Localiser des Applications avec l'IA
Autres langues : English Español Deutsch 日本語 한국어 Português 中文
Que vous envisagiez de localiser votre projet ou que vous appreniez simplement comment le faire, l’IA peut être un bon point de départ. Elle offre un point d’entrée économique pour les expériences et les automatisations.
Dans cet article, nous allons parcourir une telle expérience. Nous allons :
- choisir une application open-source
- examiner et implémenter les prérequis
- automatiser l’étape de traduction en utilisant l’IA

Si vous n’avez jamais fait de localisation et souhaitez apprendre, c’est peut-être une bonne idée de commencer ici. À part quelques détails techniques, l’approche est largement universelle, et vous pouvez l’appliquer dans d’autres types de projets.
Si vous êtes déjà familier avec les bases et souhaitez simplement voir l’IA en action, vous pouvez passer directement à Traduire les textes ou cloner mon fork pour parcourir les commits et évaluer les résultats.
Obtenir le projet
Créer une application juste pour une expérience de localisation serait excessif, alors faisons un fork d’un projet open-source. J’ai choisi Spring Petclinic, une application web exemple utilisée pour présenter le framework Spring pour Java.
gh repo fork https://github.com/spring-projects/spring-petclinic --clone=trueSi vous n’avez jamais utilisé Spring auparavant, certains extraits de code peuvent ne pas vous sembler familiers, mais, comme je l’ai déjà mentionné, cette discussion est agnostique en termes de technologie. Les étapes sont à peu près les mêmes quel que soit le langage et le framework.
Internationalisation
Avant qu’une application puisse être localisée, elle doit être internationalisée.
L’internationalisation (aussi appelée i18n) est le processus d’adaptation d’un logiciel pour supporter différentes langues. Elle commence généralement par l’externalisation des chaînes d’interface utilisateur vers des fichiers spéciaux, communément appelés bundles de ressources.
Les bundles de ressources contiennent les valeurs textuelles pour différentes langues :
en.json:
{
"greeting": "Hello!",
"farewell": "Goodbye!"
}es.json:
{
"greeting": "¡Hola!",
"farewell": "¡Adiós!"
}Pour que ces valeurs arrivent à l’interface utilisateur, l’interface doit être explicitement programmée pour utiliser ces fichiers.
Cela implique généralement une bibliothèque d’internationalisation ou une fonctionnalité intégrée au langage, dont le but est de remplacer les textes de l’interface par les valeurs correctes pour une locale donnée. Des exemples de telles bibliothèques incluent i18next (JavaScript), Babel (Python), et go-i18n (Go).
Java supporte l’internationalisation nativement, donc nous n’avons pas besoin d’ajouter de dépendances supplémentaires au projet.
Examiner les sources
Java utilise des fichiers avec l’extension .properties pour stocker les chaînes localisées pour l’interface utilisateur.
Heureusement, il y en a déjà plusieurs dans le projet. Par exemple, voici ce que nous avons pour l’anglais et l’espagnol :
welcome=Welcome
required=is required
notFound=has not been found
duplicate=is already in use
nonNumeric=must be all numeric
duplicateFormSubmission=Duplicate form submission is not allowed
typeMismatch.date=invalid date
typeMismatch.birthDate=invalid datewelcome=Bienvenido
required=Es requerido
notFound=No ha sido encontrado
duplicate=Ya se encuentra en uso
nonNumeric=Sólo debe contener numeros
duplicateFormSubmission=No se permite el envío de formularios duplicados
typeMismatch.date=Fecha invalida
typeMismatch.birthDate=Fecha invalidaExternaliser les chaînes d’interface utilisateur n’est pas quelque chose que tous les projets font universellement. Certains projets peuvent avoir ces textes directement codés en dur dans la logique de l’application.

Externaliser les textes d’interface utilisateur est une bonne pratique avec des avantages au-delà de l’internationalisation. Cela rend le code plus facile à maintenir et favorise la cohérence dans les messages d’interface. Si vous démarrez un projet, envisagez d’implémenter l’i18n le plus tôt possible.
Test de fonctionnement
Ajoutons un moyen de changer la locale via les paramètres d’URL. Cela nous permettra de tester si tout est entièrement externalisé et traduit dans au moins une langue.
