Junie programmiert (AsciiDoc-Unterstuetzung)
Andere Sprachen: English Español Français 日本語 한국어 Português 中文
Letzte Woche habe ich ueber den Duplicate Finder im Foojay Podcast gesprochen, moderiert von Frank Delporte. Wir haben kurz die Implementierung der Unterstuetzung fuer andere Formate angesprochen, und Frank fragte, ob ich plane, AsciiDoc hinzuzufuegen, da es nuetzlich fuer sein technisches Schreiben bei Azul sein koennte.
Wir haben uns darauf geeinigt, bald ueber die Unterstuetzung nachzudenken. Zur gleichen Zeit erhielt ich Zugang zu Junie, einem neu angekuendigten Coding-Agenten von JetBrains, der sich derzeit im Early Access befindet. Nach einer Weile kam mir der Gedanke, dass dies eine grossartige Gelegenheit ist, ihn in Aktion auszuprobieren. Coding-Agenten sind dafuer bekannt, typische Aufgaben gut zu loesen. Aber was ist mit einem Projekt, das nicht auf einem bekannten Framework basiert und ausserhalb einer sehr gaengigen Domaene liegt? Als jemand, der Coding-Agenten gegenueber eher skeptisch ist, waren meine Erwartungen gemischt.

So ist es gelaufen.
Installation und Ueberblick
Junie ist ein IntelliJ IDEA Plugin. Die Benutzeroberflaeche verwendet ein vertrautes vertikales Tool-Fenster, aehnlich dem von JetBrains AI Assistant oder GitHub Copilot. So sieht es aus:
Das minimalistische Design zeigt nur ein Prompt-Feld, eine Schaltflaeche zum Hinzufuegen von Kontext und ein Kontrollkaestchen mit dem Titel Brave Mode. Diese Option steuert, ob Junie Befehle ausfuehren kann, ohne bei Ihnen nachzufragen. Ich bin noch nicht so mutig, also werde ich das naechstes Mal ausprobieren.
Anforderungen festlegen
Bevor ich Junie die Programmieraufgabe gab, habe ich
ein Thema aus dem AsciiDoctor-Leitfaden heruntergeladen
und unter src/test/resources/ abgelegt, damit Junie es als Testdaten und Referenz verwenden kann.
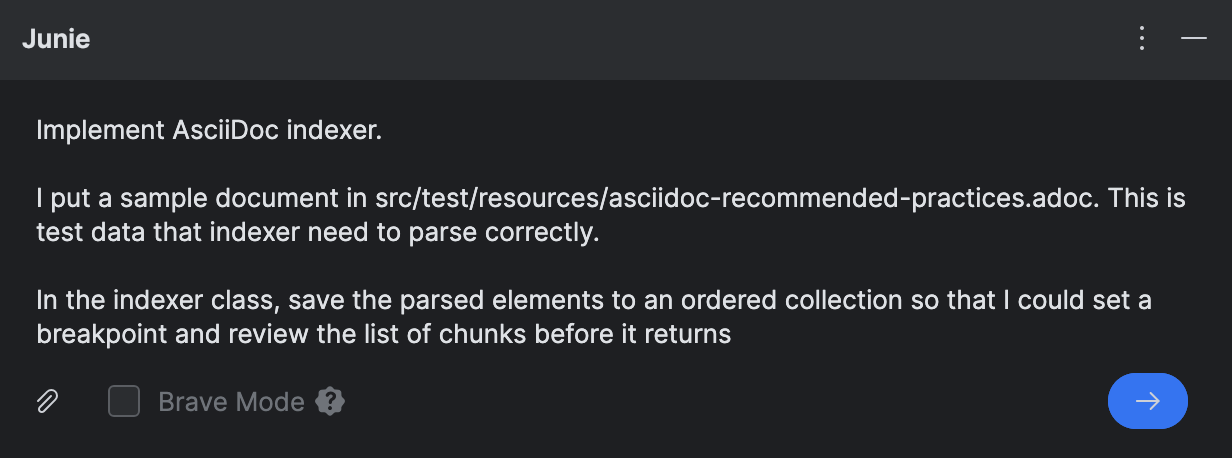
Zu Debugging-Zwecken bat ich Junie, die geparsten Bloecke einer separaten Collection hinzuzufuegen. Das liegt daran, dass der eigentliche Index in mehreren Ebenen strukturiert ist, was das Debugging unpraktisch macht. Der Einfachheit halber wuerde ich die geparsten Elemente lieber als flache Struktur betrachten, wenn ich die Ergebnisse zur Laufzeit ueberpruefen muss.
