LLMs + Saída Estruturada como um Serviço de Tradução
Outras línguas: EnglishEspañolFrançaisDeutsch日本語한국어中文
Em um post anterior dedicado à localização de um app com AI, discutimos sobre automatizar a tradução de strings da interface do usuário. Para essa tarefa, optei por uma ferramenta de tradução ao invés de uma LLM, baseado na seguinte justificativa:
…Eu estava planejando usar o GPT3.5 Turbo da OpenAI, mas como ele não é estritamente um modelo de tradução, ele requer esforço extra para configurar o prompt. Além disso, seus resultados tendem a ser menos estáveis, então escolhi um serviço de tradução dedicado que primeiro veio à mente…
Posteriormente naquele ano, vários provedores de LLM introduziram o recurso de saída estruturada, tornando as LLMs significativamente mais adequadas para o caso de uso discutido. Hoje, vamos dar uma olhada mais detalhada no problema e como este recurso resolve.
O problema
As LLMs são inerentemente não determinísticas, o que significa que podem produzir diferentes saídas para a mesma entrada. Esta aleatoriedade torna as LLMs “criativas”, mas também reduz a confiabilidade delas quando é necessário seguir um formato de saída específico.
Considere o caso de uso de tradução como exemplo. Uma solução ingênua seria descrever o formato requerido no prompt:
> Translate 'cat' to Dutch. ONLY GIVE A TRANSLATION AND NOTHING ELSE.Isso funciona, embora ocasionalmente, uma LLM possa interpretar errado as instruções:
> Certainly, allow me to provide the translation for you.
The word 'cat' is translated as 'kat' in Dutch. Sometimes, female cats may also be referred to as 'poes'.Como o aplicativo espera uma única palavra como resposta, qualquer coisa diferente de uma única palavra pode levar a erros ou dados corrompidos. Mesmo com verificações adicionais e tentativas de nova execução, tais inconsistências comprometem a confiabilidade do fluxo de trabalho.
O que é saída estruturada
A saída estruturada aborda os problemas com formatação inconsistente, permitindo que você defina um esquema para a resposta. Por exemplo, você pode solicitar uma estrutura assim:
{
"word": "cat",
"target_locale": "nl",
"translation_1": "kat",
"translation_2": "poes"
}Por trás das cortinas, a implementação de saída estruturada pode variar entre modelos. Algumas abordagens comuns incluem:
- usando uma máquina de estado finito para rastrear as transições entre tokens e podar caminhos de geração que violam o esquema fornecido
- modificando as probabilidades dos tokens candidatos para diminuir a probabilidade de selecionar opções não conformes
- aprimorando o modelo com um conjunto de dados focado em reconhecer esquemas JSON e outros formatos de dados estruturados
Estes mecanismos adicionais ajudam a alcançar uma maior confiabilidade em comparação com simplesmente adicionar instruções de formato ao prompt.
Código
Vamos atualizar o script de tradução. Para começar, vamos definir o objeto que representa o esquema:
response_format={
"type": "json_schema",
"json_schema": {
"name": "translation_service",
"schema": {
"type": "object",
"required": [
"word",
"translation"
],
"properties": {
"word": {
"type": "string",
"description": "The word that needs to be translated."
},
"translation": {
"type": "string",
"description": "The translation of the word in the target language."
}
},
"additionalProperties": False
},
"strict": True
}
}Em seguida, podemos usar o objeto do esquema na função que executa a requisição:
def translate_property_llm(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {openai_key}',
}
url = 'https://api.openai.com/v1/chat/completions'
data = {
'model': 'gpt-4o-mini',
'response_format': response_format,
'messages': [
{'role': 'system',
'content': f'Translate "{value}" to {target_lang}. '
f'Only provide the translation without any additional text or explanation.'},
{'role': 'user', 'content': value}
],
}
response = requests.post(url, headers=headers, data=json.dumps(data))
try:
content_json = json.loads(response.json()["choices"][0]["message"]["content"])
return content_json["translation"]
except (json.JSONDecodeError, KeyError) as e:
raise ValueError(f"Failed to parse translation response: {str(e)}")Isso é tudo para a codificação! Para mais contexto, você é bem-vindo para explorar e experimentar o projeto no repositório do GitHub.
