IntelliJ IDEAの自己プロファイリング
他の言語: EnglishEspañolFrançaisDeutsch한국어Português中文
この記事も前の記事のように、少しメタ的なものになります。 もちろん、IntelliJ IDEA を使って別のプロセスをプロファイリングすることはできますが、 IntelliJ IDEA自体が自身をプロファイリングできることをご存知でしたか?
これは、あなたがIntelliJ IDEAのプラグインを作成していて、 プラグインのパフォーマンスに関連した問題を解決する必要がある場合などに、便利かもしれません。 また、プラグインの作者であるかどうかにかかわらず、私が取り上げるプロファイリング戦略はIntelliJ IDEAに限定されたものではなく、 他のタイプのプロジェクトや他のツールを使用して同様のボトルネックをトラブルシューティングするために使用できるため、 このシナリオはあなたにとって興味深いものであるかもしれません。
問題点
この記事では、私が数年前に遭遇した興味深いパフォーマンスのボトルネックを見ていきます。
IntelliJ IDEAのサイドプロジェクトに取り組んでいる最中、ある特定の短い名前を持つクラス、たとえば、 A 、
のテストを検索する移動 (Navigate) | テスト (Test)ことが驚くほど遅く、しばしば2分以上かかることに気づきました。
このボトルネックの存在はプロジェクトのサイズに依存しているようではなく、
たとえば、名前が A >という単一のクラスで構成されるプロジェクトでも、
ナビゲーションには非常に時間がかかります。
私はこれまでに巨大なIntelliJ IDEAのモノレポでもこの機能に関連する遅延を経験したことがないので、
ほぼ空のプロジェクトでの遅れは特に奇妙に思えました。
