Analise o IntelliJ IDEA com ele mesmo
Outras línguas: English Español Français Deutsch 日本語 한국어 中文
Assim como o post anterior, este também será um pouco meta. Obviamente, você pode usar o IntelliJ IDEA para perfilar outro processo, mas você sabia que o IntelliJ IDEA pode perfilar a si mesmo?

Isso pode ser útil se você estiver escrevendo um plugin para IntelliJ IDEA e precisar resolver problemas relacionados ao desempenho do plugin. Além disso, independentemente de você ser um autor de plugins, esse cenário pode ser interessante para você porque a estratégia de perfilamento que vou cobrir não é exclusiva do IntelliJ IDEA - você pode usá-la para solucionar gargalos semelhantes em outros tipos de projetos e usando outras ferramentas.
O problema
Neste post, vamos analisar um gargalo de desempenho bastante interessante em que tropecei há alguns anos.
Enquanto trabalhava em um projeto paralelo no IntelliJ IDEA, notei que
encontrar testes Navigate | Test para classes com certos nomes curtos, como A ,
era surpreendentemente lento, muitas vezes levando 2 minutos ou mais.

A presença do gargalo não parecia depender do tamanho do projeto -
mesmo em projetos que consistem em uma única classe chamada A ,
a navegação ainda demoraria muito.
Eu nunca experimentei atrasos relacionados a este recurso mesmo no enorme
monorepo do IntelliJ IDEA, então a desaceleração em um projeto quase vazio parecia especialmente curiosa.
Por que isso estava acontecendo? E, mais importante, como abordar problemas semelhantes, caso você os encontre no seu projeto?
Recriar o ambiente
Originalmente escrevi este artigo para uso interno na JetBrains, no entanto, a ideia de torná-lo público só me ocorreu recentemente. Felizmente, com o passar do tempo, o artigo não envelheceu bem, e o problema parece não ser mais reproduzível nas versões atuais do IntelliJ IDEA e em hardware mais recente.
Como eu não consegui reproduzir a desaceleração na minha configuração de trabalho, me vi tirando a poeira do meu antigo laptop e instalando uma versão anterior do IntelliJ IDEA nele. Se você quiser seguir a investigação em seu IDE, certifique-se de clonar o IntelliJ IDEA Community Edition, pois isso facilitará a navegação e a depuração para você.
Vamos também certificar de que temos um projeto vazio com a seguinte classe nele:
public class A {
public static void main(String[] args) {
System.out.println("I like tests");
}
}IntelliJ Profiler
Como você já sabe, o IntelliJ IDEA possui um JVM profiler integrado. Você pode lançar aplicações com o profiler anexado. Alternativamente, você pode anexar o profiler a um processo já em execução, que é o que vamos fazer.
Para isso, vá para a janela de ferramentas Profiler e encontre o processo correspondente lá. Se você não vê seu IDE na lista, certifique-se de marcar Show Development Tools no menu próximo a Process. Quando você clica em um processo, o IntelliJ IDEA sugere as ferramentas integradas de análise de desempenho, que permitem que você:
- perfil uso de CPU e alocações de memória
- analisar o heap da JVM
- capturar thread dumps
- monitorar o consumo de recursos em tempo real
Todas essas ferramentas são abordadas na documentação, e neste post vamos nos concentrar especificamente no profiler.
