Junie Codifica (Soporte AsciiDoc)
Otros idiomas: EnglishFrançaisDeutsch日本語한국어Português中文
La semana pasada, hablé sobre Duplicate Finder en el Podcast de Foojay presentado por Frank Delporte. Tocamos brevemente la implementación del soporte para otros formatos, y Frank preguntó si planeo añadir AsciiDoc, ya que podría ser útil para su redacción técnica en Azul.
Acordamos pensar en agregar el soporte pronto. Al mismo tiempo obtuve acceso a Junie, un recién anunciado agente de programación por JetBrains, que actualmente está en acceso anticipado. Después de un tiempo, se me ocurrió que esta es una gran oportunidad para probarlo en acción. Los agentes de programación son conocidos por resolver tareas típicas de forma eficaz. Pero, ¿qué pasa con un proyecto que no se basa en un marco de trabajo conocido y está fuera de un dominio muy común? Como un escéptico de los agentes de programación, mis expectativas eran mixtas.
Aquí está cómo fue.
Instalación y visión general
Junie es un plugin de IntelliJ IDEA. La interfaz de usuario adopta una ventana de herramientas verticales familiar, similar a la del JetBrains AI Assistant o GitHub Copilot. Así es como se ve:
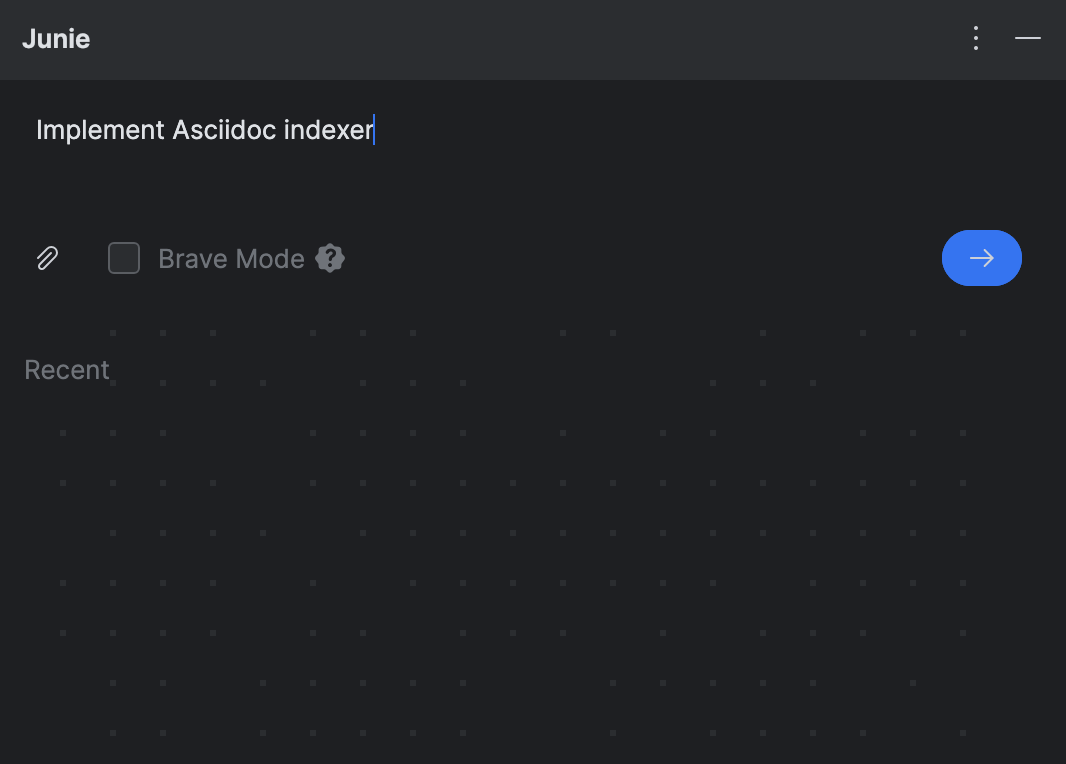
El diseño minimalista solo presenta un campo de indicaciones, un botón para agregar contexto, y una casilla de verificación titulada Brave Mode. Esta opción controla si Junie puede ejecutar comandos sin consultar doblemente contigo. Aún no soy tan valiente, así que lo intentaré la próxima vez.