‘Programmieren’
Nachdem Sie den Prompt eingegeben haben, zerlegt Junie die Aufgabe in kleinere Elemente und beginnt mit der Implementierung. Fuer das Hinzufuegen der AsciiDoc-Unterstuetzung erstellte er folgenden Plan:
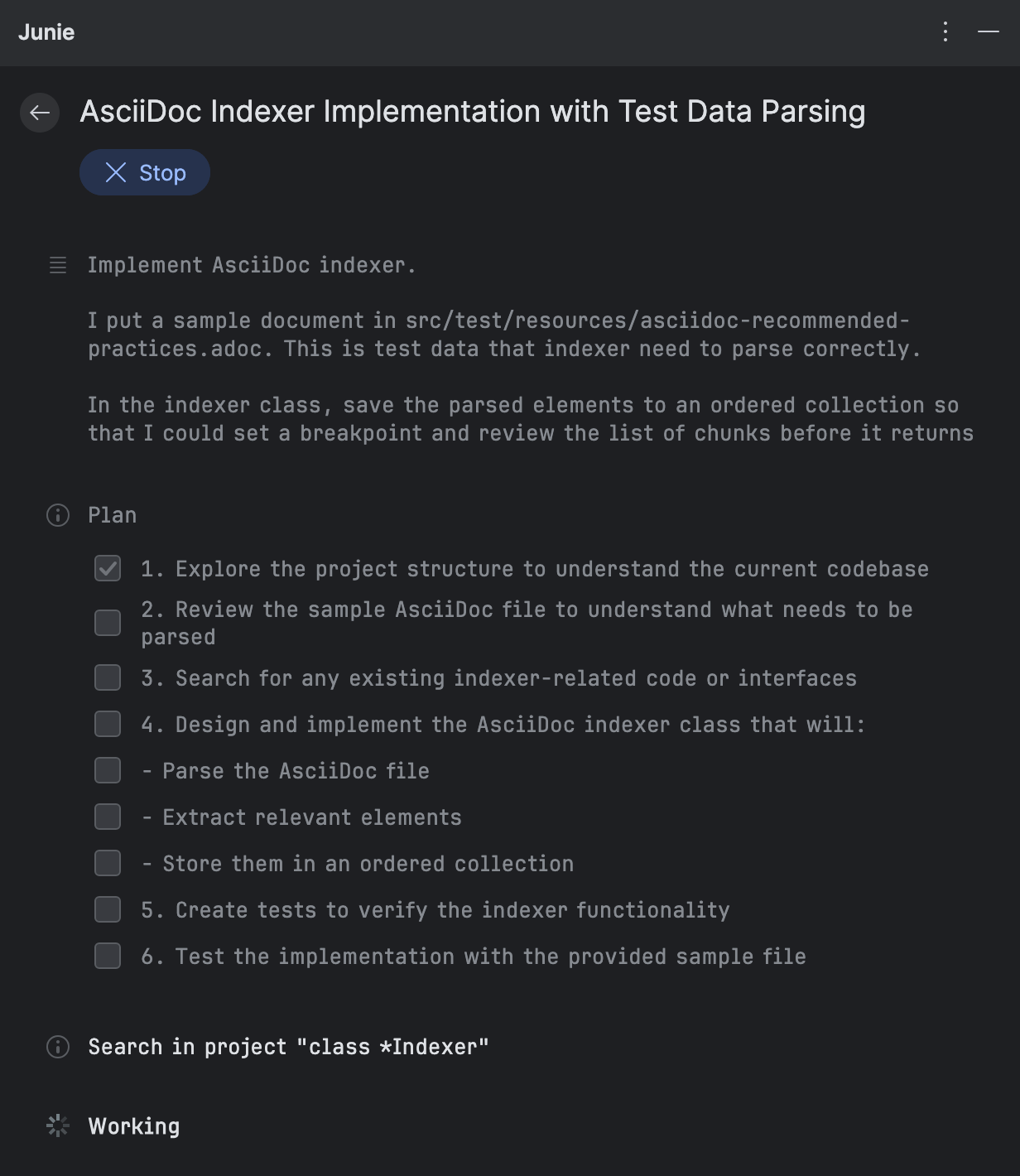
Waehrend Junie jedes Element ausfuehrt, gibt er Ihnen eine Zusammenfassung