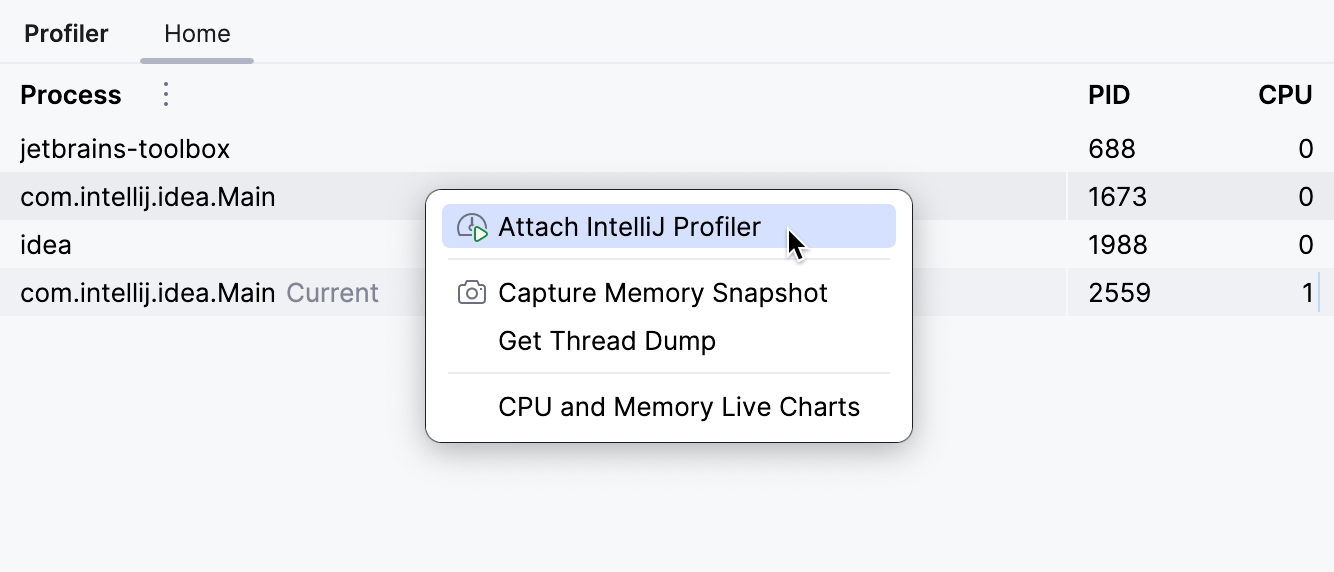
Precisamos anexá-lo antes de o problema acontecer. Por exemplo, se o problema surge como resultado da chamada de alguma API, anexe o profiler ao processo primeiro e depois reproduza os eventos que causam o problema.

Idealmente, devemos anexar o profiler logo antes de reproduzir o problema. Se sua aplicação está ocupada fazendo outra coisa além de apenas esperar por uma entrada, essa abordagem vai ajudar você a minimizar as amostras irrelevantes.
Dependendo de quanto tempo o código problemático leva para executar, também pode fazer sentido reproduzir o problema várias vezes, para que o profiler possa coletar mais amostras para análise. Isso fará com que o problema se destaque mais no relatório resultante.