Estableciendo requisitos
Antes de dar a Junie la tarea de programación, descargué
un tema de la guía AsciiDoctor
y lo coloqué bajo src/test/resources/ para que Junie lo use como datos de prueba y referencia.
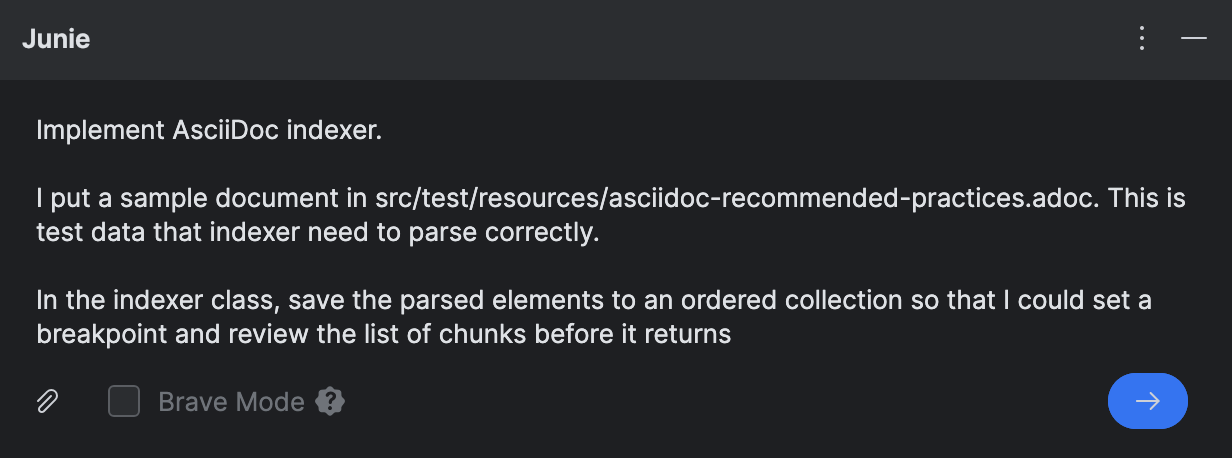
Para fines de depuración, pedí a Junie que añadiera los bloques analizados a una colección separada. Esto se debe a que el índice actual está estructurado en varios niveles, lo que dificulta la depuración. Por simplicidad, prefiero ver los elementos analizados como una estructura plana, si necesito verificar los resultados en tiempo de ejecución.