Pour y parvenir, nous ajoutons la classe suivante pour gérer le paramètre de locale :
import java.util.Locale;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public LocaleResolver localeResolver() {
SessionLocaleResolver slr = new SessionLocaleResolver();
slr.setDefaultLocale(Locale.US);
return slr;
}
@Bean
public LocaleChangeInterceptor localeChangeInterceptor() {
LocaleChangeInterceptor lci = new LocaleChangeInterceptor();
lci.setParamName("lang");
return lci;
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(localeChangeInterceptor());
}
}Maintenant que nous pouvons tester différentes locales, nous lançons le serveur et comparons la page d’accueil pour plusieurs paramètres de locale :
- http://localhost:8080 – locale par défaut
- http://localhost:8080/?lang=es – Espagnol
- http://localhost:8080/?lang=ko – Coréen
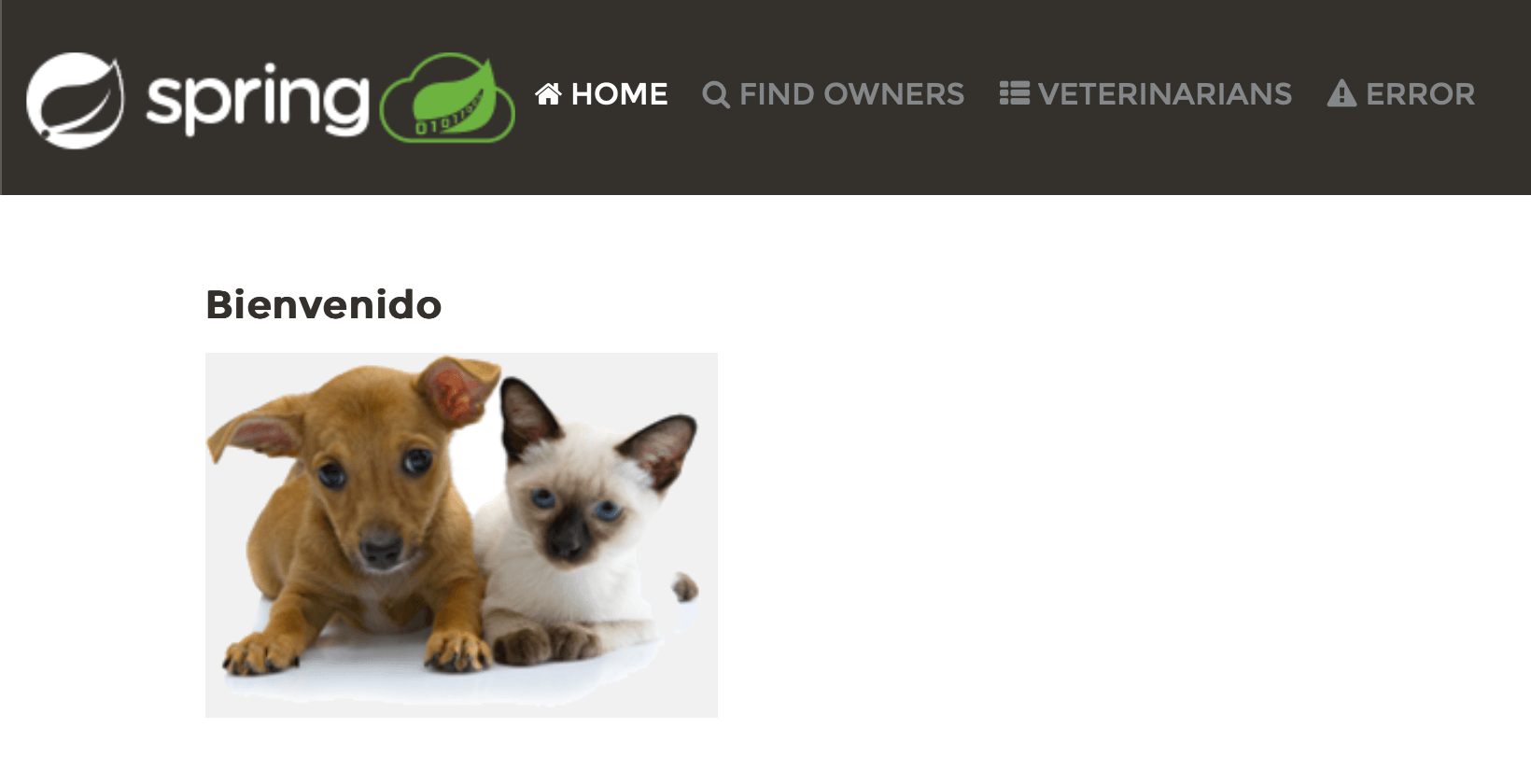
Changer la locale se reflète dans l’interface, ce qui est une bonne nouvelle. Il apparaît cependant que le changement de locale n’a affecté qu’une partie des textes. Pour l’espagnol, Welcome est devenu Bienvenido, mais les liens dans l’en-tête sont restés les mêmes, et les autres pages sont toujours en anglais. Cela signifie que nous avons du travail à faire.
