Junie Codes (Suporte AsciiDoc)
Outras línguas: EnglishEspañolFrançaisDeutsch日本語한국어中文
Na semana passada, eu falei sobre o Localizador de Duplicatas no Podcast Foojay apresentado por Frank Delporte. Nós abordamos brevemente a implementação de suporte a outros formatos e Frank perguntou se eu estava planejando adicionar o suporte ao AsciiDoc, pois poderia ser útil para seus trabalhos técnicos na Azul.
Concordamos em pensar sobre adicionar o suporte em breve. Ao mesmo tempo, tive acesso ao Junie, um novo agente de codificação anunciado pela JetBrains, que atualmente está em acesso antecipado. Depois de um tempo, me ocorreu que essa era uma ótima oportunidade para testá-lo em ação. Os agentes de codificação são conhecidos por resolver tarefas típicas de forma eficaz. Mas, e quanto a um projeto que não é baseado em um framework bem conhecido e que está fora de um domínio muito comum? Como um cético em relação ao agente de codificação, minhas expectativas estavam mistas.
Aqui está como foi.
Instalação e visão geral
Junie é um plugin do IntelliJ IDEA. A interface de usuário adota uma janela de ferramenta vertical familiar, semelhante à do JetBrains AI Assistant ou GitHub Copilot. Aqui está como se parece:
O design minimalista possui apenas um campo de prompt, um botão para adicionar contexto e uma caixa de seleção intitulada Brave Mode. Esta opção controla se Junie pode executar comandos sem verificar novamente com você. Eu não sou tão corajoso ainda, então tentarei isso na próxima vez.
Definindo requisitos
Antes de dar a tarefa de codificação para o Junie, eu baixei
um tópico do guia AsciiDoctor
e o coloquei em src/test/resources/ para que Junie usasse como dados de teste e referência.
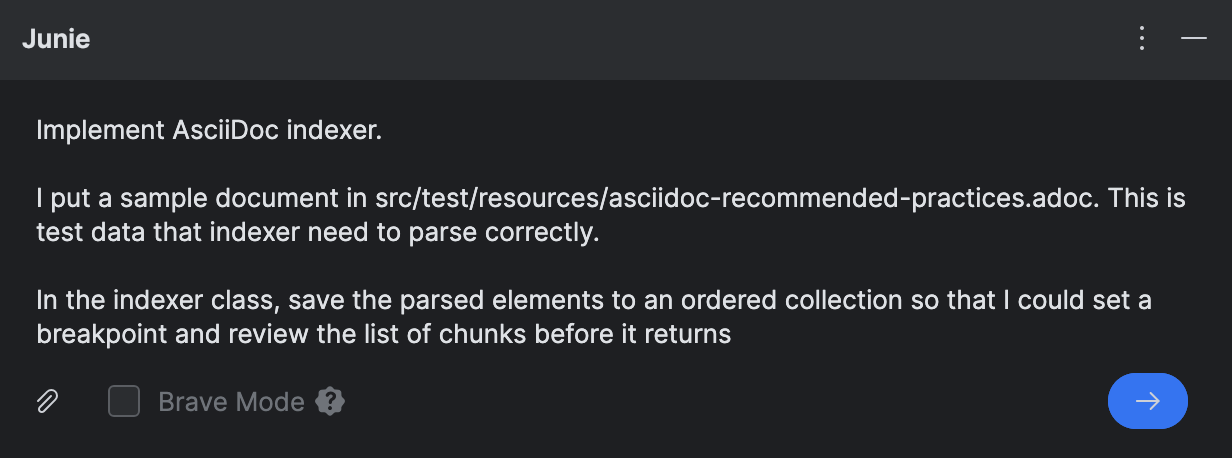
Para fins de depuração, pedi ao Junie para adicionar os blocos analisados a uma coleção separada. Isso porque o índice atual é estruturado em vários níveis, o que torna inconveniente para depurar. Por simplicidade, prefiro ver os elementos analisados como uma estrutura plana, se eu precisar verificar os resultados durante a execução.