der Aenderungen. Sie koennen sie sofort ueberpruefen, ohne auf den Abschluss des gesamten Workflows warten zu muessen:

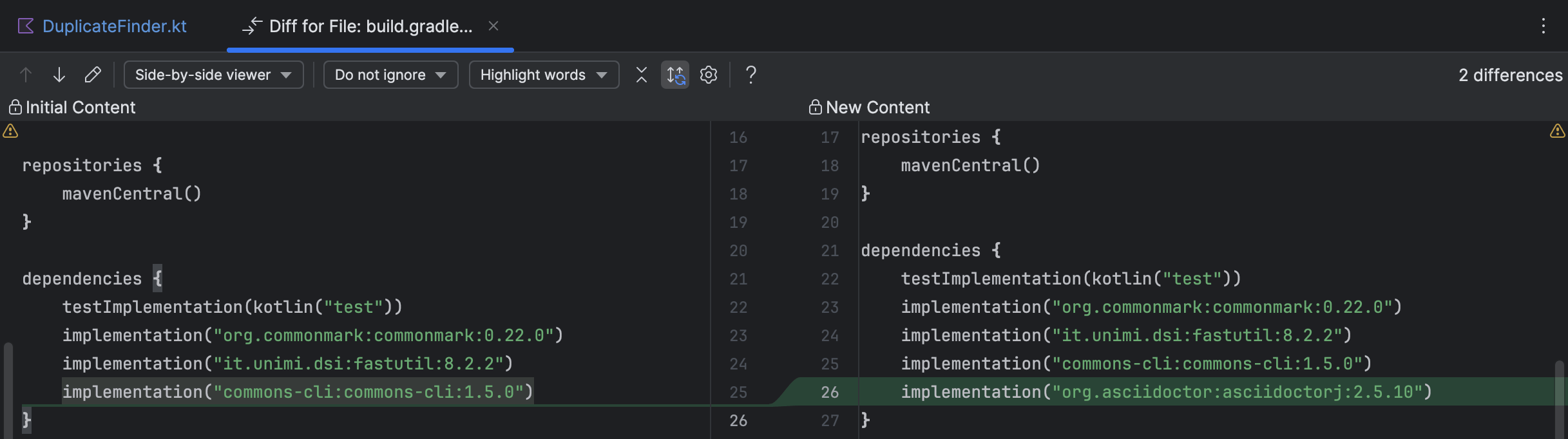
Durch Klicken auf die Dateinamen koennen Sie die Aenderungen in IntelliJ IDEAs Diff-Ansicht verfolgen, aehnlich wie beim Anzeigen von Git-Aenderungen oder Local History.
