开始使用分配剖析
阅读其他语言: English Español Français Deutsch 日本語 한국어 Português
我们经常发现自己处于这样的情况:代码运行不正常,而我们完全不知道从哪里开始调查。
难道我们不能只是盯着代码看,直到解决方案最终出现吗?当然可以,但这种方法在没有深入项目知识和大量脑力劳动的情况下可能行不通。更聪明的方法是使用手头的工具。它们可以为我们指明正确的方向。

在这篇文章中,我们将探讨如何通过剖析内存分配来解决运行时问题。
问题
让我们从克隆以下仓库开始:https://github.com/flounder4130/party-parrot
使用项目中包含的Parrot运行配置启动应用程序。应用程序似乎运行良好:您可以调整动画的颜色和速度。然而,不久之后事情就开始出错了。
工作一段时间后,动画冻结,没有任何指示问题的原因。程序有时会抛出 OutOfMemoryError ,其堆栈跟踪并没有告诉我们问题的来源。
问题的具体表现方式并不确定。这个动画冻结的有趣之处在于,在它发生后,我们仍然可以使用UI的其余部分。

我使用Amazon Corretto 11运行此应用。在其他JVM上或即使在相同的JVM上使用不同配置,结果可能会有所不同。
调试器
看来我们遇到了一个错误。让我们尝试使用调试器!以调试模式启动应用程序,等待动画冻结,然后点击暂停程序。
不幸的是,这并没有告诉我们太多,因为所有参与鹦鹉派对的线程都处于等待状态。检查它们的堆栈没有给出冻结原因的任何线索。显然,我们需要尝试另一种方法。