Modifier les templates
Le projet Spring Petclinic génère des pages en utilisant des templates Thymeleaf, alors examinons les fichiers de templates.
En effet, certains textes sont codés en dur, donc nous devons modifier le code pour référencer les bundles de ressources à la place.
Heureusement, Thymeleaf a un bon support pour les fichiers Java .properties ,
donc nous pouvons incorporer des références aux clés de bundle de ressources correspondantes directement dans le template :
<h2>Find Owners</h2><h2 th:text='#{heading.find.owners}'>Find Owners</h2>heading.find.owners=Find OwnersLe texte précédemment codé en dur est toujours là, mais il sert maintenant de valeur de repli, qui ne sera utilisée que s’il y a une erreur lors de la récupération d’un message localisé approprié.
Le reste des textes est externalisé de manière similaire ; cependant, il y a plusieurs endroits qui nécessitent une attention particulière. Par exemple, certains avertissements proviennent du moteur de validation et doivent être spécifiés en utilisant des paramètres d’annotation Java :
@Column(name = "first_name")
@NotBlank
private String firstName;@Column(name = "first_name")
@NotBlank(message = "{field.validation.notblank}")
private String firstName;À quelques endroits, la logique doit être modifiée :
<h2>
<th:block th:if="${pet['new']}">New </th:block>Pet
</h2>Dans l’exemple ci-dessus, le template utilise une condition. Si l’attribut new est présent, New est ajouté au texte de l’interface.
Par conséquent, le texte résultant est soit New Pet soit Pet selon la présence de l’attribut.
Cela peut casser la localisation pour certaines locales, à cause de l’accord
entre le nom et l’adjectif. Par exemple, en espagnol, l’adjectif serait
Nuevo ou Nueva
selon le genre du nom, et la logique existante ne prend pas en compte cette distinction.
Une solution possible à cette situation est de rendre la logique encore plus sophistiquée. C’est généralement une bonne idée d’éviter la logique compliquée chaque fois que possible, j’ai donc opté pour le découplage des branches à la place :
<h2>
<th:block th:if="${pet['new']}" th:text="#{pet.new}">New Pet</th:block>
<th:block th:unless="${pet['new']}" th:text="#{pet.update}">Pet</th:block>
</h2>Des branches séparées simplifieront également le processus de traduction et la maintenance future du code.
Le formulaire New Pet a aussi une astuce. Sa liste déroulante Type est créée en passant la collection de types d’animaux au template selectField.html :
<input th:replace="~{fragments/selectField :: select (#{pet.type}, 'type', ${types})}" />Contrairement aux autres textes d’interface, les types d’animaux font partie du modèle de données de l’application. Ils proviennent d’une base de données au moment de l’exécution. La nature dynamique de ces données nous empêche d’extraire directement les textes vers un bundle de propriétés.
Il y a encore plusieurs façons de gérer cela. Une façon est de construire dynamiquement la clé du bundle de propriétés dans le template :
<option th:each="item : ${items}"
th:value="${item}"
th:text="${item}">dog</option><option th:each="item : ${items}"
th:value="${item}"
th:text="#{'pettype.' + ${item}}">dog</option>Dans cette approche, plutôt que de rendre directement cat dans l’interface, nous le préfixons avec pettype. , ce qui donne
pettype.cat . Nous utilisons ensuite cette chaîne comme clé pour récupérer le texte d’interface localisé :
pettype.bird=bird
pettype.cat=cat
pettype.dog=dogpettype.bird=pájaro
pettype.cat=gato
pettype.dog=perro
Vous avez peut-être remarqué que nous venons de modifier le template d’un composant réutilisable. Puisque les composants réutilisables sont destinés à servir plusieurs clients, il n’est pas correct d’y apporter une logique client.