Nachdem alle Elemente abgeschlossen sind, faehrt Junie mit dem Schreiben der Tests fort und fordert Sie dann auf, sie auszufuehren:
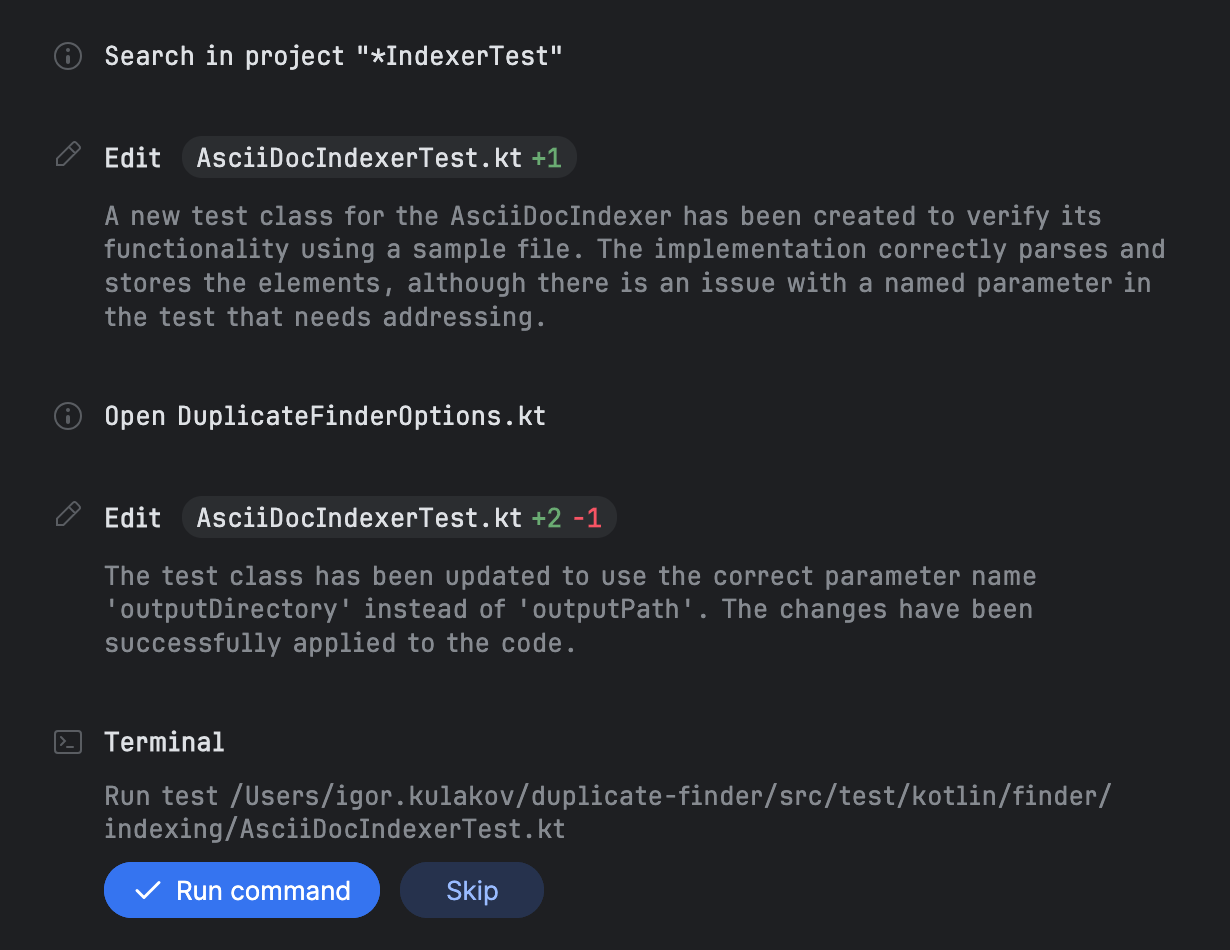
Bei dieser Aufgabe gab ich Junie Testdaten und forderte explizit Tests an. Es scheint jedoch, dass Junie sie zusammen mit den Testdaten standardmaessig generiert. Ich experimentierte damit, Aufgaben ohne Erwaehnung von Tests auszufuehren, und Junie erstellte sie trotzdem.
Nach dem Ausfuehren der Tests, die in diesem Fall erfolgreich waren, liefert Junie eine Zusammenfassung dessen, was getan wurde:

Codequalitaet
Bei der Ueberpruefung des Codes und der Tests fand ich sie gut strukturiert und sauber. Was mir wirklich gefallen hat, ist, dass Junie nicht nur den Code aenderte, der erforderlich war, damit das Projekt kompiliert, sondern auch den zusaetzlichen Schritt unternahm, andere sinnvolle Aenderungen im Kontext der Aufgabe einzufuehren.
