Auto-profilage d'IntelliJ IDEA
Autres langues : English Español Deutsch 日本語 한국어 Português 中文
Tout comme l’article precedent, celui-ci va etre legerement meta. Evidemment, vous pouvez utiliser IntelliJ IDEA pour profiler un autre processus, mais saviez-vous qu’IntelliJ IDEA peut se profiler lui-meme ?

Cela peut etre utile si vous ecrivez un plugin IntelliJ IDEA et devez resoudre des problemes lies aux performances du plugin. De plus, que vous soyez auteur de plugin ou non, ce scenario peut vous interesser car la strategie de profilage que je vais couvrir n’est pas exclusive a IntelliJ IDEA - vous pouvez l’utiliser pour resoudre des goulots d’etranglement similaires dans d’autres types de projets et avec d’autres outils.
Le probleme
Dans cet article, nous allons examiner un goulot d’etranglement de performance assez interessant sur lequel je suis tombe il y a quelques annees.
En travaillant sur un projet personnel dans IntelliJ IDEA, j’ai remarque que
trouver des tests (Navigate | Test) pour des classes avec certains noms courts, comme A ,
etait etonnamment lent, prenant souvent 2 minutes ou plus.

La presence du goulot d’etranglement ne semblait pas dependre de la taille du projet -
meme dans des projets consistant en une seule classe nommee A ,
la navigation prendrait toujours tres longtemps.
Je n’ai jamais connu de delais lies a cette fonctionnalite meme dans l’enorme
monorepo d’IntelliJ IDEA, donc le ralentissement dans un projet presque vide semblait particulierement curieux.
Pourquoi cela se produisait-il ? Et, plus important encore, comment aborder des problemes similaires, si vous les rencontrez dans votre projet ?
Recreer l’environnement
J’ai originellement ecrit cet article pour un usage interne chez JetBrains, cependant, l’idee de le rendre public m’est venue seulement recemment. Heureusement, avec le temps, l’article n’a pas bien vieilli, et le probleme ne semble plus reproductible sur les versions actuelles d’IntelliJ IDEA et le materiel plus recent.
Comme je ne pouvais pas reproduire le ralentissement sur ma configuration de travail, je me suis retrouve a ressortir mon vieux portable et a installer une version anterieure d’IntelliJ IDEA dessus. Si vous voulez suivre l’investigation dans votre IDE, assurez-vous de cloner le depot IntelliJ IDEA Community Edition, car cela facilitera la navigation et le debogage pour vous.
Assurons-nous egalement d’avoir un projet vide avec la classe suivante dedans :
public class A {
public static void main(String[] args) {
System.out.println("I like tests");
}
}IntelliJ Profiler
Comme vous le savez deja, IntelliJ IDEA possede un profileur JVM integre. Vous pouvez lancer des applications avec le profileur attache. Alternativement, vous pouvez attacher le profileur a un processus deja en cours d’execution, ce que nous allons faire.
Pour cela, allez dans la fenetre d’outils Profiler et trouvez le processus correspondant la. Si vous ne voyez pas votre IDE dans la liste, assurez-vous de cocher Show Development Tools dans le menu pres de Process. Lorsque vous cliquez sur un processus, IntelliJ IDEA suggere les outils d’analyse de performance integres, qui vous permettent de :
- profiler l’utilisation CPU et les allocations memoire
- analyser le tas JVM
- capturer des dumps de threads
- surveiller la consommation de ressources en temps reel
Tous ces outils sont couverts dans la documentation, et dans cet article nous nous concentrerons specifiquement sur le profileur.
