Buscador de Duplicados de Texto: Requisitos
Otros idiomas: English Français Deutsch 日本語 한국어 Português 中文

Ha pasado un tiempo desde que publiqué la introducción al proyecto del buscador de duplicados, así que parece un buen momento para proporcionar algunos avances sobre eso. Antes de empezar a escribir el código del programa, tiene sentido establecer primero los requisitos. Una buena forma de hacer esto es escribiendo pruebas. No sólo las pruebas nos ayudarán a desarrollar más rápido, sino que también asegurarán que el código se adhiera a la especificación.

Requisitos
En esta sección, he formulado mi idea de las principales características del buscador de duplicados. Estas funcionan bien para mis aplicaciones. Sin embargo, como cada proyecto podría tener diferentes necesidades, estaré encantado de escuchar e implementar sus ideas.
Detectar coincidencias exactas y difusas
La herramienta de detección de duplicados debe ser capaz de encontrar coincidencias exactas y difusas con granularidad hasta los símbolos individuales. Por ejemplo, debería identificar los siguientes textos como similares:
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.Además, en el caso de los duplicados difusos, el grado de similitud debería ser medible. Esto nos permitiría evaluar rápidamente los pares de duplicados y ordenarlos por el grado de similitud entre los fragmentos de texto.
Independiente del idioma
Dada la multitud de posibles idiomas objetivo, sería útil soportar tantos como fuera posible. Algunos enfoques podrían requerir un mantenimiento separado para cada idioma añadido, lo cual no es para nada escalable y requiere muchos recursos. Idealmente, la herramienta debería utilizar algún tipo de heurística o algoritmo independiente del idioma para compatibilidad con cualquier idioma común.
Configurable
Los criterios para identificar los duplicados deben poder ajustarse, con configuraciones como:
- longitud de los fragmentos de texto analizados
- número de duplicados
- grado de similitud
En general, cuanto más largo y repetido es un fragmento, más beneficioso es deduplicarlo. Sin embargo, esto depende en última instancia de la aplicación particular, por lo que sería bueno tener control sobre estos umbrales.
Definiciones
Con los requisitos básicos resueltos, es hora de establecer las definiciones del código. En esta etapa, necesitaremos:
- la unidad básica de texto que representará los posibles duplicados
- la interfaz para el buscador de duplicados
El código en este capítulo no necesita ser exhaustivo y proporcionar para cada futuro caso de uso – siempre podemos volver atrás para hacer ajustes.
Bloque
Cuando se trata de una unidad de texto, ¿qué detalles son importantes para nosotros? Para nuestros propósitos, me quedaría con el texto que contiene un fragmento, la ruta a su archivo contenedor, su número de línea y el tipo de elemento – en caso de que la fuente no sea solo texto plano:
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)Esta definición no tiene en cuenta algunos matices. Por ejemplo, podríamos dejar de lado el
campo content .
Esto nos ahorraría algo de RAM, pero la contra es la velocidad de acceso al contenido del elemento,
porque entonces el programa tendría que leerlo desde el disco cada vez en lugar de solo una vez.
No estamos luchando por el rendimiento en este momento, por lo que una elección potencialmente subóptima está bien.
Interfaz
Aún no tenemos una implementación, así que programaremos contra una interfaz. La interfaz define qué debe llevar nuestra función como entrada y qué debe devolver como salida, abstrayéndonos de los detalles internos de la función. Esto crea efectivamente un contrato, que nos permite escribir pruebas ahora, sin codificar el algoritmo actual. En el futuro, esto también hará que las implementaciones alternativas sean compatibles con las pruebas y el código del cliente existente.