‘Programando’
Después de introducir la indicación, Junie desglosa la tarea en elementos más pequeños y comienza a implementarlos. Para añadir el soporte AsciiDoc, se le ocurrió el siguiente plan:
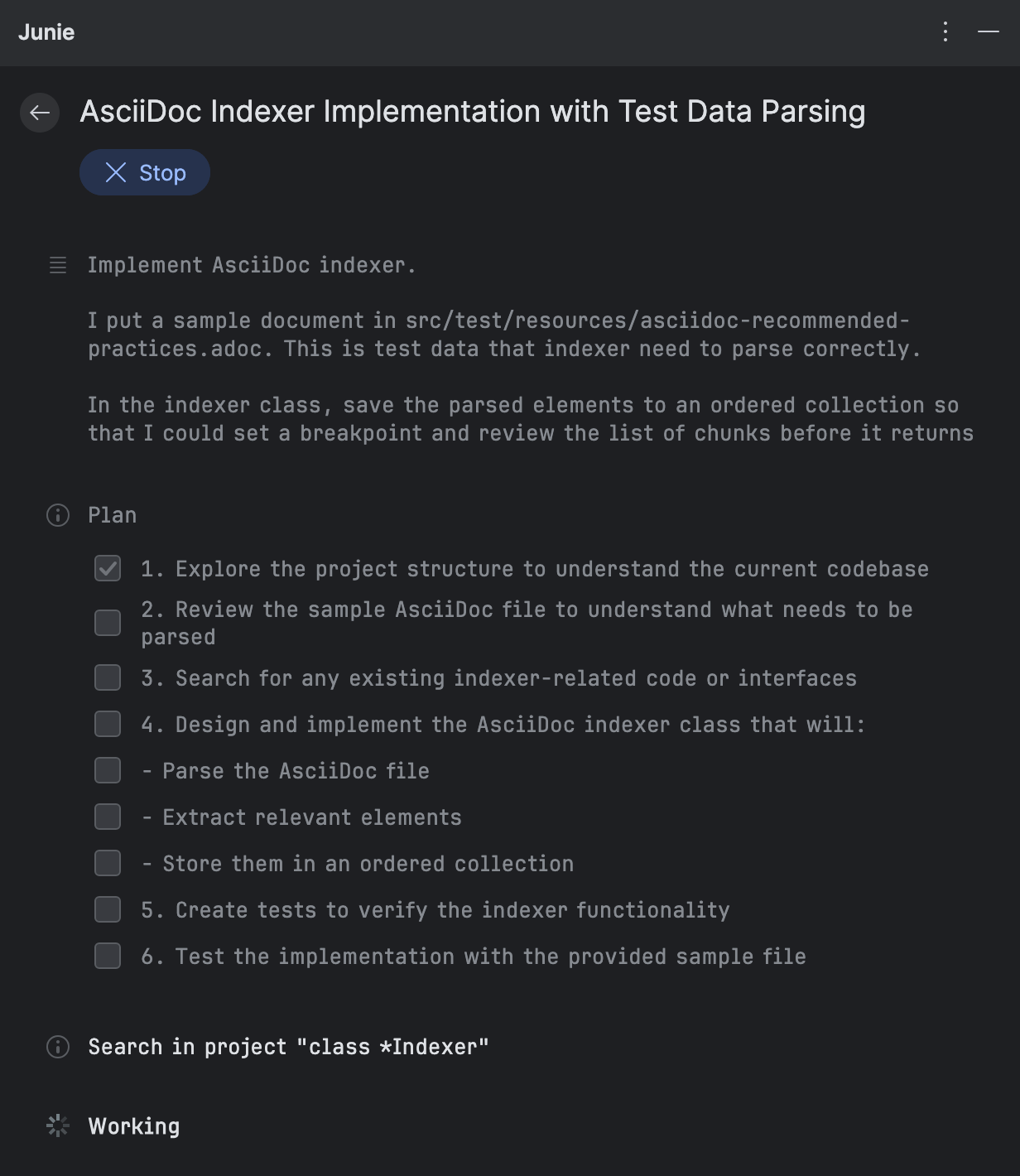
A medida que Junie ejecuta cada elemento, te da el resumen de los cambios. Puedes revisarlos de inmediato, sin tener que esperar a que se complete todo el flujo de trabajo:

Al hacer clic en los nombres de archivo, puedes seguir los cambios en la vista de diferencias de IntelliJ IDEA de una manera similar a ver los cambios de Git o Local History.