これはなぜ起こっていたのでしょうか?そして、より重要なことに、あなたがプロジェクトで同様の問題に遭遇した場合、 どのように対処すべきでしょうか?
環境の再現
当初は、この記事はJetBrainsの社内での使用のために書かれましたが、 最近になって公開するというアイデアが浮かび上がりました。 幸いなことに、記事が日焼けしてきて、現在のIntelliJ IDEAやより新しいハードウェアでは 問題が再現しないようになりました。
私の作業用のセットアップでは遅延を再現できなかったので、 使用していない古いラップトップを見つけ出して、そこに以前のバージョンの IntelliJ IDEA を インストールしました。 あなたがあなたのIDEで調査を追いかけたい場合は、 IntelliJ IDEA Community Edition リポジトリをクローンするようにしてください。 これにより、あなたはナビゲーションとデバッグを簡単にできるようになります。
次に、次のようなクラスを持つ空のプロジェクトがあることを確認しましょう:
public class A {
public static void main(String[] args) {
System.out.println("I like tests");
}
}IntelliJ プロファイラー
ご存知のように、IntelliJ IDEAには統合されたJVMプロファイラーがあります。 プロファイラーをアタッチした状態でアプリケーションを起動することができます。 また、すでに起動しているプロセスにプロファイラーをアタッチすることもできます。これが私たちが行うことです。
これを行うためには、プロファイラー (Profiler)ツールウィンドウに行き、そこで対応するプロセスを探します。 あなたのIDEをリストに見つけられない場合は、プロセス (Process)の近くのメニューで開発ツールを表示 (Show Development Tools)を確認してみてください。 プロセスをクリックすると、IntelliJ IDEAは統合されたパフォーマンス分析ツールを提案します。これにより、以下のことが可能になります:
これらの全てのツールはドキュメンテーションでカバーされています。 この記事では、特にプロファイラーに焦点を当てます。
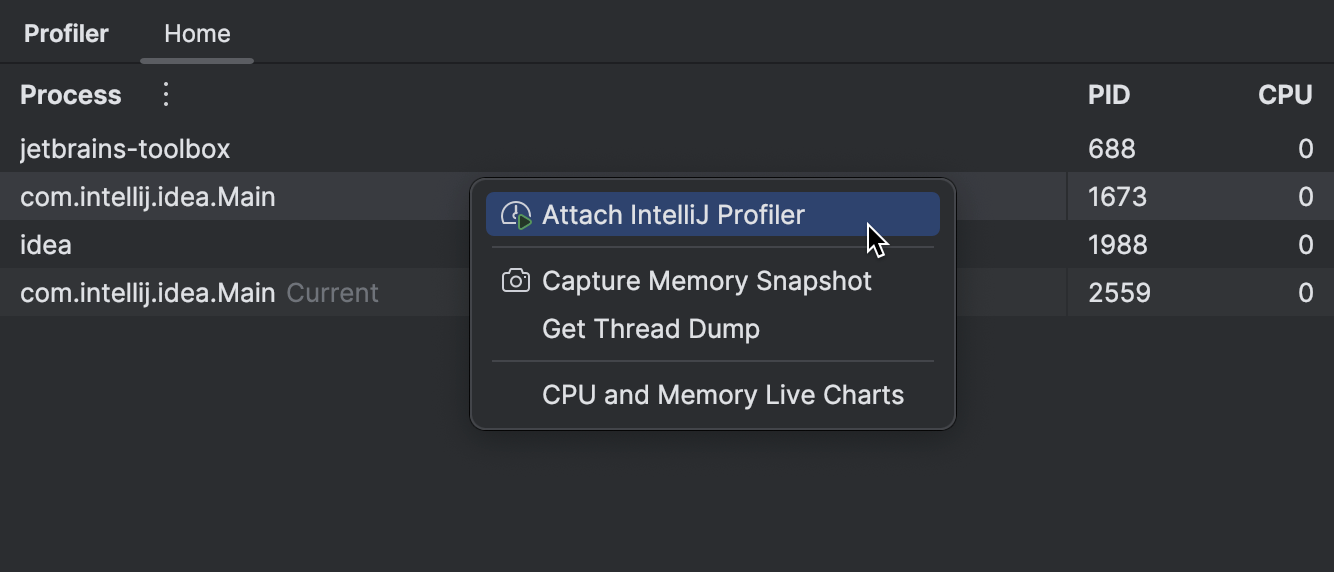
プロブレムが発生する前にプロファイラーをアタッチする必要があります。 例えば、あるAPIを呼び出す結果として問題が発生する場合、 まずプロセスにプロファイラーをアタッチし、次に問題を引き起こすイベントを再現します。
理想的には、問題を再現する直前にプロファイラーをアタッチするべきです。 アプリケーションが入力を待つだけでなく他の何かを行っている場合、このアプローチは 関連性のないサンプルの数を最小限に抑えるのに役立ちます。
問題のあるコードの実行にどの程度の時間がかかるかによって、 プロファイラーが分析のためにより多くのサンプルを収集できるように、 問題を何度か再現する意味があるかもしれません。 これにより、結果のレポートで問題がより目立つようになります。
プロファイラーをデタッチしたり、プロセスを終了したりすると、 IntelliJ IDEAは自動的に結果のスナップショットを開きます。
レポートの分析
スナップショットの分析には、いくつかのビューが利用可能です。 コールツリー、特定のメソッドの統計、スレッドごとのCPU負荷、GC活動などを調査することが選択できます。
手元の問題に対しては、タイムライン (Timeline)ビューから始めて、何か異常なものがないか探してみましょう:
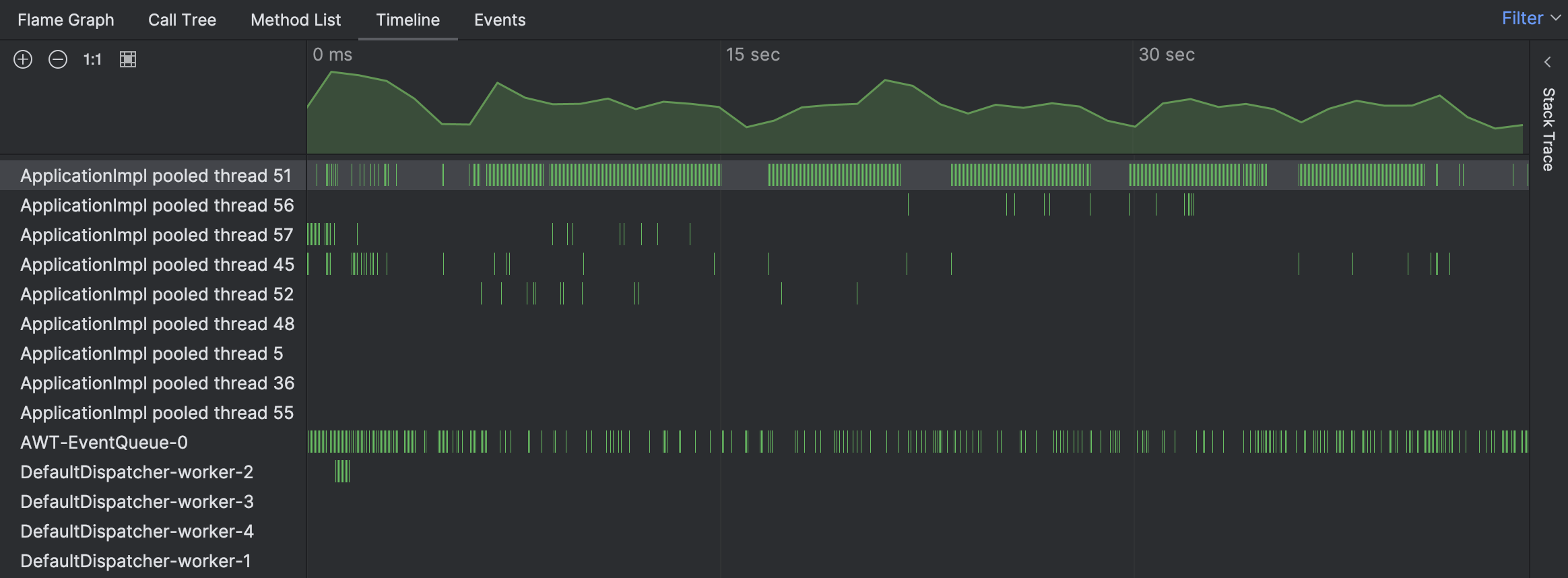