‘Codificação’
Depois de inserir o prompt, o Junie divide a tarefa em itens menores e começa a implementá-los. Para adicionar suporte ao AsciiDoc, ele elaborou o seguinte plano:
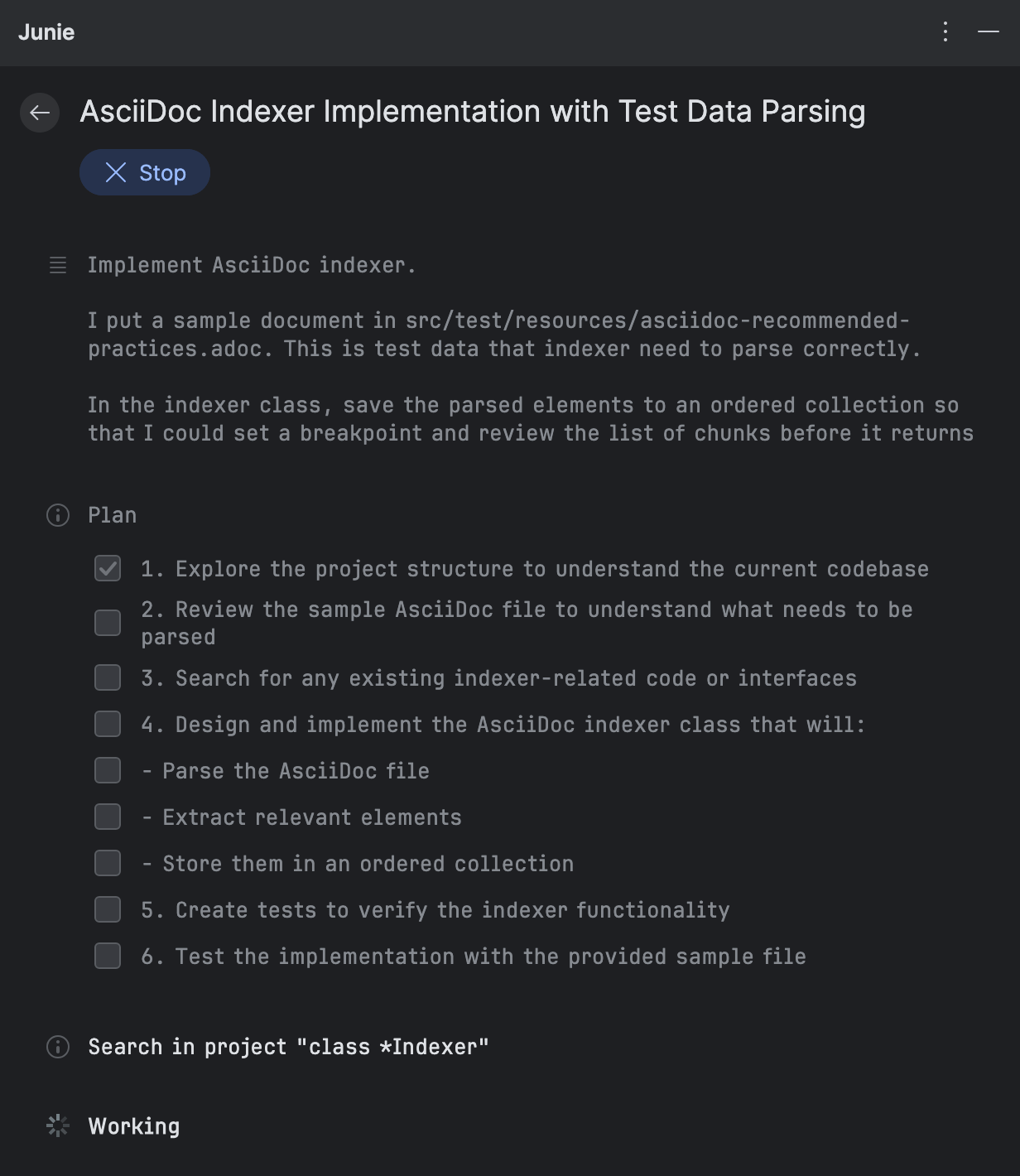
Conforme Junie executa cada item, ele fornece um resumo das alterações. Você pode revisá-las imediatamente, sem ter que esperar a conclusão de todo o fluxo de trabalho:

Clicando nos nomes dos arquivos, você pode acompanhar as alterações na visão de diferença do IntelliJ IDEA de forma semelhante a exibir alterações Git ou Local History.