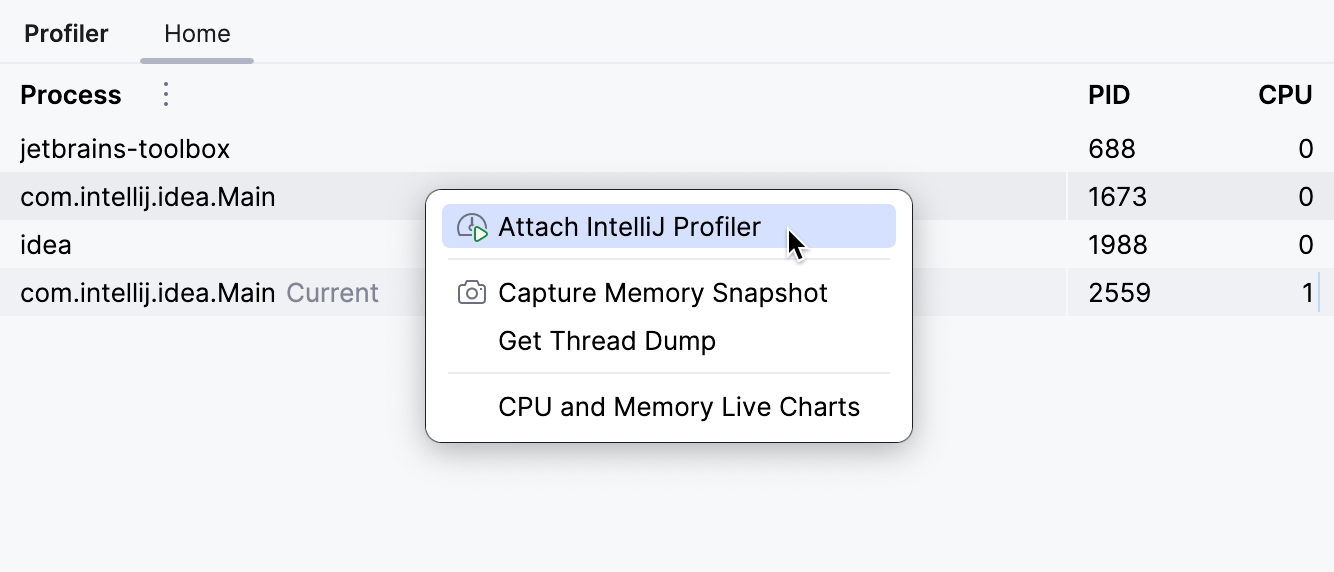
Nous devons attacher le profileur avant que le probleme ne se produise. Par exemple, si le probleme survient suite a l’appel d’une API, attachez d’abord le profileur au processus, puis reproduisez les evenements qui causent le probleme.

Idealement, nous devrions attacher le profileur juste avant de reproduire le probleme. Si votre application est occupee a faire autre chose plutot que d’attendre une entree, cette approche vous aidera a minimiser le nombre d’echantillons non pertinents.
Selon le temps que prend le code problematique a s’executer, il peut aussi etre judicieux de reproduire le probleme plusieurs fois, afin que le profileur puisse collecter plus d’echantillons pour l’analyse. Cela fera ressortir davantage le probleme dans le rapport resultant.