Quando você desanexa o profiler ou encerra o processo, o IntelliJ IDEA abre automaticamente a foto instantânea resultante.
Analisando o relatório
Para analisar as fotos instantâneas, você tem várias visões à sua disposição. Você pode escolher examinar árvores de chamadas, estatísticas para métodos específicos, carga de CPU por thread, atividade de GC e mais.
Para o problema em questão, vamos começar com a visão Timeline para ver se podemos identificar algo incomum:
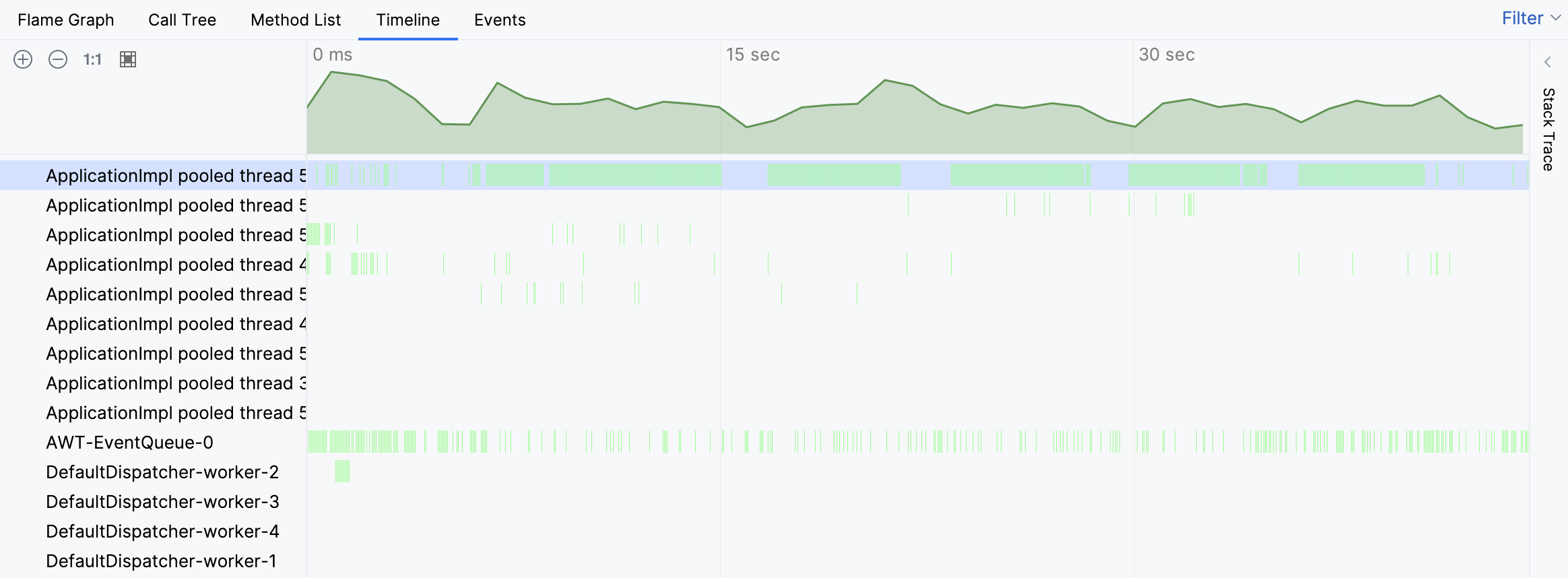
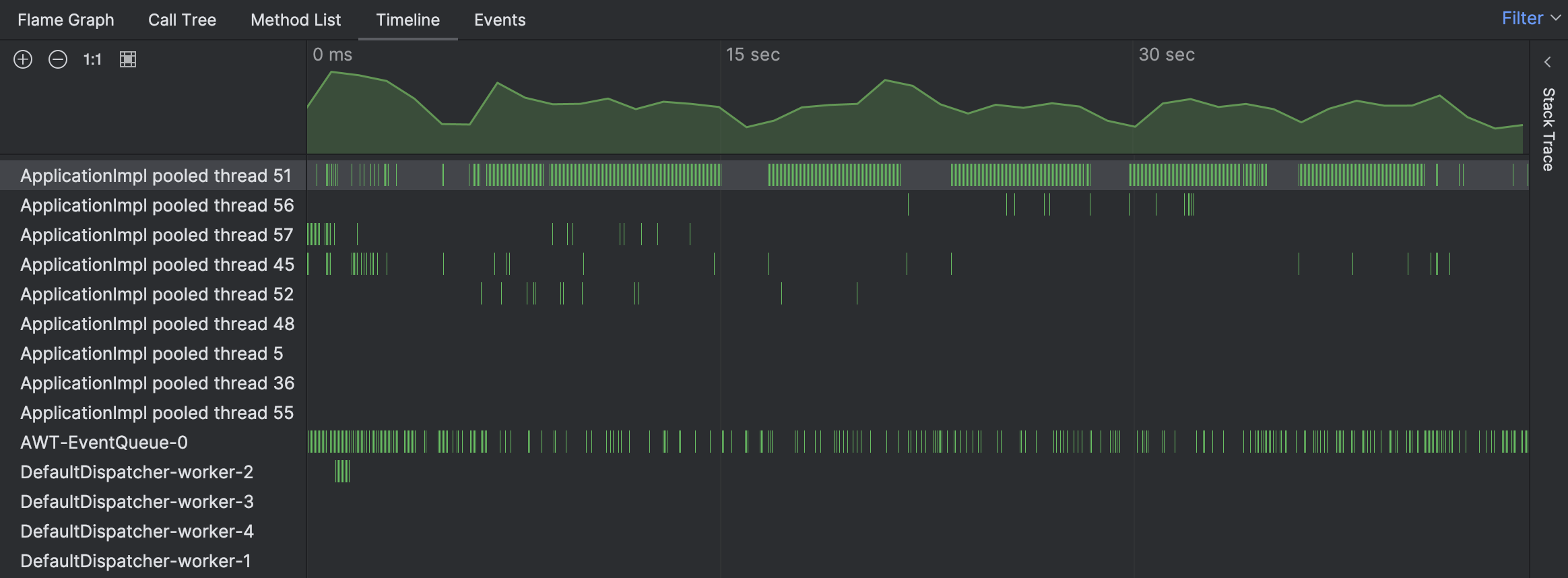
De fato, a linha do tempo indica que uma das threads estava extraordinariamente ocupada. As barras verdes correspondem às amostras coletadas para uma thread específica. Ao clicar em qualquer uma dessas barras, podemos ver o rastreamento de pilha correspondente para a amostra.