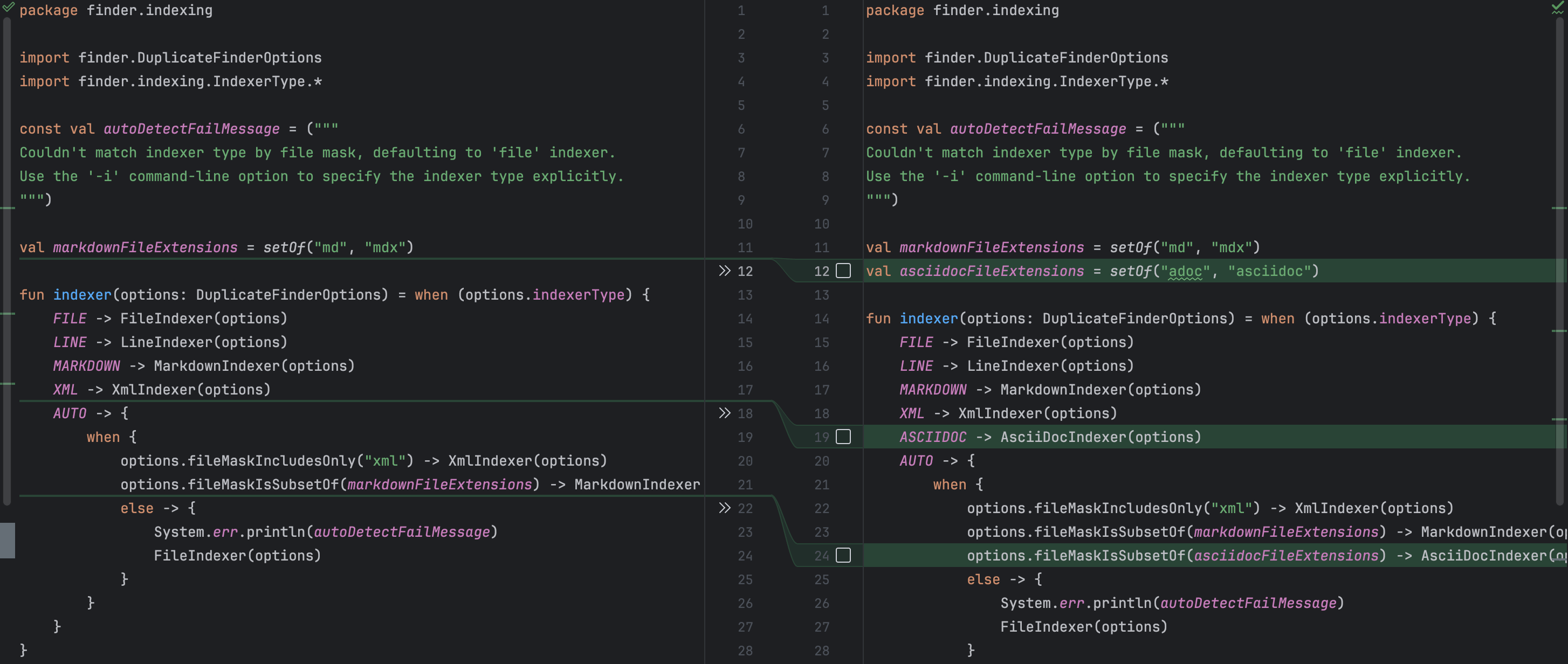
Zum Beispiel hatte ich vergessen zu erwaehnen, dass der neue Indexer in den Kommandozeilenargumenten verfuegbar gemacht werden muss. Dieses Versaeumnis wuerde keinen Kompilierungsfehler verursachen, aber es ergibt fuer den Endbenutzer keinen Sinn, wenn er nicht auf die Funktion zugreifen kann. Junie erkannte das und fuegte die entsprechende Kommandozeilenoption zusammen mit einer Beschreibung hinzu. Er aktualisierte auch korrekt die Factory-Methode, damit der Client-Code eine Instanz des neuen Indexers erhalten kann. Gleichzeitig gab es keine unnoetige Aenderungen, was ebenfalls grossartig ist!
Bisher ist alles gut, aber es scheint, dass noch mehr Arbeit getan werden muss.
