Localizador de Duplicatas para Texto
Outras línguas: English Español Français Deutsch 日本語 한국어 中文

Qualquer pessoa que tenha trabalhado em documentação técnica em uma grande equipe certamente está ciente do problema de duplicação de conteúdo . Mesmo com as melhores ferramentas e práticas, a duplicação é fundamentalmente difícil de superar

À medida que o projeto cresce, o conteúdo duplicado começará a ocorrer. Isso é especialmente verdadeiro para grandes projetos que incluem muitos produtos ou recursos semelhantes.
<p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p><TroubleshootingNote/><p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>
<!-- same meaning, slightly different wording-->
<p>
In case of problems, consult the troubleshooting guide
or contact support
</p>A ideia que advoga contra a duplicação é comumente conhecida como Princípio DRY (Don’t Repeat Yourself). Embora esteja principalmente associado à programação, a mesma propriedade é muito valorizada na documentação.
Introdução ao projeto
As ferramentas modernas de autorização normalmente têm recursos para reutilização de conteúdo, tornando as restrições técnicas menos uma preocupação. O problema real, por outro lado, está em identificar duplicatas. Antes de extrair algo para um bloco reutilizável, você precisa saber o que extrair.
Se você é um programador, seu IDE pode realçar o código duplicado para você:
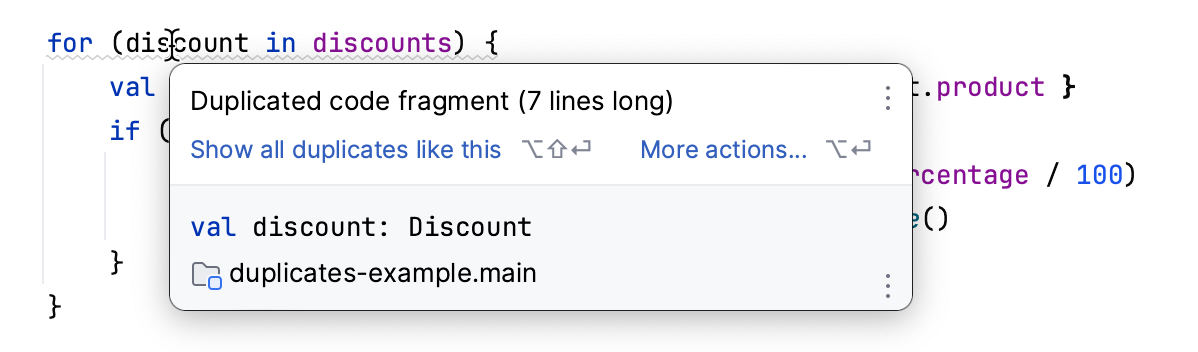
Infelizmente, o mesmo recurso não é adequado para documentação, pois depende de comparar árvores de sintaxe abstratas (AST). Essa abordagem não funciona bem com texto.
Um dos meus projetos em andamento é implementar um localizador de duplicatas para documentação. A ferramenta será capaz de encontrar rapidamente correspondências não exatas, ou fuzzy, como o exemplo ruim acima.
Estado atual
No momento da escrita, o projeto está em andamento, mas já existe um protótipo funcional:
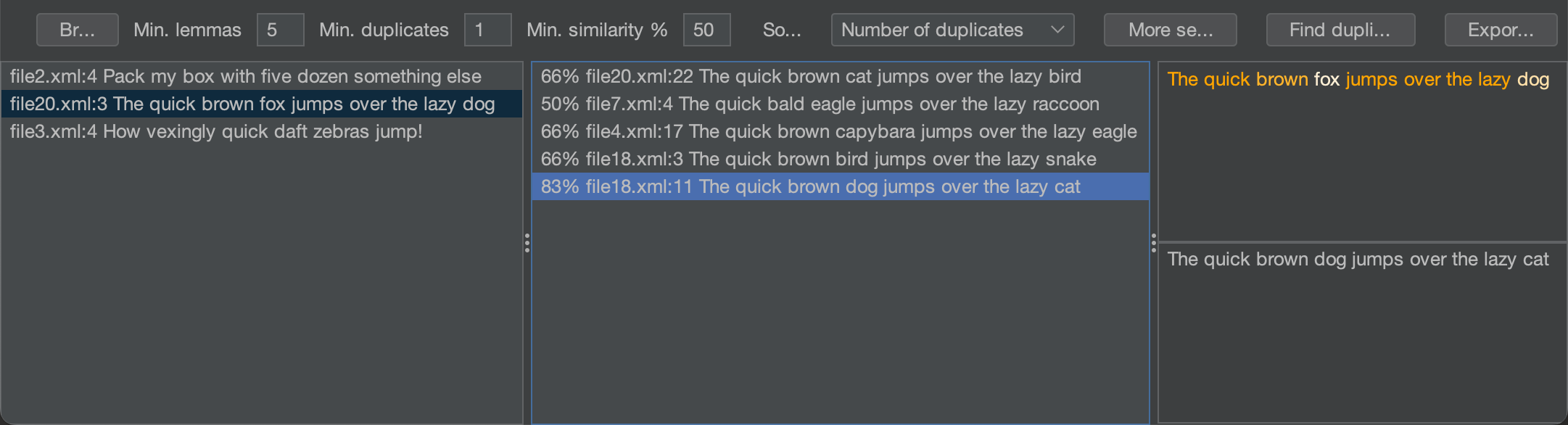
O algoritmo demora menos de 30 segundos para analisar um projeto com ~6k arquivos de origem no meu MBP M1, e planejo aprimorá-lo para destacar instantaneamente as duplicatas enquanto você digita no editor.
O protótipo já me ajudou e aos meus colegas encontrar muitas duplicatas em projetos reais, então eu estou bastante entusiasmado com os resultados e melhorias futuras.
Próximos passos
Nos próximos posts, detalharei o algoritmo passo a passo e realizarei benchmarks para avaliar seu desempenho. Se você gosta de programação, fique à vontade para acompanhar.
Alternativamente, você pode acompanhar o progresso e usar o produto final quando o projeto estiver concluído. Uma vez finalizado, este recurso estará disponível no Writerside, uma ótima ferramenta de autorização feita por meus colegas.
Espero que a descrição do projeto ressoe com você e que você ache o tutorial útil.
Te vejo nos próximos posts!