Junieのコード (AsciiDoc対応)
他の言語: English Español Français Deutsch 한국어 Português 中文
先週、Foojay Podcast で、Duplicate Finder について話しました。ホストはFrank Delporteさんで、 他のフォーマットへのサポートを実装することについて簡単に触れました。フランクは、私がAsciiDocを追加する予定があるかどうかを尋ねました。 なぜなら、それはAzulでの彼の技術文書の執筆に役立つかもしれないからです。
私たちは、その支援を近いうちに追加することについて考えることに同意しました。 同時に、私はJunieという JetBrainsが新しく発表したコーディングエージェントを試す機会が得られました。現在は早期アクセスの段階にあります。 しばらくすると、これは実際に試す絶好の機会であるという考えが浮かびました。 コーディングエージェントは典型的なタスクをよく解決します。 しかし、よく知られているフレームワークに基づかず、一般的なドメインの外にあるプロジェクトはどうでしょうか? ある意味でコーディングエージェントに懐疑的な私としては、期待は混在していました。

以下にその経過を説明します。
インストールと概要
JunieはIntelliJ IDEAプラグインです。 ユーザーインターフェースはJetBrains AIアシスタントやGitHub Copilotと似たような縦型のツールウィンドウを採用しています。以下はその見た目です:
ミニマリストデザインの特徴は、プロンプトフィールド、コンテキストの追加ボタン、 そしてBrave Modeと題されたチェックボックスだけです。このオプションでは、 Junieがあなたと二重確認することなくコマンドを実行できるか制御することができます。 私はまだそこまで勇敢ではないので、その機能は次回試してみることとします。
要件の設定
Junieにコーディングタスクを与える前に、AsciiDoctor ガイドからトピックをダウンロードし、
Junieがテストデータおよび参考資料として使用するためにsrc/test/resources/の下に配置しました。
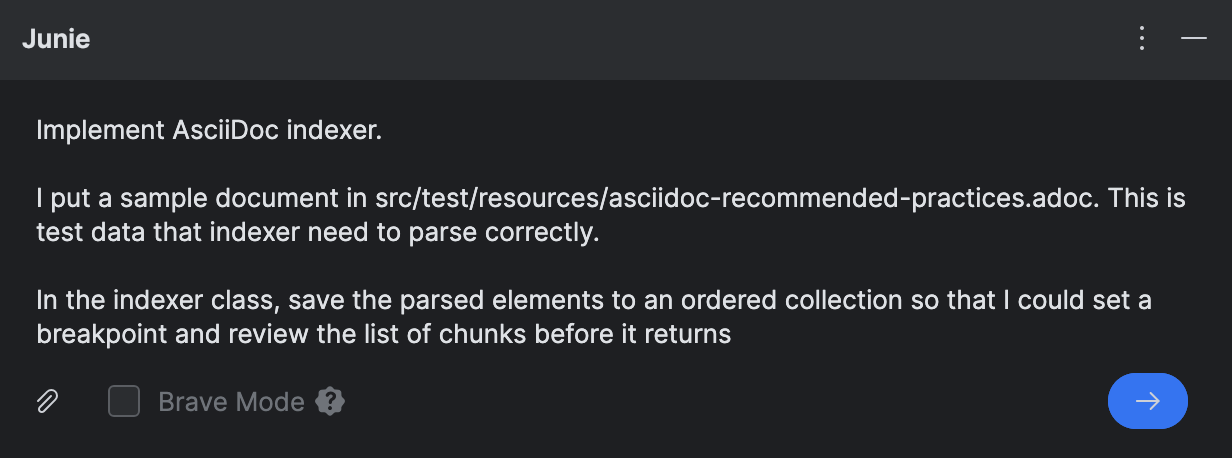