Die Implementierung korrigieren
Ein Bereich, in dem Coding-Agenten noch nicht vollstaendig autonom sind, ist das Identifizieren potenzieller Probleme zur Laufzeit. Technisch gesehen ist die Implementierung korrekt, und sie besteht alle Tests. Die Ergebnisse des Parsings sind konsistent, wie im Evaluate-Dialog zu sehen.
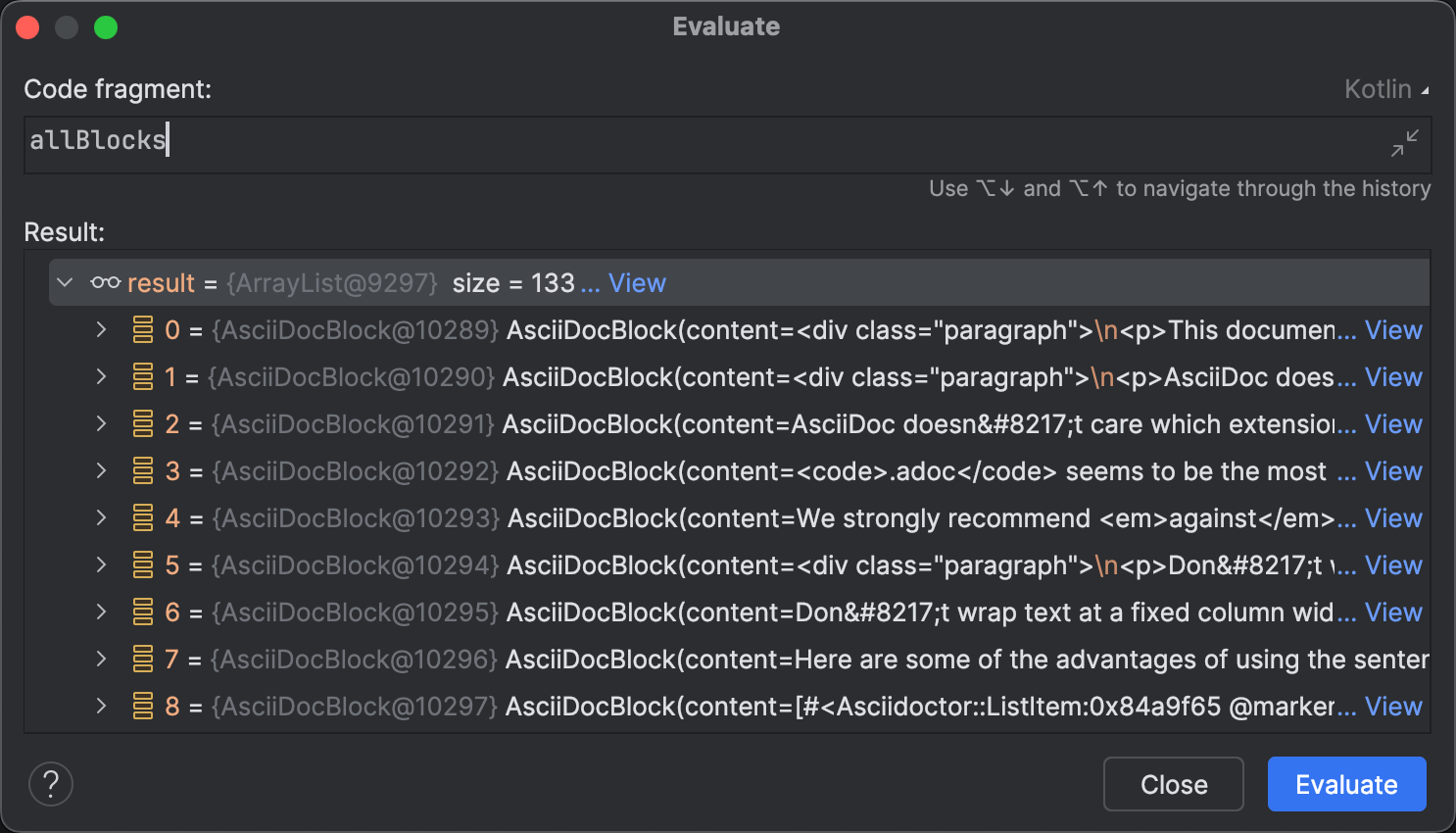

Evaluate Expression hat viele interessante Anwendungsfaelle ueber das Erkunden von Collections hinaus. Zum Beispiel koennen Sie es verwenden, um Fixes zu prototypisieren und auf ein laufendes Programm anzuwenden oder das Programmverhalten beliebig zu modifizieren
Alles sieht gut aus, ausser dass die Verarbeitung einer einzelnen Datei
ueberraschend lange dauert. Bei naeherem Hinsehen stellte ich auch fest, dass das Parsen eines Batches von etwa 35 Dateien immer mit
einem OutOfMemoryError fehlschlaegt.