Después de que se completan todos los elementos, Junie procede a escribir las pruebas y luego te indica que las ejecutes:
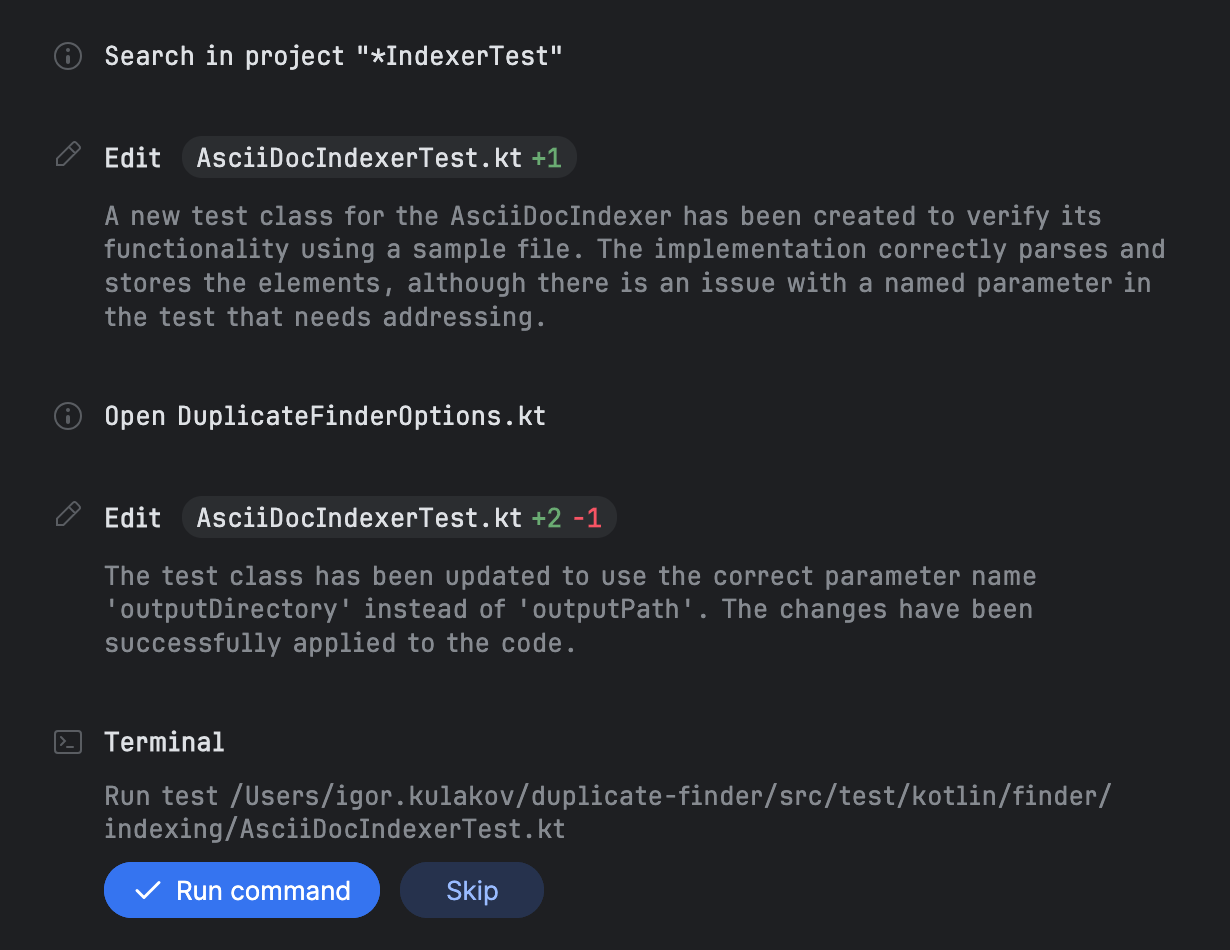
En esta tarea, le di a Junie datos de prueba y solicité explícitamente pruebas. Sin embargo, parece que Junie los genera junto con los datos de prueba por defecto. Experimenté ejecutando tareas sin mencionar las pruebas, y Junie las creó de todos modos. Para ejecutar las pruebas, Junie utiliza la ventana de herramientas Run de IntelliJ IDEA.
Después de ejecutar las pruebas, que en este caso fueron exitosas, Junie proporciona un resumen de lo que se ha hecho:

Calidad del código
Al revisar el código y las pruebas, encontré que estaban bien estructurados y eran ordenados. Lo que realmente me gustó es que Junie cambió no sólo el código necesario para que el proyecto se compilara, sino que también dio el paso adicional de introducir otros cambios significativos en el contexto de la tarea.