监控资源使用情况
既然我们收到了 OutOfMemoryError , 分析的一个好起点是CPU 和内存实时图表 (CPU and Memory Live Charts)。
它们使我们能够可视化正在运行的进程的实时资源使用情况。让我们为我们的鹦鹉应用打开这些图表,看看在动画冻结时是否能发现什么。
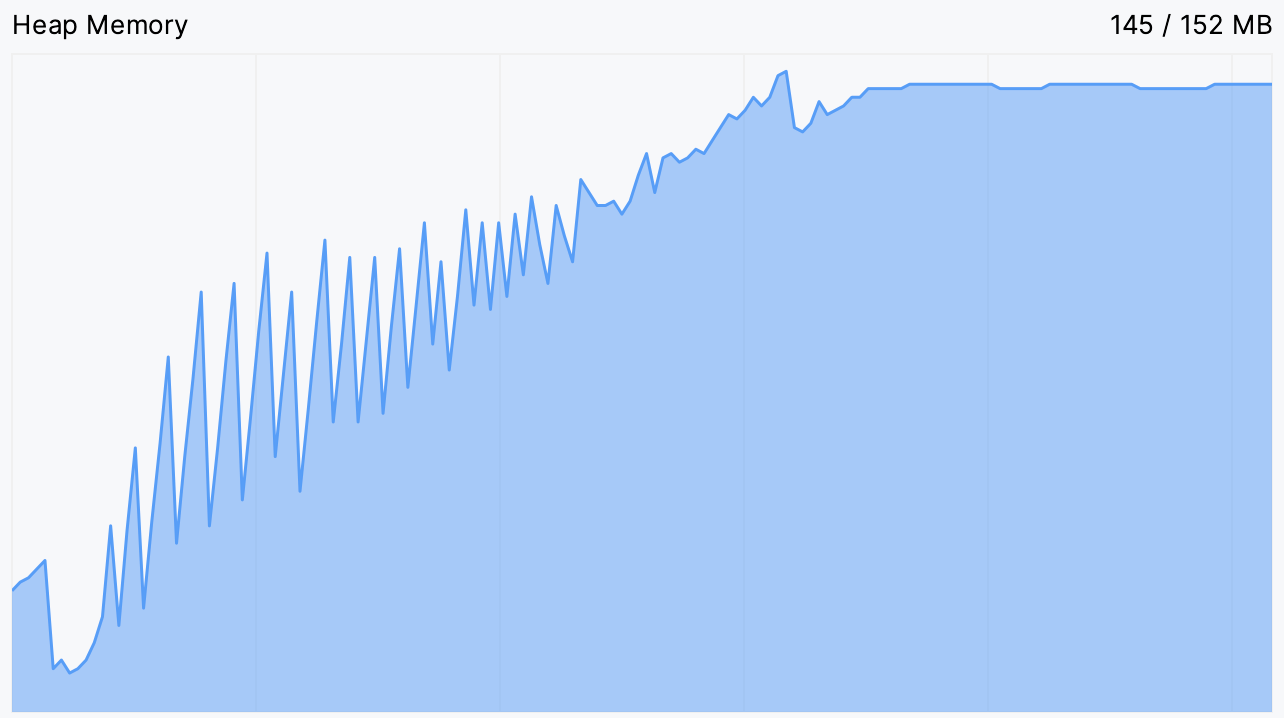
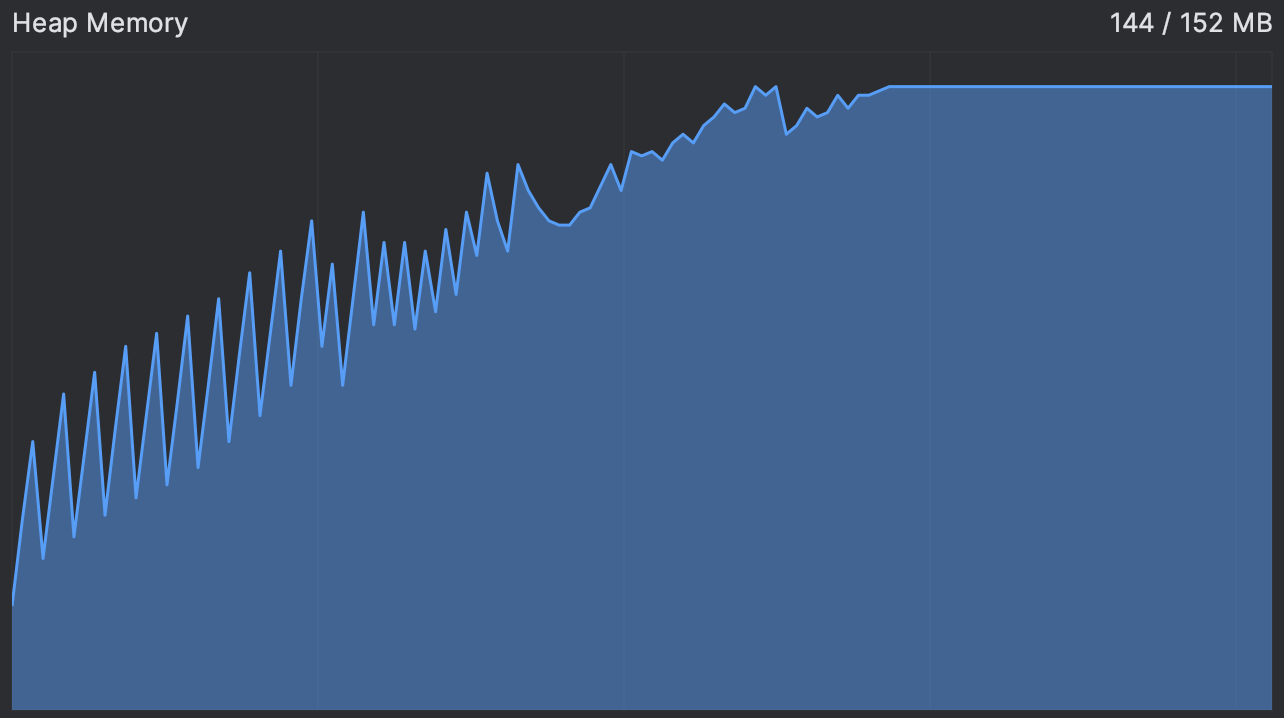
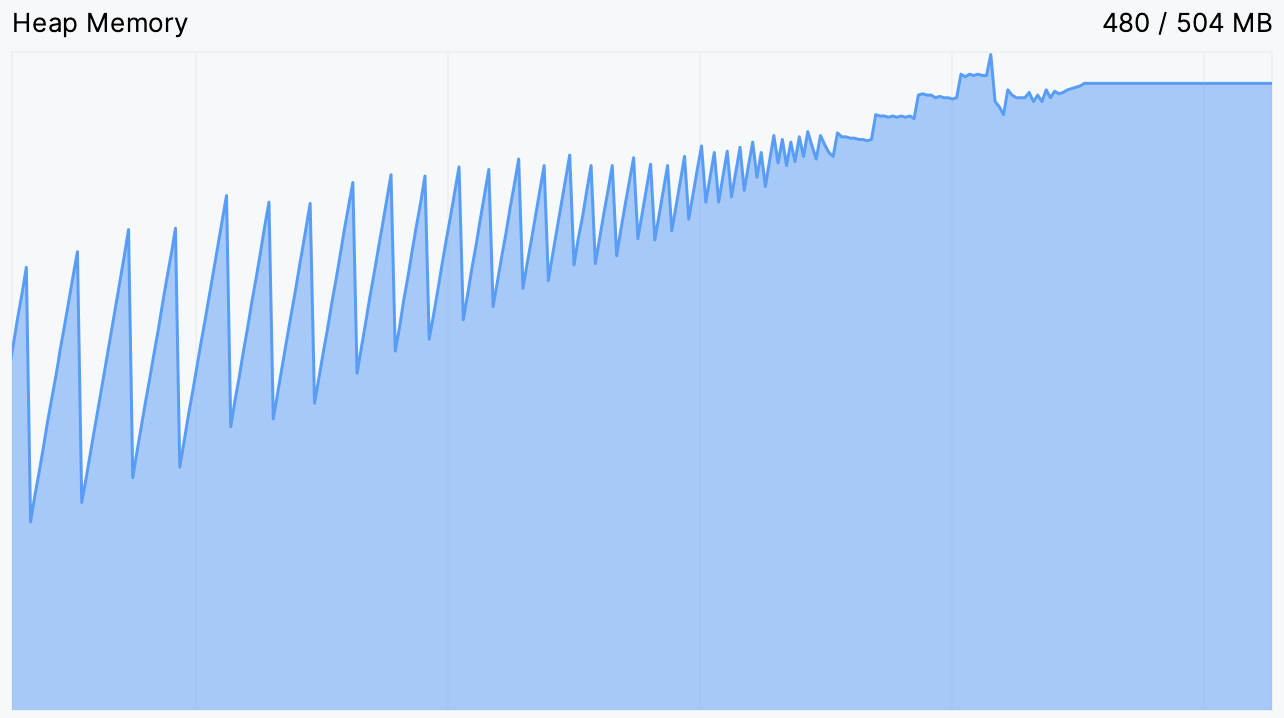
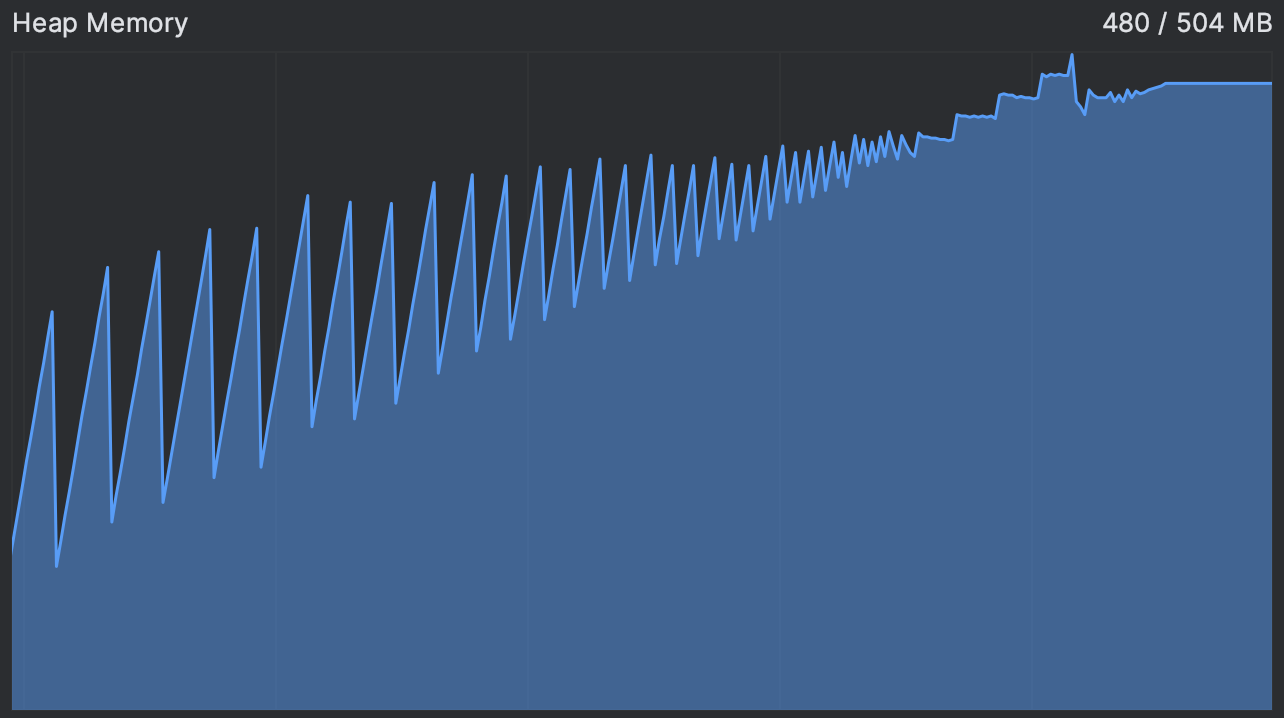
确实,我们看到内存使用量不断上升,直到达到一个平台期。这正是动画挂起的那一刻,之后似乎永远挂起了。
这给了我们一个线索。通常,内存使用曲线呈锯齿状:当新对象被分配时,图表会上升,并且在垃圾回收未使用对象后定期下降。您可以在下图中看到一个正常运行的程序示例:
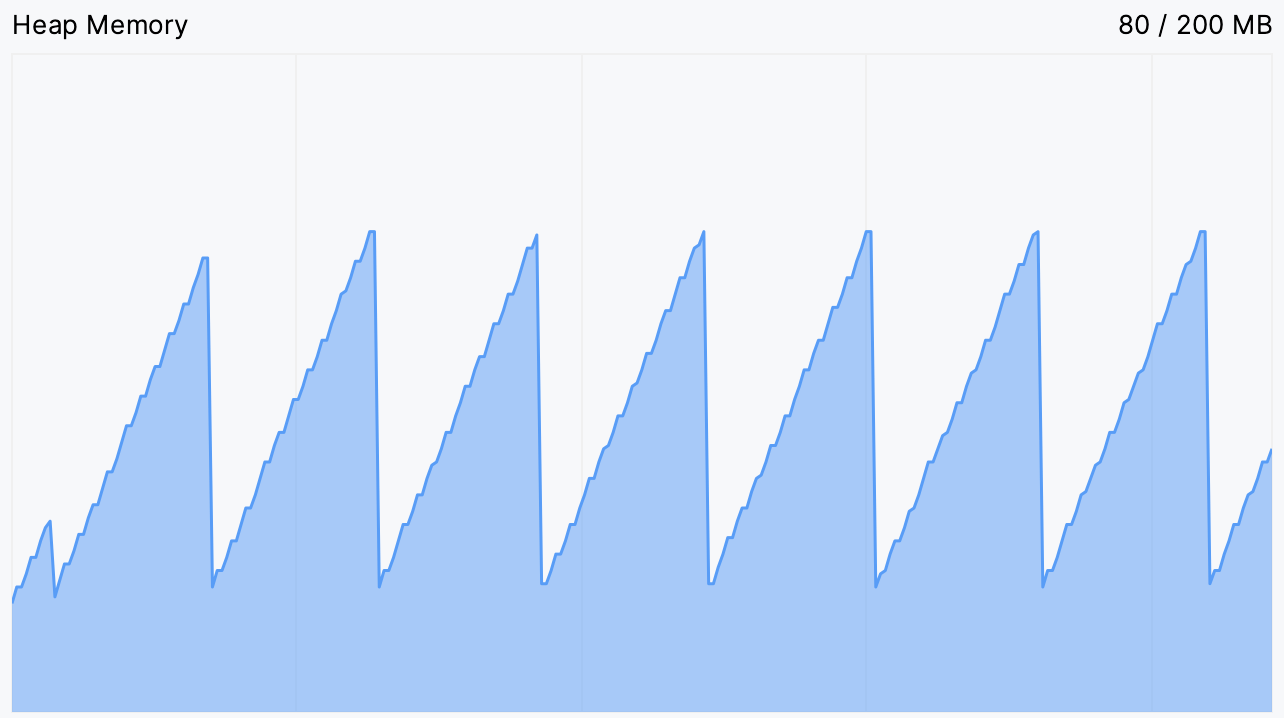
如果锯齿变得太频繁,这意味着垃圾收集器正在努力释放内存。平台意味着它无法释放任何内存。
我们可以测试JVM是否能够执行垃圾回收,通过显式请求一个:
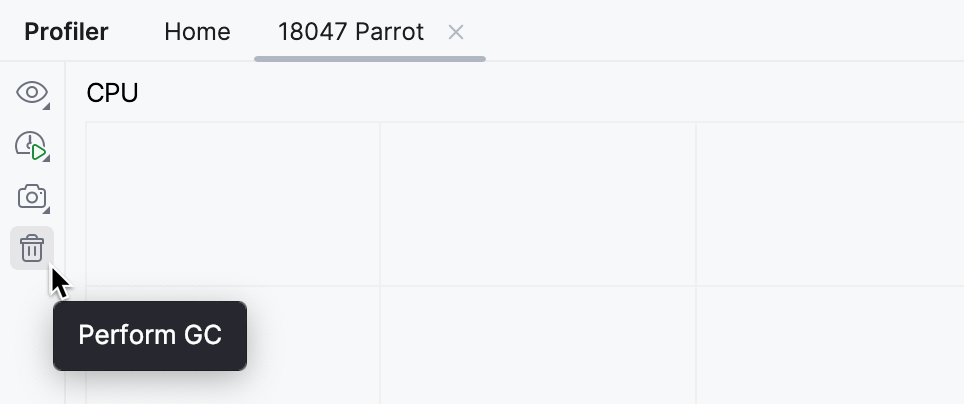
在我们的应用达到平台期后,内存使用量并没有下降,即使我们手动提示它释放一些内存。这支持了我们的假设,即没有对象有资格进行垃圾回收。