デバッグのために、Junieに解析したブロックを別のコレクションに追加してもらいました。これは 実際のインデックスが複数のレベルで構造化されており、デバッグが不便なためです。 簡単にするために、ランタイムで結果を確認する必要がある場合、解析した要素をフラットな構造で見ることが良いでしょう。
‘コーディング’
プロンプトを入力すると、Junieはタスクを小さな項目に分解し、それらを実装し始めます。 AsciiDocのサポートを追加するために、以下のようなプランを出しました:
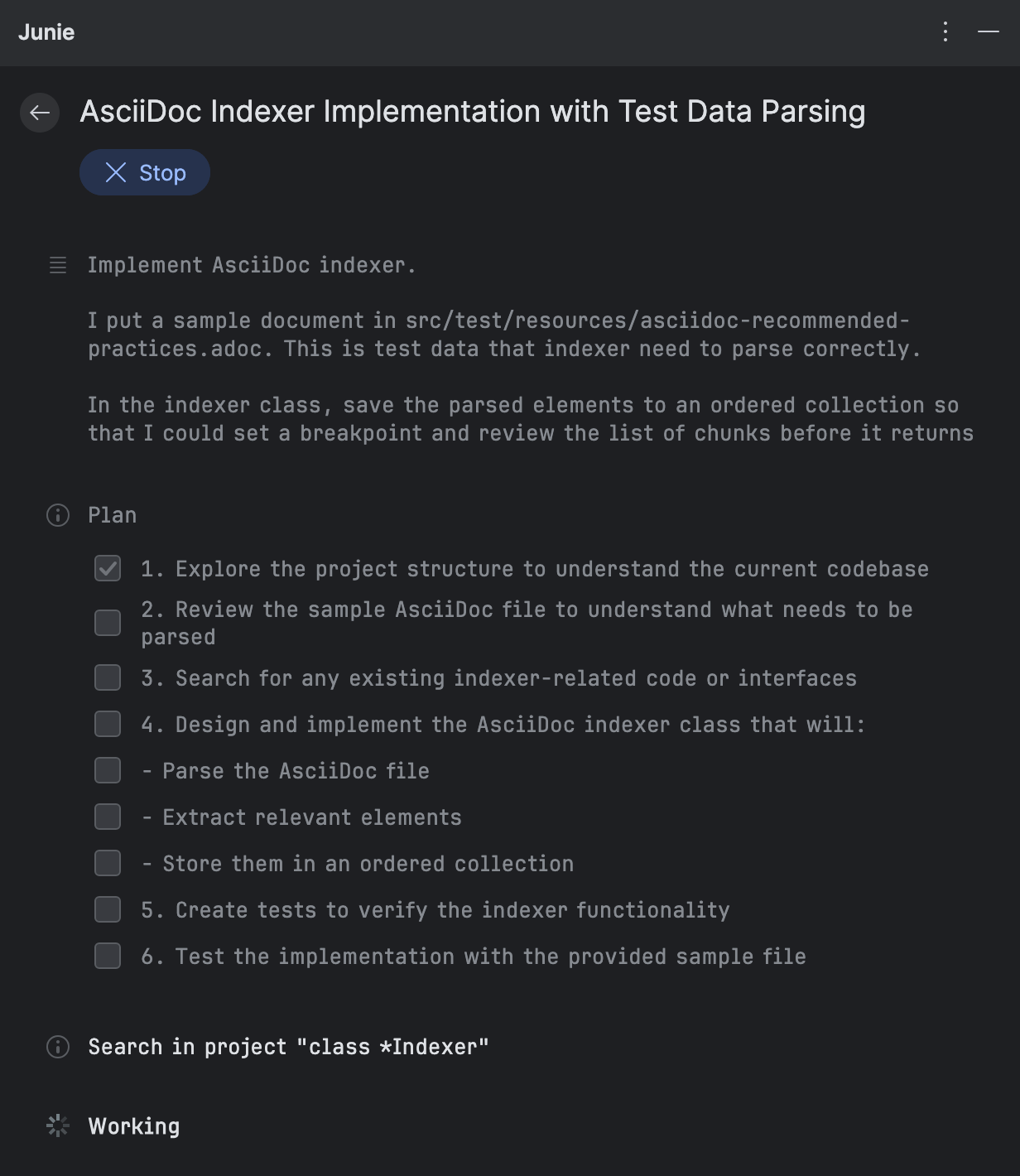
Junieが各項目を実行すると、変更の要約を提供します。これにより、全体のワークフローが終了するのを待たずに、すぐにそれらをレビューすることができます:

ファイル名をクリックすることで、 IntelliJ IDEAの diff ビューで変更を追跡することができます。これはGitの変更を表示したりローカル履歴 (Local History)と同様の方法です。
すべての項目が完了した後、Junieはテストの記述を進め、それらを実行するように提示します:
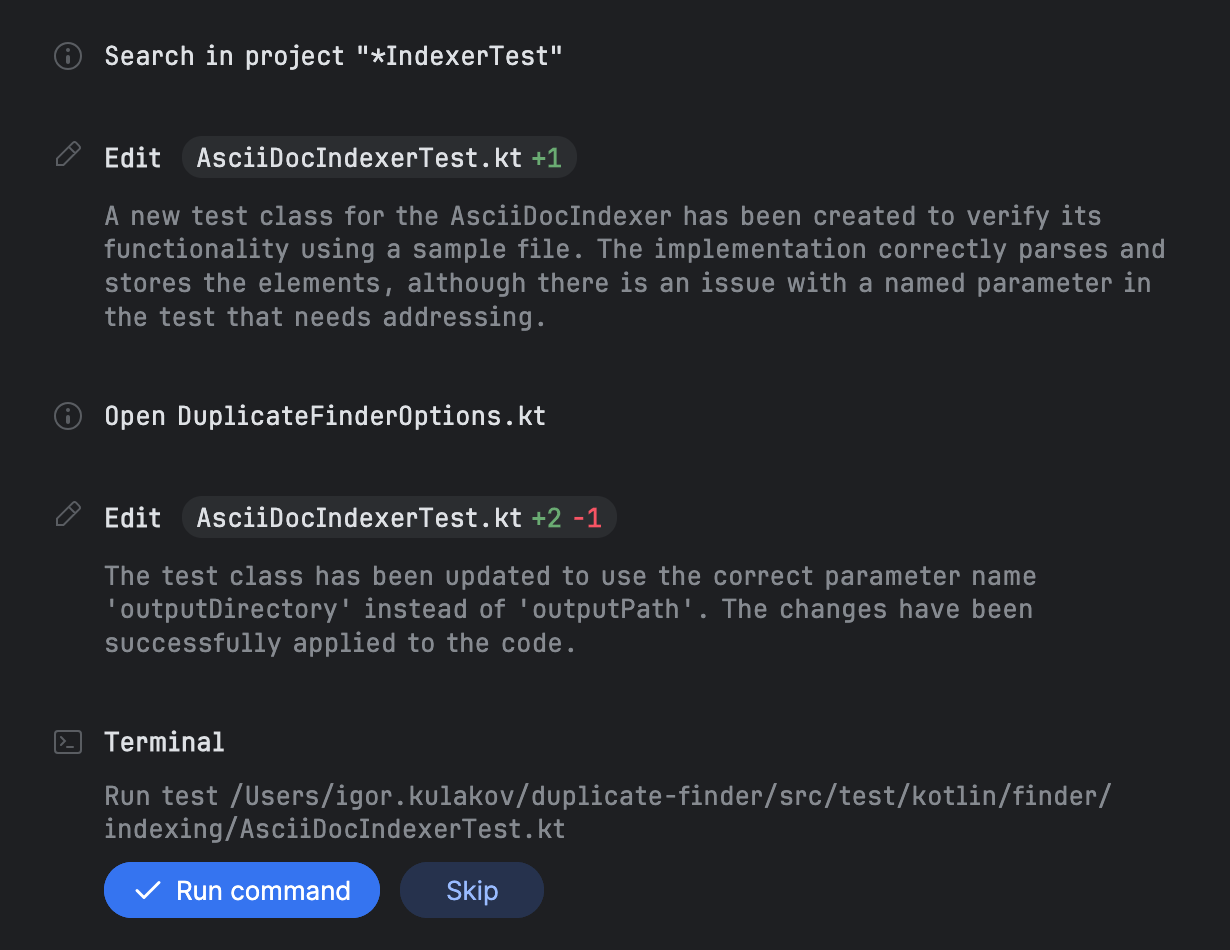
このタスクでは、私はJunieにテストデータを与え、明示的にテストを依頼しました。しかし、Junieは、デフォルトでテストデータと共にそれらを生成するように見えます。私はテストについて言及せずにタスクを実行してみましたが、その場合でもJunieはそれらを作成しました。
テストを実行した後、この場合は成功したのですが、Junieは何が行われたかの要約を提供します。

コードの質
コードとテストを確認したところ、それらはよく構造化され、清潔でした。 私が本当に気に入ったのは、Junieはプロジェクトがコンパイルできるように必要なコードを変更するだけでなく、 タスクの文脈で意味のある他の変更を導入するという余分なステップも踏みました。
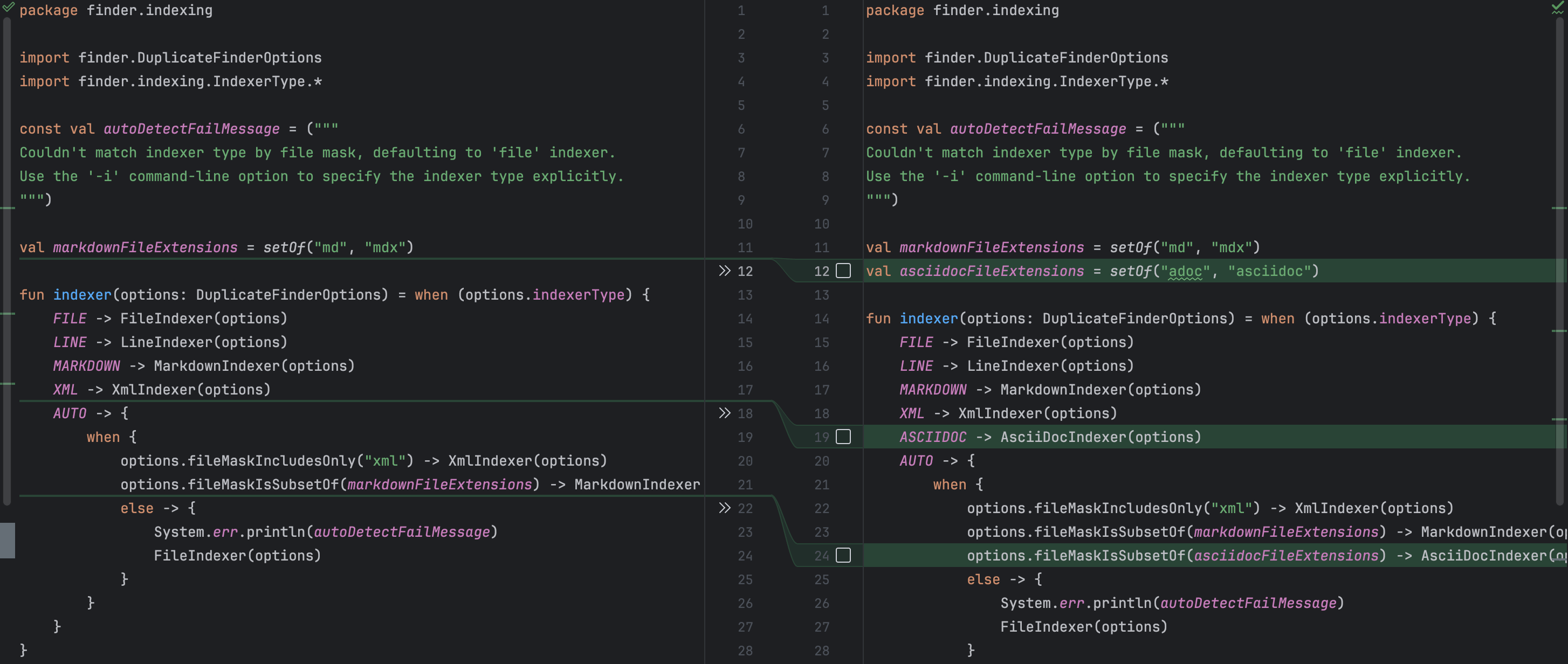
例えば、新しいインデクサーはコマンドライン引数で公開されなければならないということを私は言及するのを忘れていました。 