LLMs + Strukturierte Ausgabe als Übersetzungsdienst
Andere Sprachen: English Español Français 日本語 한국어 Português 中文
In einem früheren Beitrag zur Lokalisierung einer App mit KI haben wir die Automatisierung der Übersetzung von UI-Texten besprochen. Für diese Aufgabe habe ich ein Übersetzungstool einem LLM vorgezogen, basierend auf folgender Überlegung:
…Ich hatte geplant, OpenAIs GPT3.5 Turbo zu verwenden, aber da es nicht streng genommen ein Übersetzungsmodell ist, erfordert es zusätzlichen Aufwand, den Prompt zu konfigurieren. Außerdem sind die Ergebnisse tendenziell weniger stabil, daher habe ich einen dedizierten Übersetzungsdienst gewählt, der mir als erstes in den Sinn kam…
Später in diesem Jahr haben mehrere LLM-Anbieter die Funktion für strukturierte Ausgabe eingeführt, wodurch LLMs deutlich besser für den besprochenen Anwendungsfall geeignet sind. Heute werden wir uns das Problem und wie diese Funktion es loest genauer ansehen.

Das Problem
LLMs sind von Natur aus nicht-deterministisch, was bedeutet, dass sie für dieselbe Eingabe unterschiedliche Ausgaben erzeugen können. Diese Zufälligkeit macht LLMs “kreativ”, aber sie reduziert auch ihre Zuverlässigkeit, wenn ein bestimmtes Ausgabeformat erforderlich ist.
Betrachte den Übersetzungsanwendungsfall als Beispiel. Eine naive Lösung wäre, das erforderliche Format im Prompt zu beschreiben:
> Translate 'cat' to Dutch. ONLY GIVE A TRANSLATION AND NOTHING ELSE.Das funktioniert, obwohl ein LLM gelegentlich die Anweisungen falsch verstehen wird:
> Certainly, allow me to provide the translation for you.
The word 'cat' is translated as 'kat' in Dutch. Sometimes, female cats may also be referred to as 'poes'.Da die Anwendung ein einzelnes Wort als Antwort erwartet, kann alles andere als ein einzelnes Wort zu Fehlern oder beschädigten Daten führen. Selbst mit zusätzlichen Prüfungen und Wiederholungen beeinträchtigen solche Inkonsistenzen die Zuverlässigkeit des Workflows.
Was ist strukturierte Ausgabe
Strukturierte Ausgabe behebt die Probleme mit inkonsistenter Formatierung, indem du ein Schema für die Antwort definieren kannst. Du kannst zum Beispiel eine Struktur wie diese anfordern:
{
"word": "cat",
"target_locale": "nl",
"translation_1": "kat",
"translation_2": "poes"
}Hinter den Kulissen kann die Implementierung strukturierter Ausgabe zwischen verschiedenen Modellen variieren. Gängige Ansätze umfassen:
- die Verwendung eines endlichen Automaten, um die Übergänge zwischen Token zu verfolgen und Generierungspfade zu beschneiden, die das bereitgestellte Schema verletzen
- Modifizierung der Wahrscheinlichkeiten der Kandidaten-Token, um die Wahrscheinlichkeit der Auswahl nicht-konformer Optionen zu verringern
- Feinabstimmung des Modells mit einem Datensatz, der auf das Erkennen von JSON-Schemas und anderen strukturierten Datenformaten ausgerichtet ist
Diese zusätzlichen Mechanismen helfen dabei, eine höhere Zuverlässigkeit zu erreichen, verglichen damit, einfach Formatanweisungen zum Prompt hinzuzufügen.
Code
Aktualisieren wir das Übersetzungsskript. Zu Beginn definieren wir das Objekt, das das Schema repräsentiert:
response_format={
"type": "json_schema",
"json_schema": {
"name": "translation_service",
"schema": {
"type": "object",
"required": [
"word",
"translation"
],
"properties": {
"word": {
"type": "string",
"description": "The word that needs to be translated."
},
"translation": {
"type": "string",
"description": "The translation of the word in the target language."
}
},
"additionalProperties": False
},
"strict": True
}
}Als Nächstes können wir das Schema-Objekt in der Funktion verwenden, die die Anfrage durchführt:
def translate_property_llm(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {openai_key}',
}
url = 'https://api.openai.com/v1/chat/completions'
data = {
'model': 'gpt-4o-mini',
'response_format': response_format,
'messages': [
{'role': 'system',
'content': f'Translate "{value}" to {target_lang}. '
f'Only provide the translation without any additional text or explanation.'},
{'role': 'user', 'content': value}
],
}
response = requests.post(url, headers=headers, data=json.dumps(data))
try:
content_json = json.loads(response.json()["choices"][0]["message"]["content"])
return content_json["translation"]
except (json.JSONDecodeError, KeyError) as e:
raise ValueError(f"Failed to parse translation response: {str(e)}")Das war’s für das Programmieren! Für mehr Kontext kannst du das Projekt gerne im GitHub-Repository erkunden und damit experimentieren.