実際に、タイムラインはあるスレッドが異常に忙しかったことを示しています。 緑色のバーは特定のスレッドのために収集されたサンプルに対応しています。 これらのバーのいずれかをクリックすると、そのサンプルのための対応するスタックトレースを見ることができます。
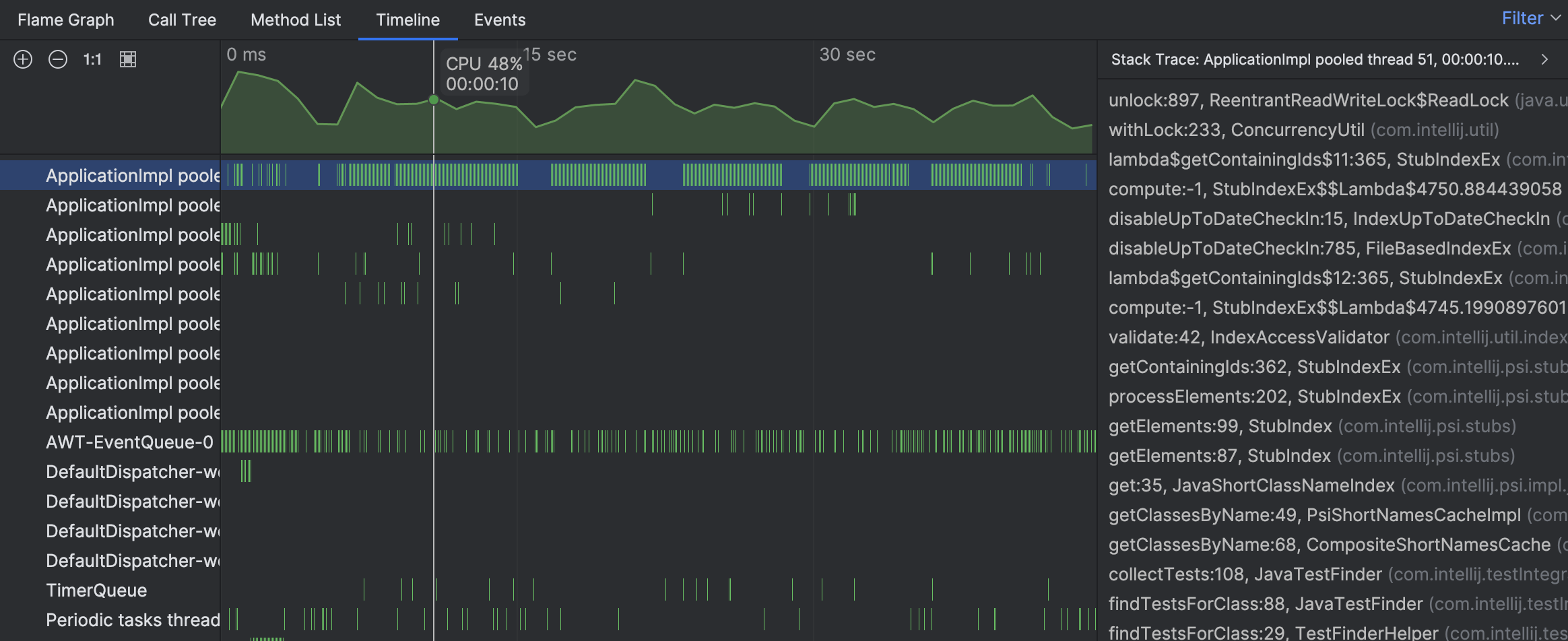
個々のサンプルからのスタックトレースは、 スレッドの活動がテストの検索に関連していることを示しています。 しかし、まだ全体像を見ることはできません。炎のグラフで忙しいスレッドに移動してみましょう:
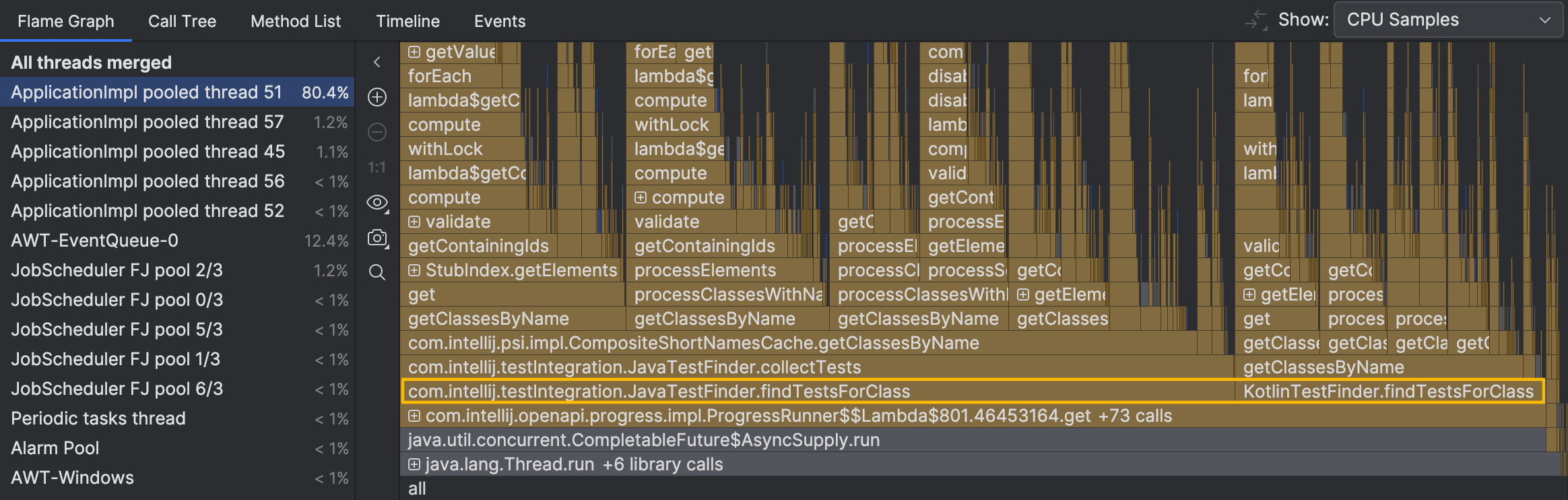
私たちが興味を持つ可能性があるメソッドである JavaTestFinder.findTestsForClass() と KotlinTestFinder.findTestsForClass() は、
グラフの最下部にあります。
私たちは、それらの下にある折りたたまれたメソッドを考慮に入れていません。これらは重要な自己時間や分岐を持っていません。
それらは制御フローを行っているだけで、集中的な計算を行っていません。
これらのメソッドが実際に遅延に関連しているかどうかを確認するために、
問題のないケースをプロファイリングすることができます:
たとえば、より現実的な名前を持つクラス、
ClassWithALongerName のテストを検索します。その後、
diff ビューを使ってこれらのメソッドがどうなるかを見てみます。

新しいスナップショットには、 JavaTestFinder.findTestsForClass() と
KotlinTestFinder.findTestsForClass() を含むサンプルが93~95%少なくなっています。
他のメソッドのランタイムはそれほど変わりません。私たちは正しい方向に進んでいるようです。
次の問題は、なぜそれが起こるのかです。それをデバッガーで調べてみましょう。
なぜこんなに大きな差が?
