RAG + Semantic Markup
Other languages: Español Français Deutsch 日本語 한국어 Português 中文
The importance of documentation differs among software projects, but even the most important documentation plays an inherently auxiliary role. It is not something a program relies upon to function correctly. Even when documentation shares data with the program, the connection is still unidirectional. User-facing documentation mirrors the product and doesn’t change the way the product works.
The primary reason for this is purely technological. We could implement new features and fixes by just writing documentation – if instructions in natural language could be specific enough, and computers were excellent at interpreting them. Sounds familiar, doesn’t it?
While the debate continues whether programming entirely in natural language will be possible, this potential change is actually about the accessibility of software development, rather than introducing some novel way the programs operate. Ultimately, we’d still be getting the same binaries, now with an additional, admittedly remarkable, compiler involved.
Can AI can drive features in a different way? Today, I’d like to cover one of the recent AI-driven features in JetBrains IDEs, which leverages natural language processing directly, turning lots of our documentation to an immensely useful development asset.

Action search
Starting with version 2024.3, AI Assistant in JetBrains IDEs has access to IDE actions and helps you find the correct action for the problem at hand. Additionally, it can execute this action for you:

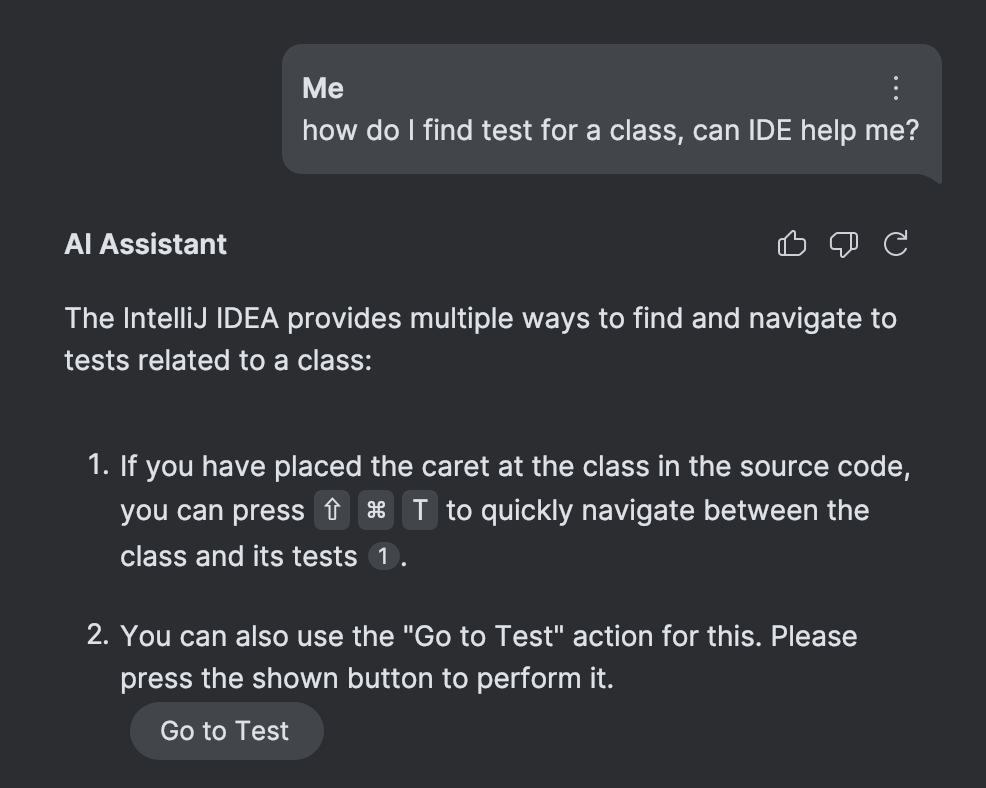
As previously stated, this feature is driven by documentation. While good old code certainly plays a part, the selection of correct action relies exclusively on an advanced form of RAG (retrieval-augmented generation) – without the need for numerous LLM functions or special mappings.
Before moving on to the details, let’s briefly revisit the concept of RAG.
RAG
Retrieval-augmented generation (RAG) is a technique commonly used to improve the precision and grounding of LLM responses. It is especially effective when LLMs are required to give responses on topics beyond their training data and facts that change frequently, making fine-tuning impractical.
In its most common form, the technique consists of maintaining an index over documentation. In this index, the key reflects a document element’s meaning, represented by embeddings, and the value corresponds to the element’s content or a reference to the element itself. Thanks to the numerical representation of keys, the corresponding elements can be semantically compared and retrieved using methods such as cosine similarity or k-nearest neighbors (KNN).
Here’s what happens when you ask something in a RAG-assisted AI chat:
How do I change font size?The system first searches the index, and if that is successful, appends the findings to the prompt. For example:
How do I change font size?
Here's supplementary information that might help you answer the question:
-> the search results are inserted here <-With this approach, the correct answer can likely be inferred from the provided supplementary information, resulting in a more informed and accurate response from the LLM. From the perspective of the end user, it may appear as if the model became more intelligent, while in reality the model remains unchanged – the only difference lies in the prompt.
Now let’s look at how we can enhance this approach.
Semantic markup
If you write technical documentation, you are probably familiar with the concept of semantic markup:
With semantic markup you specify the “meaning” behind each element
For instance, Markdown is not semantic. In Markdown, you operate with common document elements such as headings, paragraphs, lists, and so on, besides some typographical properties. This syntax outlines a high-level structure and tells the processor how to render the document. What it doesn’t tell is the purpose, or the meaning, of various elements within the document.