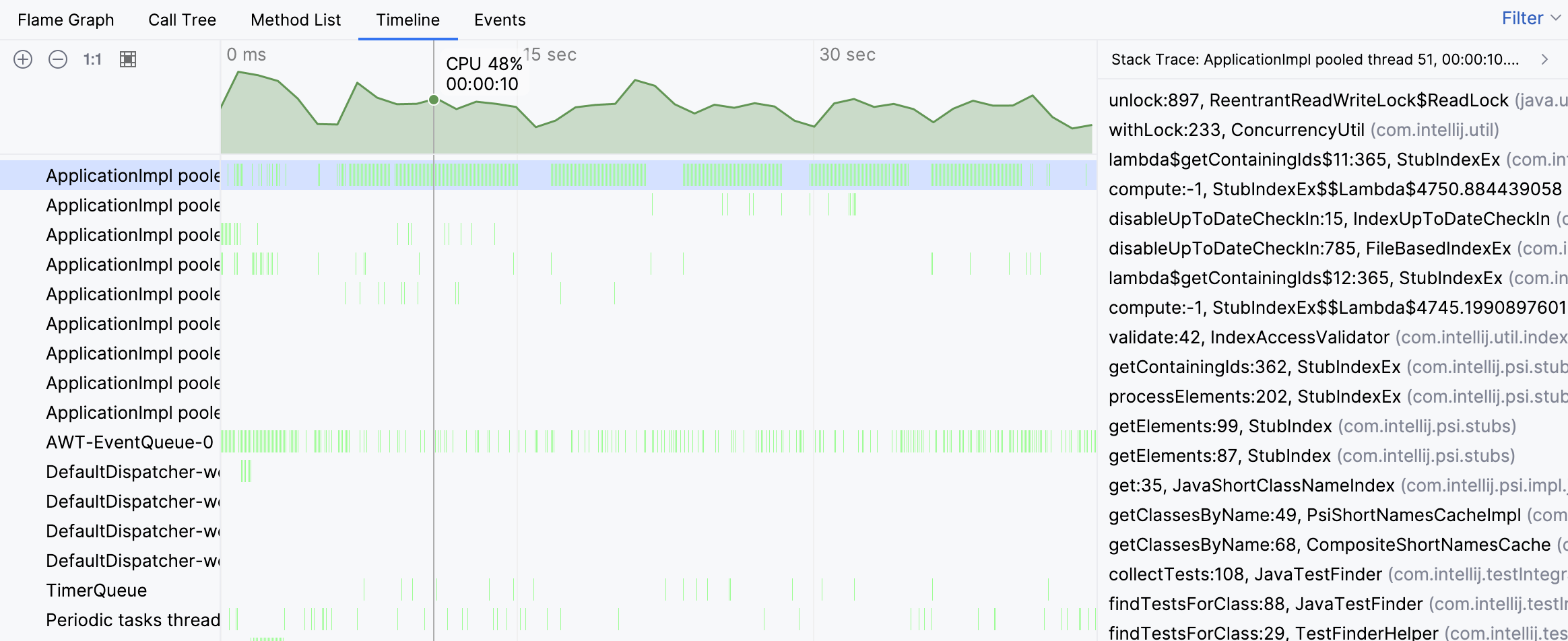
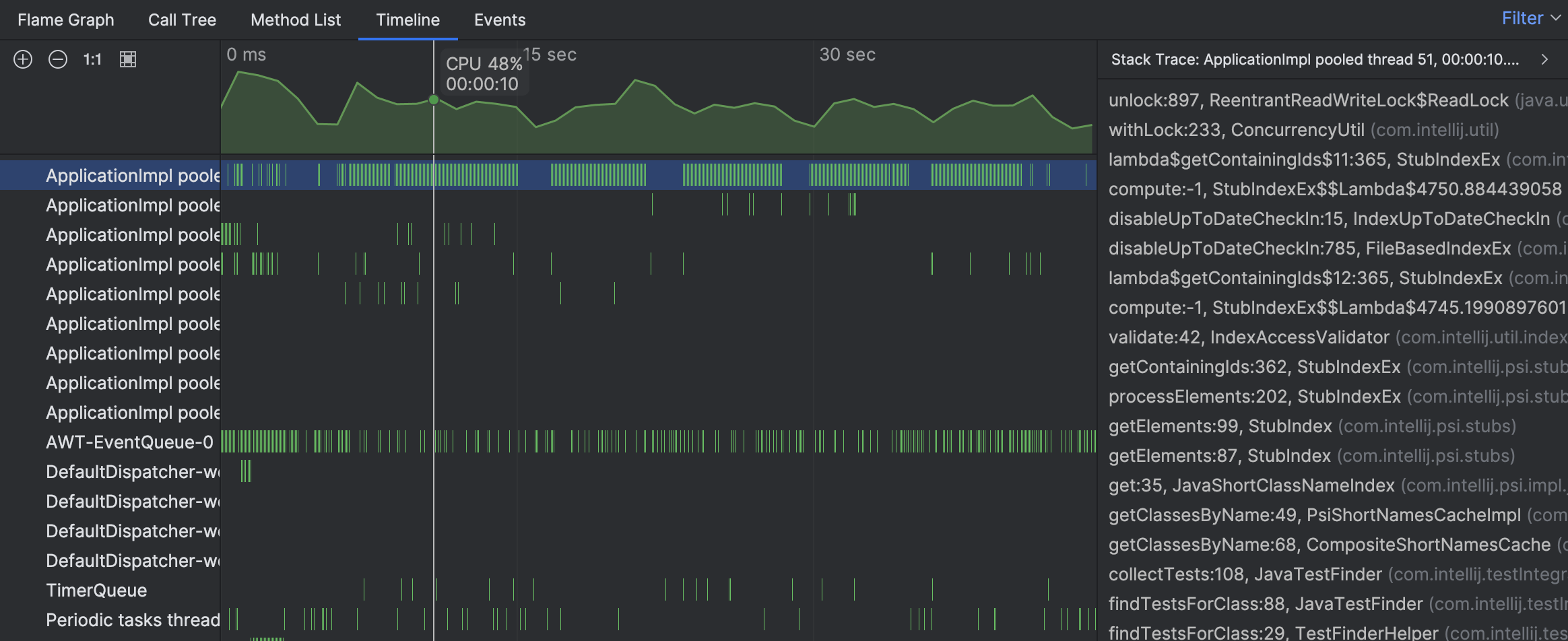
Os rastreamentos de pilha das amostras individuais sugerem que a atividade da thread está associada à procura de testes. No entanto, ainda não vemos o quadro