AIを用いたアプリケーションのローカライズ
他の言語: English Español Français Deutsch 한국어 Português 中文
プロジェクトをローカライズすべきか、またはどのように行うべきかを考えたり、その方法を学んでいるなら、AIを使って始めてみるのは良い選択肢かもしれません。 AIを使うことにより、実験や自動化のためのコスト効率の高いエントリーポイントを提供してくれます。
この投稿では、そのような実験を一緒に歩いていきます。やることは以下の通りです:
- オープンソースのアプリケーションを選びます
- 前提条件を確認し、それを実装します
- AIを使って翻訳フェーズを自動化します

まだローカリゼーションを扱ったことがなく、何から始めれば良いかわからない人にとって、ここから始めるのが一番いいと思います。 いくつかのテクニカルな詳細は除けば、このアプローチはほぼユニバーサルであり、他のタイプのプロジェクトでも適用することができます。
すでに基本的なことは理解していて、AIが動作しているのをただ見たいだけの人は、テキストを翻訳するまでスキップしたり、私のフォークをクローンしてコミットを読み進めたりして、結果を評価することもできます。
プロジェクトを取得する
ローカリゼーション実験だけのためにアプリケーションを作成するのは過度なようなので、オープンソースプロジェクトをフォークしましょう。私はSpring Petclinicを選びました。 Spring PetclinicはJavaのフレームワークであるSpringをデモンストレーションするための一例として使用されるWebアプリです。
gh repo fork https://github.com/spring-projects/spring-petclinic --clone=trueもしSpringを使ったことがないのであれば、一部のコードスニペットがあなたにとってはなじみがないものと思われますが、この議論は技術非依存であると既に述べております。 言語やフレームワークに関係なく、手順はほぼ同じです。
インターナショナライゼーション
アプリケーションがローカライズされる前に、インターナショナライズされる必要があります。
インターナショナライゼーション(略してi18nとも言います)は、ソフトウェアを異なる言語に対応するように適応させるプロセスです。 通常はUIの文字列を特別なファイル、通常はリソースバンドルと呼ばれるものに外部化することから始まります。
リソースバンドルは、異なる言語のテキスト値を保持します:
en.json:
{
"greeting": "Hello!",
"farewell": "Goodbye!"
}es.json:
{
"greeting": "¡Hola!",
"farewell": "¡Adiós!"
}これらの値がUIに反映されるためには、UIがこれらのファイルを使用するように明示的にプログラムする必要があります。
これは通常、UIテキストを特定のロケールの正しい値で置き換えることを目的とする、インターナショナライゼーションライブラリあるいは組み込みの言語機能が行います。 このようなライブラリの例としては、i18next(JavaScript)、Babel(Python)、go-i18n(Go)などがあります。
Javaはインターナショナライゼーションをネイティブでサポートしているので、プロジェクトに追加の依存関係を導入する必要はありません。
ソースを調査する
Javaはローカライズされたユーザーインターフェースの文字列を保管するために .properties という拡張子のファイルを利用します。
幸運なことに、このプロジェクトにはすでに これらのファイルがたくさん存在しています。 例えば、英語とスペイン語のための設定は以下の通りです:
welcome=Welcome
required=is required
notFound=has not been found
duplicate=is already in use
nonNumeric=must be all numeric
duplicateFormSubmission=Duplicate form submission is not allowed