Lorsque vous detachez le profileur ou terminez le processus, IntelliJ IDEA ouvre automatiquement le snapshot resultant.
Analyser le rapport
Pour analyser les snapshots, vous avez plusieurs vues a votre disposition. Vous pouvez choisir d’examiner les arbres d’appels, les statistiques de methodes particulieres, la charge CPU par thread, l’activite du GC, et plus encore.
Pour le probleme en question, commencons par la vue Timeline pour voir si nous pouvons reperer quelque chose d’inhabituel :
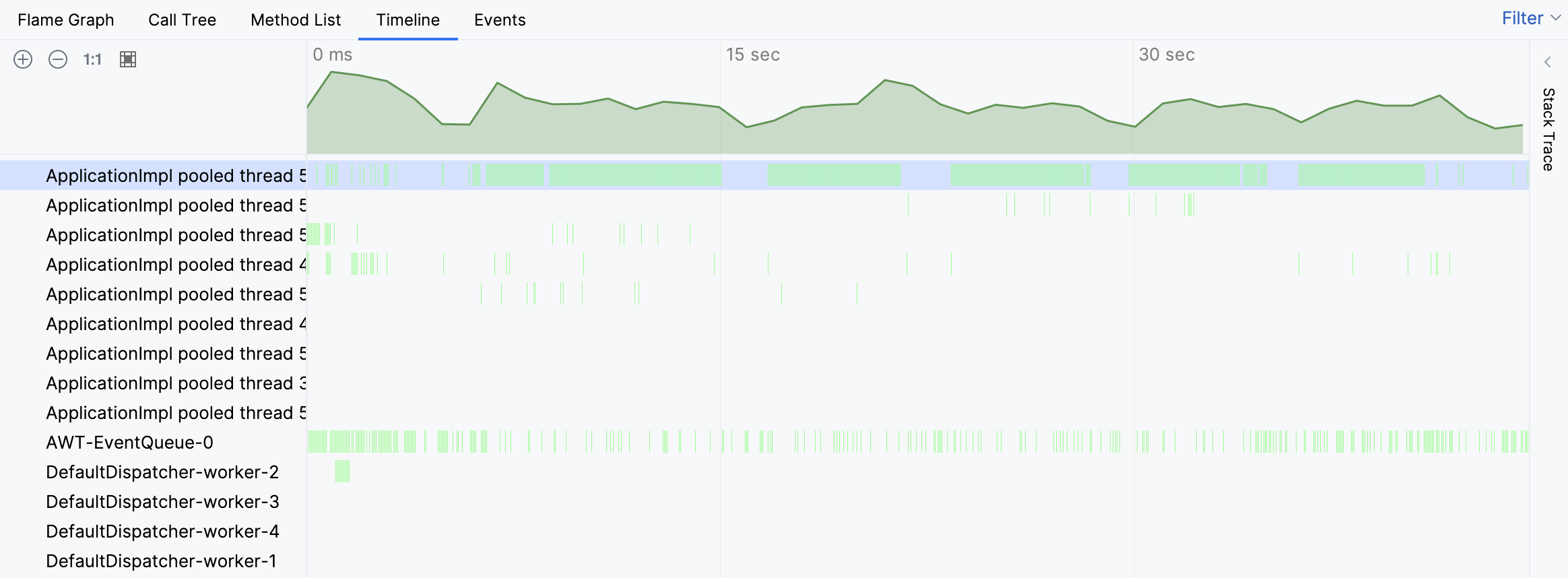
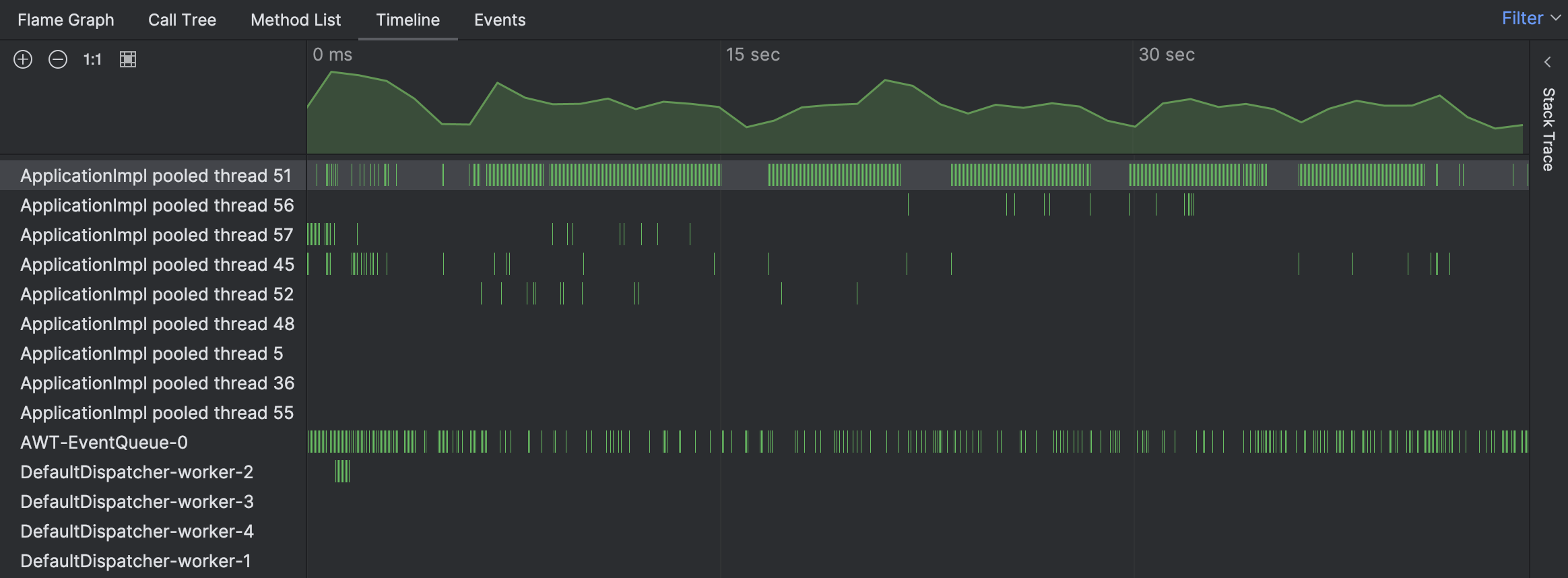
En effet, la timeline indique qu’un des threads etait extraordinairement occupe. Les barres vertes correspondent aux echantillons collectes pour un thread particulier. En cliquant sur n’importe laquelle de ces barres, nous pouvons voir la trace de pile correspondante pour l’echantillon.