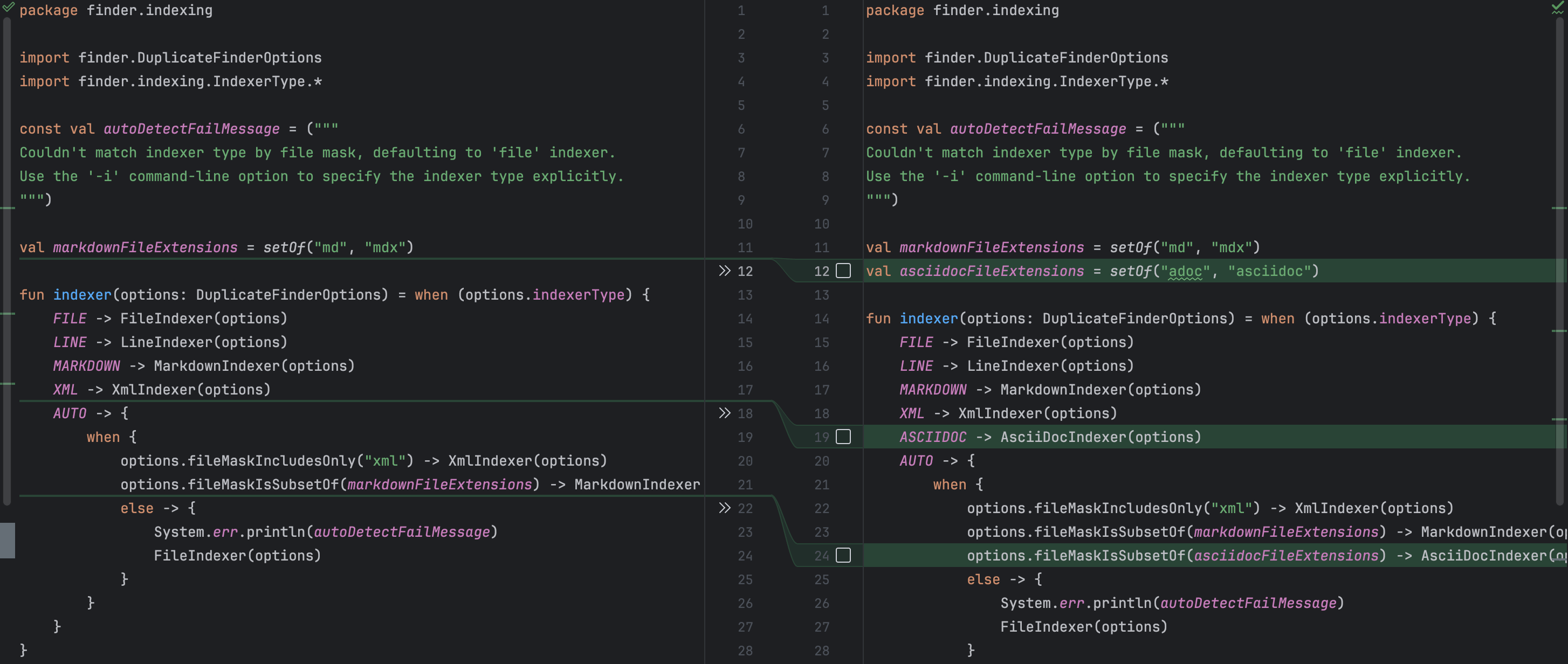
Por ejemplo, se me pasó por alto mencionar que el nuevo indexador debe exponerse en los argumentos de la línea de comandos. Este descuido no causaría un error de compilación, pero aún así no tiene sentido para el usuario final si no pueden acceder a la función. Junie reconoció eso y añadió la opción correspondiente de línea de comandos junto con una descripción. También actualizó correctamente el método de fábrica, para que el código del cliente pudiera obtener una instancia del nuevo indexador. Al mismo tiempo, no hubo cambios innecesarios, ¡lo cual también es genial!