一个简单的解决方案是简单地添加更多内存。为此,向运行配置中添加 -Xmx500m VM选项。
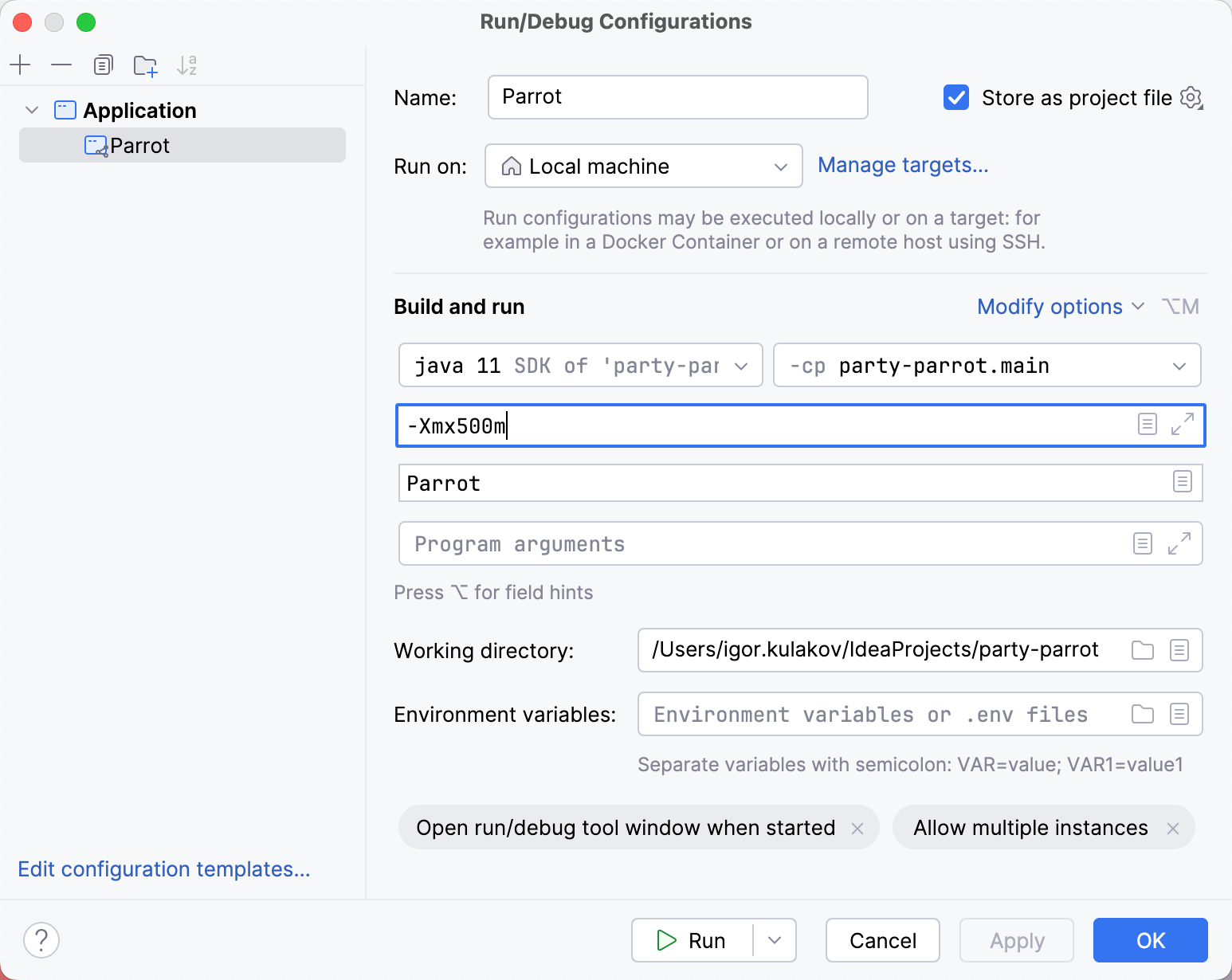

要快速访问当前选定的运行配置设置,请按住’Shift’并点击主工具栏上的运行配置名称。
无论可用内存多少,鹦鹉最终都会耗尽它。再次,我们看到了同样的画面。额外内存的唯一可见效果是我们延迟了”派对”的结束。
分配剖析
既然我们知道我们的应用程序总是得不到足够的内存,因此怀疑存在内存泄漏并分析其内存使用情况是合理的。为此,我们可以使用 -XX:+HeapDumpOnOutOfMemoryError VM选项收集内存转储。这是一种完全可接受的方法来检查堆;然而,它不会指出创建这些对象的代码。
我们可以通过剖析快照获得这些信息:它不仅提供了对象类型的统计信息,而且还揭示了它们被创建时对应的堆栈跟踪。虽然这对于分配剖析来说是一个稍微非传统的用例,但这并不能阻止我们使用它来识别问题。
让我们附带IntelliJ Profiler运行应用程序。运行时,剖析器将定期记录线程的状态并收集内存分配事件的数据。然后,这些数据被聚合成人可读的形式,给我们提供了一个概念,即应用程序在分配这些对象时正在做什么。
在运行剖析器一段时间后,让我们打开报告并选择内存分配 (Memory Allocations):
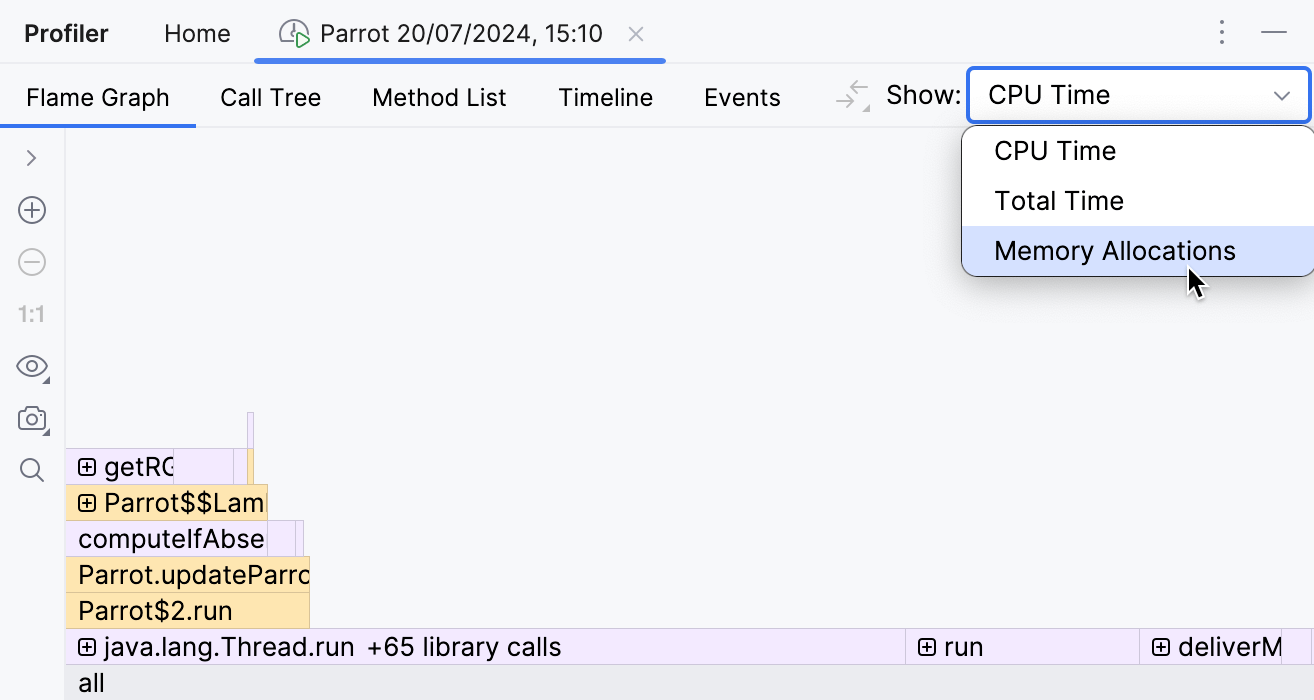
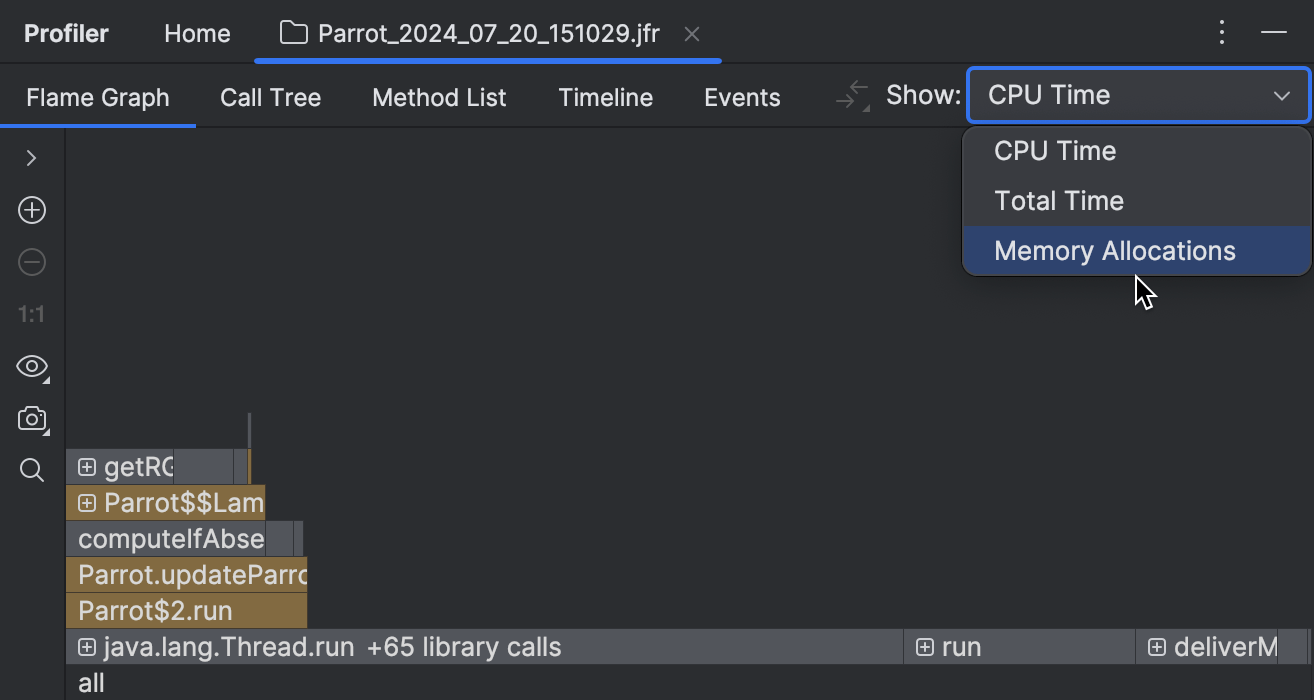