Dans ce cas particulier, le composant de liste déroulante devient lié aux types d’animaux, ce qui est problématique pour quiconque veut l’utiliser pour autre chose.
Ce défaut était là depuis le début - voir dog comme texte par défaut des options.
Nous avons juste propagé ce défaut plus loin.
Cela ne devrait pas être fait dans de vrais projets et nécessite une refactorisation.
Bien sûr, il y a plus de code de projet à internationaliser ; cependant, le reste s’aligne principalement avec les exemples ci-dessus. Pour un examen complet de tous mes changements, vous êtes invité à examiner les commits dans mon fork.
Ajouter les clés manquantes
Après avoir remplacé tous les textes d’interface par des références aux clés de bundle de propriétés, nous devons nous assurer d’introduire toutes ces nouvelles clés. Nous n’avons pas besoin de traduire quoi que ce soit à ce stade, juste ajouter les clés et les textes originaux au fichier messages.properties .
IntelliJ IDEA a un bon support Thymeleaf. Il détecte si un template référence une propriété manquante, donc vous pouvez repérer les manquantes sans beaucoup de vérification manuelle :
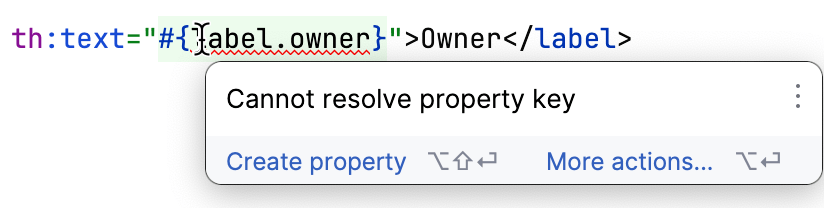
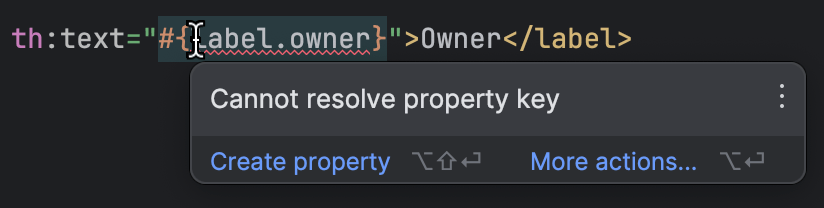
Avec toutes les préparations terminées, nous arrivons à la partie la plus intéressante du travail. Nous avons toutes les clés, et nous avons toutes les valeurs pour l’anglais. Où obtenons-nous les valeurs pour les autres langues ?
Traduire les textes
Pour traduire les textes, nous allons créer un script qui utilise un service de traduction externe. Il existe de nombreux services de traduction disponibles, et de nombreuses façons d’écrire un tel script. J’ai fait les choix suivants pour l’implémentation :
- Python comme langage de programmation, parce qu’il vous permet de programmer des petites tâches vraiment rapidement
- DeepL comme service de traduction. À l’origine, je prévoyais d’utiliser GPT3.5 Turbo d’OpenAI, mais comme ce n’est pas strictement un modèle de traduction, il nécessite un effort supplémentaire pour configurer le prompt. De plus, les résultats tendent à être moins stables, j’ai donc choisi un service de traduction dédié qui m’est venu à l’esprit en premier
Je n’ai pas fait de recherche extensive, donc ces choix sont quelque peu arbitraires. N’hésitez pas à expérimenter et découvrir ce qui vous convient le mieux.