Todo va bien hasta ahora, pero parece que todavía hay más trabajo por hacer.
Corrigiendo la implementación
Un área en la que los agentes de programación aún no son totalmente autónomos es la identificación de posibles problemas en tiempo de ejecución. Técnicamente, la implementación es correcta, y pasa todas las pruebas. Los resultados del análisis son consistentes, como se ve en el diálogo Evaluate.
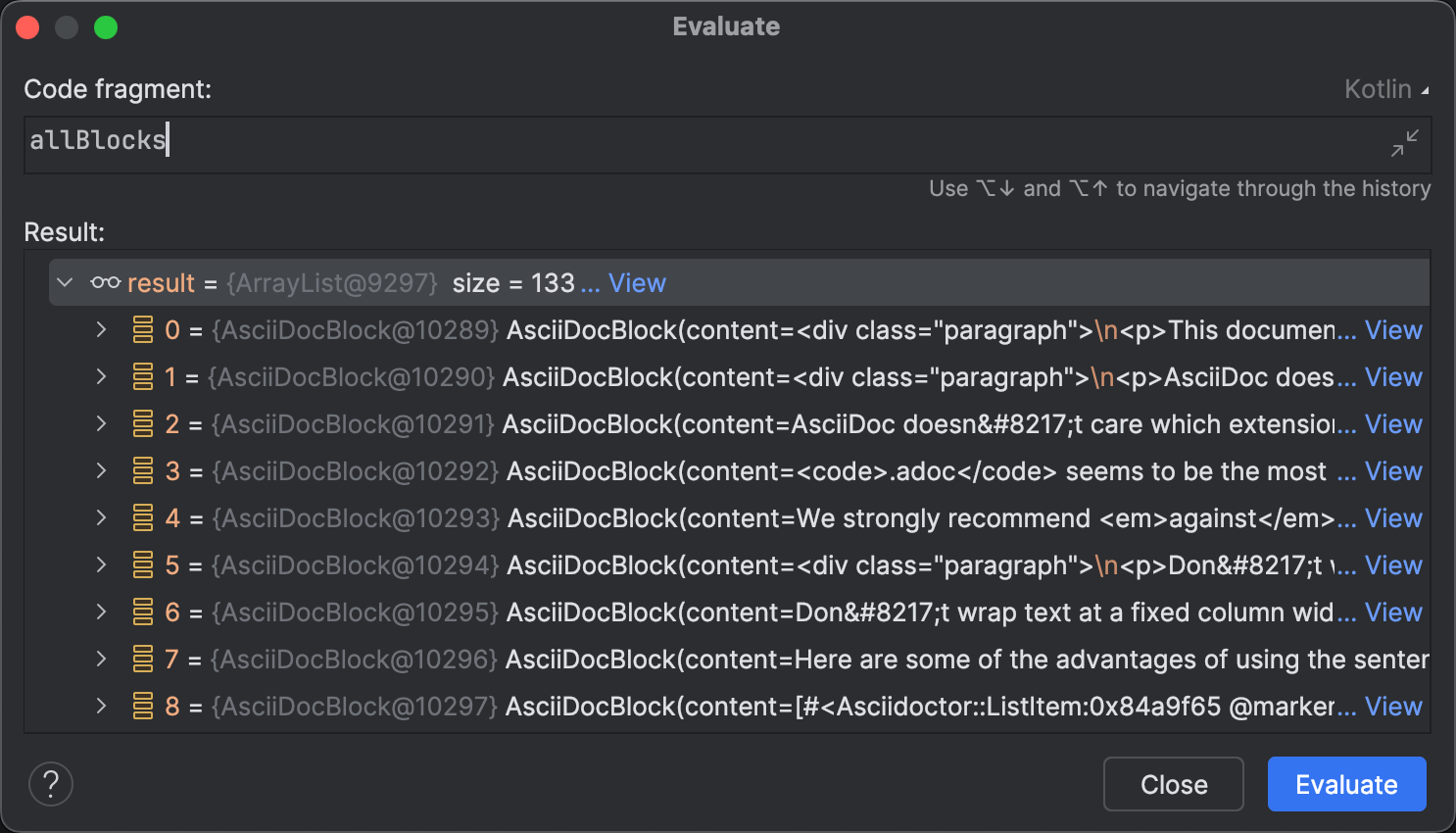
Evaluate Expression tiene muchos casos de uso interesantes más allá de explorar colecciones. Por ejemplo, puedes usarlo para prototipar y aplicar correcciones sin reiniciar el programa o modificar arbitrariamente su estado
Todo parece estar bien, excepto que el procesamiento de un solo archivo está tomando
sorprendentemente mucho tiempo. Al mirarlo, también descubrí que el análisis de un lote de ~35 archivos siempre falla
con un OutOfMemoryError .