Vergleich mit dem vorherigen Ansatz
Der Übersetzungsprozess dauerte für die aktualisierte Version etwas länger im Vergleich zur Übersetzungsdienst-basierten Version. Allerdings ist der bereitgestellte Code das einfachste funktionierende Beispiel, und wir könnten es durch asynchrones Senden der Anfragen viel schneller machen.
Was die Kosten betrifft, hat mich die Übersetzung in 5 Sprachen weniger als 0,01$ gekostet, was mehr als 10-mal günstiger ist als die vorherige Version:
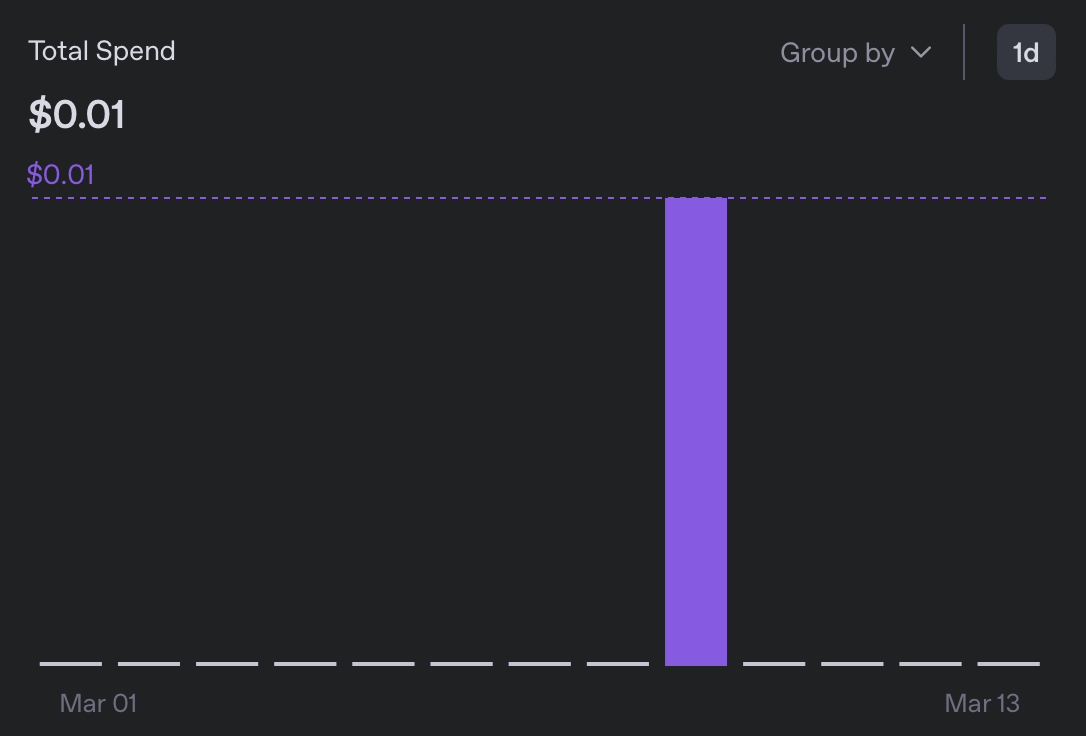
Beim Überfliegen der resultierenden Message Bundles ist mir nichts Verdächtiges aufgefallen. Obwohl ich keine der neu hinzugefügten Sprachen lesen kann, sieht die Formatierung gut aus, und ich bin auf keine Vorkommnisse von ‘Sure, I’ll translate that for you’ gestoßen.
Warum ist das wichtig
Obwohl das beschriebene Experiment ein Nischenproblem adressiert, hebt es einen breiteren und bedeutenderen Aspekt von grossen Sprachmodellen hervor. Während sie spezialisierte Dienste bei der Lösung einer bestimmten Aufgabe übertreffen können oder auch nicht, ist das wirklich Bemerkenswerte an LLMs ihre Fähigkeit, als schnelle und praktische Lösung und als Allzweck-Alternative zu spezialisierteren Werkzeugen zu dienen.
Als jemand mit nur grundlegenden Kenntnissen im maschinellen Lernen habe ich früher ganze Klassen von Aufgaben gemieden, weil selbst eine mittelmäßige Lösung Expertise erforderte, die ich nicht hatte. Jetzt ist es jedoch unglaublich einfach geworden, Klassifikatoren, Übersetzungsdienste, LLMs-als-Richter und unzählige andere Anwendungen zusammenzubasteln.
Natürlich ist Qualität immer noch eine Überlegung, aber realistisch betrachtet brauchen wir für viele Probleme sowieso keine 100%ige Perfektion. Ein Grund weniger, nicht zu hacken!
Fazit
Mir fiel keine sinnvolle Art ein, diesen Artikel abzuschließen, also hier ein Foto der Katze, die ich heute getroffen habe (nicht KI-generiert!):