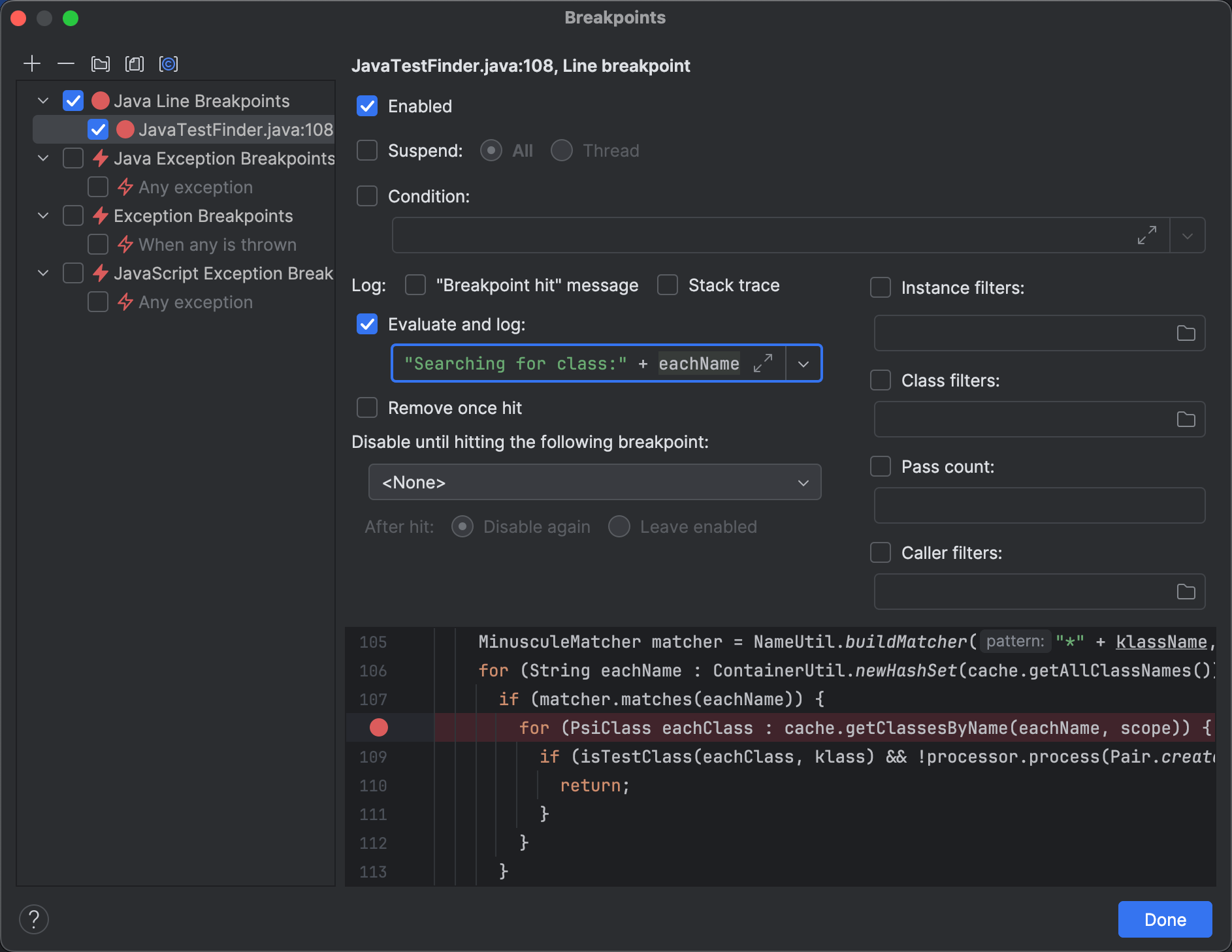
findTestsForClass() にブレークポイントを設定し、少しコードをステップ実行すると、以下のポイントに辿り着きます:
MinusculeMatcher matcher = NameUtil.buildMatcher("*" + klassName, NameUtil.MatchingCaseSensitivity.NONE);
for (String eachName : ContainerUtil.newHashSet(cache.getAllClassNames())) {
if (matcher.matches(eachName)) {
for (PsiClass eachClass : cache.getClassesByName(eachName, scope)) {
if (isTestClass(eachClass, klass) && !processor.process(Pair.create(eachClass, TestFinderHelper.calcTestNameProximity(klassName, eachName)))) {
return;
}
}
}
}このコードは、キャッシュに現在ある短い名前を正規表現を使用してフィルタリングしています。結果として得られる各文字列に対して、対応するクラスを検索します。
ログ記録を使って条件文の後のクラス名をログ出力すると、すべてのクラスがそれを通過することがわかります。