geral. Vamos navegar para a thread ocupada no gráfico de chamas:

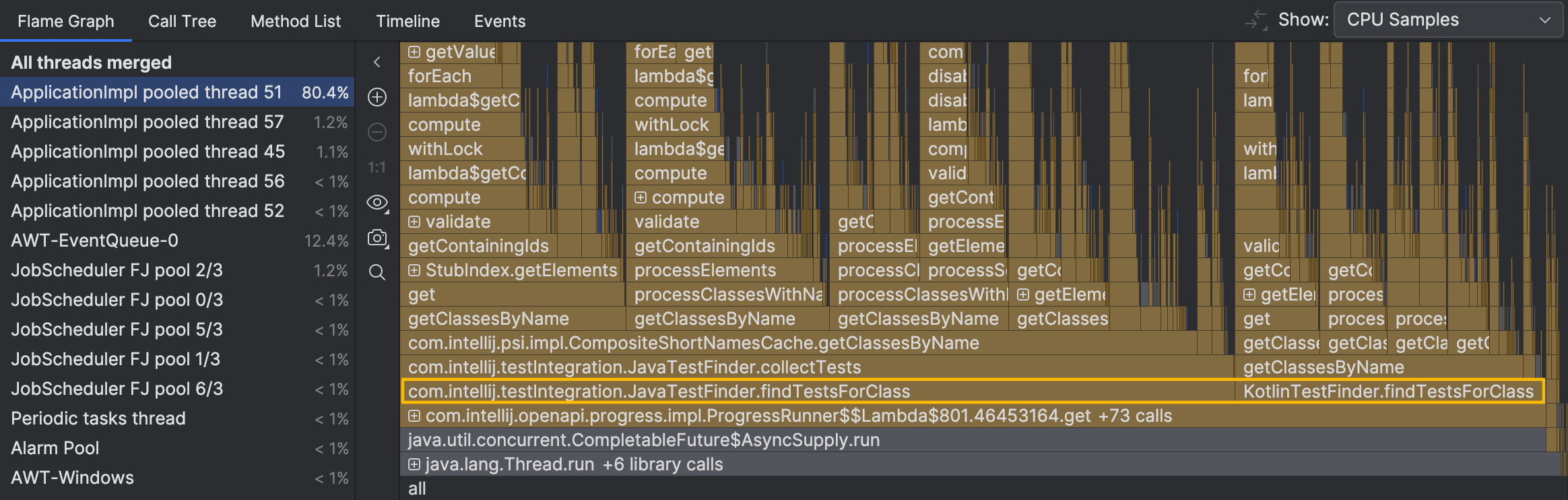
Os métodos que podem nos interessar,
JavaTestFinder.findTestsForClass() e KotlinTestFinder.findTestsForClass() ,
estão bem no fundo do gráfico.