Si vous décidez d’utiliser le script ci-dessous, vous devez créer un compte chez DeepL
et passer votre clé API personnelle au script via la variable d’environnement DEEPL_KEY
Voici le script :
import os
import requests
import json
deepl_key = os.getenv('DEEPL_KEY')
properties_directory = "../src/main/resources/messages/"
def extract_properties(text):
properties = {}
for line in text:
line = line.strip()
if line and not line.startswith('#') and '=' in line:
key_value = line.split('=')
key = key_value[0].strip()
value = key_value[1].strip()
if key and value:
properties[key] = value
return properties
def missing_properties(properties_file, properties_checklist):
with open(properties_file, 'r') as f:
text = f.readlines()
present_properties = extract_properties(text)
missing = {k: v for k, v in properties_checklist.items() if k not in present_properties.keys()}
return missing
def translate_property(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'DeepL-Auth-Key {deepl_key}',
'User-Agent': 'LocalizationScript/1.0'
}
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()["translations"][0]["text"]
def populate_properties(file_path, properties_checklist, target_lang):
with open(file_path, 'a+') as file:
properties_to_translate = missing_properties(file_path, properties_checklist)
for key, value in properties_to_translate.items():
new_value = translate_property(value, target_lang)
property_line = f"{key}={new_value}\n"
print(property_line)
file.write(property_line)
with open(properties_directory + 'messages.properties') as base_properties_file:
base_properties = extract_properties(base_properties_file)
