文本重复查找器:需求
阅读其他语言: English Español Français Deutsch 日本語 한국어 Português

自我发布了重复查找器项目的介绍 已经过了一段时间, 所以现在是个分享一下项目进展的好时机。 在开始编写程序代码之前,首先获取详细的要求是非常有必要的。一种很好的方法就是编写测试。测试不仅能帮助我们更快地进行开发, 而且还能确保代码符合规格要求。

需求
在这个部分,我已经对查找重复项的核心功能提出了我的想法。 这些对我来说很有用。 然而,由于每个项目可能有不同的需求, 我会很高兴听到并实施你的想法。
能够检测精确匹配和模糊匹配
重复检测工具应能够找到精确匹配和模糊匹配, 精度可以细化到单个符号。 例如,它应将以下文本识别为相似:
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.而且,对于模糊重复,应能测量其相似度的程度。 这样我们就可以快速评估重复对,并将其根据文本片段之间的相似度进行排序。
与语言无关
考虑到可能的目标语言的多样性, 支持尽可能多的语言会很好。 有些做法可能需要为每种新添加的语言单独进行维护, 这完全无法扩展,且需要大量资源。 理想情况下,该工具应使用一些启发式或语言无关的算法, 以便与任何常见语言兼容。
可配置
识别重复项的标准应该可以调整,设置参数如下:
- 分析的文本片段长度
- 重复次数
- 相似度
通常,一个部分越长,重复的次数越多,去重复化的好处就越大。 然而,这最终还是取决于具体的应用,因此如果能对这些阈值进行控制会很好。
定义
在基本需求确定后,接下来要设置代码中的定义。 在这个阶段,我们需要:
此章节的代码不需要详尽无遗地为每个未来的使用场景提供, 我们可以随时回来进行调整。
Chunk
当说到文本的单位时,哪些详情对我们来说是重要的? 对于我们的目的,我将选择一个片段包含的文本,指向其包含文件的路径, 行号,以及如果源不只是纯文本时的元素类型:
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)这个定义没有考虑到一些细节。例如,我们可能会剔除 content 字段。
这将为我们节省一些内存,但牺牲的是元素内容的访问速度的速度,
因为程序每次都必须从磁盘读取内容,而非只需读取一次。
现在我们并不需要拼命优化性能,所以一个可能被看作次优的选择尚属可行。
接口
我们还没有实现,所以我们将针对一个接口进行编程。 接口定义了我们的函数应该接受什么样的输入,以及应该返回什么样的输出, 抽象出我们对函数内部的理解。 这实际上创建了一个契约,允许我们在不对实际算法进行编码的情况下立即写入测试。 在未来,这也将使得替代实现与现有的测试和客户端代码兼容。