Comparação com a abordagem anterior
O processo de tradução demorou um pouco mais para a versão atualizada em comparação com o baseado em serviço de tradução. Dito isto, o código fornecido é o exemplo de trabalho mais simples, e poderíamos torná-lo muito mais rápido fazendo as solicitações de forma assíncrona.
Em termos de despesas, a tradução para 5 locais me custou menos de 0,01$, o que é mais de 10 vezes mais barato que a versão anterior:
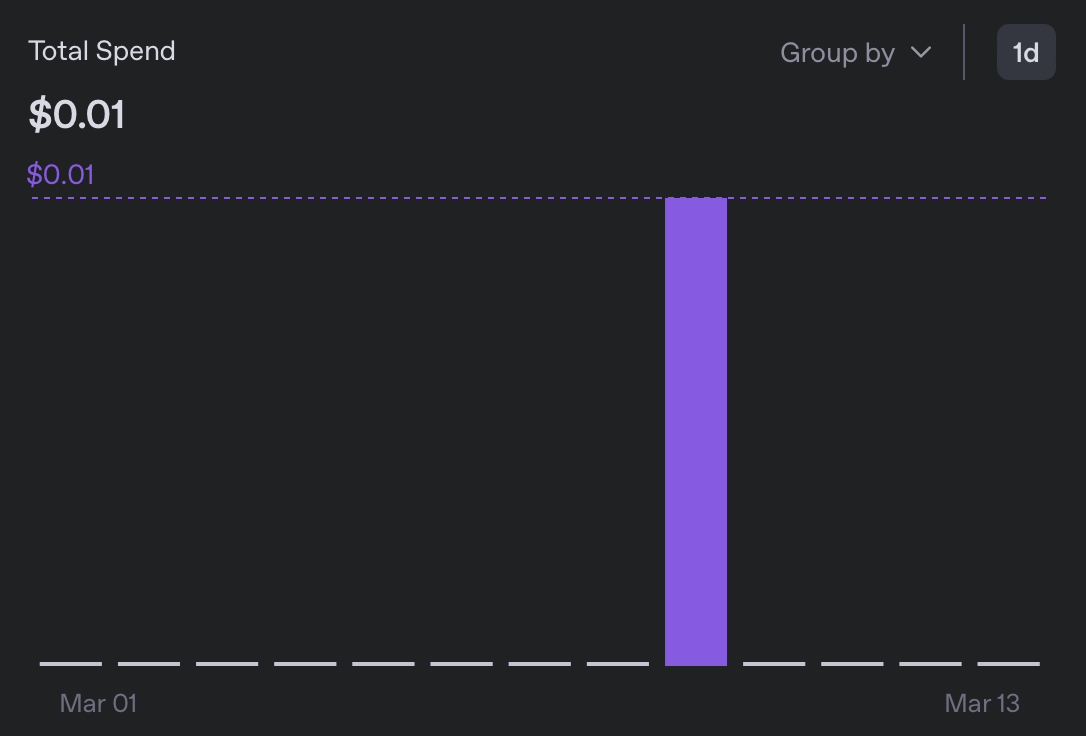
Percorrendo os pacotes de mensagens resultantes, não notei nada suspeito. Enquanto eu não posso ler nenhum dos novos idiomas adicionados, a formatação parece boa, e eu não encontrei ocorrências de ‘Claro, vou traduzir isso para você’🙂
Por que é importante
Embora o experimento descrito aborde um problema de nicho, ele destaca um aspecto mais amplo e significativo dos grandes modelos de linguagem. Embora eles possam ou não superar serviços especializados na resolução de uma tarefa específica, o que é realmente notável sobre LLMs é a capacidade delas de servir como uma solução rápida e prática e uma alternativa de propósito geral a ferramentas mais especializadas.
Como alguém com apenas um conhecimento básico de aprendizagem de máquina, eu costumava evitar classes inteiras de tarefas, porque mesmo uma solução medíocre exigia conhecimentos que eu não tinha. Agora, no entanto, tornou-se incrivelmente fácil juntar classificadores, serviços de tradução, LLMs como juiz, e inúmeras outras aplicações.
Claro, a qualidade ainda é uma consideração, mas realisticamente, não precisamos de 100% de perfeição para muitos problemas de qualquer maneira. Uma razão a menos para não hackear!
Conclusão
Eu não consegui pensar em uma maneira significativa de encerrar este artigo, então aqui está uma foto do gato que encontrei hoje (não gerado por IA!):
