Buscador de Duplicados para Textos
Otros idiomas: English Français Deutsch 日本語 한국어 Português 中文

Cualquier persona que haya trabajado en la documentación técnica en un gran equipo es sin duda consciente del problema de duplicación de contenido. Incluso con las mejores herramientas y prácticas a mano, la duplicación es fundamentalmente difícil de superar.

A medida que el proyecto crece en tamaño, comenzará a ocurrir contenido duplicado. Esto es especialmente cierto para grandes proyectos que incluyen muchos productos o características similares.
<p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p><TroubleshootingNote/><p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>
<!-- same meaning, slightly different wording-->
<p>
In case of problems, consult the troubleshooting guide
or contact support
</p>La idea que aboga contra la duplicación es comúnmente conocida como Principio DRY. Aunque se asocia principalmente con la programación, la misma propiedad es altamente valorada en la documentación.
Introducción del proyecto
Las herramientas modernas de creación de contenido suelen tener características para la reutilización de contenido, haciendo que las restricciones técnicas sean menos preocupantes. El problema real, por otro lado, radica en detectar duplicados. Antes de extraer algo a un fragmento reutilizable, necesitas saber qué extraer.
Si eres un programador, tu IDE podría resaltar el código duplicado para ti:
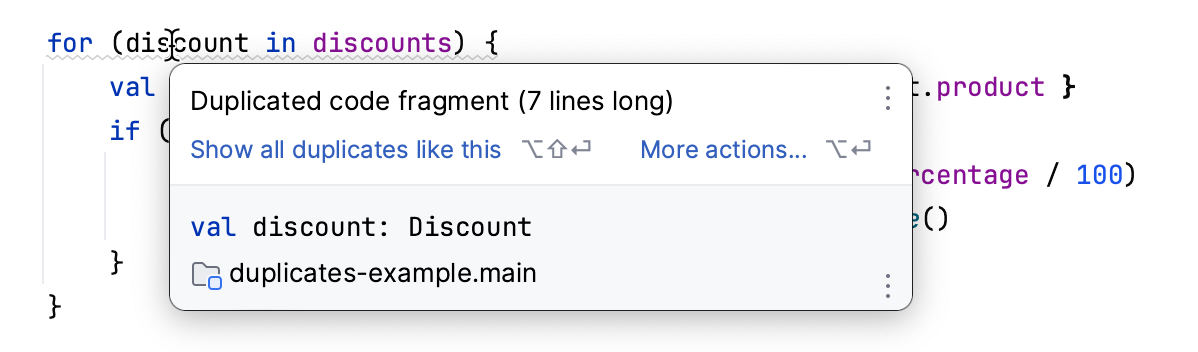
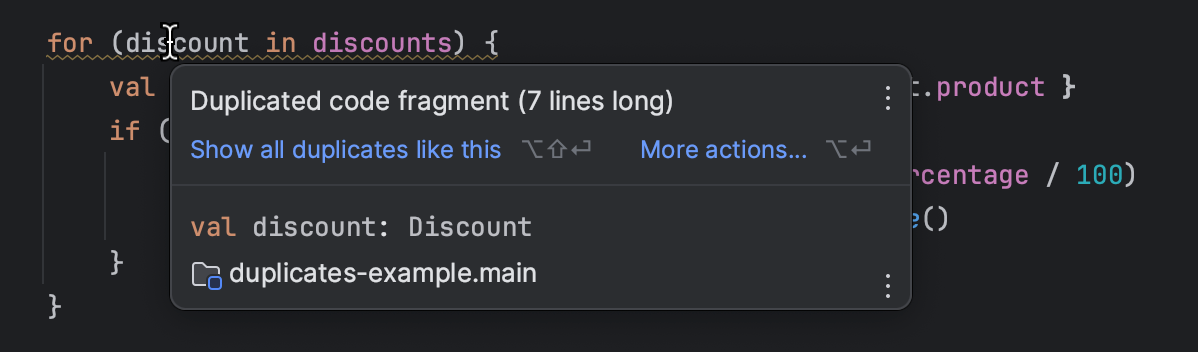
Desafortunadamente, la misma característica no es adecuada para la documentación, ya que depende de comparar árboles de sintaxis abstractos (AST). Este enfoque no funciona bien con el texto.