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}Aquí está el significado de los parámetros que acepta la interfaz:
-
root– la carpeta con el contenido a analizar -
minSimilarity– el porcentaje mínimo de similitud para que dos objetosChunksean considerados duplicados -
minLength– longitud mínima decontentpara que unChunksea analizado -
minDuplicates– número mínimo de duplicados para que se informe de un grupo de duplicados -
fileExtensions– máscara de extensión de archivo para filtrar archivos irrelevantes
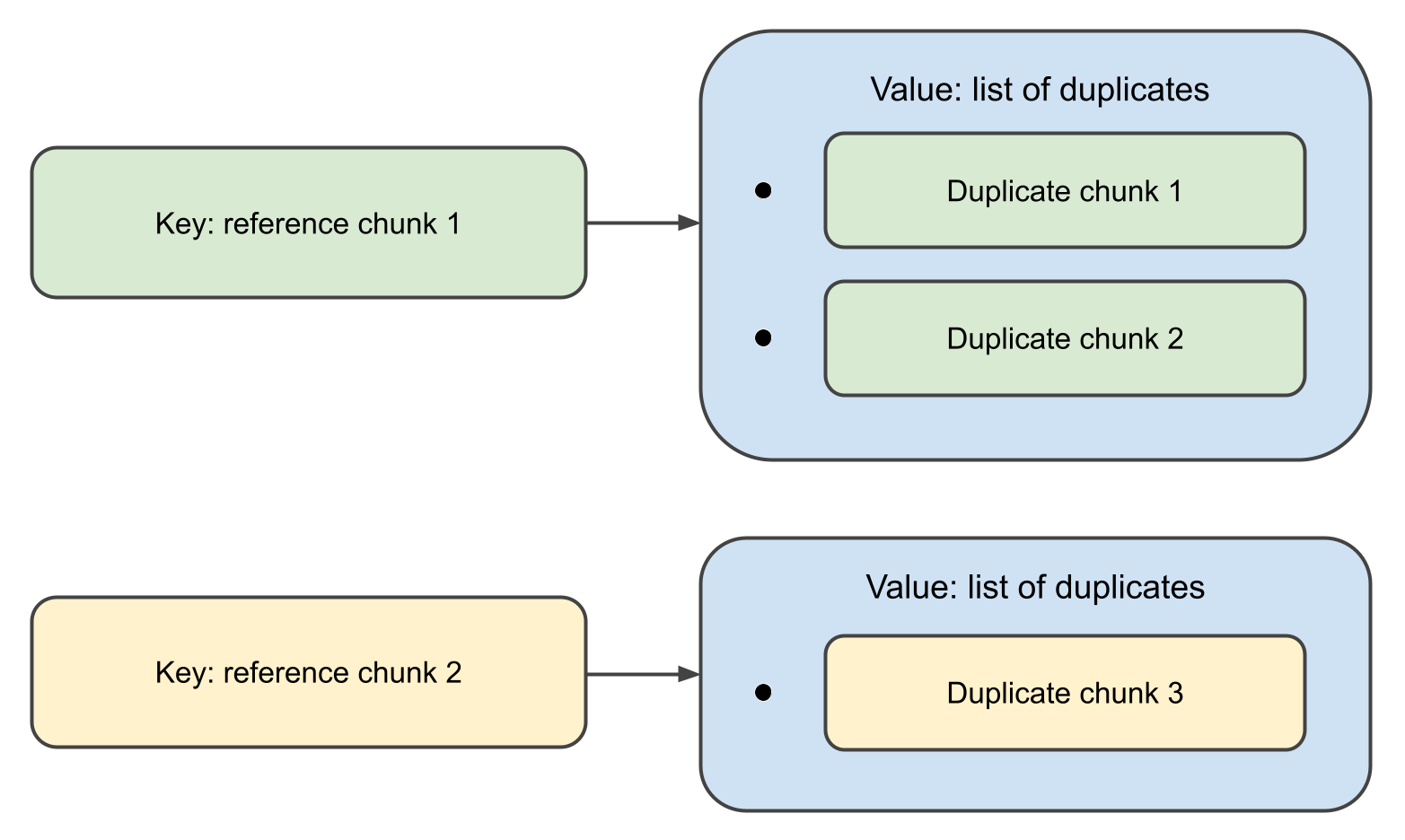
Cuando la función se completa, devolverá un map,
donde las claves son objetos Chunk , y los valores asociados son listas de sus duplicados.
De hecho, la definición anterior es innecesariamente detallada. Introducir una interfaz solo para una única función y unos pocos llamantes es demasiado. Kotlin tiene una forma elegante de manejar esto con funciones de primera clase:
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()Esta declaración significa que el buscador de duplicados es una función que toma
Path, DuplicateFinderOptions and outputs
Map<Chunk, List<Chunk>> ,
y que la función en sí misma aún no está implementada.
Esto podría no ser el mejor estilo para grandes proyectos, pero en los más pequeños como el nuestro,
funciona genial.
Datos de prueba
Dado que el buscador de duplicados está destinado a trabajar con datos de texto, las pruebas también necesitarán algunos textos para analizar. Esto significa que necesitamos preparar algunos ejemplos que contengan duplicados difusos. Comencemos con los duplicados:
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes."La idea detrás de FUZZY_MATCH_TEMPLATE
es que lo usaremos para producir programáticamente las coincidencias difusas reales:
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)A continuación, generaremos un texto compuesto de palabras aleatorias en inglés:
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}Finalmente, inyectaremos aleatoriamente EXACT_MATCH
y fuzzyMatches en el texto generado:
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}Pruebas
Como ya se mencionó, el objetivo principal de las pruebas en esta etapa es definir la especificación, así que no perdamos demasiado tiempo en perfeccionar el conjunto de pruebas. En cambio, escribiremos lo suficiente para asegurar que el código futuro se adhiera a los requisitos.
Este es el código de la clase de prueba:
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }Próximos pasos
Hemos establecido los requisitos al definir la interfaz y escribir las pruebas. En la próxima entrada de la serie, implementaremos el algoritmo real y veremos qué tan bien se desempeña. ¡Nos vemos pronto!