Não levamos em conta os métodos dobrados abaixo deles, pois eles não têm tempo próprio significativo ou ramificação.
Eles controlam o fluxo em vez de realizar cálculos intensos.
Para verificar se esses métodos estão realmente relacionados à desaceleração,
podemos fazer o perfil de um caso não problemático:
procurar por testes para uma classe com um nome mais realista, por exemplo,
ClassWithALongerName .
Em seguida, veremos o que acontece com esses métodos usando a visão de diferença.


A foto instantânea mais recente contém 93-95% menos amostras
com JavaTestFinder.findTestsForClass()
e KotlinTestFinder.findTestsForClass() .
O tempo de execução dos outros métodos não difere tanto.
Parece que estamos indo na direção certa.
A próxima pergunta é por que isso acontece. Vamos tentar descobrir isso com o depurador.
Por que uma diferença tão grande?
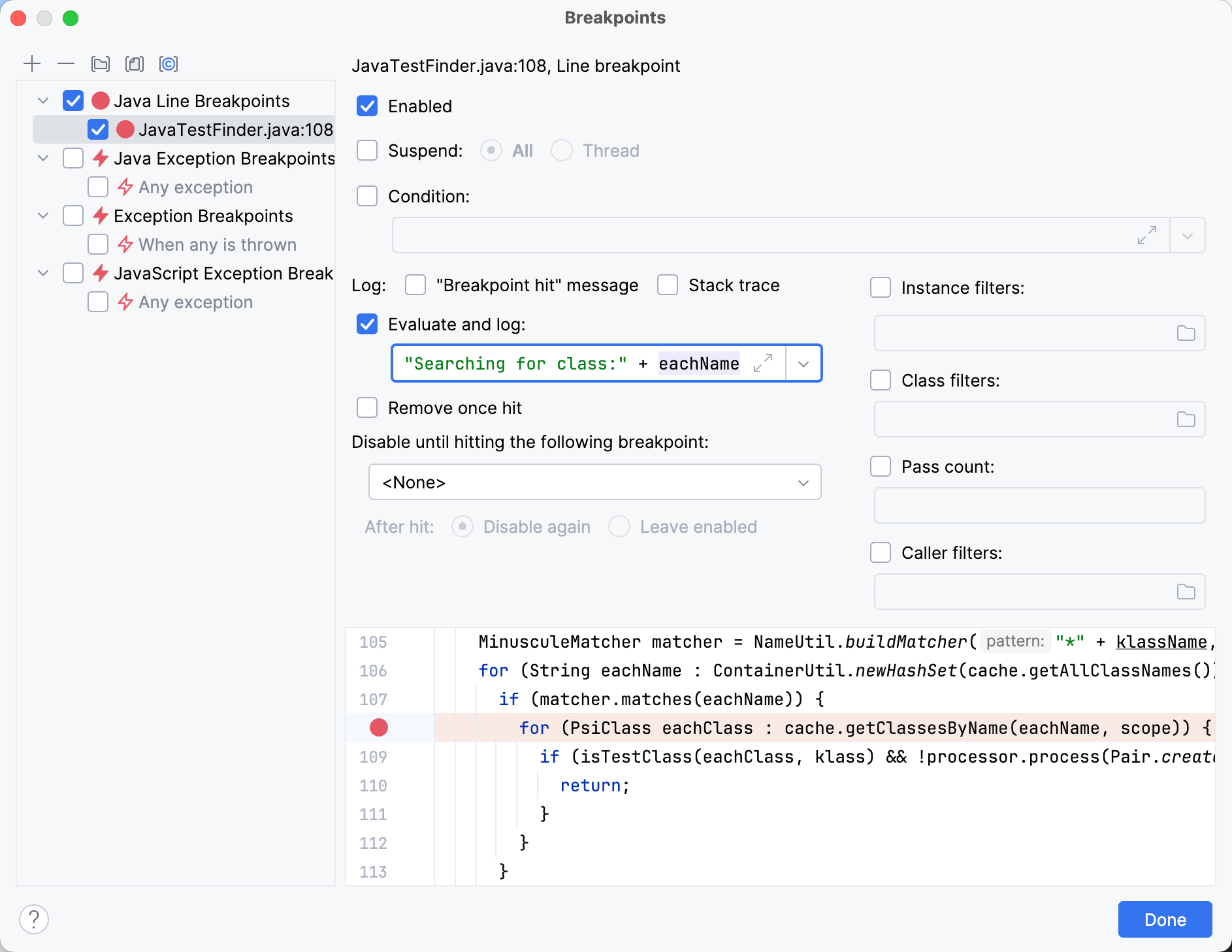
Configurando um ponto de interrupção em findTestsForClass() e um pouco de
passo a passo pelo código, nos traz ao seguinte ponto:
MinusculeMatcher matcher = NameUtil.buildMatcher("*" + klassName, NameUtil.MatchingCaseSensitivity.NONE);
for (String eachName : ContainerUtil.newHashSet(cache.getAllClassNames())) {
if (matcher.matches(eachName)) {
for (PsiClass eachClass : cache.getClassesByName(eachName, scope)) {
if (isTestClass(eachClass, klass) && !processor.process(Pair.create(eachClass, TestFinderHelper.calcTestNameProximity(klassName, eachName)))) {