typeMismatch.date=invalid date
typeMismatch.birthDate=invalid datewelcome=Bienvenido
required=Es requerido
notFound=No ha sido encontrado
duplicate=Ya se encuentra en uso
nonNumeric=Sólo debe contener numeros
duplicateFormSubmission=No se permite el envío de formularios duplicados
typeMismatch.date=Fecha invalida
typeMismatch.birthDate=Fecha invalidaすべてのプロジェクトがUIのテキストを外部化するわけではありません。 一部のプロジェクトでは、これらのテキストが直接アプリケーションのロジックにハードコードされていることもあります。

UIテキストの外部化はインターナショナライゼーションを超えた利点を持つ良い習慣です。 これはコードをメンテナンスしやすくするだけでなく、UIメッセージの一貫性を高めます。 もしあなたがプロジェクトを始めようとしているのであれば、できるだけ早期にi18nを実装することを検討してみてください。
テストラン
ロケールをURLパラメータで変更する方法を追加してみましょう。 これにより、すべてが完全に外部化されていて、少なくとも一つの言語に翻訳されているかどうかをテストすることができます。
これを実現するために、ロケールパラメータを管理する次のクラスを追加します:
import java.util.Locale;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public LocaleResolver localeResolver() {
SessionLocaleResolver slr = new SessionLocaleResolver();
slr.setDefaultLocale(Locale.US);
return slr;
}
@Bean
public LocaleChangeInterceptor localeChangeInterceptor() {
LocaleChangeInterceptor lci = new LocaleChangeInterceptor();
lci.setParamName("lang");
return lci;
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(localeChangeInterceptor());
}
}さまざまなロケールをテストできるようになったので、サーバーを起動して、いくつかのロケールパラメータでホームページを比較してみましょう:
- http://localhost:8080 – デフォルトのロケール
- http://localhost:8080/?lang=es – スペイン語
- http://localhost:8080/?lang=ko – 韓国語
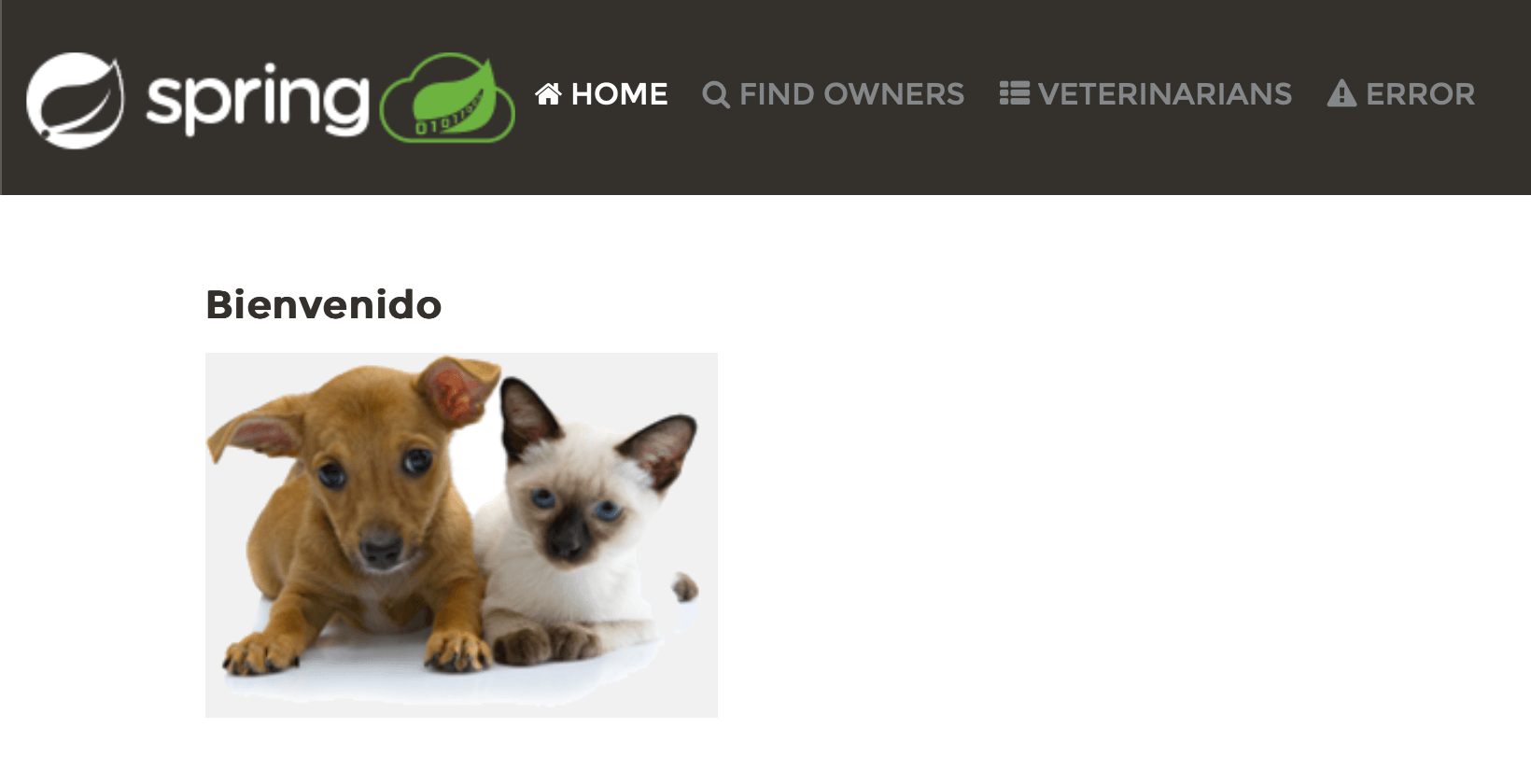
ロケールを変更するとUIが更新されるのがわかります。これは良いニュースです。 しかし、ロケールを変更してもテキストの一部しか影響を受けないようです。 例えばスペイン語では、WelcomeがBienvenidoに変わっていますが、ヘッダーのリンクは同じままで、 他のページも依然として英語です。これは私たちがまだするべき仕事があることを意味します。
テンプレートを修正する
Spring Petclinicプロジェクトはページを生成するためにThymeleafテンプレートを使用していますので、テンプレートファイルを調査してみましょう。
確かに、テキストの一部はハードコードされているので、コードを修正してリソースバンドルを参照するようにする必要があります。