Depois que todos os itens são concluídos, o Junie prossegue escrevendo os testes e, em seguida, pede para você executá-los:
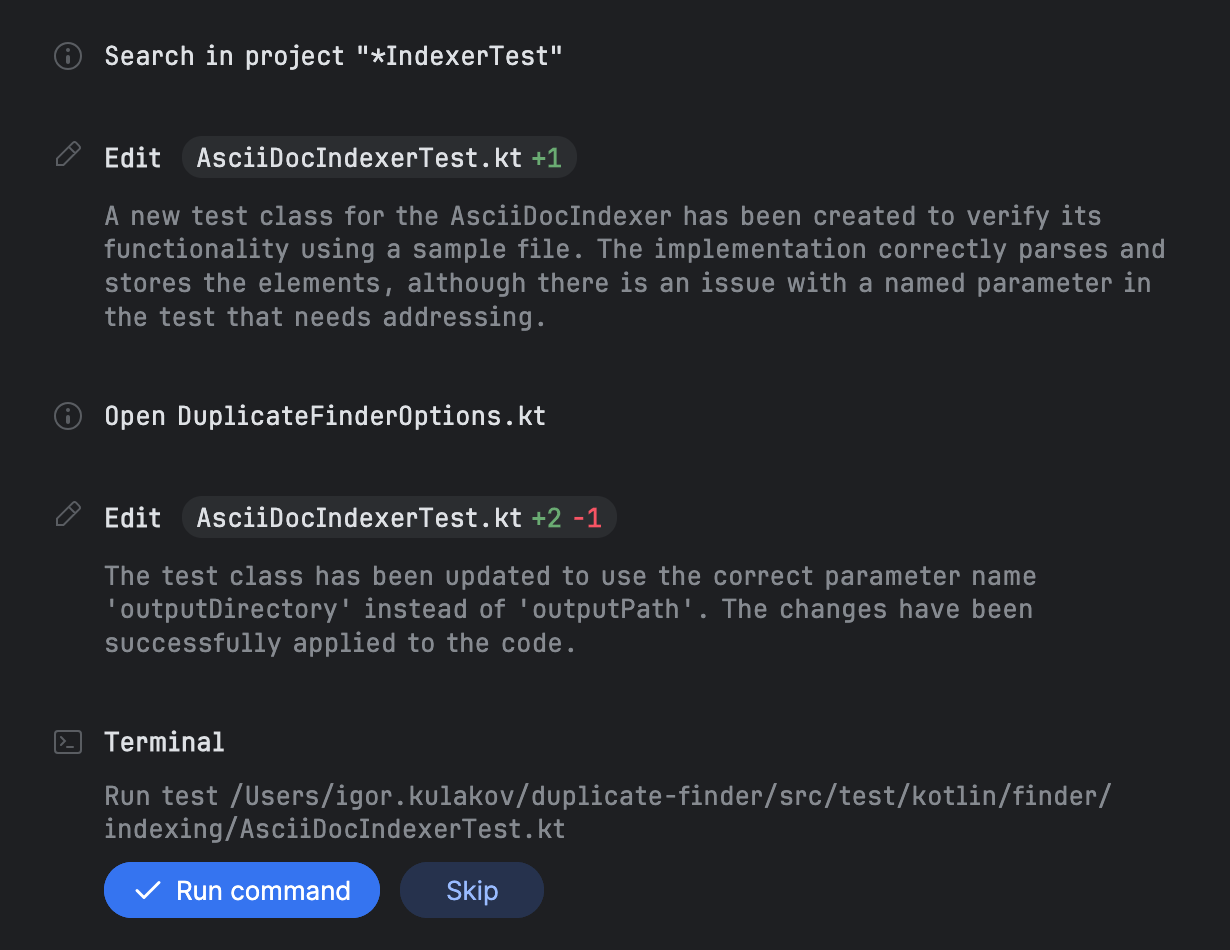
Nesta tarefa, dei ao Junie dados de teste e solicitei explicitamente os testes. No entanto, parece que Junie os gera juntamente com os dados de teste por padrão. Experimentei executar tarefas sem mencionar testes, e Junie os criou de qualquer maneira. Para executar os testes, Junie usa a janela de ferramentas Run do IntelliJ IDEA.