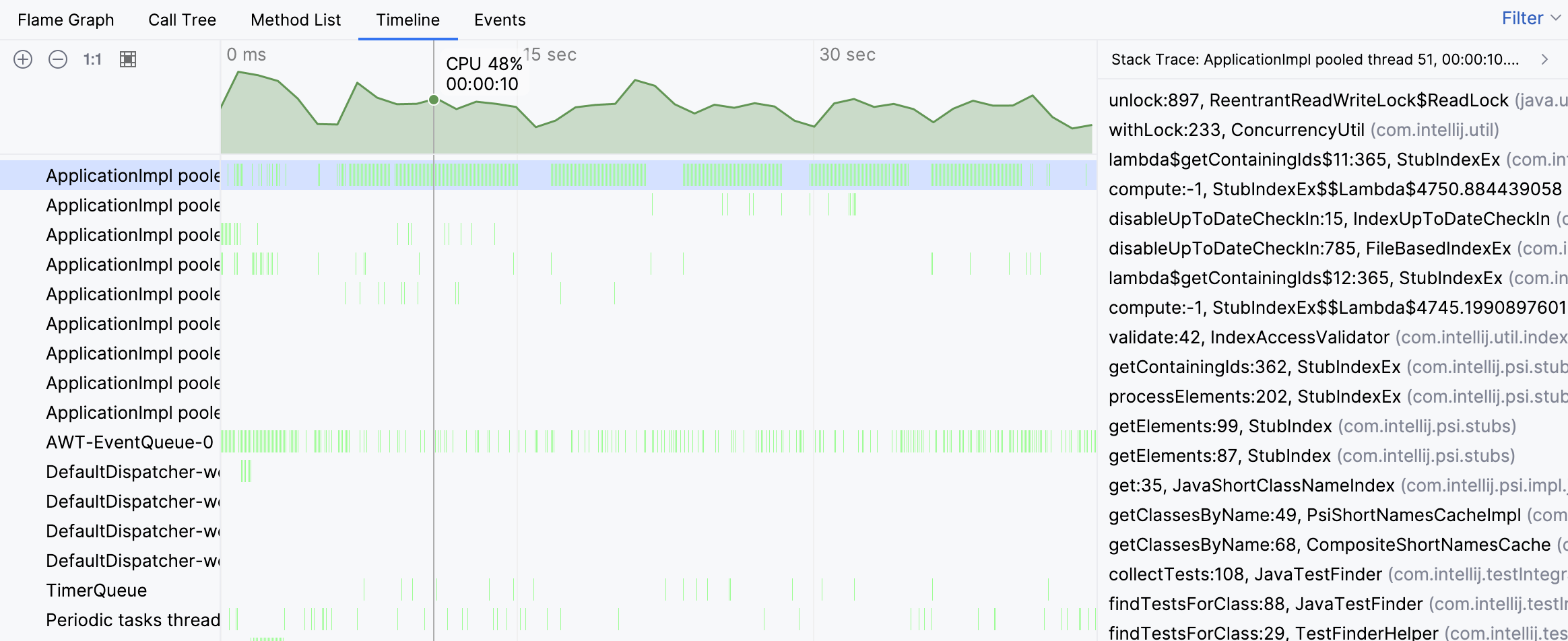
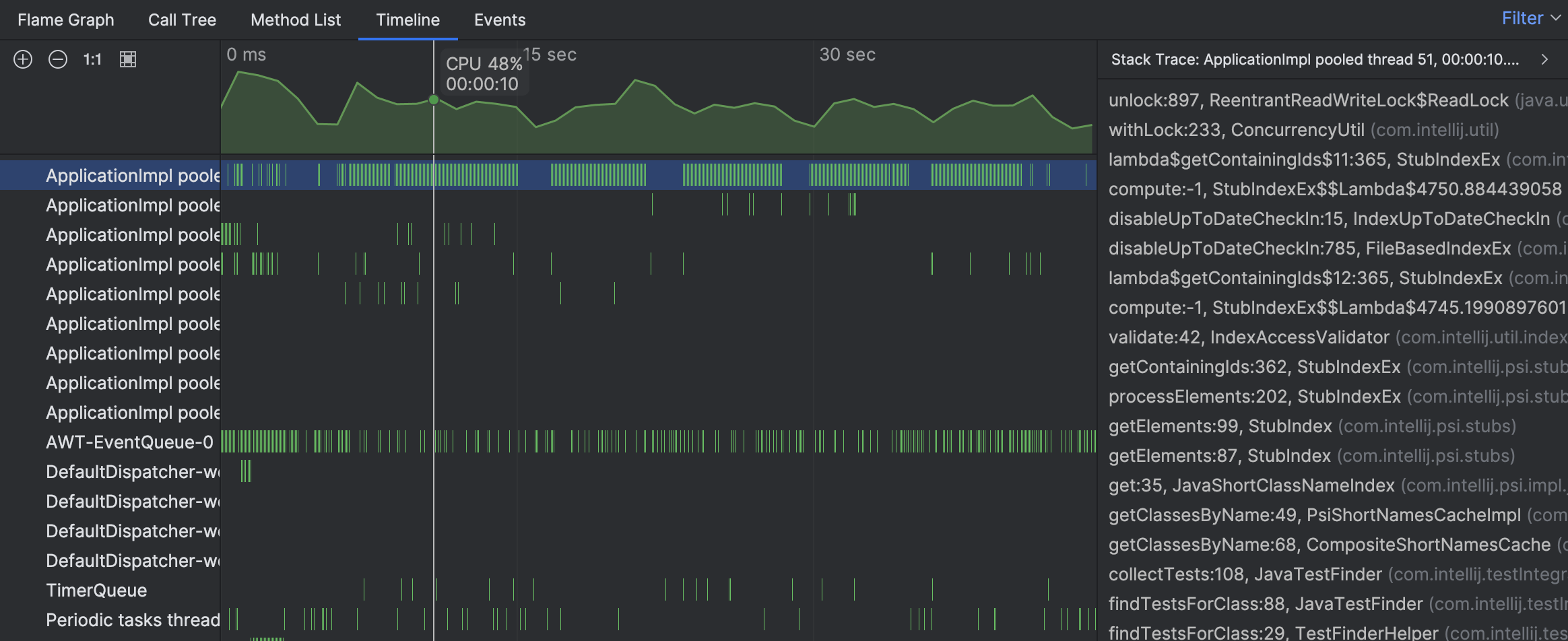
Les traces de pile des echantillons individuels suggerent que l’activite du thread est associee a la recherche de tests. Cependant, nous ne voyons toujours pas la vue