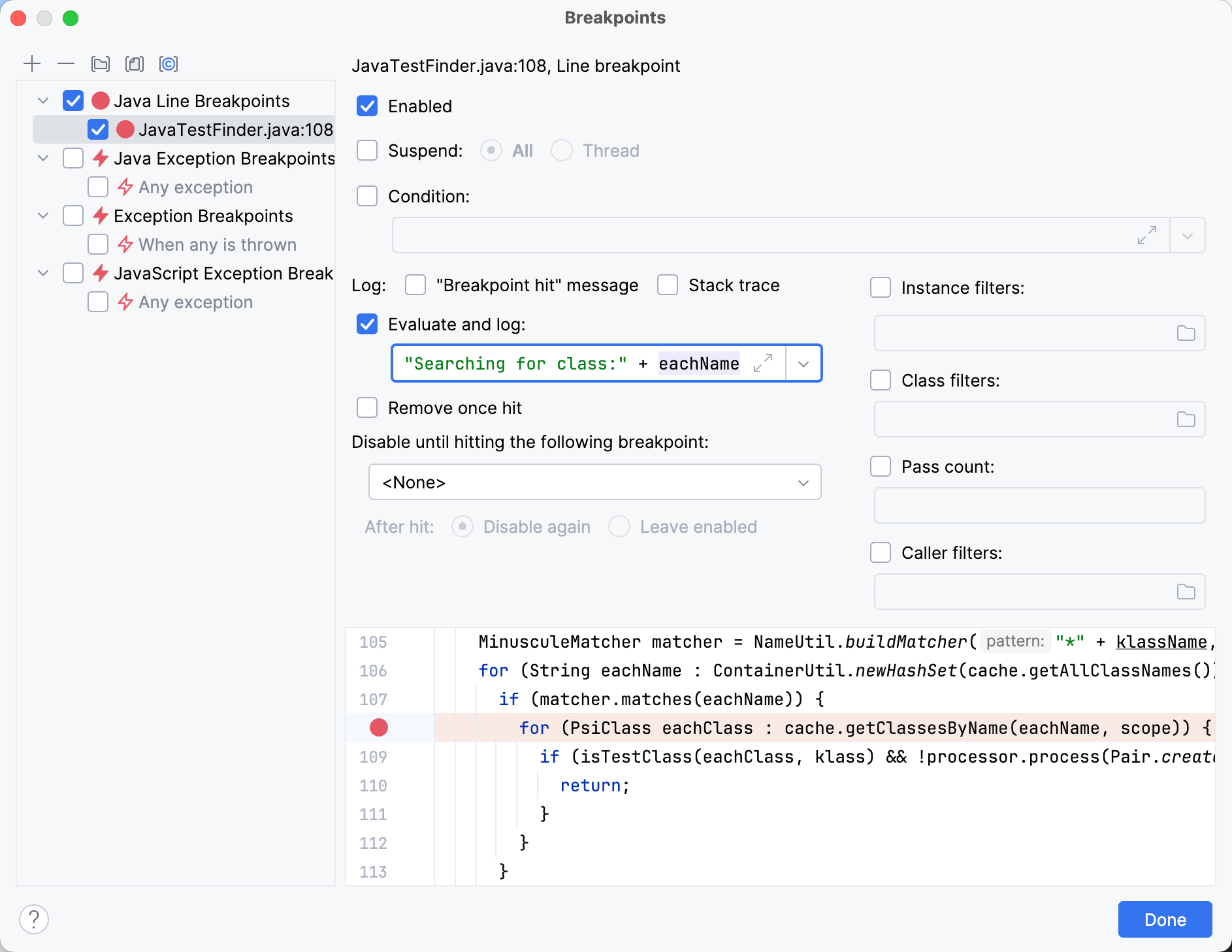
Das Setzen eines Breakpoints in findTestsForClass() und ein bisschen
Durchsteppen durch den Code bringt uns zu folgendem Punkt:
MinusculeMatcher matcher = NameUtil.buildMatcher("*" + klassName, NameUtil.MatchingCaseSensitivity.NONE);
for (String eachName : ContainerUtil.newHashSet(cache.getAllClassNames())) {
if (matcher.matches(eachName)) {
for (PsiClass eachClass : cache.getClassesByName(eachName, scope)) {
if (isTestClass(eachClass, klass) && !processor.process(Pair.create(eachClass, TestFinderHelper.calcTestNameProximity(klassName, eachName)))) {
return;
}
}
}
}Der Code filtert die kurzen Namen, die derzeit im Cache sind, mit einem regulären Ausdruck. Für jeden der resultierenden Strings sucht er die entsprechenden Klassen.