Após a execução dos testes, que foram bem-sucedidos neste caso, Junie fornece o resumo do que foi feito:

Qualidade do código
Ao revisar o código e os testes, achei-os bem estruturados e organizados. O que realmente gostei é que o Junie alterou não apenas o código necessário para o projeto compilar, mas também deu o passo extra para introduzir outras alterações significativas no contexto da tarefa.
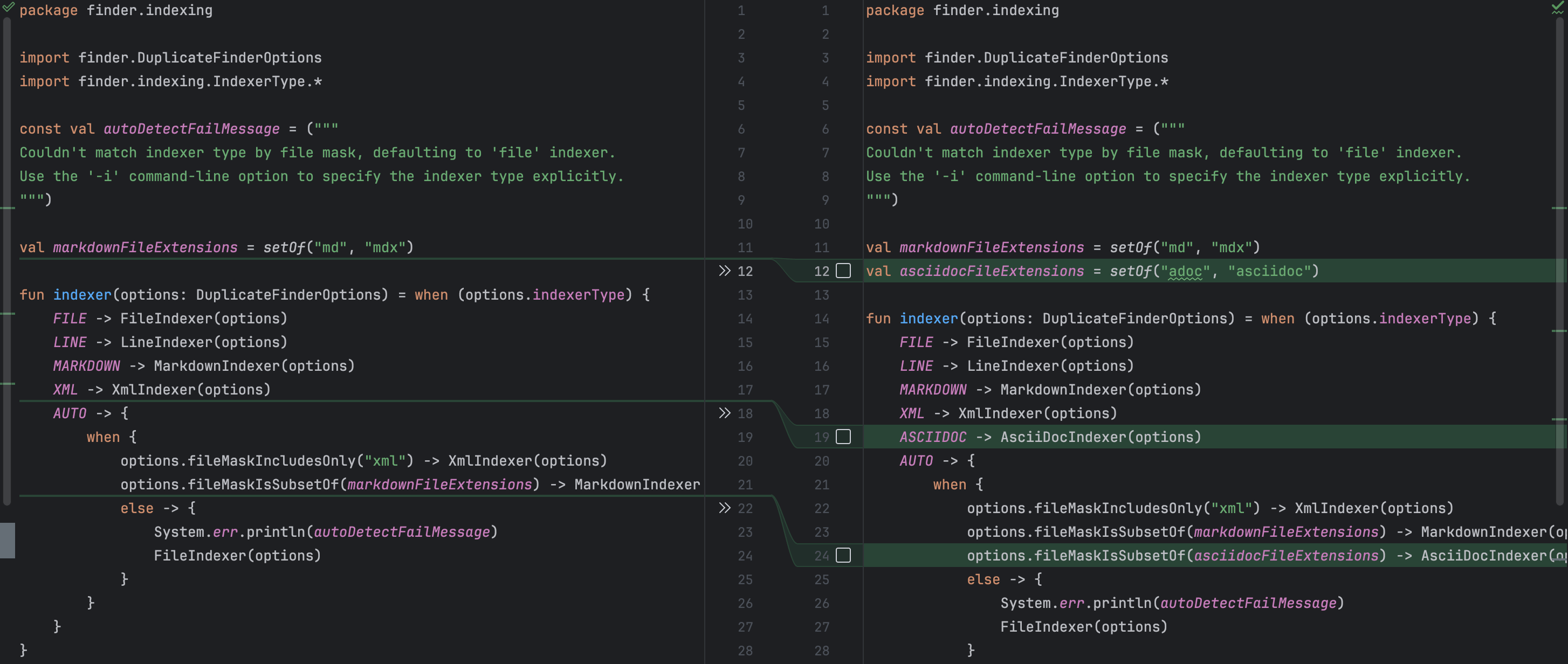
Por exemplo, esqueci de mencionar que o novo indexador deve ser exposto nos argumentos de linha de comando. Essa supervisão não causaria um erro de compilação, mesmo assim, não faz sentido para o usuário final se ele não pode acessar o recurso. Junie reconheceu isso e adicionou a opção de linha de comando correspondente junto com uma descrição. Ele também atualizou corretamente o método de fábrica, para que o código do cliente pudesse obter uma instância do novo indexador. Ao mesmo tempo, não houve alterações desnecessárias, o que também é ótimo!