return;
}
}
}
}O código está filtrando os nomes curtos que estão atualmente no cache usando uma expressão regular. Para cada uma das strings resultantes, ele procura as classes correspondentes.
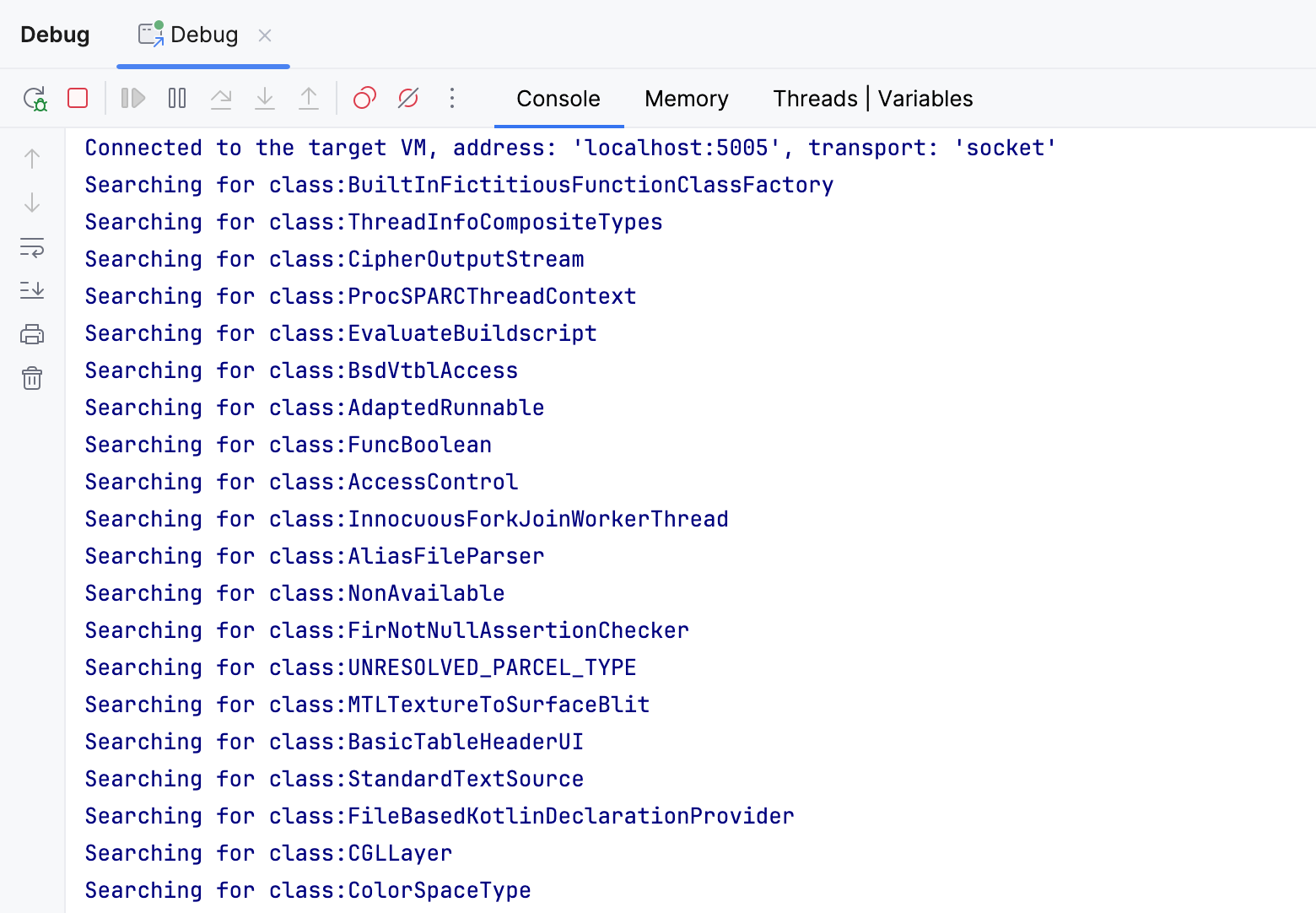
Ao registrar os nomes das classes após a condição, obtemos todas as classes que passam por ela.
Quando eu executei o programa, foram registradas cerca de 25000 classes, um número surpreendentemente grande para um projeto vazio!
Os nomes de classe registrados estão claramente vindo de algum outro lugar, não do meu projeto ‘Hello World’.
O mistério é resolvido: o IntelliJ IDEA demora tanto para encontrar testes para a classe A ,
porque verifica todas as classes armazenadas em cache, incluindo dependências, JDKs e até classes de outros projetos.
Muitos deles passam pelo filtro porque todos eles têm
a letra A em seus nomes.
Com nomes de classe mais longos e mais realistas, essa ineficiência teria permanecido despercebida,
apenas porque a maioria desses nomes teria sido filtrada pela regex.
A solução?
Infelizmente, não consegui encontrar uma solução simples e confiável para este problema. Uma estratégia potencial seria excluir dependências do escopo de pesquisa. Isso parece viável à primeira vista, mas existe a possibilidade de que as dependências possam conter testes. Isso não acontece com frequência, mas ainda assim, essa abordagem quebraria o recurso para tais dependências.