对于收集的数据有几个可用的视图。在本教程中,我们将使用火焰图。它将收集到的堆栈聚合在一个类似堆栈的结构中,根据收集到的样本数量调整元素宽度。最宽的元素代表在剖析期间大规模分配的类型。
需要注意的一点是,大量的分配并不一定表明存在问题。只有当分配的对象没有被垃圾回收时,才会发生内存泄漏。虽然分配剖析没有告诉我们关于垃圾回收的信息,但它仍然可以为我们进一步的调查提供线索。
![分配图中最大的两个帧是int[]和byte[]](/img/profile-memory-allocations/flame-graph-1.png)
![分配图中最大的两个帧是int[]和byte[]](/img/profile-memory-allocations/flame-graph-1-dark.png)
让我们看看两个最大的元素, byte[] 和 int[] ,来自哪里。堆栈的顶部告诉我们,这些数组是在由 java.awt.image 包中的代码处理图像时创建的。堆栈的底部告诉我们,这一切都是在一个由执行器服务管理的单独线程中发生的。我们不是在查找库代码中的错误,所以让我们看看中间的项目代码。
从顶部到底部,我们看到的第一个应用程序方法是 recolor() ,它反过来又被 updateParrot() 调用。从名称判断,这个方法正是让我们的鹦鹉移动的。让我们看看它是如何实现的,以及为什么需要那么多数组。
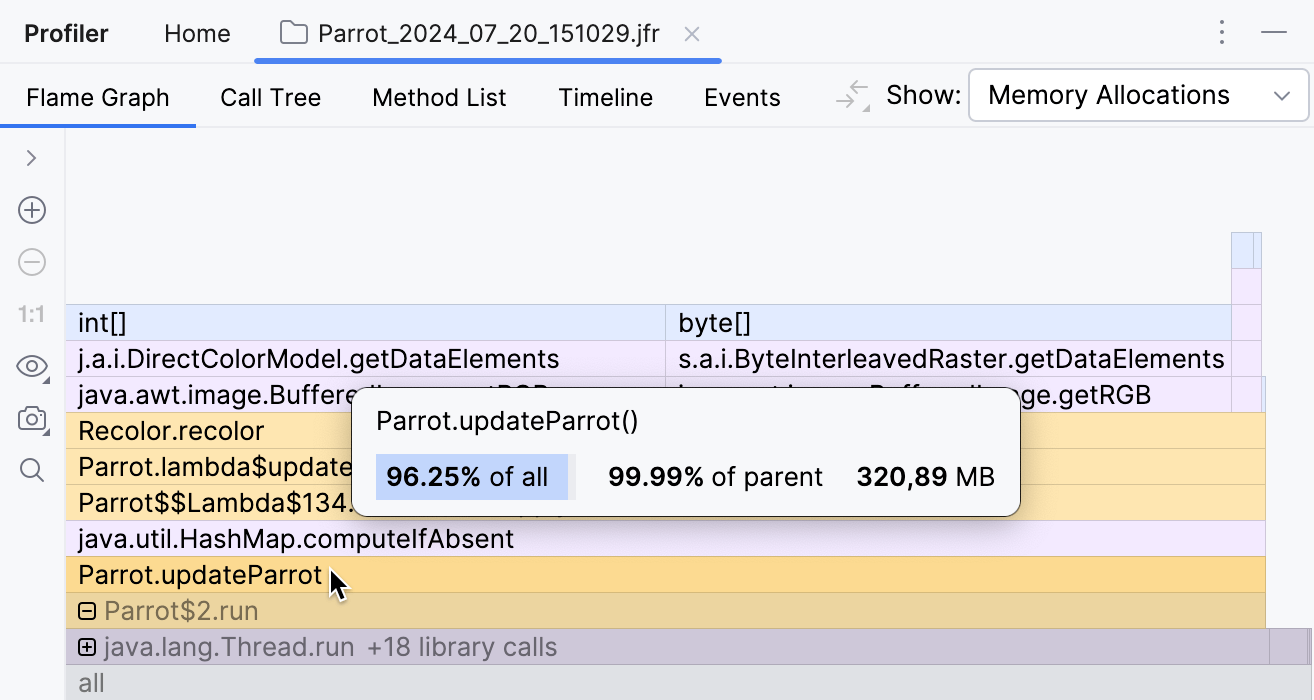
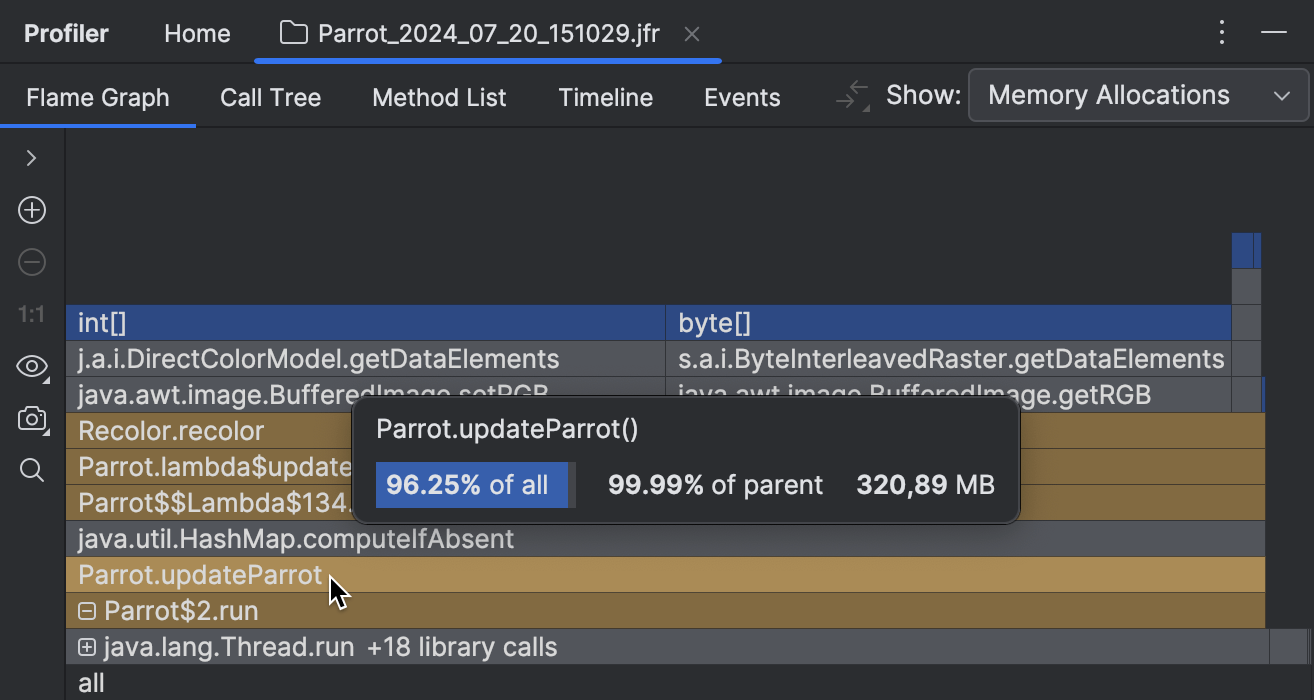
点击框架会带我们到相应方法的源代码:
public void updateParrot() {
currentParrotIndex = (currentParrotIndex + 1) % parrots.size();
BufferedImage baseImage = parrots.get(currentParrotIndex);
State state = new State(baseImage, getHue());
BufferedImage coloredImage = cache.computeIfAbsent(state, (s) -> Recolor.recolor(baseImage, hue));
parrot.setIcon(new ImageIcon(coloredImage));
}看起来 updateParrot() 接受某个基础图像,然后对其进行重新着色。
为了减少额外的工作,实现首先尝试从某个缓存中检索该图像。
检索的键是一个 State 对象,其构造函数
接受一个基础图像和一个色调:
public State(BufferedImage baseImage, int hue) {
this.baseImage = baseImage;
this.hue = hue;
}分析数据流
使用内置的静态分析器,我们可以追踪到
State 构造函数调用的输入值范围。
右键点击 baseImage 构造参数,
然后从菜单中选择 分析 (Analyze) | 流入此处的数据流 (Data Flow to Here)。
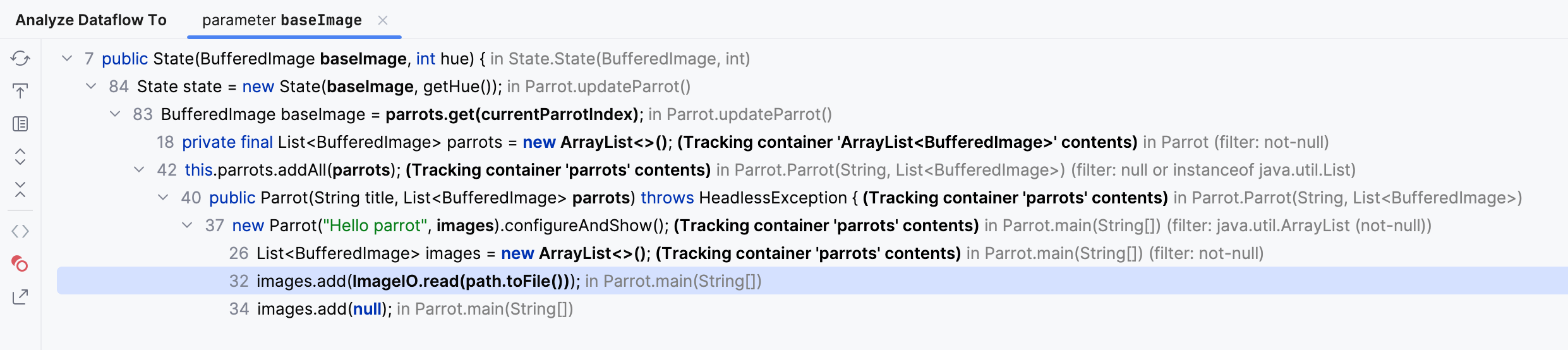