Tudo está bom até agora, mas parece que ainda há mais trabalho a ser feito.
Corrigindo a implementação
Uma área onde os agentes de codificação ainda não são totalmente autônomos é a identificação de possíveis problemas em tempo de execução. Tecnicamente, a implementação está correta e passa em todos os testes. Os resultados da análise são consistentes, como visto no diálogo Avaliar.
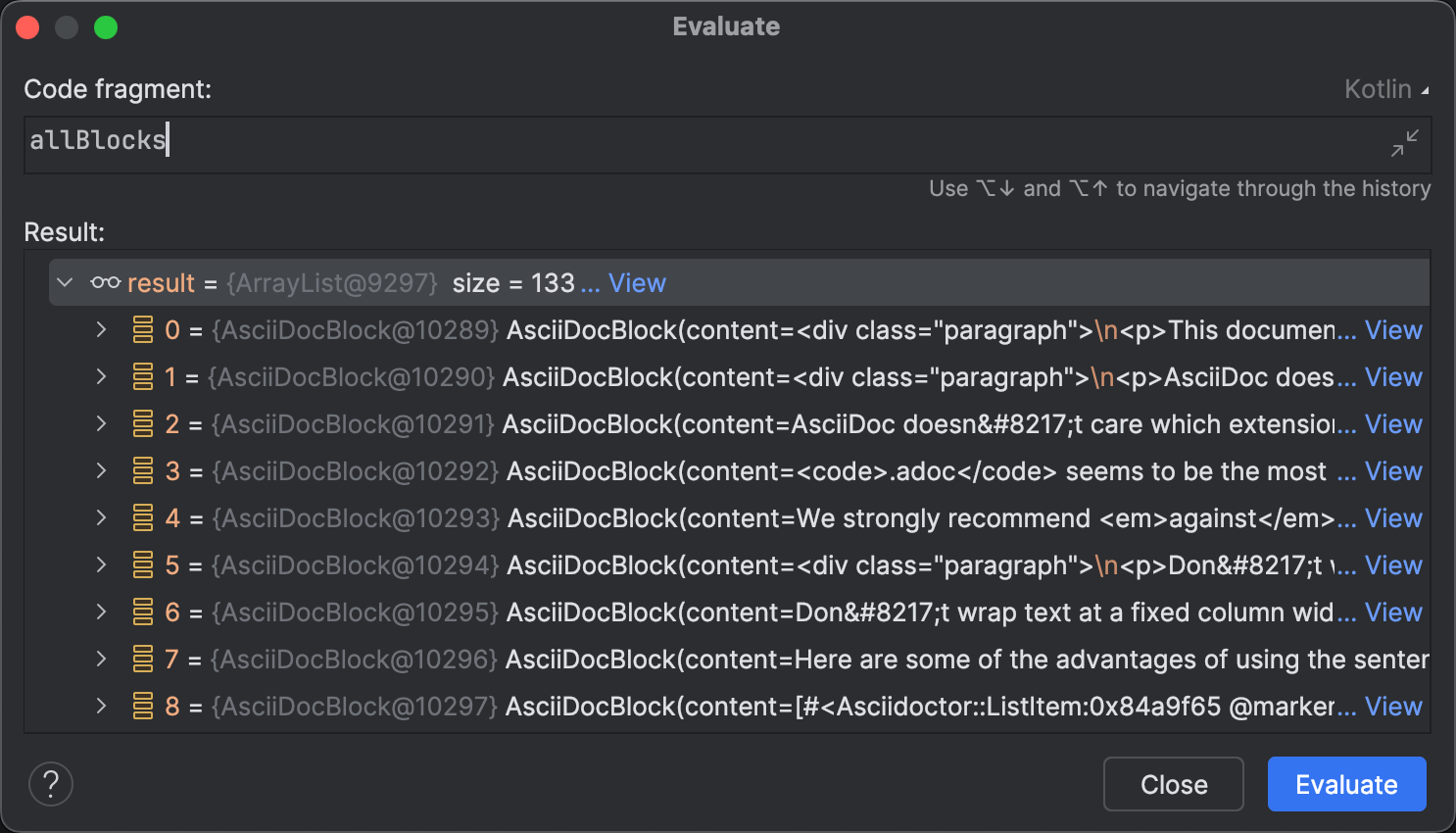
Evaluate Expression tem uma variedade de usos interessantes para além de explorar coleções. Por exemplo, você pode usá-lo para prototipar e aplicar correções sem reiniciar o programa ou modificar arbitrariamente o seu estado
Tudo parece bem, exceto que o processamento de um único arquivo está demorando
surpreendentemente muito. Ao investigar, também descobri que a análise de um lote de ~35 arquivos sempre falha
com um OutOfMemoryError .
Ao analisar a implementação, não encontrei falhas óbvias, como loops ineficientes ou vazamento de recursos.