languages = [
# configure languages here
"nl", "es", "fr", "de", "it", "pt", "ru", "ja", "zh", "fi"
]
for language in languages:
populate_properties(properties_directory + f"messages_{language}.properties", base_properties, language)
Le script extrait les clés du bundle de propriétés par défaut ( messages.properties ) et cherche leurs traductions dans les bundles spécifiques à la locale. S’il trouve qu’une certaine clé manque de traduction, le script demandera la traduction à l’API DeepL et l’ajoutera au bundle de propriétés.
J’ai spécifié 10 langues cibles, mais vous pouvez modifier la liste ou ajouter vos langues préférées, tant que DeepL les supporte.
Le script peut être encore optimisé pour envoyer les textes à traduire par lots de 50. Je ne l’ai pas fait ici pour garder les choses simples.
Plus tard, j’ai mis à jour le script pour utiliser un LLM avec sortie structurée. Vous pouvez consulter les résultats ici.
Exécuter le script
Exécuter le script sur 10 langues m’a pris environ 5 minutes. Le tableau de bord d’utilisation montre 8348 caractères, ce qui aurait coûté 0,16€ si nous étions sur un plan payant.
En résultat, les fichiers suivants apparaissent :
- messages_fi.properties
- messages_fr.properties
- messages_it.properties
- messages_ja.properties
- messages_nl.properties
- messages_pt.properties
- messages_ru.properties
- messages_zh.properties
De plus, les propriétés manquantes sont ajoutées à :
- messages_de.properties
- messages_es.properties
Mais qu’en est-il des traductions réelles ? Pouvons-nous les voir déjà ?
Vérifier les résultats
