Detecteur de Doublons pour Texte : Exigences
Autres langues : English Español Deutsch 日本語 한국어 Português 中文

Cela fait un moment depuis que j’ai publie l’introduction au projet de detecteur de doublons, il semble donc qu’il soit grand temps de fournir quelques avancees a ce sujet. Avant de commencer a ecrire le code du programme, il est logique d’etablir d’abord les exigences. Une bonne facon de le faire est d’ecrire des tests. Non seulement les tests nous aideront a developper plus rapidement, mais ils garantiront egalement que le code respecte les specifications.

Exigences
Dans cette section, j’ai formule mon idee des fonctionnalites principales du detecteur de doublons. Celles-ci fonctionnent bien pour mes applications. Cependant, comme chaque projet peut avoir des besoins differents, je serais heureux d’entendre et d’implementer vos idees.
Detection des correspondances exactes et floues
L’outil de detection de doublons doit etre capable de trouver a la fois des correspondances exactes et floues avec une granularite jusqu’aux symboles individuels. Par exemple, il devrait identifier les textes suivants comme similaires :
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.De plus, dans le cas de doublons flous, le degre de similarite devrait etre mesurable. Cela nous permettrait d’evaluer rapidement les paires de doublons et de les trier selon leur degre de ressemblance.
Agnostique au langage
Compte tenu de la multitude de langages cibles potentiels, il serait agreable d’en supporter autant que possible. Certaines approches pourraient necessiter une maintenance separee pour chaque langue ajoutee, ce qui n’est pas du tout evolutif et necessite beaucoup de ressources. Idealement, l’outil devrait utiliser un algorithme heuristique ou agnostique au langage pour la compatibilite avec n’importe quel langage courant.
Configurable
Les criteres d’identification des doublons devraient etre ajustables, avec des parametres du type :
- la longueur des fragments de texte analyses
- le nombre de doublons
- le degre de similarite
Generalement, plus une section est longue et frequemment repetee, plus il est benefique de la dedupliquer. Cependant, cela depend en fin de compte de l’application particuliere, il serait donc agreable d’avoir le controle sur ces seuils.
Definitions
Avec les exigences de base etablies, il est temps de mettre en place les definitions de code. A ce stade, nous aurons besoin de :
- l’unite de base de texte qui representera les doublons potentiels
- l’interface du detecteur de doublons
Le code de ce chapitre n’a pas besoin d’etre exhaustif et de prevoir tous les cas d’utilisation futurs - nous pouvons toujours revenir pour des ajustements.
Chunk
En ce qui concerne une unite de texte, quels details sont importants pour nous ? Pour nos besoins, je m’en tiendrais au texte qu’un fragment contient, au chemin vers son fichier conteneur, a son numero de ligne, et au type de l’element - au cas ou la source n’est pas du texte brut :
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)Cette definition ne prend pas en compte certaines nuances. Par exemple, nous pourrions omettre le
champ content .
Cela nous economiserait de la RAM, mais le compromis sera la vitesse d’acces au contenu de l’element,
car alors le programme devra le lire depuis le disque a chaque fois au lieu d’une seule fois.
Nous ne cherchons pas la performance pour l’instant, donc un choix potentiellement sous-optimal est acceptable.
Interface
Nous n’avons pas encore d’implementation, nous allons donc programmer contre une interface. L’interface definit ce que notre fonction doit prendre en entree et ce qu’elle doit retourner en sortie, en faisant abstraction des details internes de la fonction. Cela cree effectivement un contrat, nous permettant d’ecrire des tests des maintenant, sans coder l’algorithme reel. A l’avenir, l’interface rendra egalement les implementations alternatives compatibles avec les tests existants et le code client.