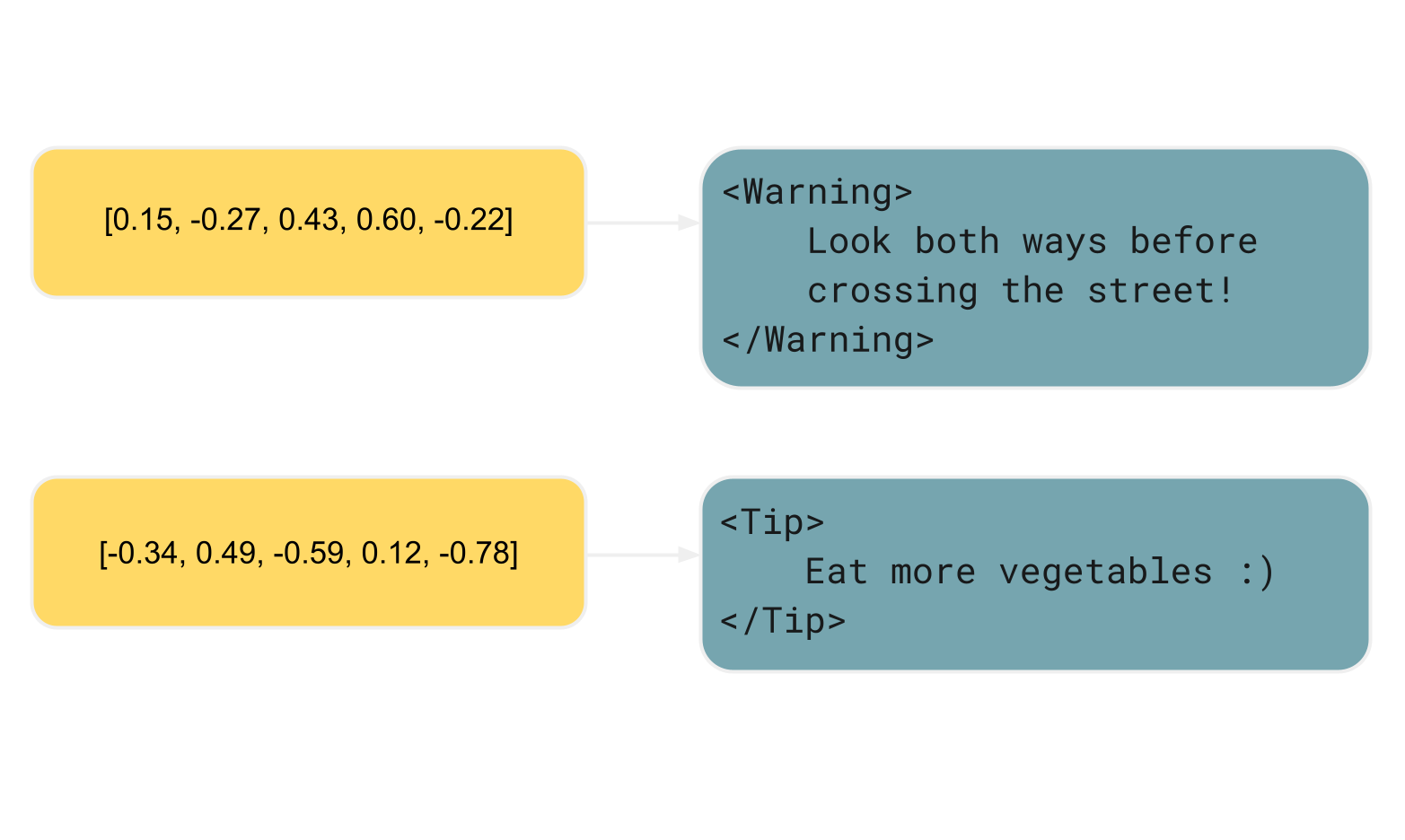
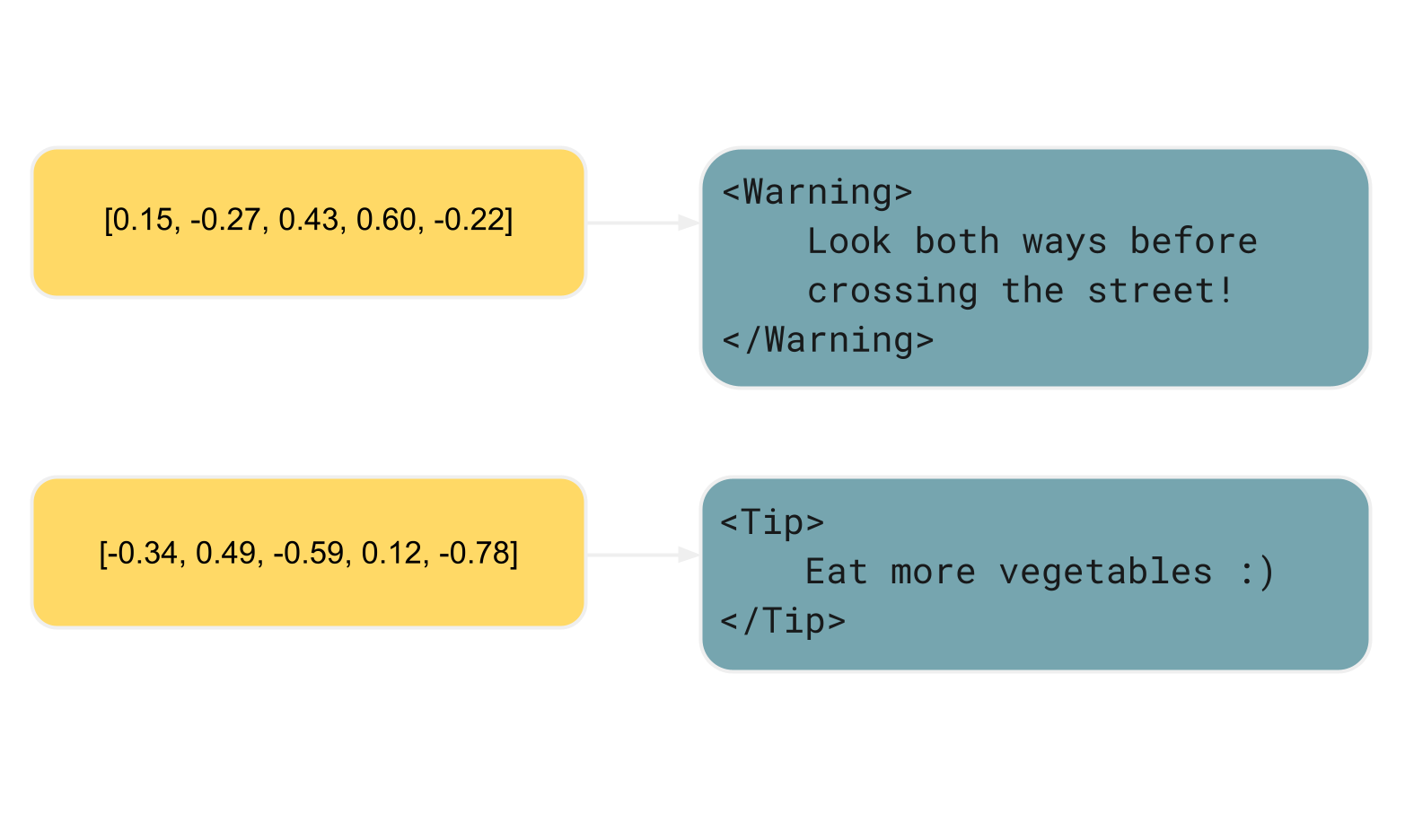
Here’s a brief example. The asterisks indicate to the processor that it should italicize the phrase, similar
to what <i> in HTML means:
*Look both ways before crossing the street!*In contrast, MDX, a superset of Markdown, has semantic properties. MDX allows you to define custom elements, which often stand for UI components and can communicate the content’s intended purpose:
<Warning>
Look both ways before crossing the street!