d’ensemble. Naviguons vers le thread occupe sur le graphique de flammes :

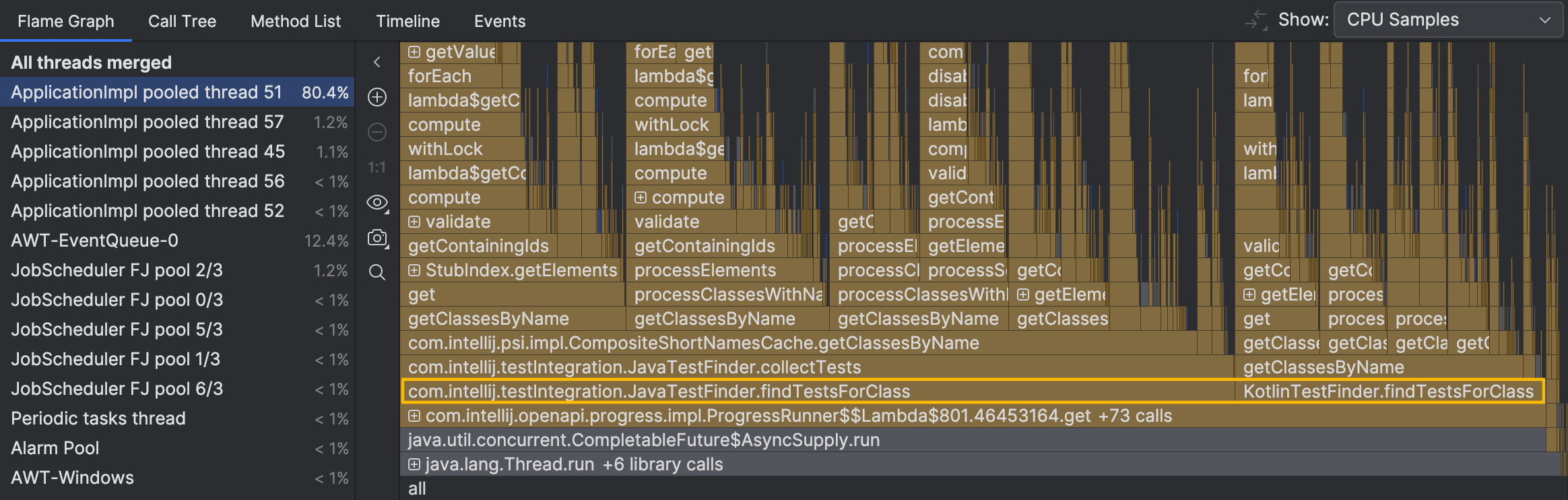
Les methodes qui pourraient nous interesser,
JavaTestFinder.findTestsForClass() et KotlinTestFinder.findTestsForClass() ,
sont tout en bas du graphique.
