Detecteur de Doublons pour Texte
Autres langues : English Español Deutsch 日本語 한국어 Português 中文

Quiconque a travaille sur de la documentation technique dans une grande equipe connait certainement le probleme de la duplication de contenu. Meme avec les meilleurs outils et pratiques a portee de main, la duplication est fondamentalement difficile a surmonter.

Au fur et a mesure que le projet grandit, du contenu duplique commencera a apparaitre. C’est particulierement vrai pour les grands projets incluant de nombreux produits ou fonctionnalites similaires.
<p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p><TroubleshootingNote/><p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>
<!-- same meaning, slightly different wording-->
<p>
In case of problems, consult the troubleshooting guide
or contact support
</p>L’idee qui preconise contre la duplication est communement connue sous le nom de Principe DRY. Bien qu’il soit principalement associe a la programmation, la meme propriete est tres appreciee dans la documentation.
Presentation du projet
Les outils d’edition modernes ont generalement des fonctionnalites de reutilisation de contenu, ce qui rend les contraintes techniques moins preoccupantes. Le vrai probleme, en revanche, reside dans la detection des doublons. Avant d’extraire quelque chose vers un fragment reutilisable, vous devez savoir quoi extraire.
Si vous etes programmeur, votre IDE peut mettre en evidence le code duplique pour vous :
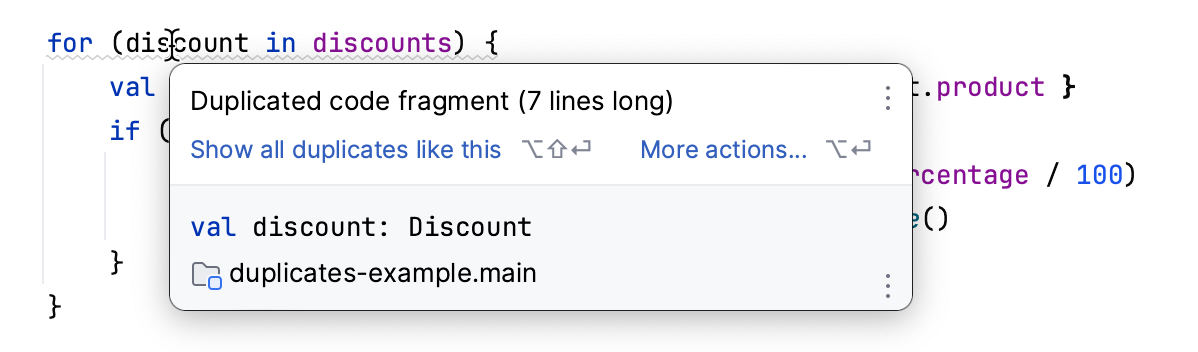
Malheureusement, la meme fonctionnalite n’est pas adaptee a la documentation, car elle repose sur la comparaison d’arbres syntaxiques abstraits (AST). Cette approche ne fonctionne pas bien avec le texte.
L’un de mes projets en cours est d’implementer un detecteur de doublons pour la documentation. L’outil sera capable de trouver rapidement des correspondances non exactes, ou floues, telles que l’exemple mauvais ci-dessus.
Statut actuel
Au moment ou j’ecris ces lignes, le projet est en cours de developpement, mais il existe deja un prototype fonctionnel :
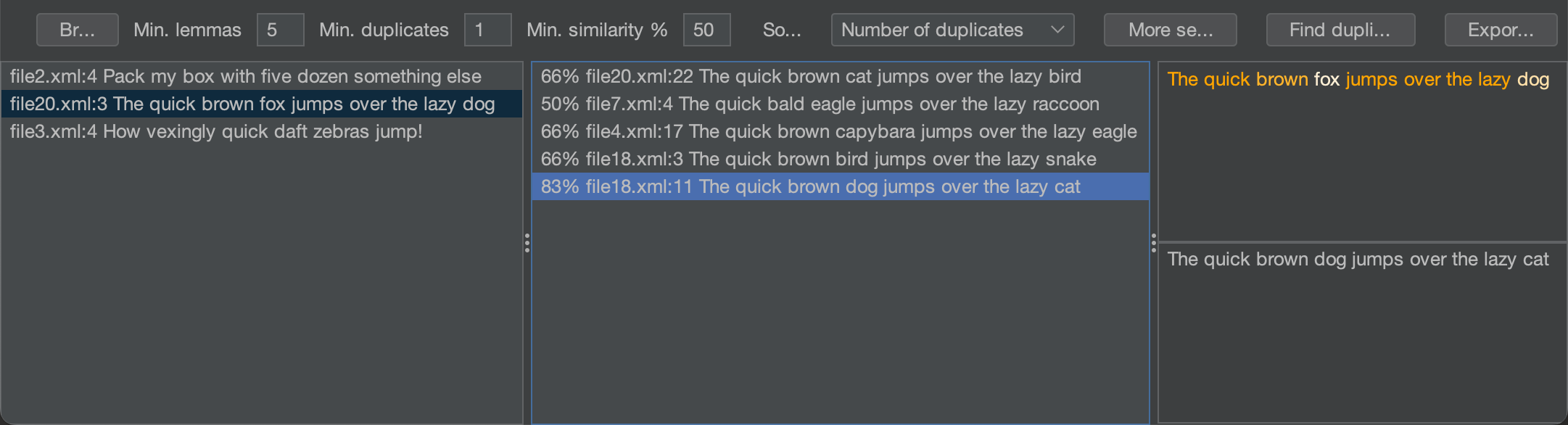
L’algorithme prend moins de 30 secondes pour analyser un projet avec ~6000 fichiers sources sur mon MBP M1, et je prevois de l’ameliorer pour mettre instantanement en evidence les doublons pendant que vous tapez dans l’editeur.
Le prototype a deja aide moi et mes collegues a trouver beaucoup de doublons dans des projets reels, donc je suis assez enthousiaste quant aux resultats et aux ameliorations futures.
Et ensuite
Dans les prochains articles, je detaillerai l’algorithme etape par etape et effectuerai des benchmarks pour evaluer ses performances. Si vous aimez la programmation, vous etes invite a coder en parallele.
Alternativement, vous pouvez suivre les progres et utiliser le livrable final lorsque le projet sera termine. Une fois termine, cette fonctionnalite sera disponible dans Writerside, un excellent outil d’edition cree par mes collegues.
J’espere que la description du projet vous parle, et que vous trouverez le tutoriel utile.
A bientot dans les prochains articles !