</Warning>Unlike vanilla Markdown, this specific MDX example abstracts away the visual aspect and focuses on the
content’s purpose instead.
As documentation writers, we are less concerned about whether <Warning>
should use italics or otherwise stand out from the regular text.
Its style is defined in a separate place, such as within the component itself or a CSS stylesheet.
Such separation of concerns
makes the codebase easier to maintain and lets you change the styling in a centralized manner
based on the content’s meaning.
A perfect match?
At JetBrains, we author our documentation using Writerside. This tool supports both Markdown and semantic XML as source formats for documentation. The example below shows a typical document structure written in Writerside’s semantic XML:
<chapter title="Testing" id="testing">
... some content ...
<procedure title="Navigate to tests" type="choices">
<p>
When at a symbol declaration, you can navigate to the corresponding
tests by doing one of the following:
</p>
<step>
From the main menu, select <ui-path>Navigate | Test</ui-path>.
</step>
<step>
Press <shortcut key="GotoTest"/>.
</step>
</procedure>
... more content ...
</chapter>You will notice there is some meta information in the provided snippet. It is already valuable for the reasons stated above, but nothing prevents us from putting it to some additional use.
Consider the <shortcut> tag,
which represents a platform-dependent key binding.
This tag is a part of an indirection layer that enables
managing and validating shortcut mentions in a centralized way.
To insert a shortcut within a document, you use the <shortcut> tag
along with the corresponding action ID like this: <shortcut key="CoolAction"> .
During the build process, the tool validates and transforms the <shortcut> elements
into the actual key bindings for the available keymaps.
This approach synchronizes the shortcuts between the documentation and the product, as well as gives the documentation users the flexibility to choose their preferred keymap. To see this in action, visit IntelliJ IDEA help and note how the shortcuts change in the text depending on the selected keymap in the Shortcuts menu:
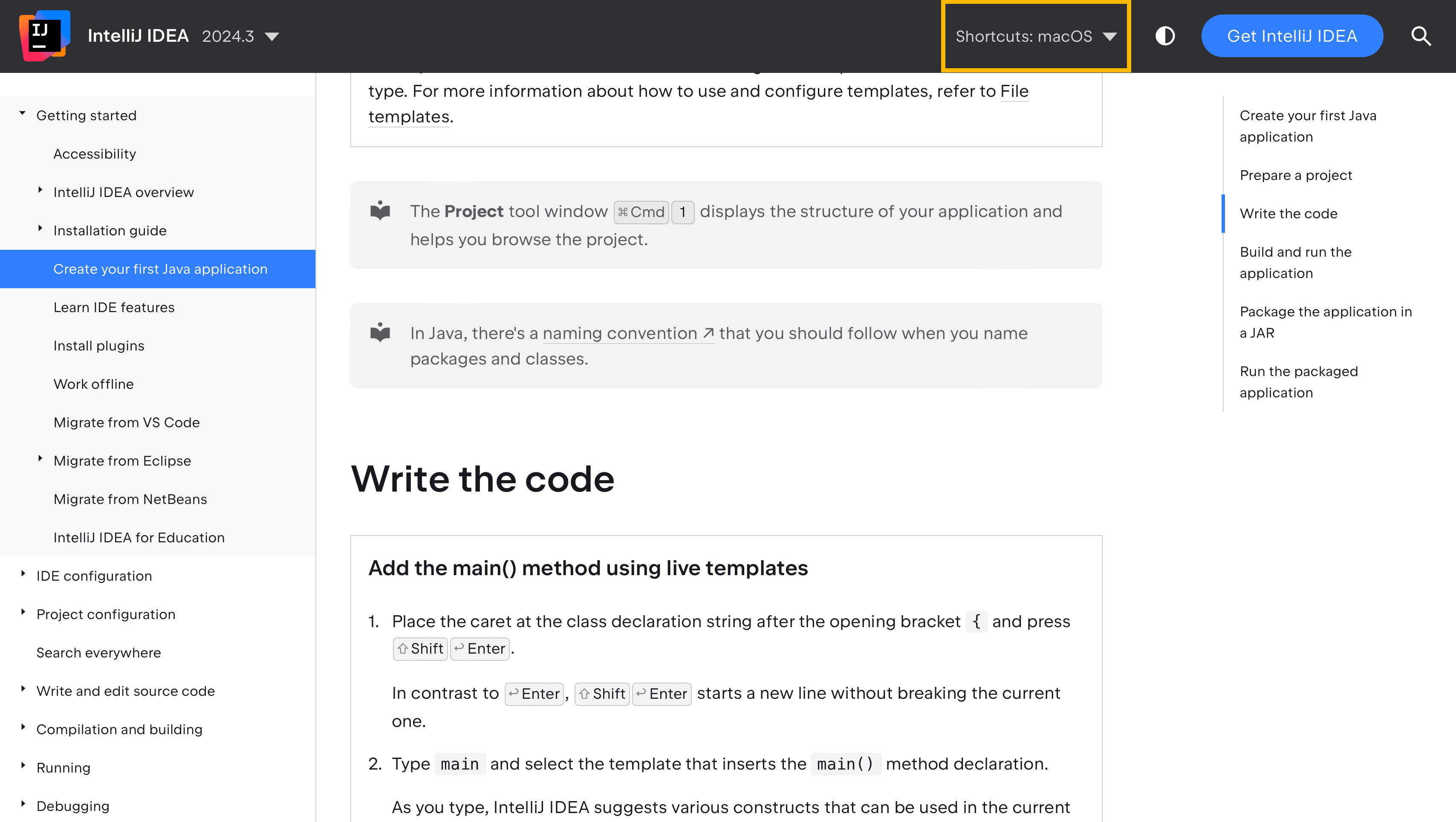
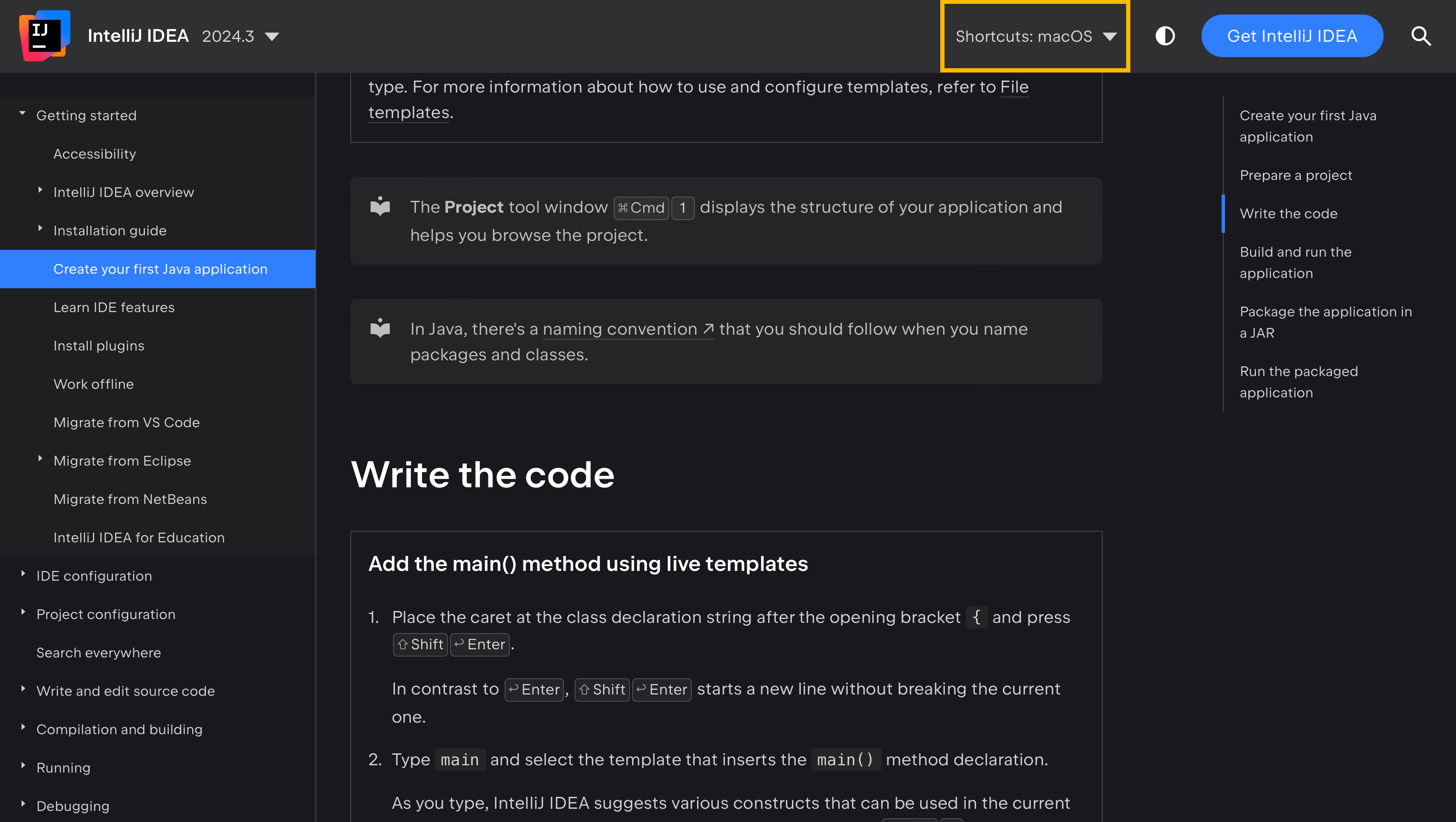
That’s the primary purpose of the <shortcut> tag.
How can this tag be beneficial in terms of enhancing RAG?