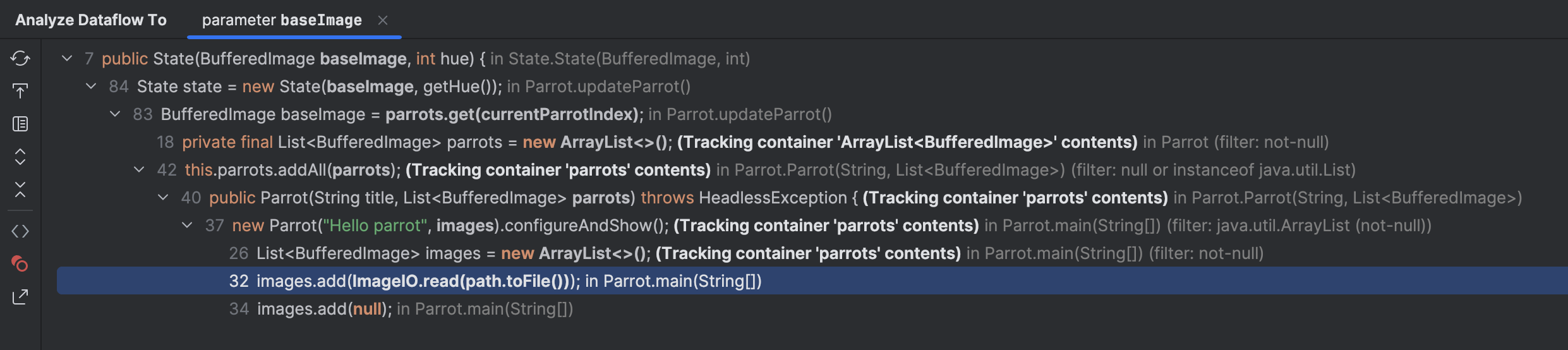
展开节点并注意 ImageIO.read(path.toFile()) 。
这向我们展示了基础图像是从一组文件中来的。
如果我们双击这一行并查看附近的 PARROTS_PATH 常量,
我们就能发现这些文件的位置:
public static final String PARROTS_PATH = "src/main/resources";通过导航到这个目录,我们可以看到以下内容:
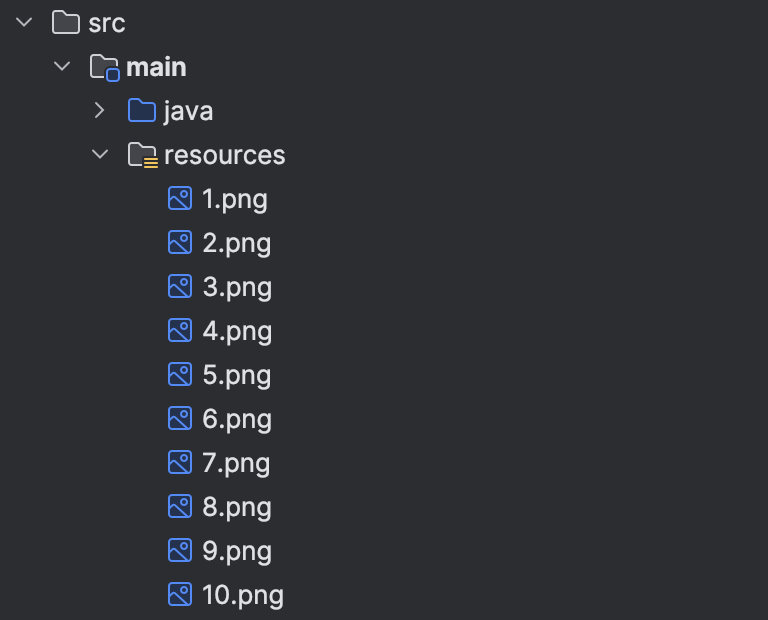
这是对应于鹦鹉可能位置的10个基础图像。
那么,关于 hue 构造参数呢?
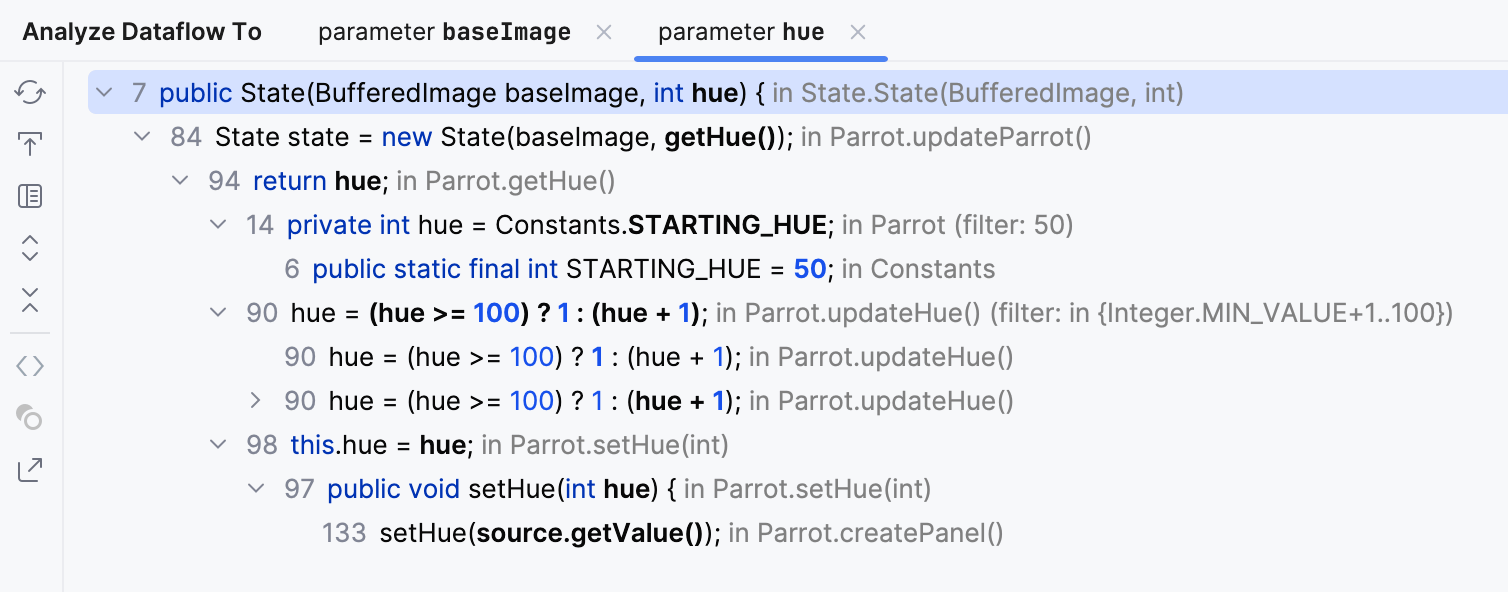
如果我们检查修改 hue 变量的代码,我们会看到它有一个
初始值 50 。
然后它要么被滑块设置,要么由 updateHue() 方法自动更新。
无论哪种方式,它总是在 1 到 100 的范围内。
因此,我们有100种色调变体和10个基础图像, 这应该保证缓存永远不会超过1000个元素。让我们检查一下是否确实如此。
条件断点
现在,这就是调试器可以发挥作用的地方。 我们可以通过条件断点来检查缓存的大小。
在热点代码中设置条件断点 可能会显著减慢 目标应用程序的速度。
让我们在更新动作处设置一个断点,并添加一个条件,以便仅在 缓存大小超过1000个元素时暂停应用程序。