この見落としはコンパイルエラーを引き起こすものではありませんが、エンドユーザーが機能にアクセスできないと意味がありません。 Junieはそれを認識し、対応する コマンドラインオプションと説明を追加しました。また、クライアントコードが新しいインデクサーのインスタンスを取得できるように、ファクトリーメソッドも正しく更新しました。 同時に、不要な変更はなく、それも素晴らしいところです!
ここまでのところはすべて良好ですが、まだやらなければならない作業が残っているようです。
実装の修正
コーディングエージェントがまだ完全に自律していない分野の一つは、ランタイムでの潜在的な問題を認識することです。 技術的には、実装は正しく、すべてのテストを通過しています。 パースの結果は一貫しており、 評価ダイアログで確認できます。
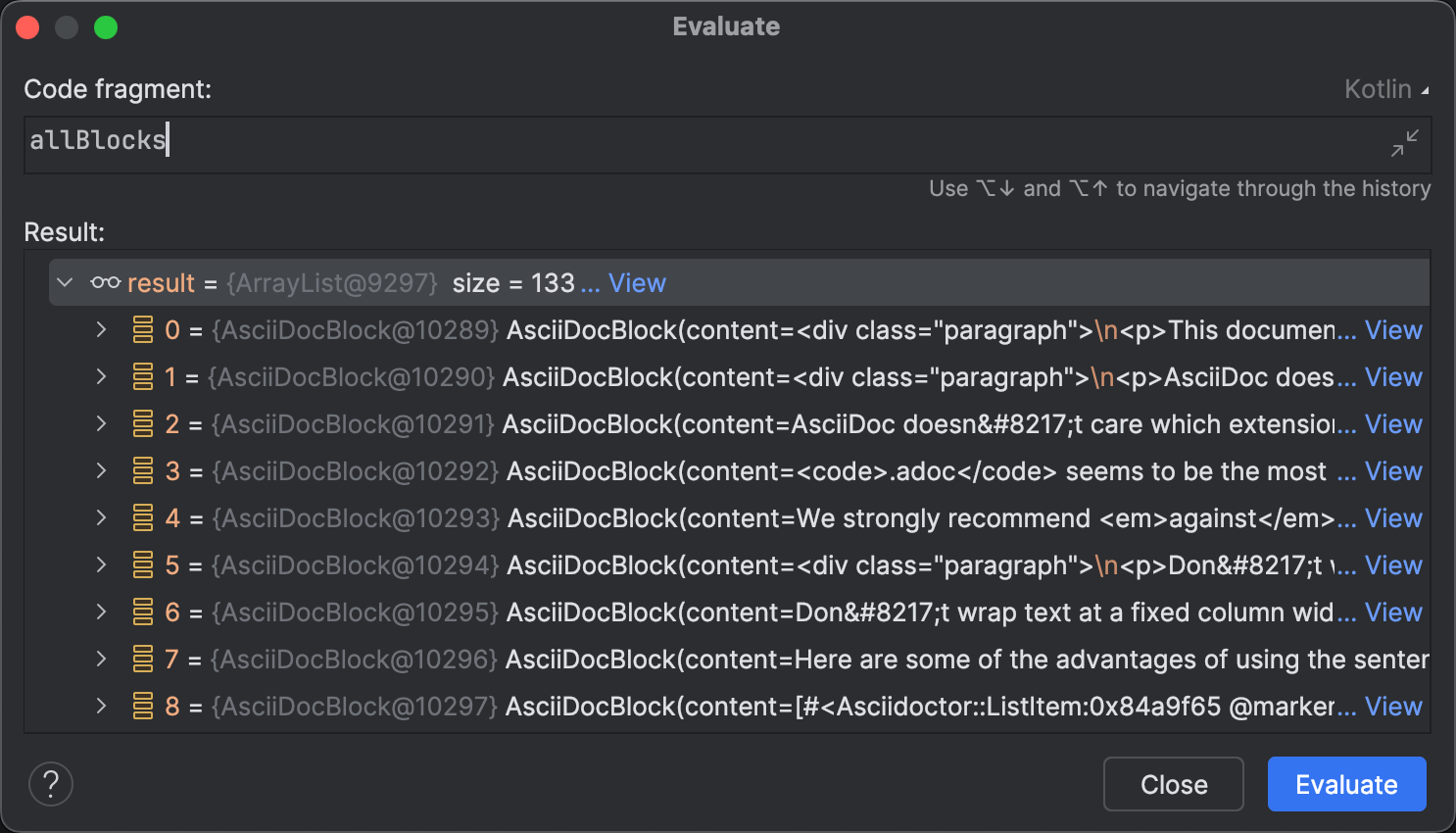

式の評価 (Evaluate Expression) は、コレクションを探索するだけでなく、さまざまな興味深い使用例があります。 例えば、プログラムを再起動せずにフィックスをプロトタイプ化して適用するためや、その状態を任意に変更するために使用することができます。