Nous ne prenons pas en compte les methodes repliees en dessous, car elles n’ont pas de temps propre significatif ni de branchement.
Elles controlent le flux plutot qu’elles n’effectuent des calculs intensifs.
Pour verifier si ces methodes sont effectivement liees au ralentissement,
nous pouvons profiler un cas non problematique :
rechercher des tests pour une classe avec un nom plus realiste, par exemple,
ClassWithALongerName .
Ensuite, nous verrons ce qui arrive a ces methodes en utilisant la vue de comparaison.


Le snapshot plus recent contient 93-95% moins d’echantillons
avec JavaTestFinder.findTestsForClass()
et KotlinTestFinder.findTestsForClass() .
Le temps d’execution des autres methodes ne differe pas tant que ca.
Il semble que nous allons dans la bonne direction.
La question suivante est pourquoi cela se produit. Essayons de le decouvrir avec le debogueur.
Pourquoi une telle difference ?
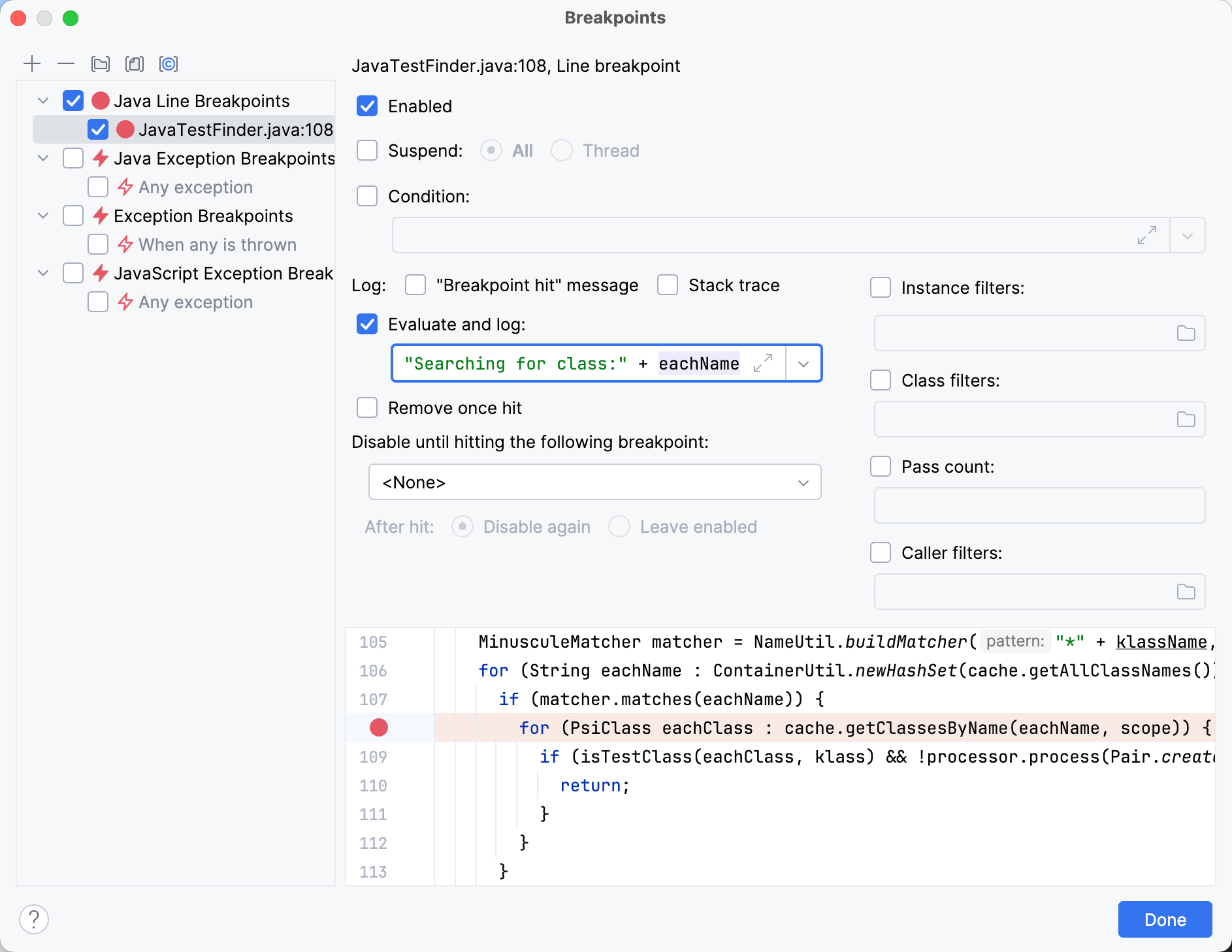
Definir un point d’arret dans findTestsForClass() et un peu
de pas a pas dans le code nous amenent au point suivant :
MinusculeMatcher matcher = NameUtil.buildMatcher("*" + klassName, NameUtil.MatchingCaseSensitivity.NONE);
for (String eachName : ContainerUtil.newHashSet(cache.getAllClassNames())) {
if (matcher.matches(eachName)) {
for (PsiClass eachClass : cache.getClassesByName(eachName, scope)) {
if (isTestClass(eachClass, klass) && !processor.process(Pair.create(eachClass, TestFinderHelper.calcTestNameProximity(klassName, eachName)))) {
return;