Al analizar la implementación, no encontré ninguna falla obvia como bucles ineficientes o recursos que se escapan.
La ejecución de la aplicación con -XX:+HeapDumpOnOutOfMemoryError me dio un volcado de memoria, que
reveló numerosos tipos de JRuby con tamaños retenidos enormes.
Esto indicó la biblioteca como una posible fuente del problema.
Por supuesto, esta suposición podría no ser precisa, dándonos una fascinante oportunidad para hacer un perfil (o leer la documentación). De todos modos, la sustitución de una dependencia de JRuby por una implementación simple de Kotlin aceleraría muy probablemente las cosas. Por lo tanto, decidí pedir a Junie que reescribiera la implementación usando un analizador personalizado.
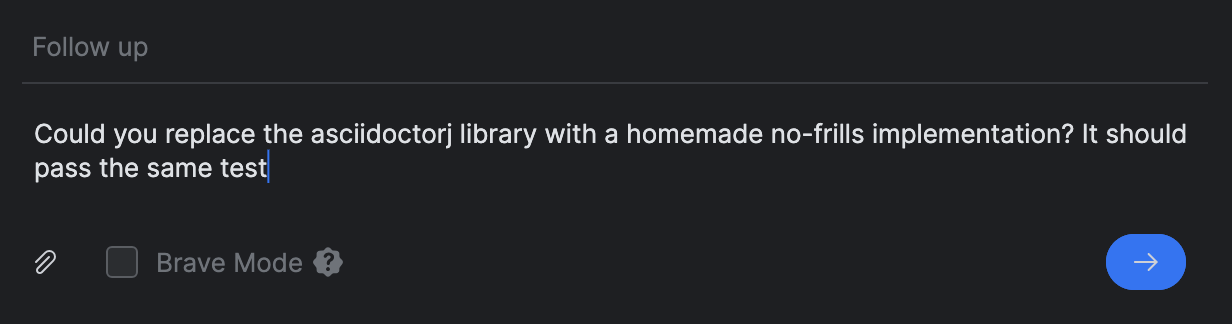
En lugar de comenzar una nueva tarea, utilicé el indicador Follow up para ello:
Resultados
Junie revisó la implementación según lo solicitado. Aunque no estoy muy familiarizado con el formato AsciiDoc, el análisis parece ser en gran medida correcto a primera vista. Hay algo de margen de mejora en el análisis del prefacio, y probablemente algo más, pero hace su trabajo.
Al ejecutar el Buscador de Duplicados actualizado en la propia ayuda de AsciiDoctor se detectaron algunos duplicados. ¡El análisis tomó 350 milisegundos en mi portátil!