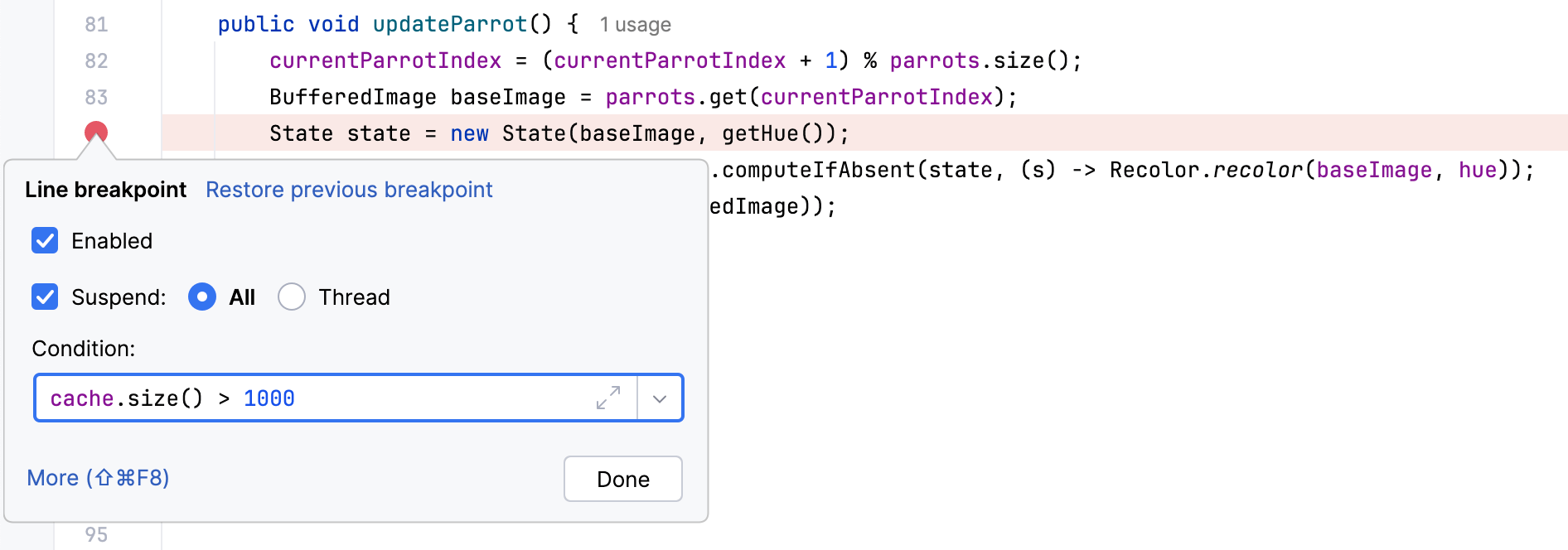
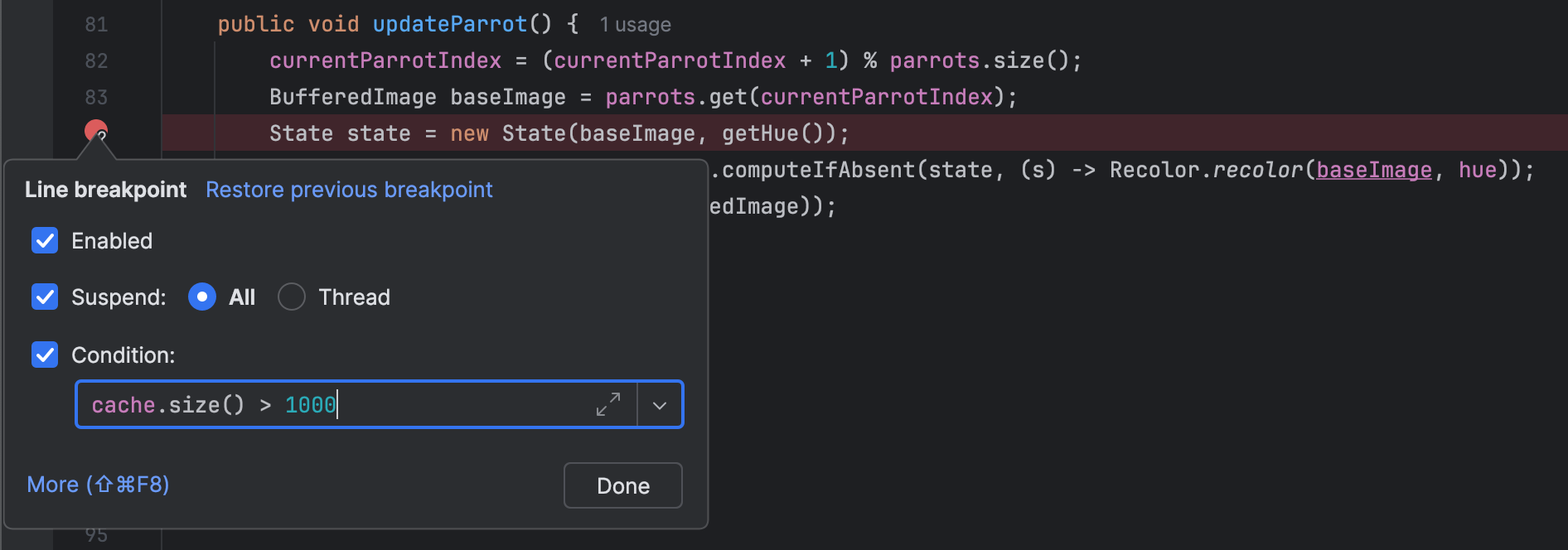
现在以调试模式运行应用程序。


确实,在运行程序一段时间后,我们在这一点上停止了, 这意味着问题确实出在缓存上。
检查代码
转到声明
点击 cache 带我们到它的声明位置:
private static final Map<State, BufferedImage> cache = new HashMap<>();如果我们查阅 HashMap 的文档,
我们会发现它的实现依赖于 equals()
和 hashCode() 方法,
并且用作键的类型必须正确地覆盖它们。
我们来检查一下。转到声明
点击 State 带我们到类定义。
class State {
private final BufferedImage baseImage;
private final int hue;
public State(BufferedImage baseImage, int hue) {
this.baseImage = baseImage;
this.hue = hue;
}
public BufferedImage getBaseImage() { return baseImage; }
public int getHue() { return hue; }
}看起来我们找到了罪魁祸首: equals()
和 hashCode() 的实现不仅不正确,而且完全缺失!
重写方法
为 equals()
和 hashCode() 编写实现是一项乏味的任务。