}
}
}
}Le code filtre les noms courts actuellement dans le cache en utilisant une expression reguliere. Pour chacune des chaines resultantes, il recherche les classes correspondantes.
En journalisant les noms de classe apres la condition, nous obtenons toutes les classes qui la passent.
Lorsque j’ai execute le programme, il a journalise environ 25000 classes, un nombre etonnamment eleve pour un projet vide !
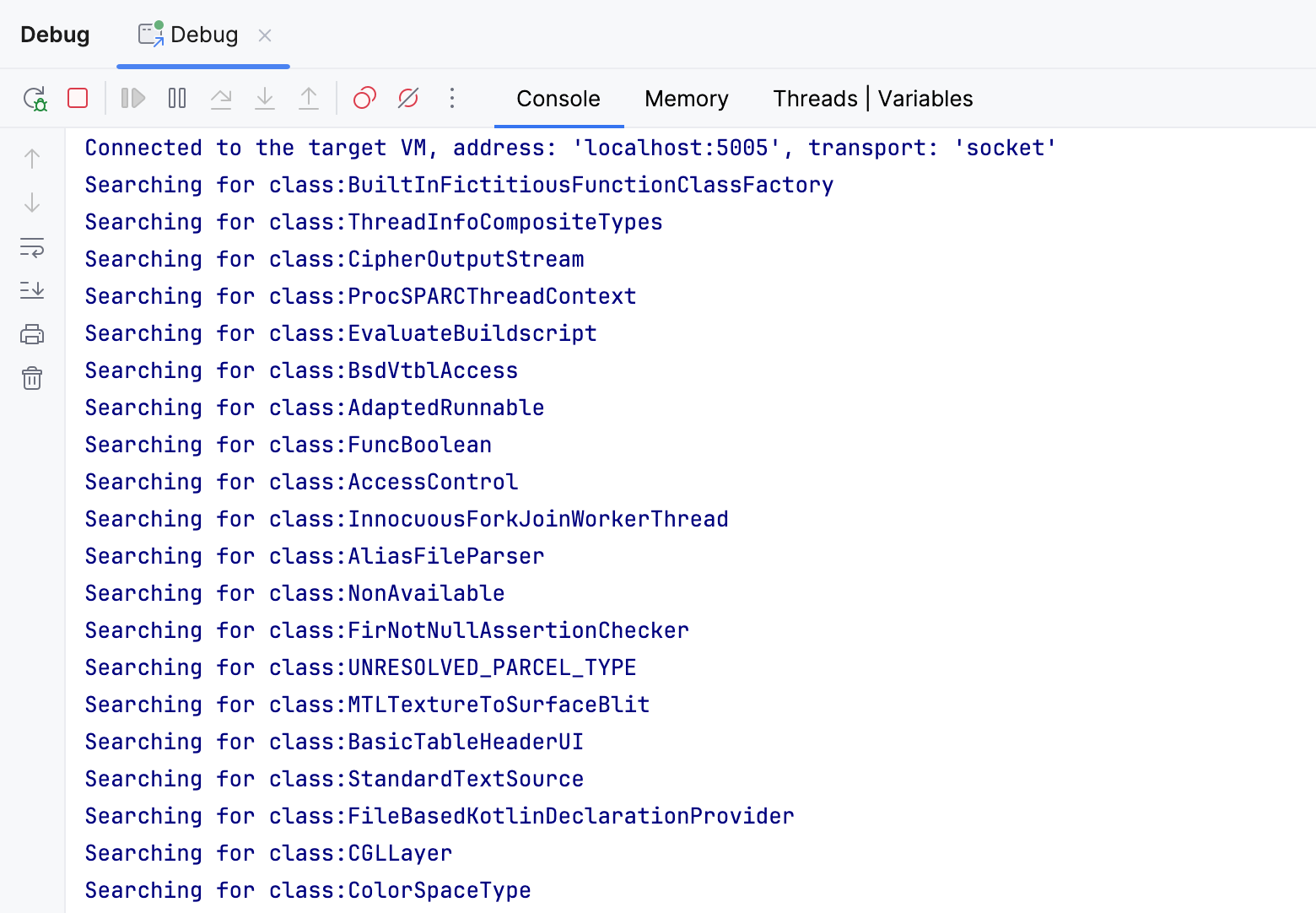
Les noms de classe journalises viennent clairement d’ailleurs, pas de mon projet ‘Hello World’.
Le mystere est resolu : IntelliJ IDEA met si longtemps a trouver des tests pour la classe A ,
parce qu’il verifie toutes les classes en cache, y compris les dependances, les JDK, et meme les classes d’autres projets.
Trop d’entre elles passent le filtre parce qu’elles ont toutes
la lettre A dans leurs noms.
Avec des noms de classe plus longs et plus realistes, cette inefficacite serait passee inapercue,
simplement parce que la plupart de ces noms auraient ete filtres par la regex.
La correction ?
Malheureusement, je n’ai pas pu trouver de correction simple et fiable pour ce probleme. Une strategie potentielle serait d’exclure les dependances du perimetre de recherche. Cela semble viable a premiere vue, mais il y a une possibilite que les dependances contiennent des tests. Cela n’arrive pas tres souvent, mais quand meme, cette approche casserait la fonctionnalite pour de telles dependances.