The most straightforward use is to display platform-specific shortcuts in AI chat, much like on the help page:

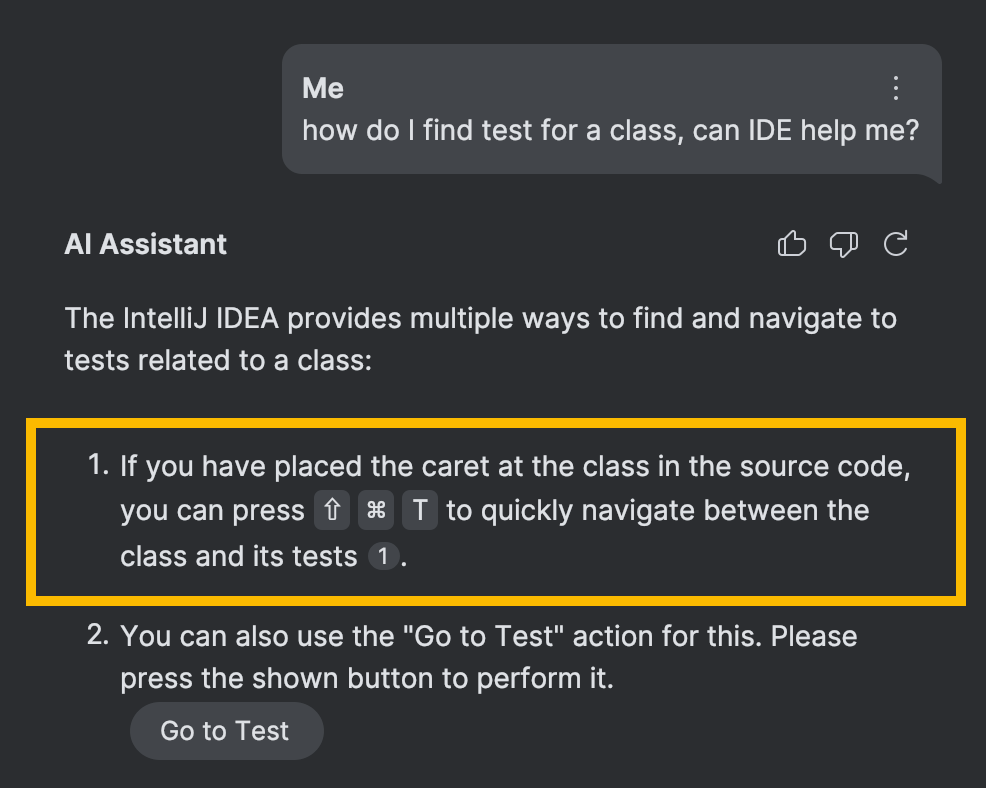
However, there is a more interesting part to it. Similar to building indexes for retrieving facts and instructions, it is possible to build indexes that enable the lookup of action IDs.
In the simpler RAG scenario discussed earlier, we generated the embeddings from the same element intended for retrieval. However, for the action ID index, we’ll use the following structure:
- the keys are the embeddings derived from the elements enclosing a