A execução do aplicativo com -XX:+HeapDumpOnOutOfMemoryError me deu um despejo de heap, que
revelou vários tipos de JRuby com tamanhos retidos enormes.
Isso indicou a biblioteca como uma possível fonte do problema.
Claro, este palpite pode não ser preciso, nos dando uma oportunidade fascinante para profile (ou ler documentação). De qualquer forma, mudar uma dependência do JRuby por uma implementação simples do Kotlin provavelmente aceleraria as coisas. Portanto, decidi pedir ao Junie para reescrever a implementação usando um analisador personalizado.
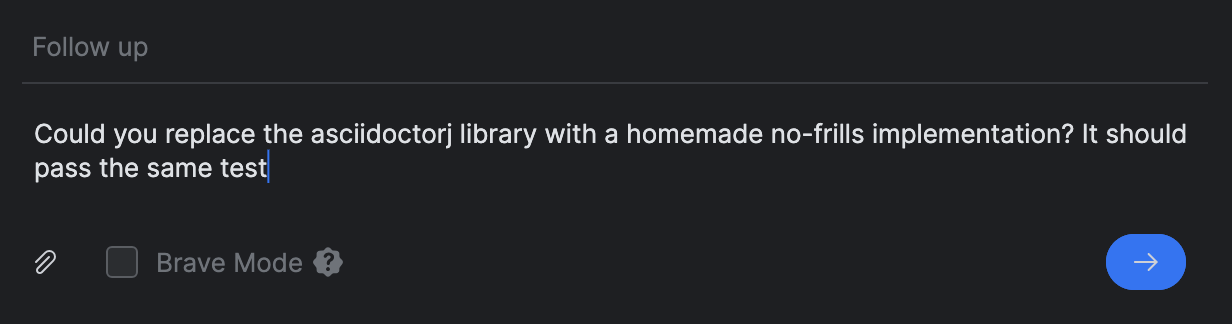
Em vez de iniciar uma nova tarefa, usei o prompt Follow up para isso:
Resultados
Junie revisou a implementação conforme solicitado. Embora eu não esteja muito familiarizado com o formato AsciiDoc, a análise parece ser em grande parte correta à primeira vista. Há espaço para melhoria na análise do preâmbulo, e provavelmente em algo mais, mas faz o seu trabalho.
