Duplicate Finder for Text: Requirements
Other languages: Español Français Deutsch 日本語 한국어 Português 中文

It’s been a while since I published the intro to the duplicate finder project, so it looks like high time to provide some progress on that. Before starting to write the program code, it makes sense to lay down the requirements first. A good way to do this is by writing tests. Not only will the tests help us develop faster, but they will also ensure that the code adheres to the specification.

Requirements
In this section, I’ve formulated my idea of the duplicate finder’s core features. These work well for my applications. However, as each project might have different needs, I would be happy to hear and implement your ideas.
Detecting both exact and fuzzy matches
The duplicate detection tool should be capable of finding both exact and fuzzy matches with granularity down to individual symbols. For example, it should identify the following texts as similar:
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.Additionally, in the case of fuzzy duplicates, the degree of similarity should be measurable. This would allow us to quickly evaluate the duplicate pairs and sort them by how closely the text fragments resemble each other.
Language-agnostic
Given the multitude of potential target languages, it would be nice to support as many of them as possible. Some approaches might require separate maintenance for every added language, which is not at all scalable and requires lots of resources. Ideally, the tool should use some heuristic or language-agnostic algorithm for compatibility with any common language.
Configurable
The criteria for identifying duplicates should be adjustable, with the settings along the lines of:
- the length of the analyzed text fragments
- the number of duplicates
- the degree of similarity
Generally, the longer and more frequently repeated a section is, the more beneficial it is to deduplicate it. However, it ultimately depends on the particular application, so it would be nice to have control over these thresholds.
Definitions
With the basic requirements sorted out, it’s time to get code definitions in place. At this stage, we’ll need:
- the basic unit of text that will represent potential duplicates
- the interface for the duplicate finder
The code in this chapter doesn’t need to be exhaustive and provide for every future use-case – we can always come back for adjustments.
Chunk
When it comes to a unit of text, which details are important for us? For our purposes, I’d stick with the text that a fragment contains, the path to its containing file, its line number, and the type of the element – in case the source is not just plain text:
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)This definition doesn’t take into account some nuances. For example, we might leave out the
content field.
This would save us some RAM, but the tradeoff will be the speed of accessing the element’s content,
because then the program will have to read it from disk each time instead of only once.