<shortcut>tag - the values are the action IDs within the corresponding
<shortcut>tag
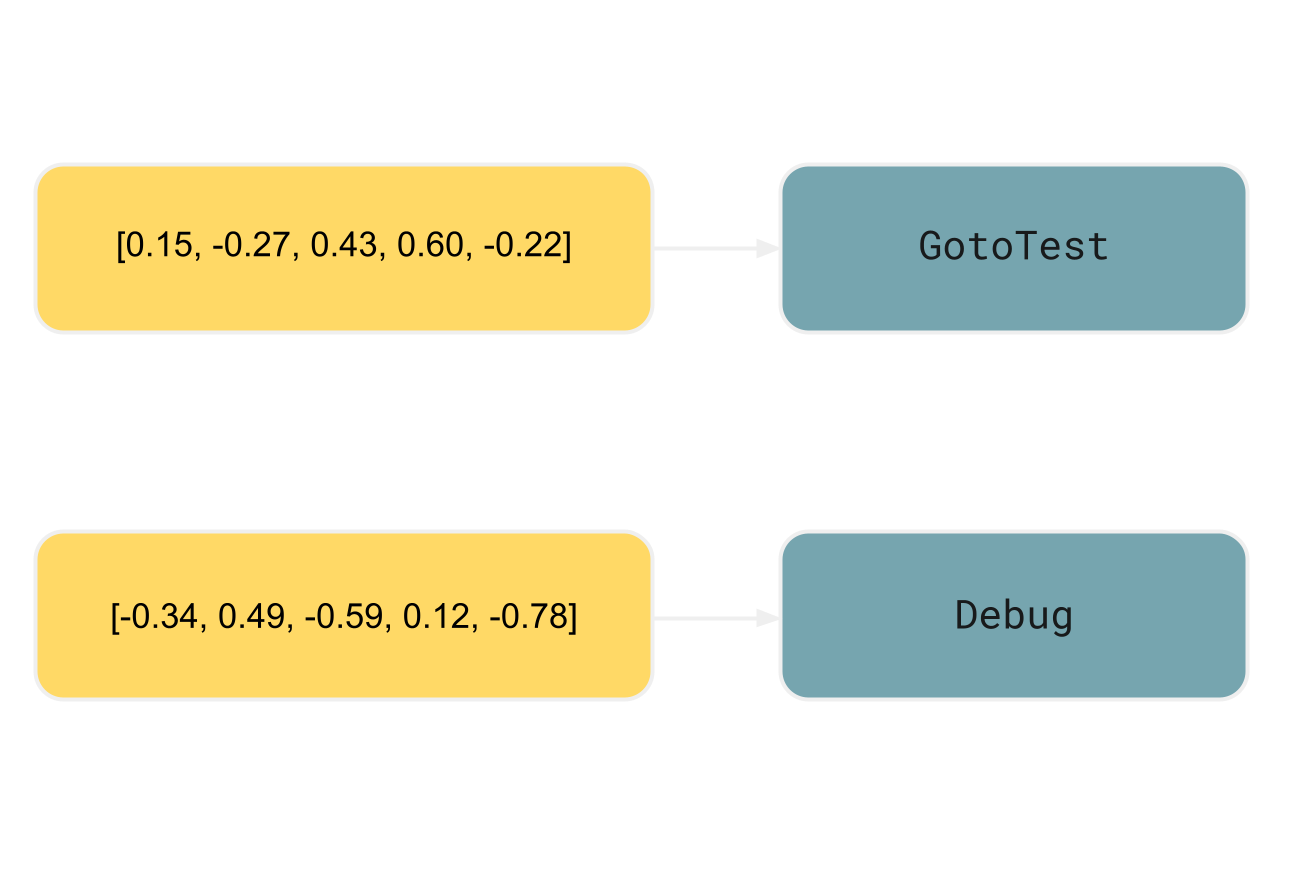
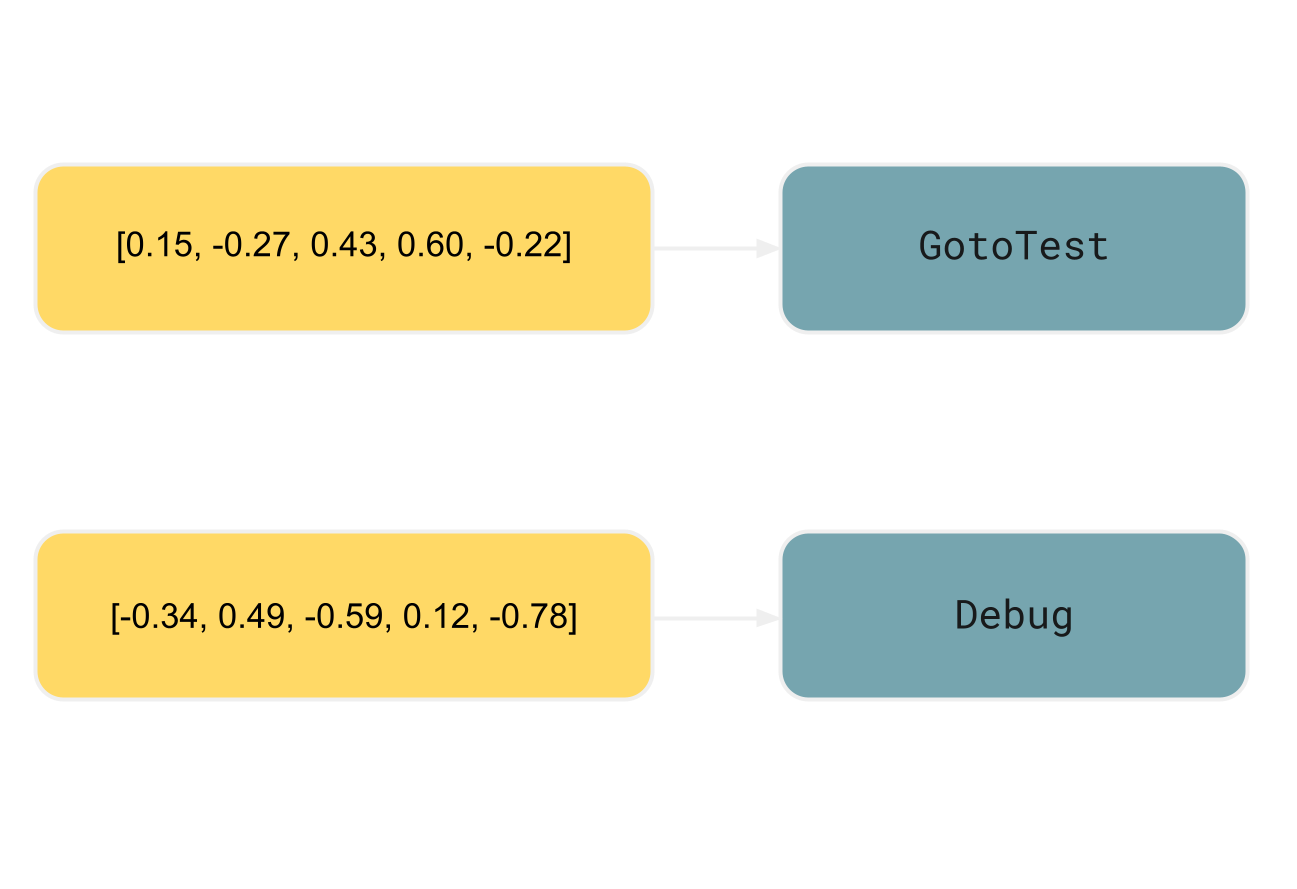
In the example, the enclosing element
for <shortcut key="GotoTest"/>
would be <step>
or even the entire <procedure> :
<procedure title="Navigate to tests" type="choices">
<p>
When at a symbol declaration, you can navigate to the corresponding
tests by doing one of the following:
</p>
<step>
From the main menu, select <ui-path>Navigate | Test</ui-path>.
</step>
<step>
Press <shortcut key="GotoTest"/>.