Executando o Localizador de Duplicatas atualizado no próprio manual do AsciiDoctor, detectou-se algumas duplicatas! A análise demorou 350 milissegundos no meu laptop:
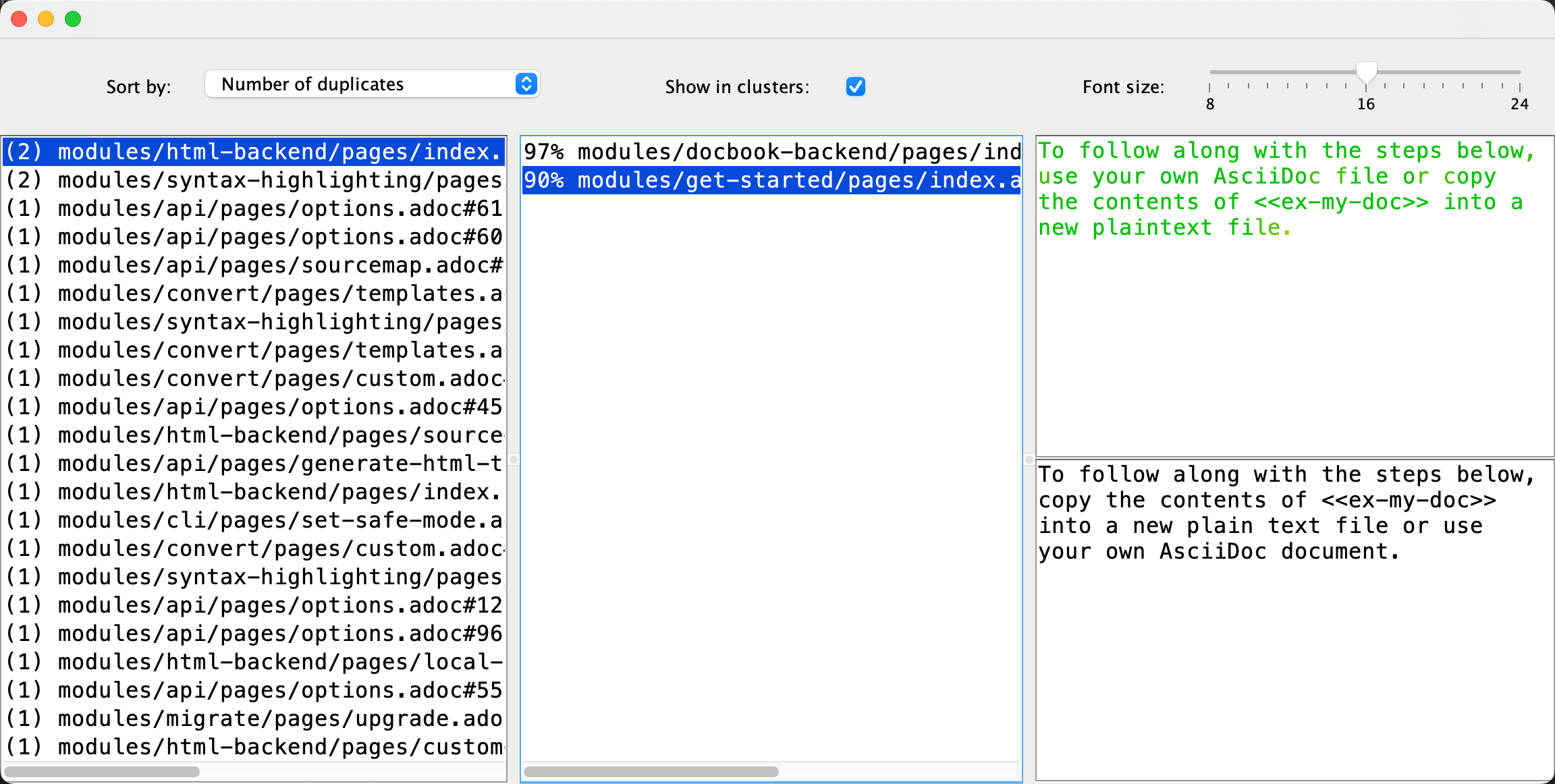
O projeto com as mudanças está no meu GitHub. Para experimentar a nova versão do aplicativo, você pode encontrar instruções e o link de download na página do Localizador de Duplicatas. No geral, a implementação pode não ser perfeita, e definitivamente requer uma verificação mais detalhada, mas ainda assim estou muito impressionado com o que se pode realizar em 5 minutos nos dias de hoje.
Se você quiser experimentar o Junie, pode se inscrever para o EAP aqui.