Durch Protokollieren der Klassennamen nach der Bedingung erhalten wir alle Klassen, die sie passieren.
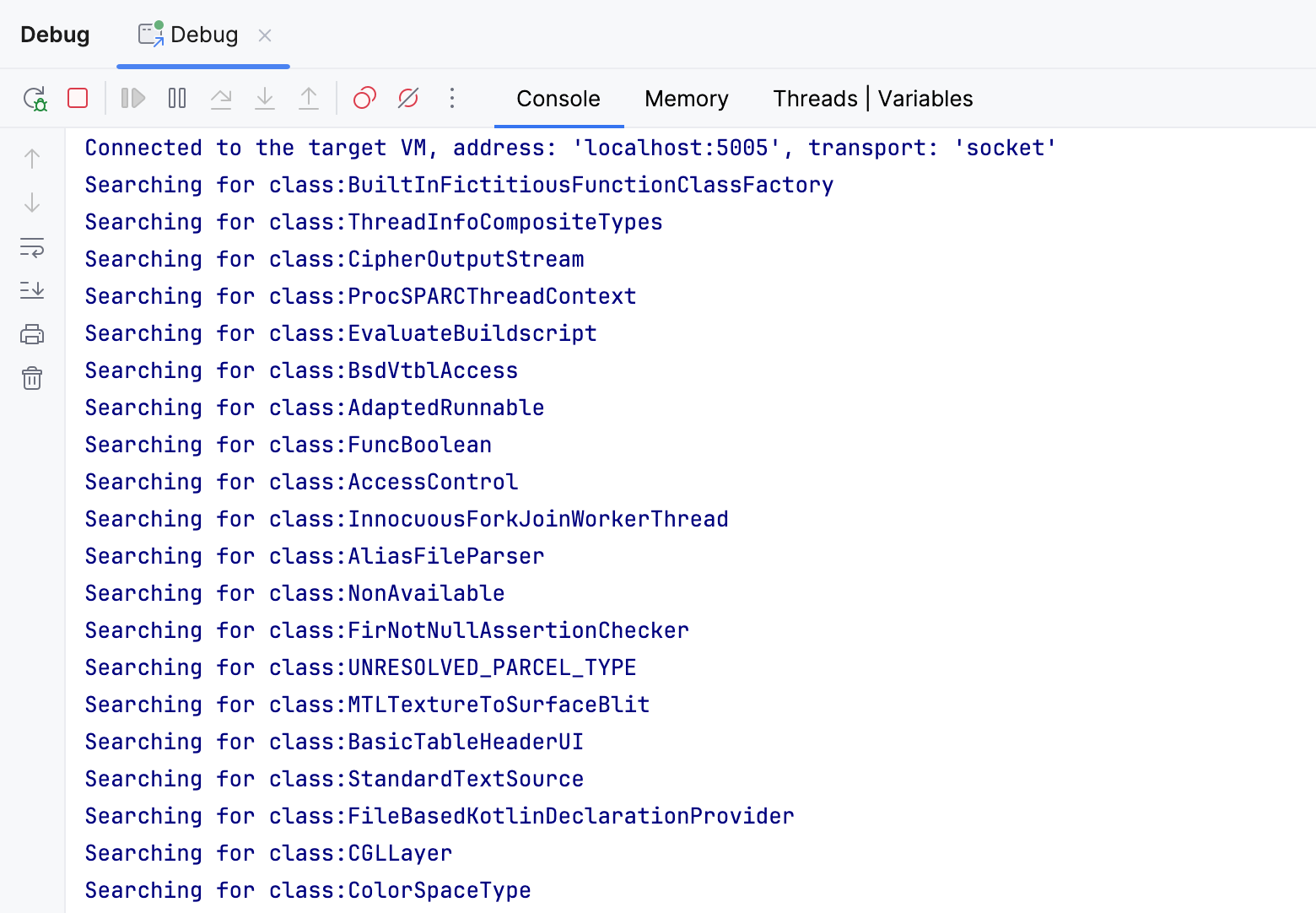
Als ich das Programm ausführte, protokollierte es etwa 25000 Klassen, eine überraschend große Anzahl für ein leeres Projekt!