</step>
</procedure>Context matters
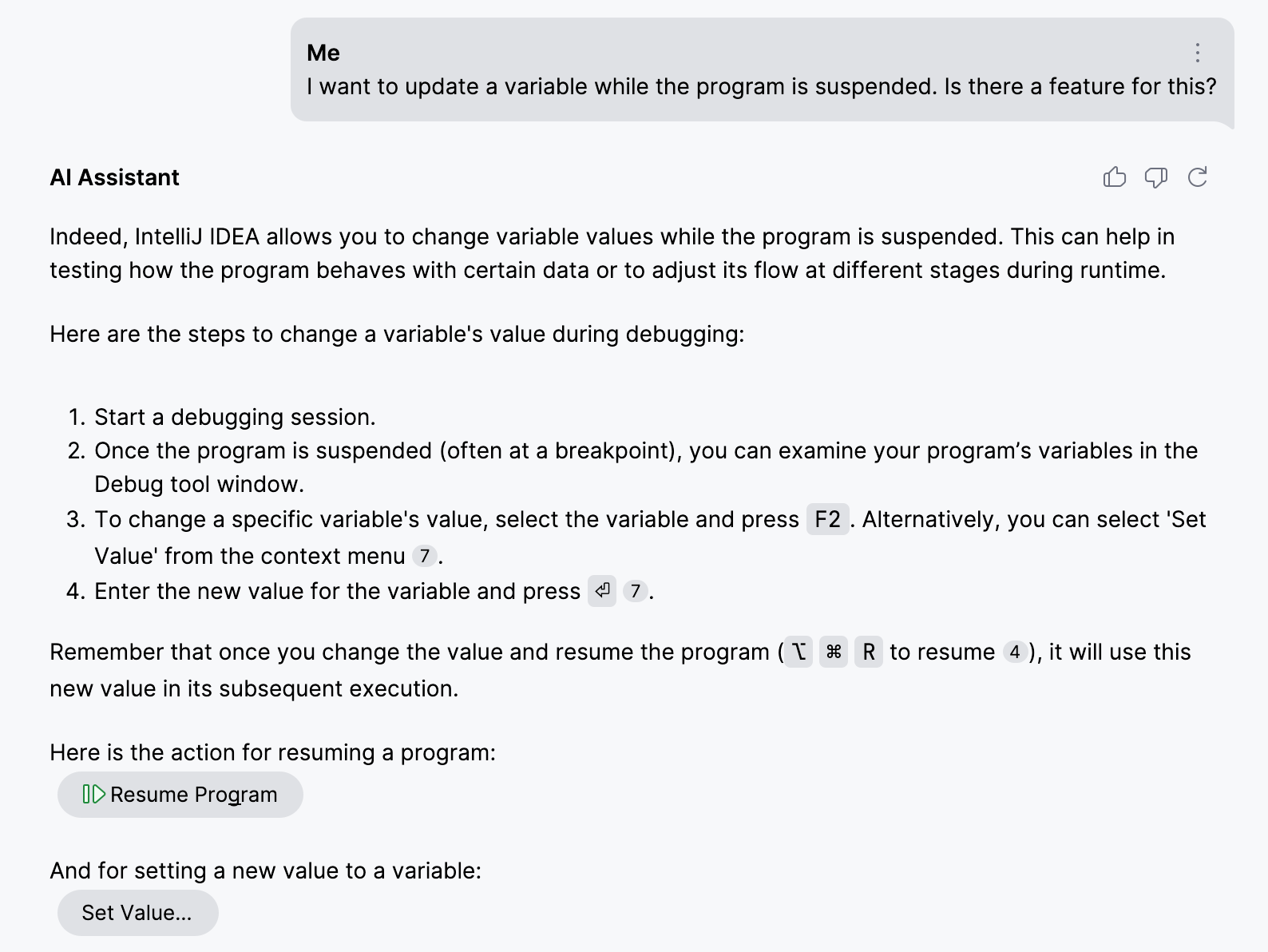
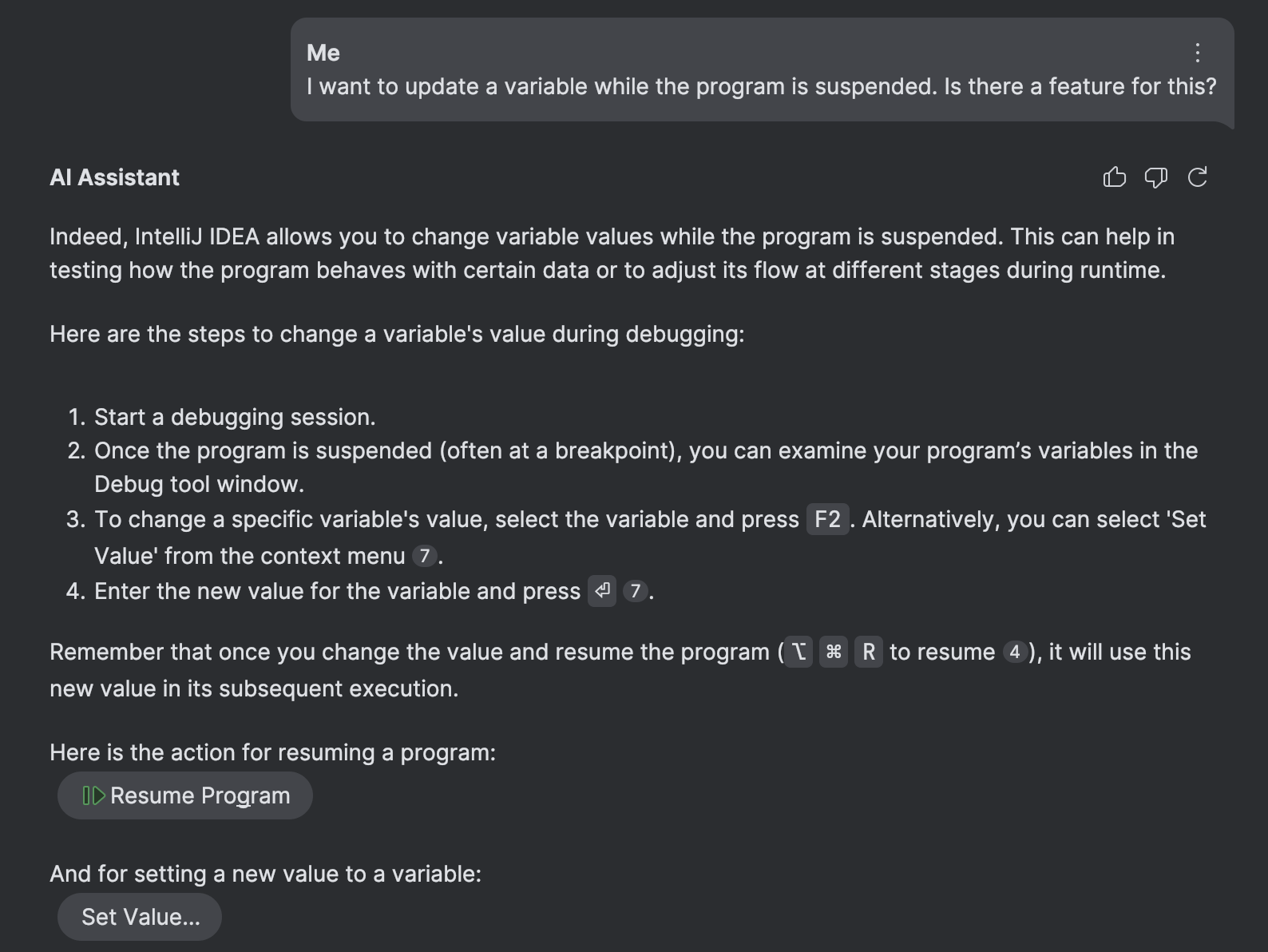
To demonstrate the importance of indexing the enclosing element’s content, let’s use IntelliJ IDEA’s Set Value feature as an example. This feature lets you update variables while the program is suspended in debug mode.