幸運なことに、ThymeleafはJavaの .properties ファイルをよくサポートしているので、テンプレートにリソースバンドルキーの参照を直接組み込むことができます:
<h2>Find Owners</h2><h2 th:text='#{heading.find.owners}'>Find Owners</h2>heading.find.owners=Find Owners以前のハードコードされたテキストはまだ存在していますが、それは今はフォールバック値としての役割を果たし、それは適切なローカライズメッセージの取得にエラーが発生した場合にのみ使われます。
残りのテキストも同様に外部化されますが、いくつか特別な注意を必要とする場所があります。 例えば、いくつかの警告はバリデーションエンジンから来ており、Javaのアノテーションパラメータを使って指定する必要があります:
@Column(name = "first_name")
@NotBlank
private String firstName;@Column(name = "first_name")
@NotBlank(message = "{field.validation.notblank}")
private String firstName;いくつかの部分で、ロジックを変更する必要があります:
<h2>
<th:block th:if="${pet['new']}">New </th:block>Pet
</h2>上記の例では、テンプレートは条件を使用しています。もし new 属性が存在すれば、NewがUIテキストに追加されます。
その結果、結果として出力されるテキストは、属性の存在に応じてNew PetまたはPetとなります。
これは一部のロケールでのローカライゼーションを破る可能性があります。なぜなら、名詞と形容詞の合意によります。たとえば、スペイン語では、形容詞は名詞の性別により Nuevo または Nueva となり、既存のロジックはこの区別を考慮に入れていません。
この状況を解消するための方法はいくつかあります。1つは、ロジックをさらに洗練されたものにすることです。 しかし、可能な限り複雑なロジックは避けた方が良いと一般的に考えられているので、私はブランチを分離することにしました:
<h2>
<th:block th:if="${pet['new']}" th:text="#{pet.new}">New Pet</th:block>
<th:block th:unless="${pet['new']}" th:text="#{pet.update}">Pet</th:block>
</h2>別々のブランチは翻訳プロセスとコードベースの将来のメンテナンスを簡素化します。
New Petフォームもまた一筋縄ではいきません。そのTypeドロップダウンは、ペットタイプのコレクションを selectField.html テンプレートに渡すことで作られます:
<input th:replace="~{fragments/selectField :: select (#{pet.type}, 'type', ${types})}" />他のUIテキストとは異なり、ペットタイプはアプリケーションのデータモデルの一部です。 それらはランタイムでデータベースから取得されます。 このデータの動的な性質により、テキストを直接プロパティーバンドルに抽出することができません。
これに対処する方法もいくつかあります。1つの方法は、テンプレート内でプロパティーバンドルキーを動的に構築することです:
<option th:each="item : ${items}"
th:value="${item}"
th:text="${item}">dog</option><option th:each="item : ${items}"
th:value="${item}"
th:text="#{'pettype.' + ${item}}">dog</option>このアプローチでは、UIに直接 cat をレンダリングする代わりに、それに pettype. を接頭辞として付け、その結果として得られる pettype.cat を使ってローカライズされたUIテキストを取得します:
pettype.bird=bird
pettype.cat=cat
pettype.dog=dogpettype.bird=pájaro
pettype.cat=gato
pettype.dog=perro
あなたは私たちが再利用可能なコンポーネントのテンプレートを変更したことに気づいたかもしれません。 再利用可能なコンポーネントは複数のクライアントに対応するために存在するので、その中にクライアントのロジックを持ち込むのは適切ではありません。
特にこのケースでは、ドロップダウンリストコンポーネントはペットタイプに縛られてしまい、それ以外のものを使いたい人たちにとっては問題となります。
この欠点は最初から存在していました。オプションのデフォルトテキストとして dog を見てみてください。
これはその欠点がさらに広がっただけです。
これは実際のプロジェクトでは行われるべきではなく、リファクタリングが必要です。
もちろん、国際化のためにもっとプロジェクトのコードが必要ですが、残りの部分は主に前述の例に沿っています。 私のすべての変更を完全にチェックしたい場合、 私のフォークでコミットを確認 していただくことを歓迎します。
不足しているキーの追加
ユーザーインターフェースのテキストをすべてプロパティパッケージのキーへの参照に置き換えた後、新たに追加されたすべての キーが導入されていることを確認する必要があります。この段階では何も翻訳する必要はありません、単にキーと元のテキストを messages.properties ファイルに追加するだけです。
IntelliJ IDEAはThymeleafをサポートしています。テンプレートが欠けているプロパティを参照している場合を検出するので、あまり手作業でチェックすることなく、どれが欠けているかを特定することができます。
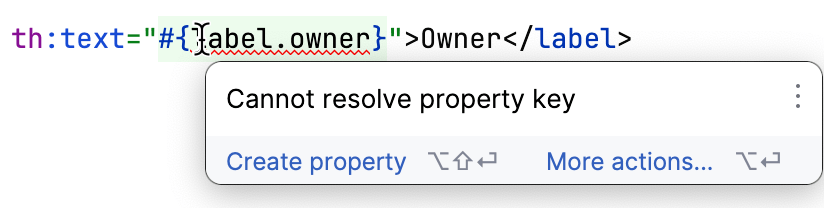
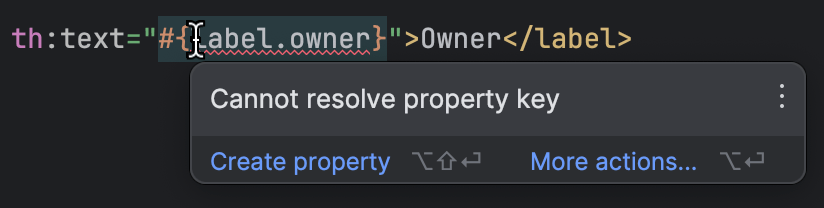
すべての準備が整ったら、仕事の最も面白い部分に入ります。 すべてのキーを持っていて、すべての値を英語で持っています。 他の言語の値はどこから入手するのでしょうか?
テキストを翻訳する
テキストを翻訳するために、外部の翻訳サービスを使うスクリプトを作成します。 利用できる翻訳サービスは数多くあり、スクリプトを書く方法もさまざまです。 私は実装にあたって以下の選択をしました:
- プログラミング言語としてPython、なぜなら小さなタスクを非常に早くプログラミングできるからです。
- DeepL を翻訳サービスとして選びました。 もともとは OpenAIのGPT3.5 Turboを使う予定でしたが、それは厳密には翻訳モデルではなく、プロンプトを設定するために追加の努力が必要でした。 また、結果が安定しない傾向があるため、最初に思いついた専用の翻訳サービスを選びました。
詳細な調査は行っていないので、これらの選択はある程度恣意的なものです。 思う存分実験して、あなたにとって最適なものを見つけてください。
下記のスクリプトを使う場合は、DeepLにアカウントを作成し、
個人のAPIキーを環境変数 DEEPL_KEY を通じてスクリプトに渡す必要があります。
このスクリプトがそれです:
import os
import requests
import json
deepl_key = os.getenv('DEEPL_KEY')
properties_directory = "../src/main/resources/messages/"
def extract_properties(text):
properties = {}
for line in text:
line = line.strip()
if line and not line.startswith('#') and '=' in line:
key_value = line.split('=')
key = key_value[0].strip()
value = key_value[1].strip()
if key and value:
properties[key] = value