Die protokollierten Klassennamen kommen offensichtlich von woanders, nicht aus meinem ‘Hello World’-Projekt.
Das Rätsel ist gelöst: IntelliJ IDEA braucht so lange, um Tests für die Klasse A zu finden,
weil es alle gecachten Klassen überprüft, einschließlich Abhängigkeiten, JDKs und sogar Klassen aus anderen Projekten.
Zu viele von ihnen passieren den Filter, weil sie alle
den Buchstaben A in ihren Namen haben.
Mit längeren und realistischeren Klassennamen wäre diese Ineffizienz unbemerkt geblieben,
einfach weil die meisten dieser Namen vom Regex herausgefiltert worden wären.
Der Fix?
Leider konnte ich keinen einfachen und zuverlässigen Fix für dieses Problem finden. Eine mögliche Strategie wäre, Abhängigkeiten aus dem Suchbereich auszuschließen. Das sieht auf den ersten Blick machbar aus, aber es besteht die Möglichkeit, dass Abhängigkeiten Tests enthalten könnten. Das passiert nicht allzu oft, aber trotzdem würde dieser Ansatz die Funktion für solche Abhängigkeiten brechen.
Ein alternativer Ansatz ist die Einführung der *.java-Dateimaske, die kompilierte Klassen herausfiltern würde.
Während das gut mit Java funktioniert, wird es für Tests, die in anderen Sprachen wie Kotlin geschrieben sind, problematisch.
Selbst wenn wir alle möglichen Sprachen hinzufügen, wird diese Funktion einfach still für neu unterstützte fehlschlagen,
was zu zusätzlichem Overhead für Wartung und Debugging führt.
Unabhängig vom Ansatz rechtfertigt der Fix einen eigenen Beitrag, also implementieren wir ihn jetzt nicht. Was wir jedoch getan haben, ist die Grundursache einer Verlangsamung zu entdecken, was genau der Grund ist, warum man einen Profiler verwenden würde.
Snapshot teilen
Bevor wir abschließen, gibt es noch eine Sache, die es wert ist, besprochen zu werden. Hast du bemerkt, dass ich einen Snapshot verwendet habe, der auf einem anderen Computer aufgenommen wurde? Darüber hinaus war der Snapshot nicht nur von einer anderen Maschine. Auch das Betriebssystem und die Version von IntelliJ IDEA waren unterschiedlich.
Eine schöne Sache, die oft übersehen wird am Profiler, ist die Einfachheit des Daten-Teilens. Der Snapshot wird in eine Datei geschrieben, die du an jemand anderen senden kannst (oder von jemandem empfangen kannst). Im Gegensatz zu anderen Werkzeugen, wie dem Debugger, brauchst du keinen vollständigen Reproducer, um mit der Analyse zu beginnen. Tatsächlich brauchst du dafür nicht einmal ein kompilierbares Projekt.
Glaub mir nicht einfach; probiere es selbst aus. Hier ist der Snapshot: idea64_exe_2024_07_22_113311.jfr