Uno de mis proyectos en curso es implementar un buscador de duplicados para la documentación. La herramienta será capaz de encontrar rápidamente coincidencias no exactas, o difusas, como el ejemplo malo anterior.
Estado actual
Al momento de escribir esto, el proyecto está en desarrollo, pero ya hay un prototipo funcional:
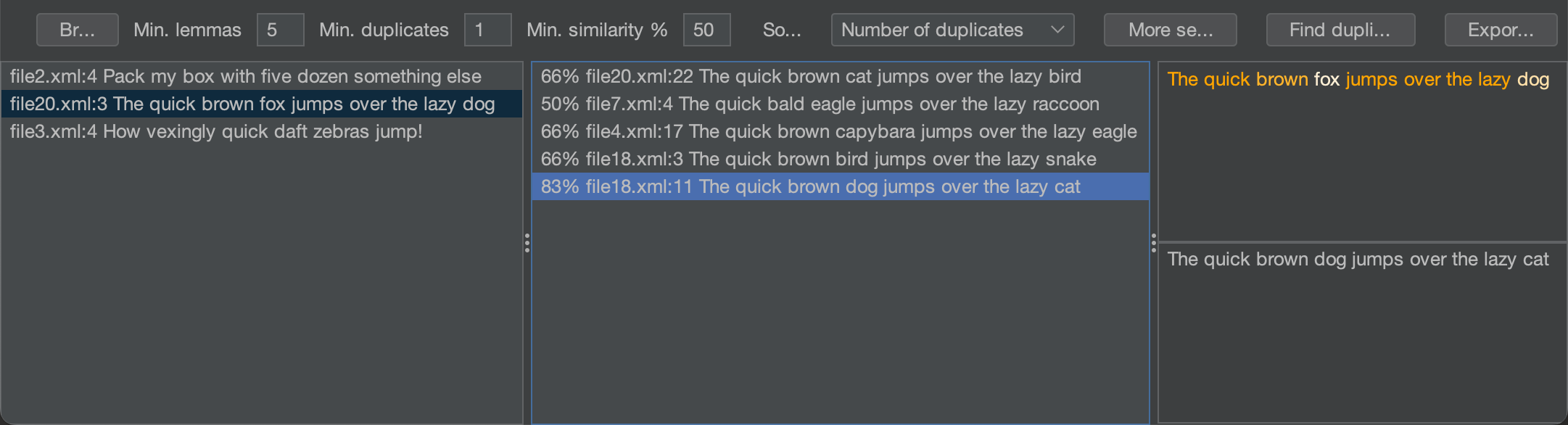
El algoritmo tarda menos de 30 segundos en analizar un proyecto con ~6k archivos fuente en mi MBP M1, y estoy planeando mejorarla para resaltar instantáneamente los duplicados justo cuando tecleas en el editor.
El prototipo ya me ha ayudado a mí y a mis colegas a encontrar muchos duplicados en proyectos reales, así que estoy bastante entusiasmado con los resultados y las mejoras futuras.
Qué sigue
En las siguientes publicaciones, explicaré el algoritmo paso a paso y realizaré pruebas de rendimiento para evaluar su desempeño. Si te gusta programar, eres bienvenido a codificar junto a nosotros.
Alternativamente, puedes estar atento al progreso y utilizar el producto final cuando el proyecto esté completo. Una vez terminado, esta característica estará disponible en Writerside, una gran herramienta de creación de contenido hecha por mis colegas.
Espero que la descripción del proyecto resuene contigo, y que encuentres útil el recorrido.
Nos vemos en las próximas publicaciones!