すべてが順調に見えますが、一つのファイルの処理に驚くほど長い時間がかかっています。それを調べると、約35ファイルのバッチを解析すると必ず OutOfMemoryError が発生することが分かりました。
実装を分析してみたところ、非効率的なループやリソースのリークといった明らかな欠陥は見つかりませんでした。
アプリを -XX:+HeapDumpOnOutOfMemoryError で実行すると、ヒープダンプが得られ、
これは大きな保持サイズを持つ多数のJRuby型を明らかにしました。
これはライブラリが問題の可能性があることを示唆しています。
もちろん、この推測は正確でないかもしれませんが、これによってプロファイリング (またはドキュメントの読み込み)の興味深い機会が得られます。 とにかく、JRubyの依存関係を単純なKotlinの実装に変更すると、速度が大幅に向上する可能性があります。 ですので、私はJunieにカスタムパーサーを使用して実装を書き直してもらうことにしました。
新しいタスクを開始する代わりに、 そのためにFollow upプロンプトを使用しました:
結果
Junieは要求通りに実装を見直しました。私はAsciiDocフォーマットにそれほど慣れていないのですが、 パースが大体正しく行われているように見受けられます。プリアンブルのパースに改善の余地があることや、おそらく他の何かがあることですが、それはその役割を果たします。
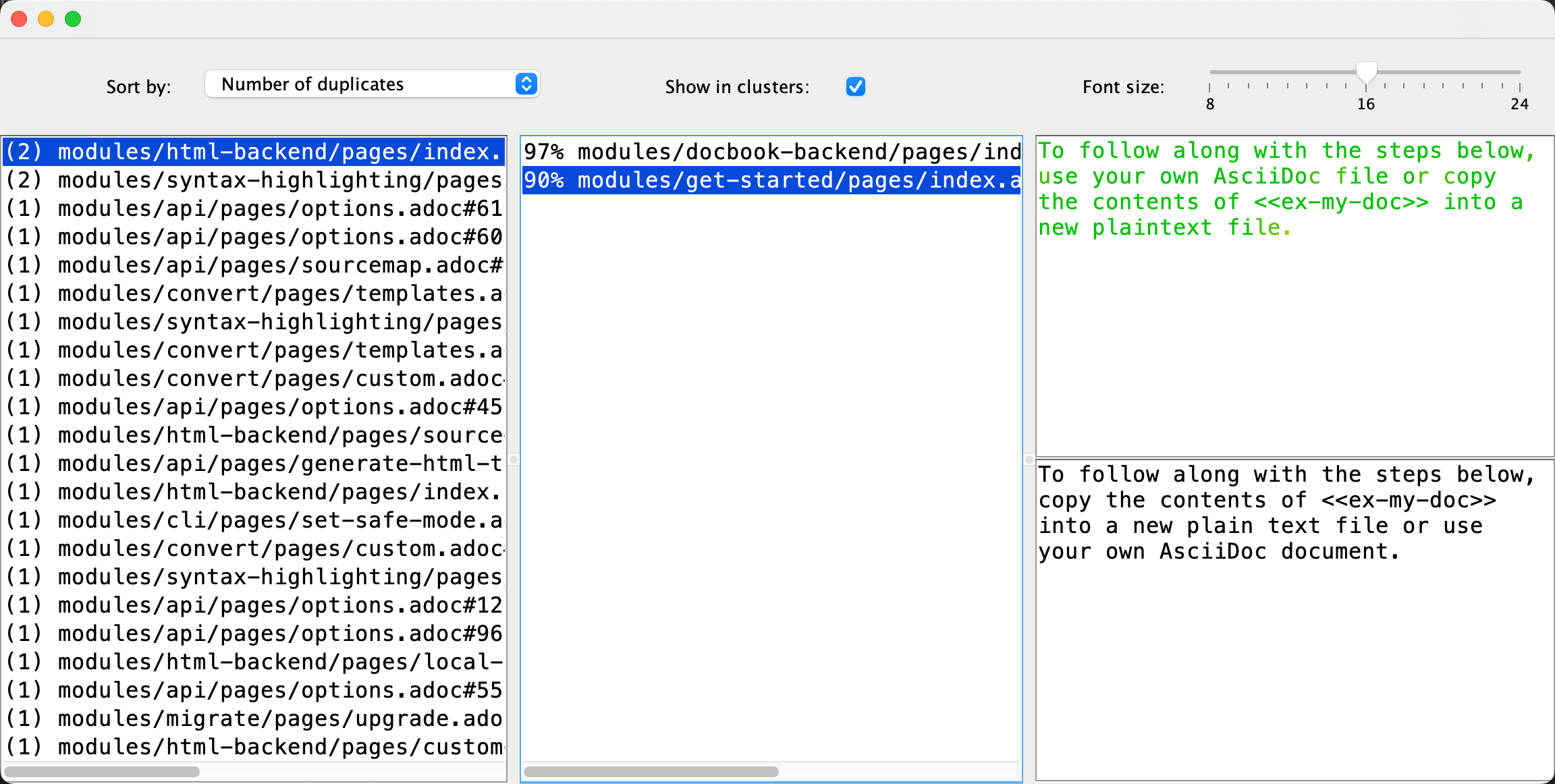
更新されたDuplicate Finderを AsciiDoctor自身のヘルプに適用すると、いくつかの重複が検出されました! 分析には私のラップトップで350ミリ秒かかりました:
変更がコミットされたプロジェクトは私のGitHubにあります。 新しいバージョンのアプリを試すための手順とダウンロードリンクは、Duplicate Finderのページにあります。 全体として、実装は完璧ではないかもしれませんし、確かにもっと徹底的なチェックが必要ですが、 それでも、今日では5分でどれだけ多くのことを達成できるかについて、私は非常に感銘を受けています。
Junie を自分で試してみたい方は、ここからEAPにサインアップできます。