LLMs + 번역 서비스로서의 구조적 출력
다른 언어: EnglishEspañolFrançaisDeutsch日本語Português中文
앞선 글에서는 인공지능으로 앱을 지역화하는 과정에서 UI 문자열을 번역하는 것을 자동화하는 방법을 논의했습니다. 그 작업을 위해 저는 다음과 같은 이유로 LLM보다 번역 도구를 선택했습니다:
…제가 OpenAI의 GPT3.5 Turbo를 사용하려고 계획했지만 이는 엄밀히 말해서 번역 모델이 아니므로 프롬프트를 구성하는 데 추가적인 노력이 필요합니다. 또한, 그 결과가 비교적 불안정하므로 저는 먼저 떠오르는 전용 번역 서비스를 선택했습니다…
그해 나중에 몇몇 LLM 공급자들은 구조적 출력 기능을 소개하여 LLM을 논의된 사용 사례에 더욱 적합하게 만들었습니다. 오늘은 문제와 이 기능이 그것을 어떻게 해결하는지에 대해 좀 더 자세히 알아보겠습니다.
문제점
LLM은 본질적으로 비결정론적이므로 동일한 입력에 대해 다른 출력을 생성할 수 있습니다. 이 무작위성은 LLM이 “창의적”이게 만들지만, 특정 출력 형식을 따라야 할 때에는 그 신뢰성을 저하시킵니다.
번역 사용 사례를 예로 들어보겠습니다. 순진한 해결책은 프롬프트에서 필요한 형식을 설명하는 것일 수 있습니다:
> Translate 'cat' to Dutch. ONLY GIVE A TRANSLATION AND NOTHING ELSE.이는 작동하지만 가끔 LLM이 지시사항을 잘못 이해할 수 있습니다:
> Certainly, allow me to provide the translation for you.
The word 'cat' is translated as 'kat' in Dutch. Sometimes, female cats may also be referred to as 'poes'.어플리케이션은 하나의 단어만을 응답으로 기대하기 때문에, 단일 단어 이외의 것은 오류를 일으키거나 데이터를 손상시킬 수 있습니다. 추가적인 확인 및 재시도와 함께라도 이러한 불일치는 워크플로우의 신뢰성을 저하시킵니다.
구조적 출력이란 무엇인가
구조적 출력은 응답에 대한 스키마를 정의하는 것으로, 일관성 없는 서식을 해결합니다. 예를 들어, 다음과 같은 구조를 요청할 수 있습니다:
{
"word": "cat",
"target_locale": "nl",
"translation_1": "kat",
"translation_2": "poes"
}배경에는 구조적 출력의 구현이 모델마다 다를 수 있습니다. 일반적인 접근 방식은 다음과 같습니다:
- 토큰 간 전환을 추적하고 제공된 스키마를 위반하는 생성 경로를 삭제하는 유한 상태 머신을 사용
- 후보 토큰의 확률을 수정하여 비합리적인 옵션을 선택할 가능성을 감소
- JSON 스키마와 다른 구조화된 데이터 형식을 인식하는 데 초점을 맞춘 데이터셋으로 모델을 세부 조정
이러한 추가 메커니즘은 형식 지시 사항만 프롬프트에 추가하는 것보다 더 높은 신뢰성을 도달하는 데 도움이 됩니다.
코드
번역 스크립트를 업데이트합시다. 먼저, 스키마를 나타내는 객체를 정의하겠습니다:
response_format={
"type": "json_schema",
"json_schema": {
"name": "translation_service",
"schema": {
"type": "object",
"required": [
"word",
"translation"
],
"properties": {
"word": {
"type": "string",
"description": "The word that needs to be translated."
},
"translation": {
"type": "string",
"description": "The translation of the word in the target language."
}
},
"additionalProperties": False
},
"strict": True
}
}다음으로, 스키마 객체를 요청을 수행하는 함수에서 사용할 수 있습니다:
def translate_property_llm(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {openai_key}',
}
url = 'https://api.openai.com/v1/chat/completions'
data = {
'model': 'gpt-4o-mini',
'response_format': response_format,
'messages': [
{'role': 'system',
'content': f'Translate "{value}" to {target_lang}. '
f'Only provide the translation without any additional text or explanation.'},
{'role': 'user', 'content': value}
],
}
response = requests.post(url, headers=headers, data=json.dumps(data))
try:
content_json = json.loads(response.json()["choices"][0]["message"]["content"])
return content_json["translation"]
except (json.JSONDecodeError, KeyError) as e:
raise ValueError(f"Failed to parse translation response: {str(e)}")코딩은 여기까지입니다! 더 많은 맥락을 위해 GitHub 저장소에서 프로젝트를 탐색하고 실험하는 것을 환영합니다.