私がプログラムを実行したとき、それは約25000のクラスをログ出力しました。これは空のプロジェクトにとって驚くべきに大きな数です!
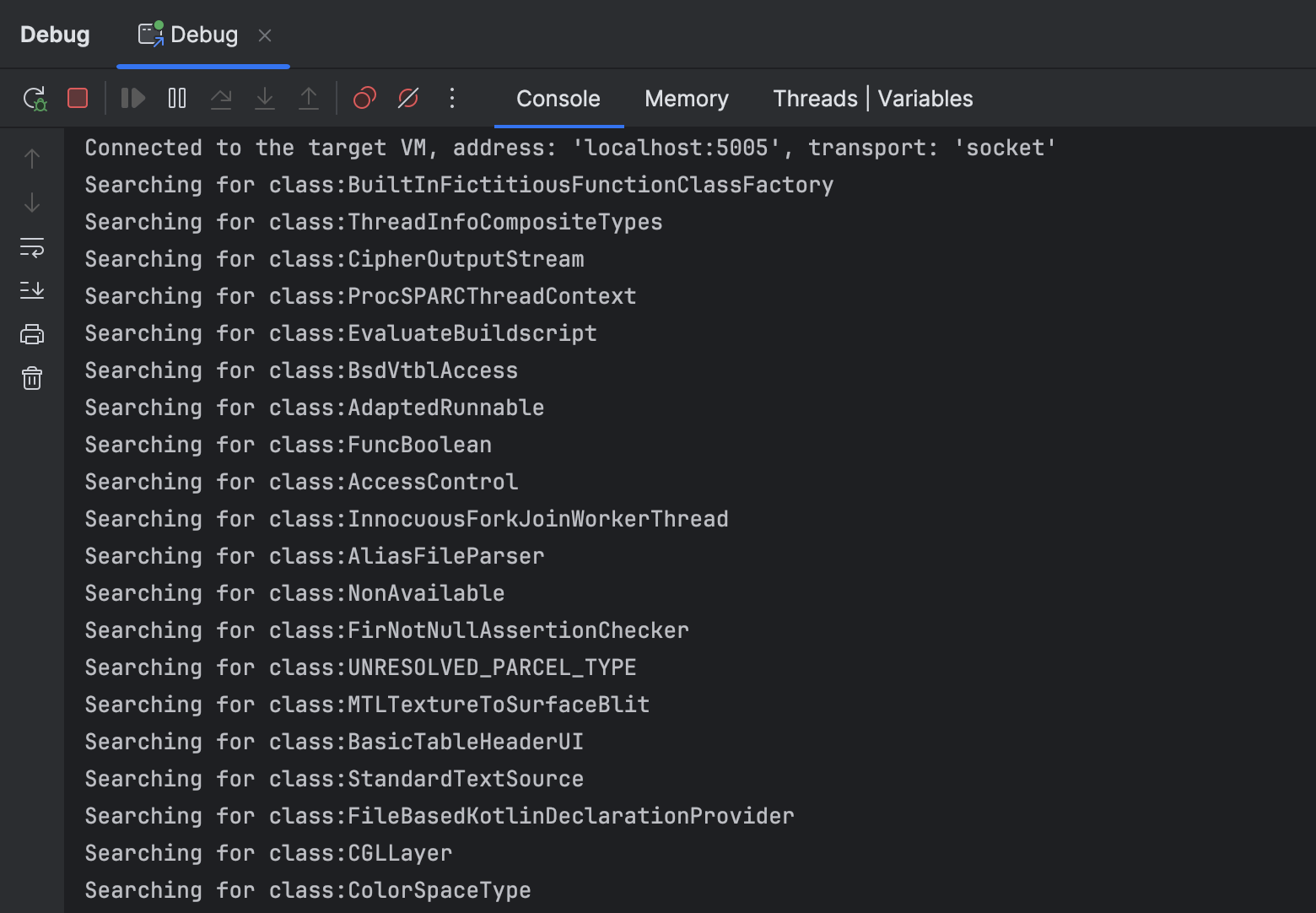
ログに記録されたクラス名は、明らかに他の場所から来ているもので、私の’Hello World’プロジェクトからではありません。
謎が解けました:IntelliJ IDEAがクラス A >のテストを見つけるのに時間がかかるのは、
それがキャッシュされたすべてのクラス、つまり依存関係、JDK、さらには他のプロジェクトのクラスすべてをチェックしているからです。
そのうちの数多くが彼らの名前に文字Aを持っているため、フィルターを通過してしまいます。
より長く、より現実的なクラス名では、この非効率性は気にならなかっただろう、と言えます。
なぜなら、ほとんどのこれらの名前が正規表現によってフィルターされてしまうからです。
修正方法は?
残念ながら、この問題の簡単で信頼性のある解決策を見つけることはできませんでした。 一つの可能な戦略は、検索範囲から依存関係を除外することです。 これは一見実現可能に見えますが、依存関係がテストを含む可能性があるため、問題があります。 これはあまり頻繁には起こりませんが、それでも、このような依存関係に対しては機能が壊れてしまいます。
別のアプローチとしては、*.javaファイルマスクを導入するというものがあります。これにより、コンパイル済みのクラスがフィルターから除外されます。