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}Voici la signification des parametres que l’interface accepte :
-
root- le dossier avec le contenu a analyser -
minSimilarity- le pourcentage minimum de similarite pour que deux objetsChunksoient consideres comme des doublons -
minLength- longueur minimale decontentpour qu’unChunksoit analyse -
minDuplicates- nombre minimum de doublons pour qu’un groupe de doublons soit signale -
fileExtensions- masque d’extension de fichier pour filtrer les fichiers non pertinents
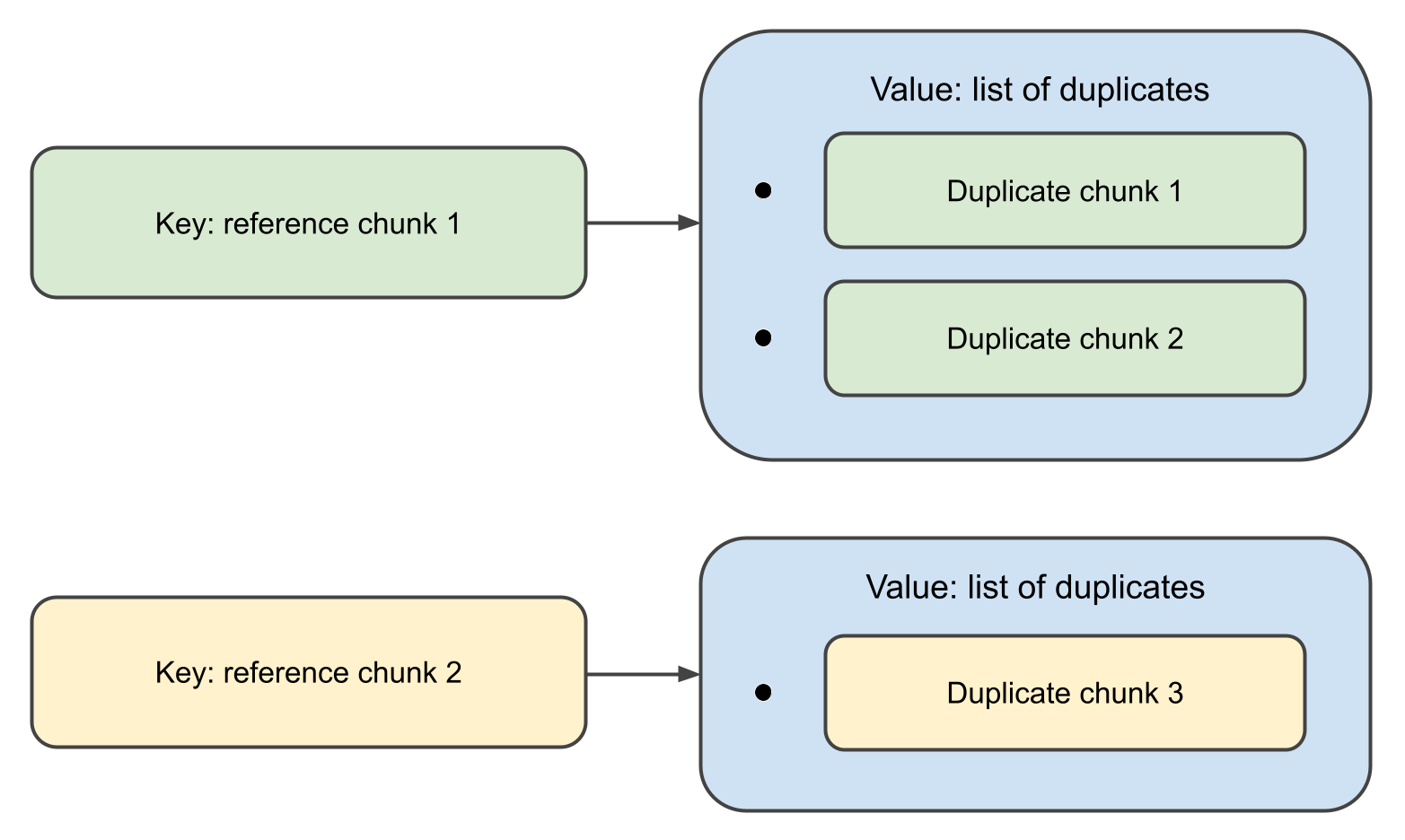
Lorsque la fonction se termine, elle retournera une map,
ou les cles sont des objets Chunk , et les valeurs associees sont des listes de leurs doublons.
En fait, la definition ci-dessus est inutilement verbeuse. Introduire une interface juste pour une seule fonction et quelques appelants, c’est trop. Kotlin a une maniere elegante de gerer cela avec les fonctions de premiere classe :
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()Cette declaration signifie que le detecteur de doublons est une fonction qui prend
Path, DuplicateFinderOptions et renvoie
Map<Chunk, List<Chunk>> ,
et que la fonction elle-meme n’est pas encore implementee.
Ce n’est peut-etre pas le meilleur style pour les grands projets, mais dans les plus petits comme le notre,
cela fonctionne tres bien.
Donnees de test
Puisque le detecteur de doublons est cense fonctionner avec des donnees textuelles, les tests auront aussi besoin de textes a analyser. Cela signifie que nous devons preparer quelques exemples contenant des doublons flous. Commencons par les doublons :
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes."L’idee derriere FUZZY_MATCH_TEMPLATE
est que nous l’utiliserons pour produire programmatiquement les correspondances floues reelles :
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)Ensuite, nous genererons un texte compose de mots anglais aleatoires :
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}Enfin, nous injecterons aleatoirement EXACT_MATCH
et fuzzyMatches dans le texte genere :
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}Tests
Comme deja mentionne, l’objectif principal des tests a ce stade est de definir les specifications, donc ne perdons pas trop de temps a perfectionner la suite de tests. Au lieu de cela, nous ecrirons juste assez pour nous assurer que le futur code respecte les exigences.
Voici le code de la classe de test :
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }Prochaines etapes
Nous avons etabli les exigences en definissant l’interface et en ecrivant les tests. Dans le prochain article de la serie, nous implementerons l’algorithme reel et verrons comment il performe. A bientot !