Bei der Analyse der Implementierung fand ich keine offensichtlichen Maengel wie ineffiziente Schleifen oder Ressourcenlecks.
Das Ausfuehren der App mit -XX:+HeapDumpOnOutOfMemoryError gab mir einen Heap Dump, der
zahlreiche JRuby-Typen mit riesigen Retained Sizes zeigte.
Dies deutete auf die Bibliothek als moegliche Problemquelle hin.
Natuerlich ist diese Vermutung moeglicherweise nicht genau, was uns eine faszinierende Gelegenheit fuer Profiling (oder das Lesen der Dokumentation) gibt. Auf jeden Fall wuerde das Ersetzen einer JRuby-Abhaengigkeit durch eine einfache Kotlin-Implementierung die Dinge sehr wahrscheinlich beschleunigen. Also beschloss ich, Junie zu bitten, die Implementierung mit einem benutzerdefinierten Parser neu zu schreiben.
Anstatt eine neue Aufgabe zu starten, verwendete ich dafuer den Follow up-Prompt:
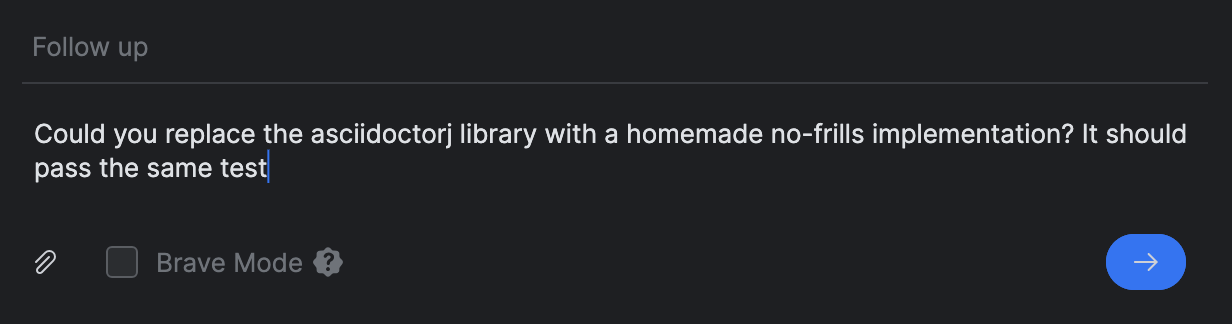
Ergebnisse
Junie ueberarbeitete die Implementierung wie gewuenscht. Obwohl ich mit dem AsciiDoc-Format nicht sehr vertraut bin, scheint das Parsing auf den ersten Blick groesstenteils korrekt zu sein. Es gibt Verbesserungspotenzial beim Parsing der Preamble und wahrscheinlich auch bei anderen Dingen, aber es erfuellt seinen Zweck.