幸运的是,现代工具可以为我们生成它们。
当在 State 类中时,
按下 Cmd + N
并选择 equals() 和 hashCode() (equals() and hashcode())。
接受建议并点击 下一个 (Next) 直到方法出现在光标处。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
State state = (State) o;
return hue == state.hue && Objects.equals(baseImage, state.baseImage);
}
@Override
public int hashCode() {
return Objects.hash(baseImage, hue);
}检验修复
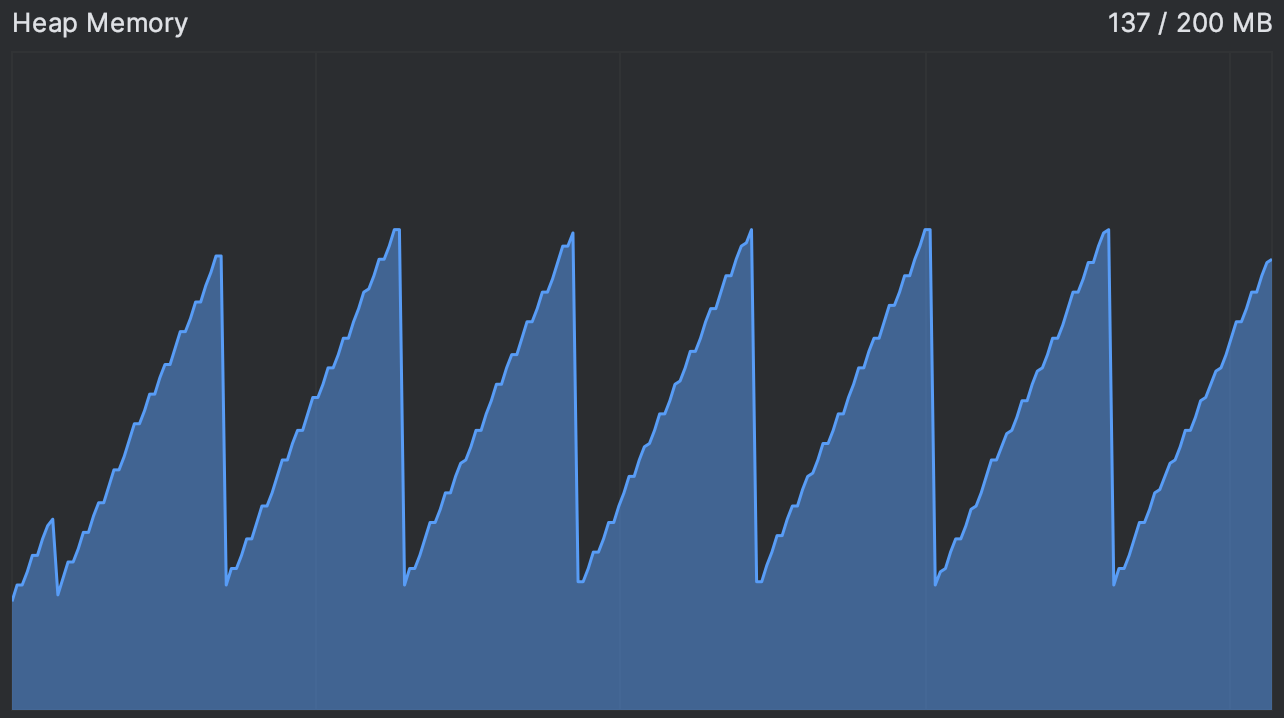
让我们重启应用程序,看看情况是否有所改善。 同样,我们可以使用 CPU 和内存实时图表 来进行:
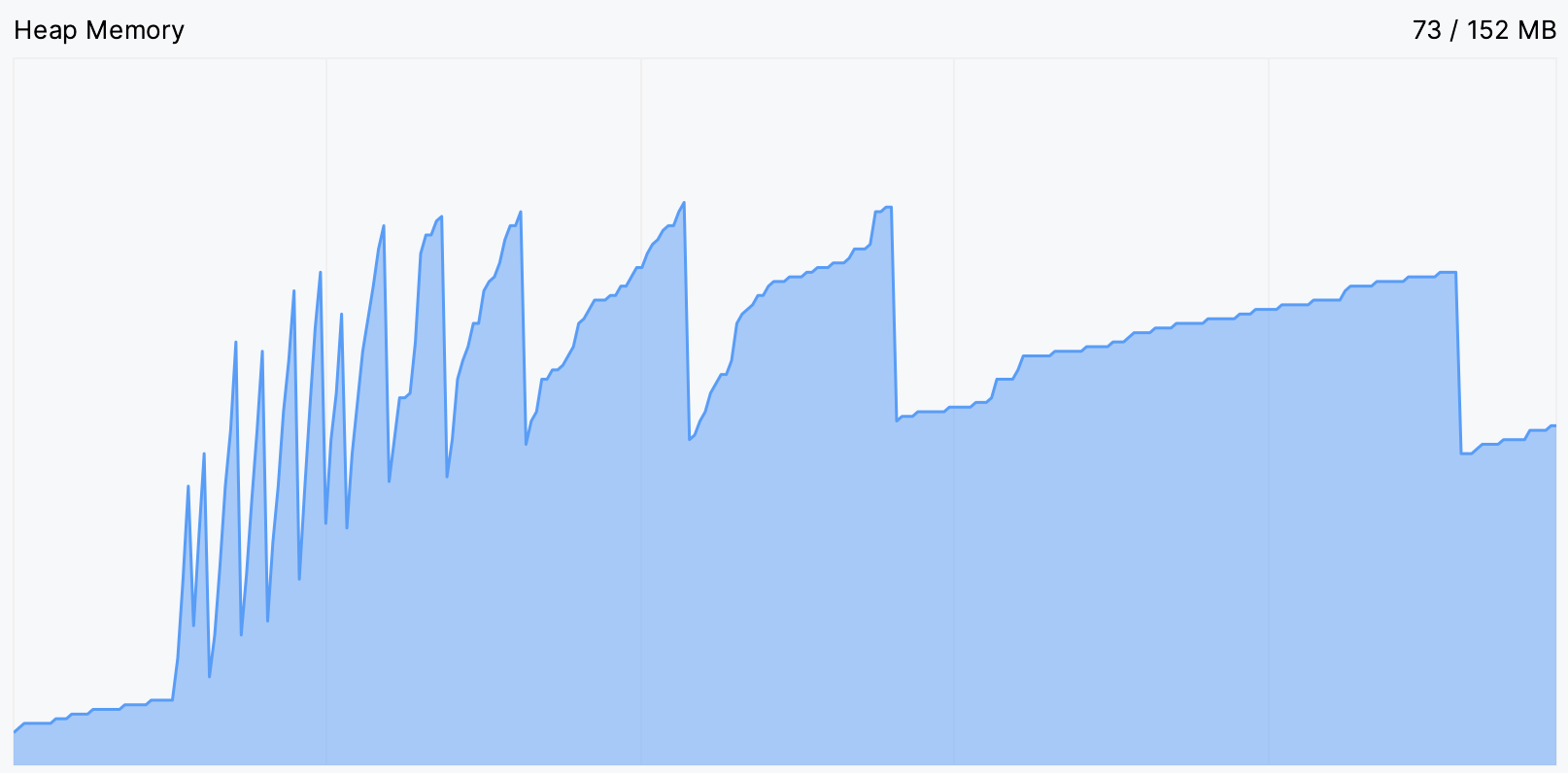
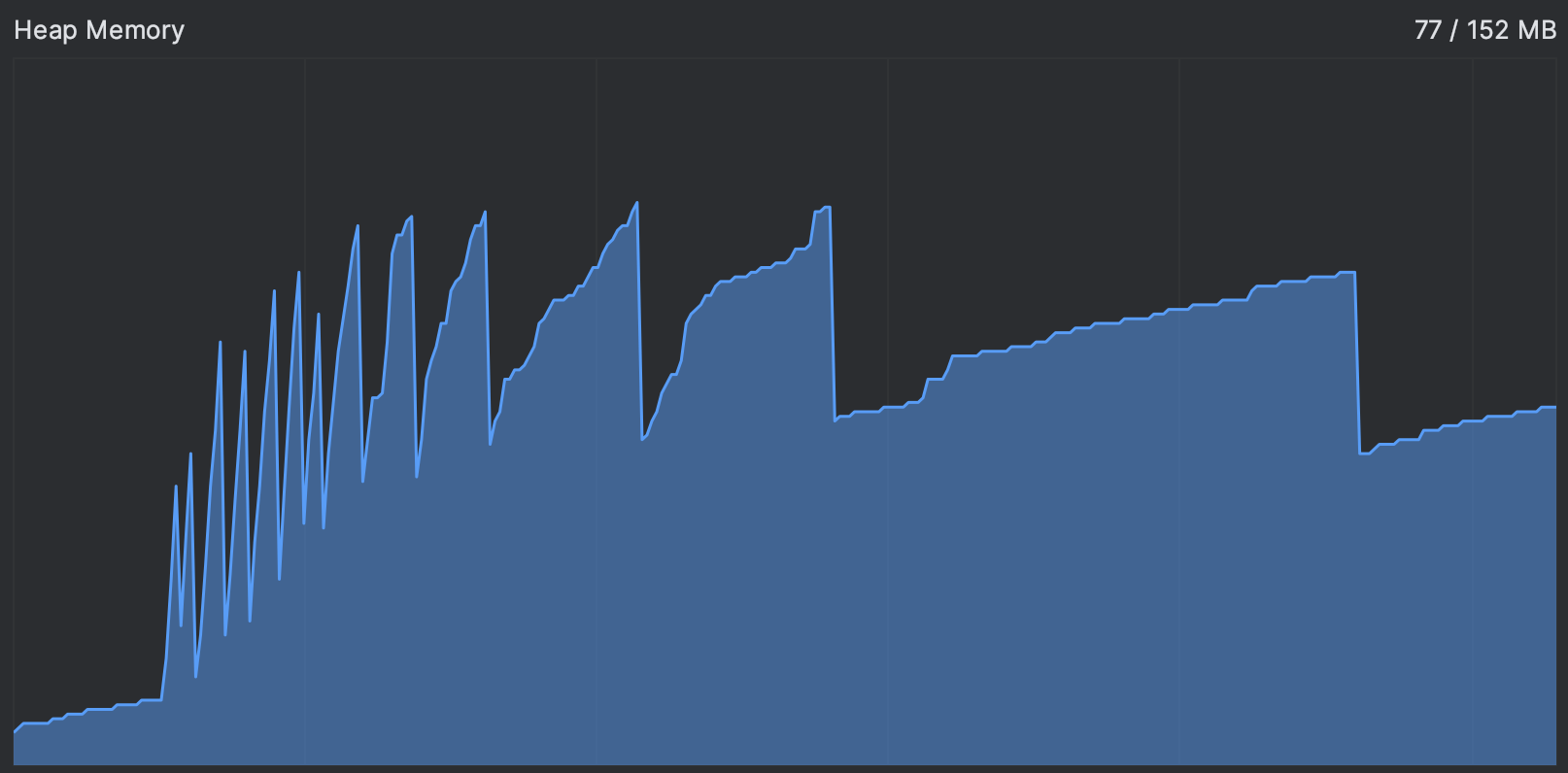
这好多了!
总结
在这篇文章中,我们探讨了如何从问题的一般症状开始,然后, 利用我们的推理和可供我们使用的各种工具, 逐步缩小搜索范围,直到找到导致问题的确切代码行。 更重要的是,我们确保了鹦鹉派对无论如何都会继续进行!
一如既往,我很乐意听到您的反馈!愉快地进行性能分析吧!