이전 접근법과의 비교
번역 과정은 번역 서비스 기반 버전에 비해 업데이트된 버전에서 좀 더 오래 걸렸습니다. 하지만, 제공된 코드는 가장 간단한 작동 예시이며, 요청을 비동기적으로 보내는 것으로 이를 훨씬 빠르게 만들 수 있을 것입니다.
비용의 경우, 5개의 로케일로 번역하는 데는 0.01$ 미만의 비용이 들었는데, 이는 이전 버전보다 10배 이상 저렴하다:
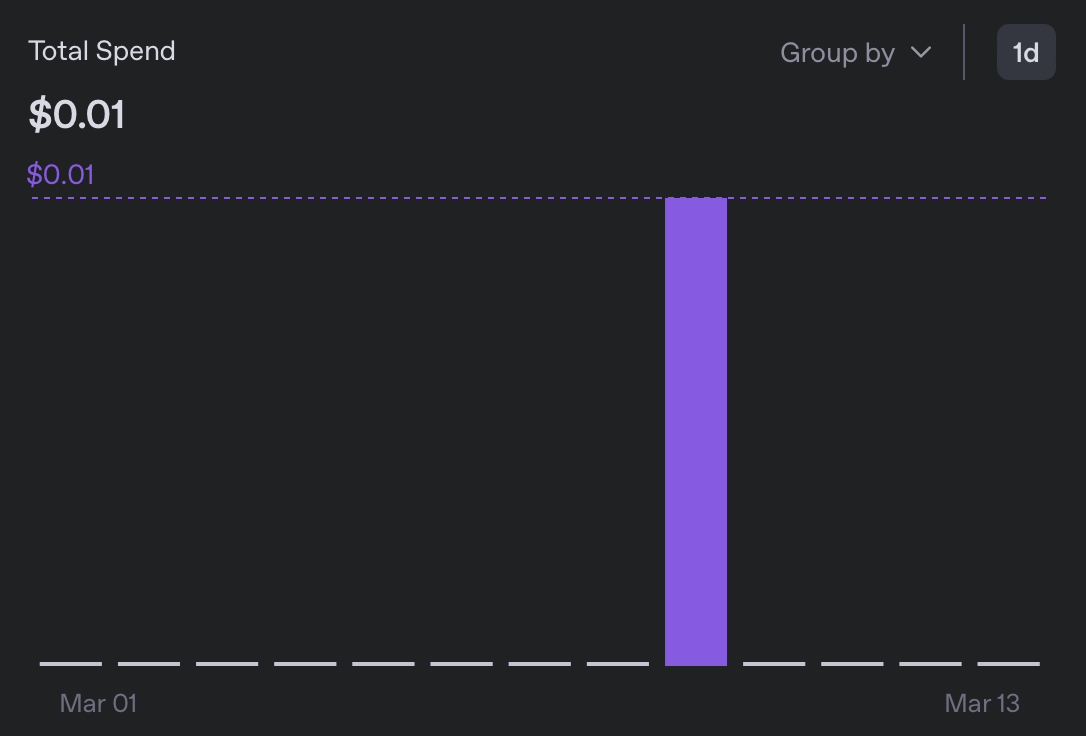
결과적으로 나온 메시지 번들을 훑어봤지만, 의심스러운 것은 없었습니다. 새롭게 추가된 언어 중에서는 어느 것도 읽지 못하지만 서식은 좋아 보이고, ‘그걸 해석해줄게요’라는 절을 찾아볼 수 없었습니다🙂
왜 중요한가
설명된 실험은 구체적인 문제를 다루지만, 대형 언어 모델의 보다 광범위하고 더 중요한 측면을 강조합니다. 그들이 특정 작업을 해결하는 데에서 전문화된 서비스를 능가하거나 못 미쳤을지라도, LLM이 놀라운 것은 빠르고 실용적인 해결책으로서, 더 전문화된 도구에 대한 일반적인 목적의 대안으로서 역할을 할 수 있다는 것입니다.
기계 학습에 대해 기본적인 지식만 가지고 있는 사람으로서, 나는 중급 해결책을 요구하는 작업 클래스를 피하려 했었습니다. 왜냐하면 그것은 나에게 없는 전문 지식이 필요했기 때문입니다. 그러나 이제는 분류기, 번역 서비스, LLMs-as-a-judge 등 무수히 많은 어플리케이션을 잘 짜낼 수 있게 되었습니다.
물론, 품질은 여전히 고려할 사항이지만, 현실적으로 많은 문제들에는 100% 완벽함이 필요하지 않습니다. 해킹을 하지 않을 이유가 하나 줄어들었습니다!
결론
이 글을 마무리하는 의미 있는 방법을 생각해내지 못했으므로, 오늘 만났던 고양이의 사진을 올립니다 (AI가 생성한 것이 아닙니다!):