Relançons l’application et testons-la en utilisant différentes valeurs de paramètre lang . Par exemple :
- http://localhost:8080/?lang=es
- http://localhost:8080/?lang=nl
- http://localhost:8080/?lang=zh
- http://localhost:8080/?lang=fr
Personnellement, je trouve très satisfaisant de voir chaque page correctement localisée. Nous avons fourni des efforts, et maintenant ça porte ses fruits :

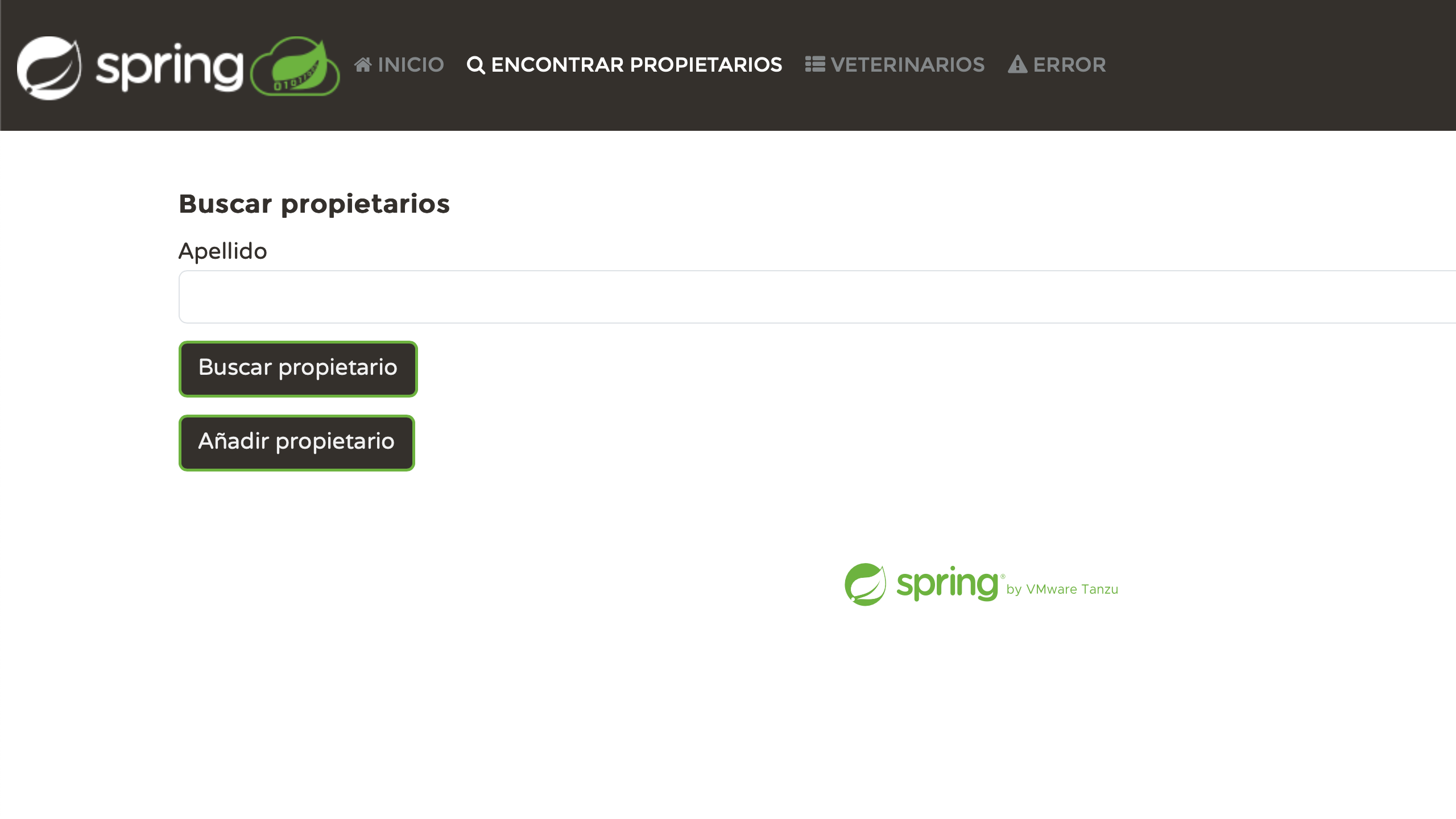
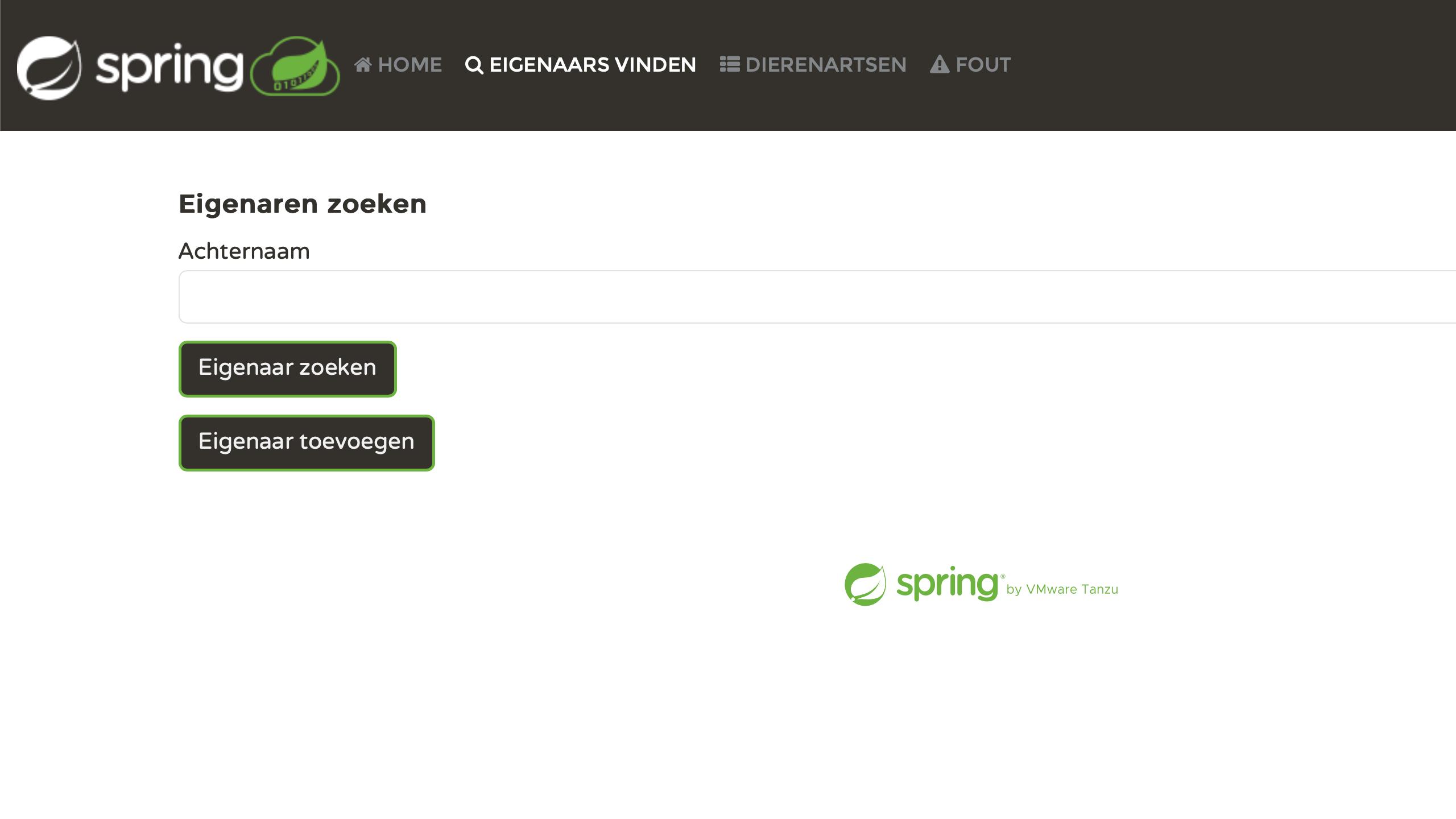

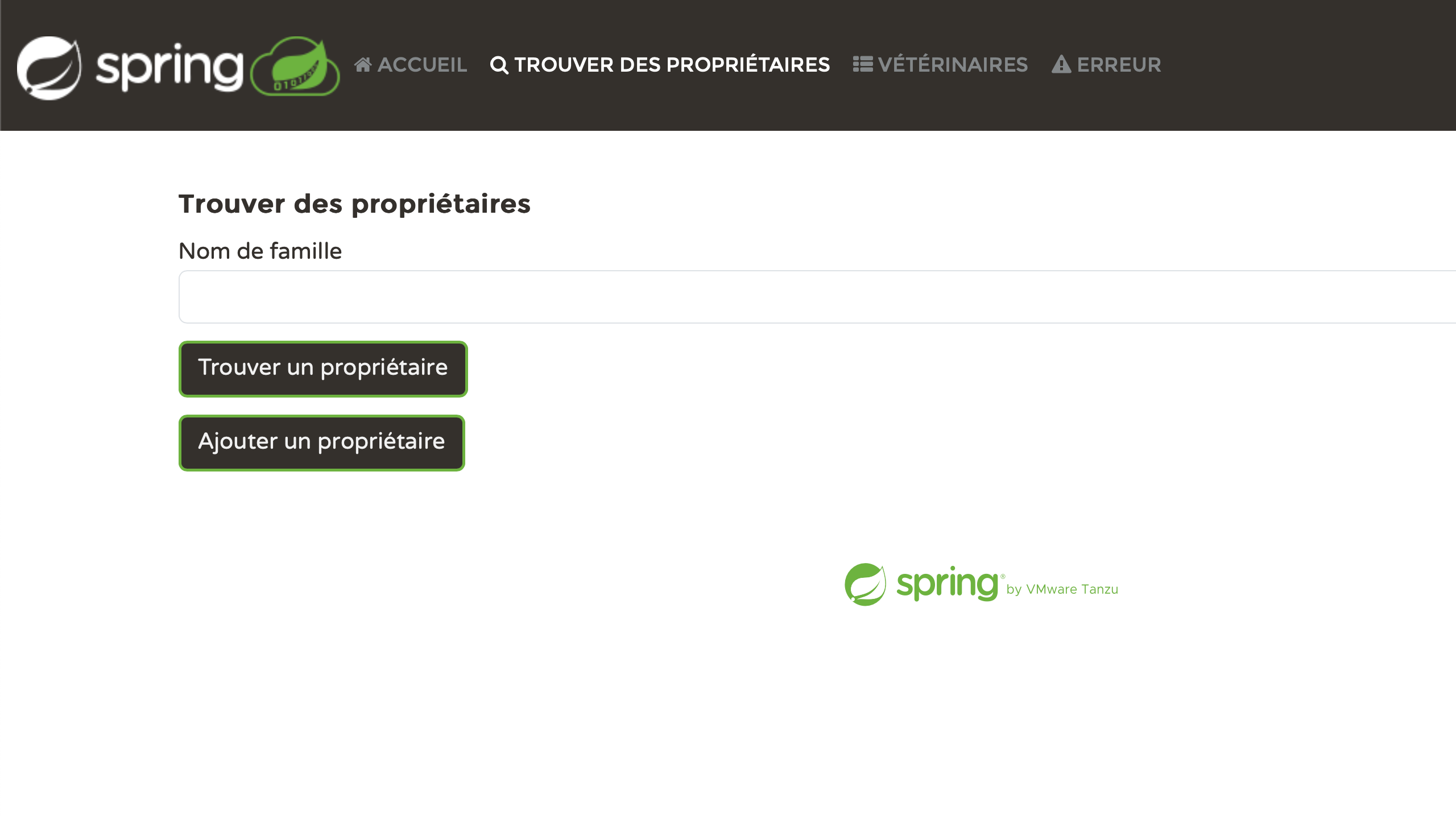
Résoudre les problèmes
Les résultats sont impressionnants. Cependant, si vous regardez de plus près, vous pouvez découvrir des erreurs qui proviennent d’un manque de contexte. Par exemple :
visit.update = Visit Visit peut être à la fois un nom et un verbe. Sans contexte supplémentaire, le service de traduction
produit une traduction incorrecte dans certaines langues.
Cela peut être résolu soit par une édition manuelle, soit en ajustant le flux de travail de traduction. Une solution possible est de fournir du contexte dans les fichiers .properties en utilisant des commentaires :
# Noun. Heading. Displayed on the page that allows the user to edit details of a veterinary visit
visit.update = VisitNous pouvons ensuite modifier le script de traduction pour analyser ces commentaires et les passer avec
le paramètre context :
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True,
'context': context
}Au fur et à mesure que nous approfondissons et considérons plus de langues, nous pourrions rencontrer plus de choses qui doivent être améliorées. C’est un processus itératif.