We’re not fighting for performance right now, so a potentially suboptimal choice is fine.
Interface
We don’t have an implementation yet, so we’ll program against an interface. The interface defines what our function should take as input and what it should return as output, abstracting away the function’s internals. This effectively creates a contract, allowing us to write tests right now, without coding the actual algorithm. In the future, the interface will also make alternative implementations compatible with the existing tests and client code.
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}Here’s the meaning of the parameters that the interface accepts:
-
root– the folder with the content to analyze -
minSimilarity– the minimum percentage of similarity for twoChunkobjects to be considered duplicates -
minLength– minimumcontentlength for aChunkto be analyzed -
minDuplicates– minimum number of duplicates for a cluster of duplicates to be reported -
fileExtensions– file extension mask for filtering out irrelevant files
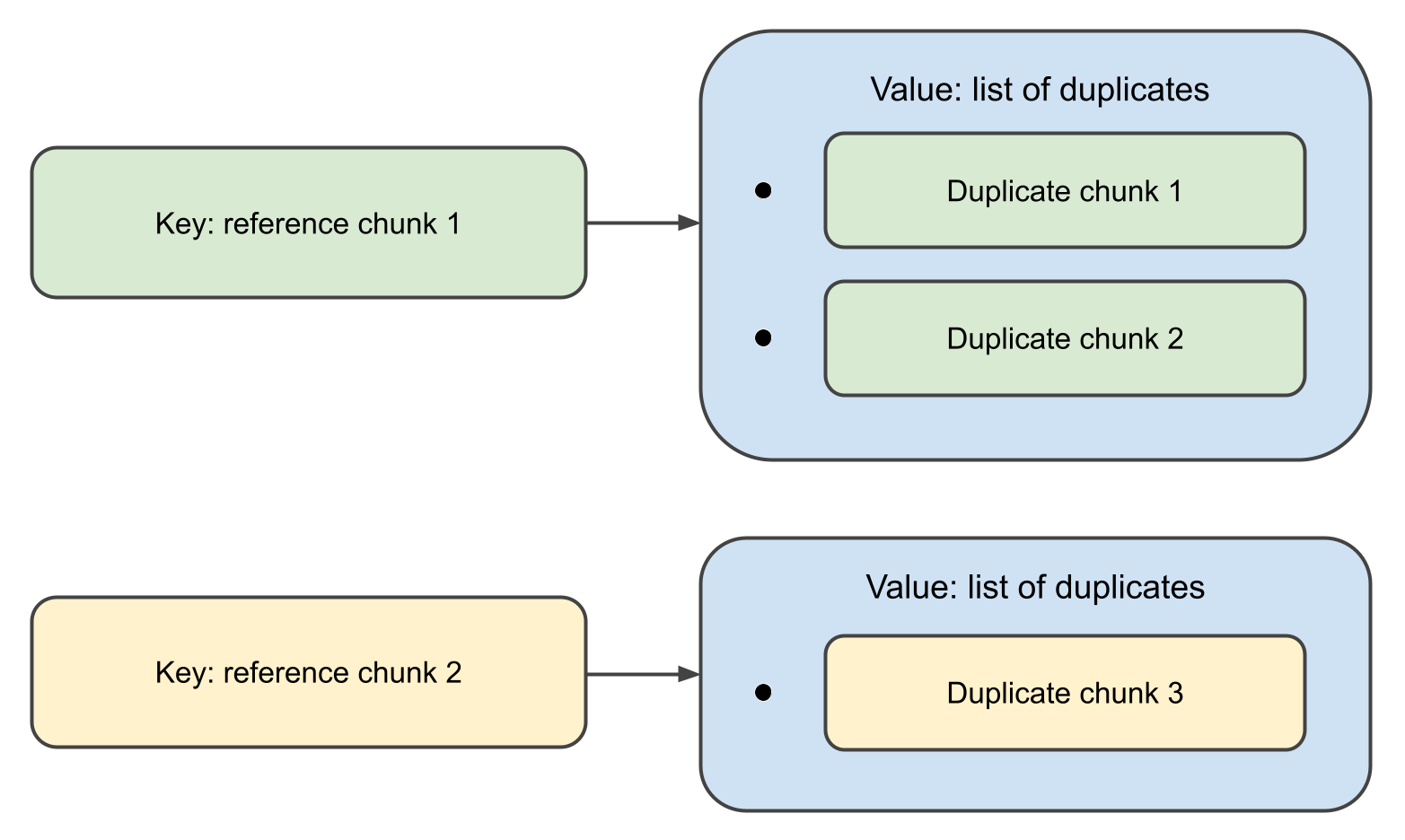
When the function completes, it will return a map,
where the keys are Chunk objects, and the associated values are lists of their duplicates.
Actually, the definition above is unnecessarily verbose. Introducing an interface just for a single function and a few callers is too much. Kotlin has an elegant way of handling this with first-class functions:
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()This declaration means that the duplicate finder is a function that takes
Path, DuplicateFinderOptions and outputs
Map<Chunk, List<Chunk>> ,
and that the function itself is not yet implemented.
This might not be the best style for large projects, but in smaller ones like ours,
it works great.
Test data
Since the duplicate finder is supposed to work with text data, the tests will also need some texts to analyze. This means we need to prepare some examples containing fuzzy duplicates. Let’s start with the duplicates:
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes."The idea behind FUZZY_MATCH_TEMPLATE
is that we’ll use it to programmatically produce the actual fuzzy matches:
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)Next, we’ll generate a text consisting of random English words:
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}Finally, we’ll randomly inject EXACT_MATCH
and fuzzyMatches into the generated text:
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}Tests
As already mentioned, the primary goal of the tests at this stage is to define the specification, so let’s not waste too much time on perfecting the test suite. Instead, we’ll write just enough to ensure that the future code adheres to the requirements.
This is the code of the test class:
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }Next steps
We have established the requirements by defining the interface and writing the tests. In the next post of the series, we’ll implement the actual algorithm and see how well it performs. See you soon!