Das Ausfuehren des aktualisierten Duplicate Finders auf der eigenen Hilfe von AsciiDoctor erkannte einige Duplikate! Die Analyse dauerte auf meinem Laptop 350 Millisekunden:
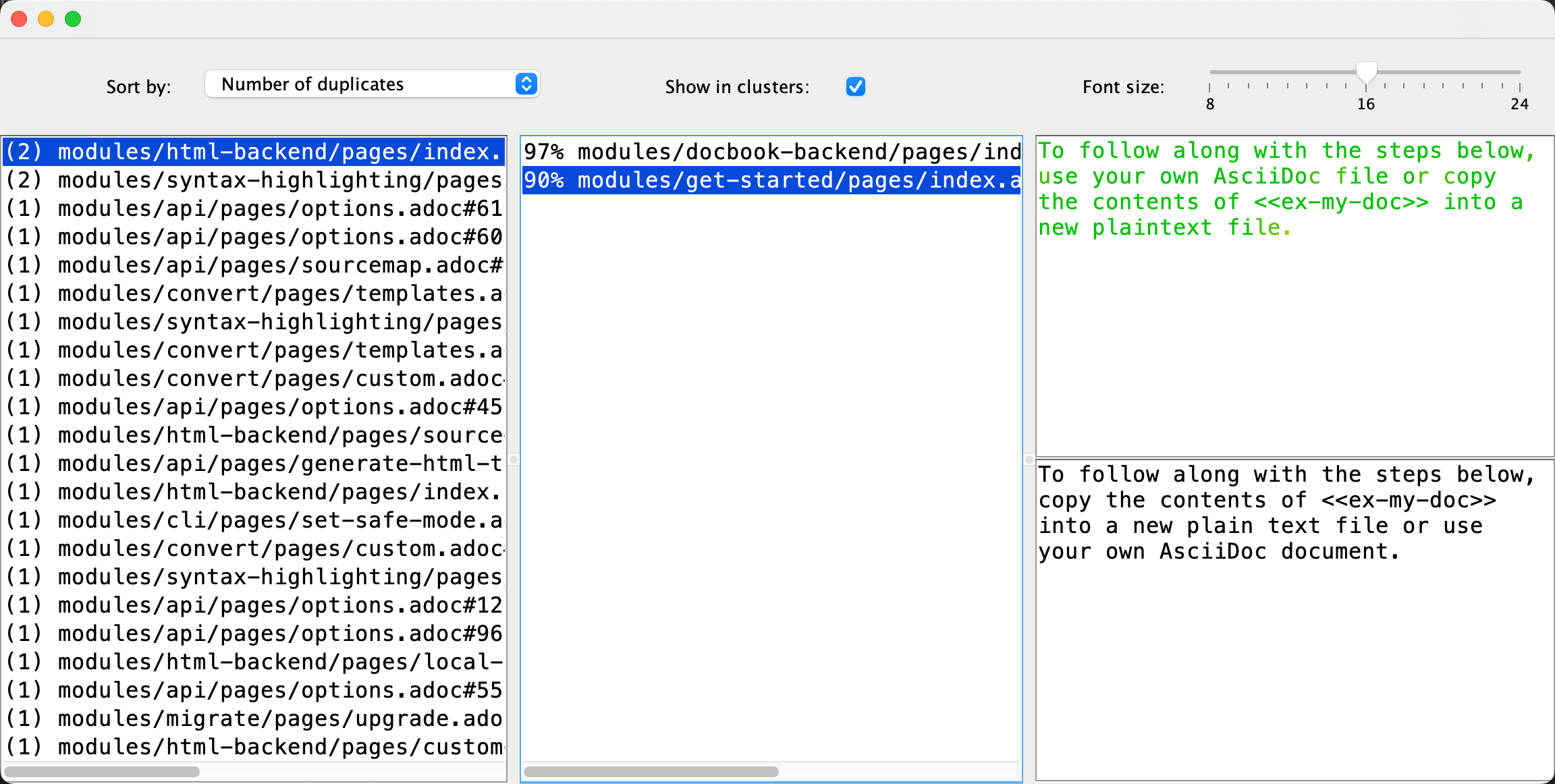
Das Projekt mit den committeten Aenderungen ist auf meinem GitHub. Um die neue Version der App auszuprobieren, finden Sie die Anweisungen und den Download-Link auf der Duplicate Finder-Seite. Insgesamt ist die Implementierung vielleicht nicht perfekt, und sie erfordert definitiv gruendlichere Ueberpruefung, aber trotzdem bin ich sehr beeindruckt davon, was man heutzutage in 5 Minuten erledigen kann.
Wenn Sie Junie selbst ausprobieren moechten, koennen Sie sich hier fuer das EAP anmelden.