return properties
def missing_properties(properties_file, properties_checklist):
with open(properties_file, 'r') as f:
text = f.readlines()
present_properties = extract_properties(text)
missing = {k: v for k, v in properties_checklist.items() if k not in present_properties.keys()}
return missing
def translate_property(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'DeepL-Auth-Key {deepl_key}',
'User-Agent': 'LocalizationScript/1.0'
}
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()["translations"][0]["text"]
def populate_properties(file_path, properties_checklist, target_lang):
with open(file_path, 'a+') as file:
properties_to_translate = missing_properties(file_path, properties_checklist)
for key, value in properties_to_translate.items():
new_value = translate_property(value, target_lang)
property_line = f"{key}={new_value}\n"
print(property_line)
file.write(property_line)
with open(properties_directory + 'messages.properties') as base_properties_file:
base_properties = extract_properties(base_properties_file)
languages = [
# configure languages here
"nl", "es", "fr", "de", "it", "pt", "ru", "ja", "zh", "fi"
]
for language in languages:
populate_properties(properties_directory + f"messages_{language}.properties", base_properties, language)
このスクリプトはデフォルトのプロパティパッケージ( messages.properties )からキーを抽出し、 ロケール特有のパッケージでそれらの翻訳を探します。 あるキーが翻訳を欠いていることを検出した場合、スクリプトはDeepLのAPIに翻訳を求め、 それをプロパティパッケージに追加します。
私は10のターゲット言語を指定しましたが、DeepLが サポートしている限り、リストを修正したり、あなたが好む言語を追加したりすることができます。
スクリプトはさらに最適化して、翻訳のためのテキストを50件のバッチで送信することができます。ここではシンプルに保つためにそうはしていません。
後で、私はスクリプトを更新して、構造化された出力を持つLLMを使用しました。 あなたはここで結果を確認できます。
スクリプトの実行
10の言語でスクリプトを実行するのに約5分かかりました。 使用パネルには8348文字が表示され、有料プランであれば €0.16になっただろうと推測されます。
その結果、以下のファイルが生成されます:
- messages_fi.properties
- messages_fr.properties
- messages_it.properties