これはJavaではうまく動作しますが、Kotlinのような他の言語で書かれたテストでは問題になります。
可能な言語すべてを追加しても、この機能は新たにサポートされる言語に対しては静かに失敗し、
メンテナンスとデバッグのためのオーバーヘッドが増える結果となります。
どのアプローチでも、修正は自身の投稿を必要とするので、今はそれを実装しません。 しかし、私たちは遅延の根本原因を発見した、これこそがプロファイラーを使う理由です。
スナップショットの共有
終わりに、もう一つだけ議論に値することがあります。 私が別のコンピュータで取られたスナップショットを使用したことに気づきましたか? さらに、スナップショットは単に別のマシンからだけでなく、 オペレーティングシステムとIntelliJ IDEAのバージョンも異なっていました。
プロファイラーについてよく overlooked される一つの美しいことは、データの共有の容易さです。 スナップショットはファイルに書き込まれ、 あなたはそれを他の誰かに送ることができます(または他の誰かから受け取ることができます)。 デバッガーのような他のツールとは異なり、分析を始めるために完全な再現が必要ない。 事実上、そのためにはコンパイル可能なプロジェクトすら必要ありません。
私の言葉を信じることなく、自分で試してみてください。ここにスナップショットがあります:idea64_exe_2024_07_22_113311.jfr