S’il y a une chose indispensable dans ce processus, c’est la révision et les tests. Indépendamment du fait que nous améliorions l’automatisation ou que nous éditions sa sortie, nous trouverons nécessaire de conduire un contrôle qualité et une évaluation.
Au-delà du scope
Spring Petclinic est un projet simple, mais réaliste, tout comme les problèmes que nous venons de résoudre. Bien sûr, la localisation présente beaucoup de défis qui sont hors du scope de cet article, incluant :
- adapter les templates aux règles grammaticales cibles
- formats de devise, date et nombre
- différents schémas de lecture, comme RTL
- adapter l’interface utilisateur pour des longueurs de texte variables
Chacun de ces sujets mérite un article à part entière. Si vous souhaitez en lire plus, je serai heureux de couvrir ces sujets dans des articles séparés.
Résumé
Bien, maintenant que nous avons fini de localiser notre application, il est temps de réfléchir à ce que nous avons appris :
- La localisation ne concerne pas seulement la traduction de textes - elle affecte également les ressources connexes, les sous-systèmes et les processus
- Bien que l’IA soit très efficace dans certaines étapes de localisation, la supervision humaine et les tests restent nécessaires pour obtenir les meilleurs résultats
- La qualité des traductions automatiques dépend de divers facteurs, incluant la disponibilité du contexte et, dans le cas des LLMs, un prompt correctement rédigé
J’espère que vous avez apprécié cet article, et j’aimerais avoir vos retours ! Si vous avez des questions de suivi ou souhaitez discuter de l’approche, n’hésitez pas à me contacter.
Au plaisir de vous voir dans les prochains articles !