- messages_ja.properties
- messages_nl.properties
- messages_pt.properties
- messages_ru.properties
- messages_zh.properties
さらに、以下に不足していたプロパティが追加されます:
- messages_de.properties
- messages_es.properties
でも、実際の翻訳はどうなのでしょうか?既に確認できますか?
結果の確認
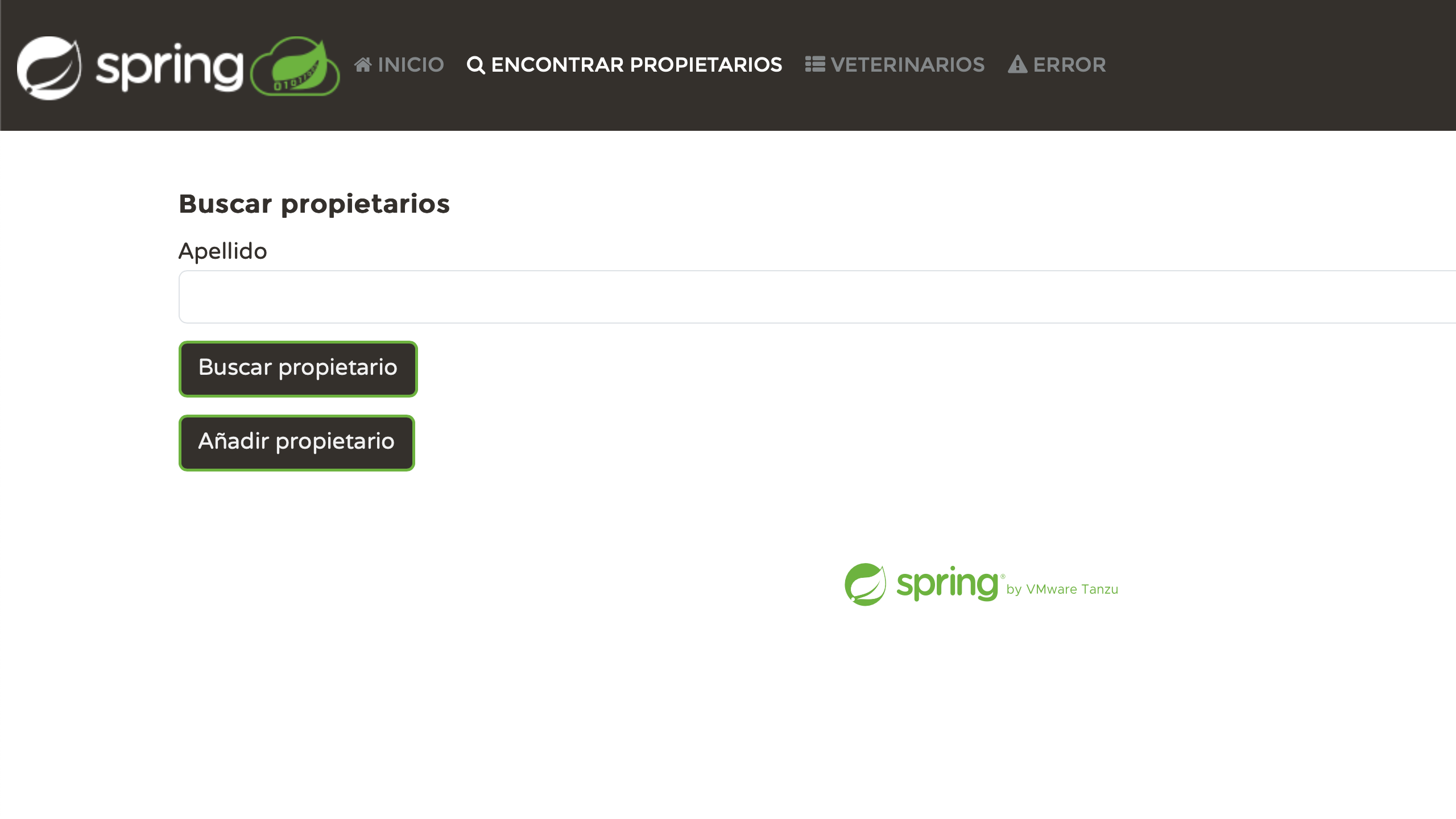
アプリケーションを再起動し、 lang パラメータの異なる値を使ってテストしてみましょう。例えば、
- http://localhost:8080/?lang=es
- http://localhost:8080/?lang=nl
- http://localhost:8080/?lang=zh
- http://localhost:8080/?lang=fr
個人的には、各ページが正しくローカライズされているのを見て非常に満足しています。 私たちはいくらか努力を注いできましたが、今では結果が出てきました:


問題に取り組む
結果は素晴らしいものです。しかし、よく注意を払ってみると、コンテキストの欠如が原因で発生するエラーを発見するかもしれません。例えば:
visit.update = Visit Visit は名詞でも動詞でもあります。追加のコンテキストがない場合、翻訳サービスは一部の言語で間違った翻訳を出力します。
これは、手動で編集するか、翻訳のワークフローを調整するかのいずれかで解決することができます。 一つの可能な解決策は、 .properties ファイルでコメントを使用してコンテキストを提供することです:
# Noun. Heading. Displayed on the page that allows the user to edit details of a veterinary visit
visit.update = Visitその後、翻訳スクリプトを修正して、そのようなコメントを解析し、
context パラメータとともに渡すことができます:
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True,
'context': context
}さらに深く掘り下げて、さらに多くの言語を考えると、改善が必要となることがもっと出てくるかもしれません。 これは反復的なプロセスです。
このプロセスで不可欠なのは、レビューとテストです。私たちが自動化を改良しようと、その出力を編集しようと、品質管理と評価を行うことが必要となることを発見するでしょう。
範囲を超えて
Spring Petclinicは、リアルな問題を解決するシンプルなプロジェクトです。 もちろん、ローカライズにはこの記事の範囲を超える多くの課題があります。例えば:
- ターゲットの文法規則に合わせてテンプレートを適応させる
- 通貨、日付、数値の形式
- RTLのような異なる読み方のパターン
- テキストの長さが変わるときのユーザーインターフェースの適応
これらの主題それぞれが独立した記事に値します。 もしもっと読みたいと思われたら、これらのトピックを別の投稿で取り上げることをうれしく思います。
まとめ
さて、私たちのアプリケーションのローカライズが終わったので、学んだことを振り返ってみましょう:
- ローカライズは単にテキストを翻訳するだけではなく、関連する資産、サブシステム、プロセスにも影響を与えます
- AIはローカライズの一部のステップで非常に効率的ではありますが、 最高の結果を得るためには人間による監督とテストが依然として必要です
- 自動翻訳の品質は、コンテキストの可用性や、 LLMの場合は、適切に書かれた通知など、さまざまな要素に依存します
この記事が気に入っていただけたら幸いです、そしてあなたのフィードバックを聞くのが楽しみです!後続の質問や提案がある場合、または単におしゃべりしたいだけの場合でも、遠慮なくご連絡ください。
今後の投稿でお会いしましょう!