Une approche alternative est d’introduire le masque de fichier *.java, qui filtrerait les classes compilees.
Bien que fonctionnant bien avec Java, cela devient problematique pour les tests ecrits dans d’autres langages, comme Kotlin.
Meme si nous ajoutons tous les langages possibles, cette fonctionnalite echouera simplement silencieusement pour les nouveaux langages supportes,
entrainant une charge supplementaire de maintenance et de debogage.
Quelle que soit l’approche, la correction merite un article a part entiere, donc nous ne l’implementons pas maintenant. Ce que nous avons fait, cependant, c’est decouvrir la cause racine d’un ralentissement, ce qui est exactement pourquoi on utilise un profileur.
Partager le snapshot
Avant de conclure, il y a encore une chose qui vaut la peine d’etre discutee. Avez-vous remarque que j’ai utilise un snapshot pris sur un autre ordinateur ? De plus, le snapshot ne venait pas juste d’une machine differente. Le systeme d’exploitation et la version d’IntelliJ IDEA etaient egalement differents.
Une belle chose qui est souvent negligee a propos du profileur est la facilite de partage des donnees. Le snapshot est ecrit dans un fichier, que vous pouvez envoyer a quelqu’un d’autre (ou recevoir de quelqu’un). Contrairement a d’autres outils, comme le debogueur, vous n’avez pas besoin d’un reproducteur complet pour commencer l’analyse. En fait, vous n’avez meme pas besoin d’un projet compilable pour ca.
Ne me croyez pas sur parole ; essayez vous-meme. Voici le snapshot : idea64_exe_2024_07_22_113311.jfr