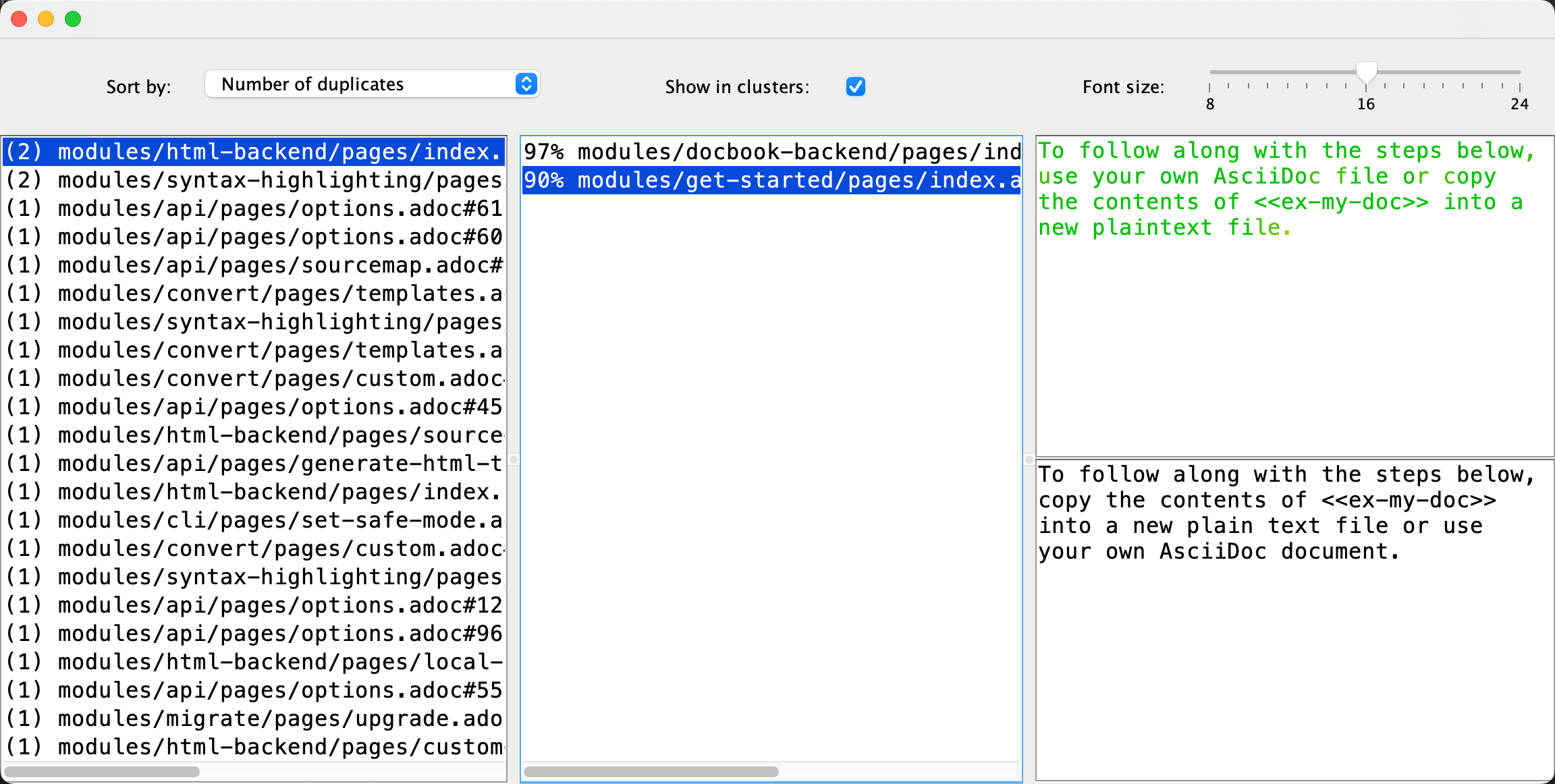
El proyecto con los cambios comprometidos está en mi GitHub. Para probar la nueva versión de la aplicación, puedes encontrar instrucciones y el enlace de descarga en la página de Duplicate Finder. En general, la implementación puede no ser perfecta, y definitivamente requiere una revisión más exhaustiva, pero aún así estoy muy impresionado por lo que se puede conseguir en 5 minutos hoy en día.
Si te gustaría probar Junie tú mismo, puedes registrarte para EAP aquí.