The ID for the corresponding action is SetValue .
However, this ID in isolation isn’t particularly descriptive.
Given that SetValue and lots of other IDs are rather generic word combinations in programming,
a semantic search based solely on these IDs will result in
an unacceptable share of both false positives and negatives.
Without including additional context in the index,
the task becomes practically impossible.
In contrast, by establishing the relationship between the action ID and the surrounding content, we provide AI Assistant with details about the exact functionality, its common use-cases, and limitations. This information significantly increases the accuracy of retrieval:
The client part
Finally, once AI Assistant has the correct action ID, it can suggest this action and even display a button to invoke it right from the chat:

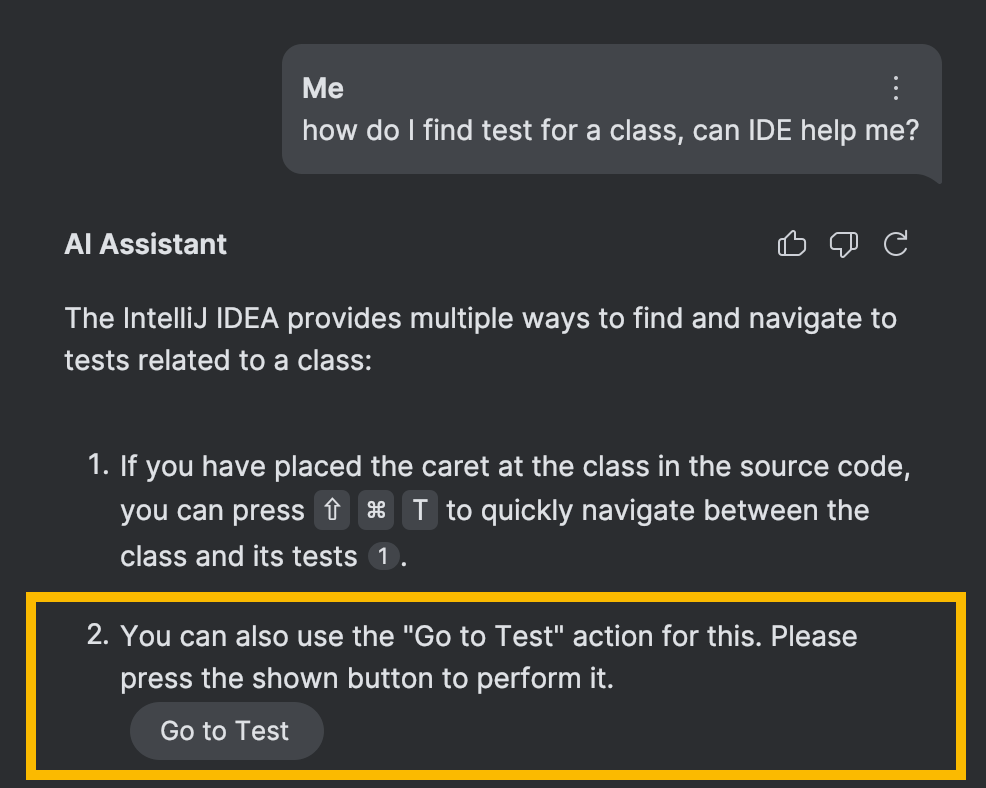
Of course, this part is slightly more complex than simply adding a button to the UI. Given that IDE actions are context-dependent, there are additional checks that need to be implemented, but this topic is very specific to IntelliJ Platform development and warrants a separate discussion of its own.
Other markup elements
In this post, we have primarily focused on the ‘action search’ feature, which works by retrieving
action IDs from Writerside’s <shortcut> tag.
However, you can apply the same principles to many other element types within semantic markup.
Just a quick example using the ui-path element. This element denotes series of UI elements, such as menu items, that one needs to navigate through in order to access the described functionality.
<step>
Open the IDE settings (<shortcut key="ShowSettings"/>),
then navigate to <ui-path>Tools | Terminal</ui-path>.
</step>It makes perfect sense to provide long paths in web help, because direct navigation from a web page to the product isn’t typically practical. On the other hand, when a user asks about this in the product, there is no reason not to show the corresponding settings page right away:


Summary
A while ago, many envisioned the concept of Web 3.0. The idea was to move the entire web to semantic markup, so that machines could use it just like people. Although this didn’t happen, it’s interesting how the same ideas are becoming relevant again, now from the perspective of modern tools and techniques.
The feature that I covered in this article is just one example of how you can leverage your existing good practices, such as semantic markup, with Gen AI systems. There are many more to explore. If you’re particularly interested in RAG, here’s an excellent collection of tutorials on retrieval-augmented generation.
Did you enjoy the article? Do you like experimenting with Gen AI? Even though my blog does not have a comments section, I would still be happy to hear about your perspective and use-cases, so don’t hesitate to reach out using the contacts in the footer.
See you soon!