Uma abordagem alternativa é introduzir uma máscara de arquivo *.java, que filtraria as classes compiladas.
Enquanto funciona bem com o Java, ele se torna problemático para testes escritos em outras linguagens, como o Kotlin.
Mesmo que adicionemos todas as linguagens possíveis, esse recurso falhará silenciosamente para as novas suportadas,
resultando em sobrecarga adicionada para manutenção e depuração.
Independentemente da abordagem, a solução requer uma postagem própria, então não estamos implementando-a agora. O que fizemos, no entanto, foi descobrir a causa raiz de uma desaceleração, que é exatamente por que alguém usaria um profiler.
Compartilhe a foto instantânea
Antes de terminar, há mais uma coisa que vale a pena discutir. Você notou que usei uma foto instantânea tirada em um computador diferente? Além disso, a foto instantânea não era apenas de uma máquina diferente. O sistema operacional e a versão do IntelliJ IDEA também eram diferentes.
Uma coisa bonita que muitas vezes é esquecida sobre o profiler é a facilidade de compartilhar os dados. A foto instantânea é escrita em um arquivo, que você pode enviar para outra pessoa (ou receber de alguém). Em contraste com outras ferramentas, como o depurador, você não precisa de um reprodutor completo para começar com a análise. De fato, você nem mesmo precisa de um projeto compilável para isso.
Não acredite em minha palavra; experimente você mesmo. Aqui está a foto instantânea: idea64_exe_2024_07_22_113311.jfr