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}以下是接口接受的参数的含义:
-
root– 包含要分析内容的文件夹 -
minSimilarity– 两个Chunk对象被认为是重复项的最低相似度百分比 -
minLength– 一个Chunk被分析的最小content长度 -
minDuplicates– 一个重复集群被报告的最小重复数 -
fileExtensions– 用于过滤掉无关文件的文件扩展名模式
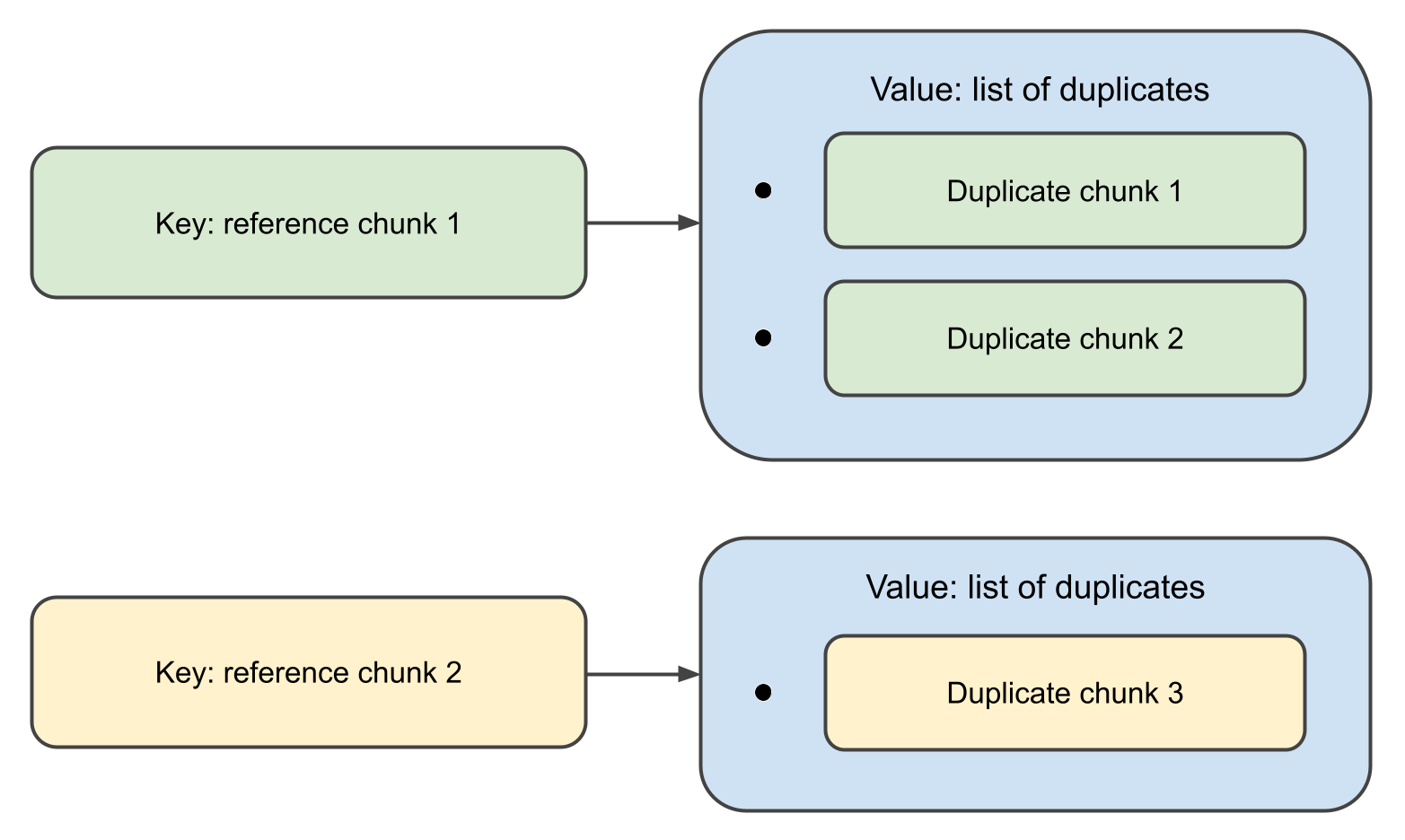
当函数完成时,它将返回一个map,
其中键是 Chunk 对象,关联值是它们的重复项列表。
事实上,上述定义过于冗长。 仅为单个函数和几个调用者引入接口过于繁琐。 Kotlin提供了一种通过一级函数处理此问题的优雅方式:
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()此声明意味着重复查找器接受的是一个函数,
该函数接收 Path, DuplicateFinderOptions ,并输出 Map<Chunk, List<Chunk>> ,
而函数本身尚未实现。
这也许并不是大型项目的最佳风格,但对于像我们这样的小型项目,效果很好。
测试数据
由于查找重复项要处理的是文本数据,因此测验也需要一些用于分析的文本。 这意味着我们需要准备一些包含模糊重复项的例子。我们先从重复项开始:
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes." FUZZY_MATCH_TEMPLATE 背后的想法是,
我们将使用它来编程产生实际的模糊匹配:
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)接下来,我们将生成由随机英文单词组成的文本:
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}最后,我们将随机地将 EXACT_MATCH
和 fuzzyMatches 注入到生成的文本中:
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}测试
如已经提及,此阶段的测试的主要目标是定义规格, 所以我们不要在完善测试套件上浪费太多时间。 相反,我们仅编写足够的测试以确保未来的代码符合需求。
这是测试类的代码:
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }下一步
我们已经通过定义接口和编写测试来建立了需求。 在系列的下一篇文章中,我们将实现实际的算法,看看其性能如何。 再见!