Localizador de texto duplicado: Requisitos
Outras línguas: English Español Français Deutsch 日本語 한국어 中文

Já faz um tempo desde que publiquei a introdução ao projeto do localizador de duplicatas, então parece o momento certo para informar sobre o progresso. Antes de começar a escrever o código do programa, faz sentido determinar os requisitos primeiro. Uma boa maneira de fazer isso é escrevendo testes. Não apenas os testes nos ajudarão a desenvolver mais rápido, mas eles também garantirão que o código está aderente à especificação.

Requisitos
Nesta seção, formulei minha ideia das características principais do localizador de duplicatas. Estas funcionam bem para as minhas aplicações. No entanto, como cada projeto pode ter necessidades diferentes, ficaria feliz em ouvir e implementar suas ideias.
Detectando correspondências exatas e aproximadas
A ferramenta de detecção de duplicatas deve ser capaz de encontrar correspondências exatas e aproximadas com granularidade até símbolos individuais. Por exemplo, ela deve identificar os seguintes textos como similares:
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.Além disso, no caso de duplicatas aproximadas, o grau de semelhança deve ser mensurável. Isso nos permitirá avaliar rapidamente os pares de duplicatas e classificá- los de acordo com a semelhança dos fragmentos de texto.
Independente de idioma
Dada a infinidade de idiomas alvo potenciais, seria bom oferecer suporte a tantos quanto possível. Algumas abordagens podem exigir manutenção separada para cada idioma adicionado, o que é nada escalável e requer muitos recursos. Idealmente, a ferramenta deve usar algum algoritmo intuitivo ou independente de idioma para compatibilidade com qualquer idioma comum.
Configurável
Os critérios para identificar duplicatas devem ser ajustáveis, com configurações do tipo:
- o comprimento dos fragmentos de texto analisados
- o número de duplicatas
- o grau de semelhança
Geralmente, quanto mais longa e mais frequentemente repetida uma seção, mais vantajoso é deduplicá-la. No entanto, isso depende da aplicação específica, então seria bom ter controle sobre esses limiares.
Definições
Com os requisitos básicos definidos, é hora de colocar as definições de código em prática. Nesta fase, precisaremos de:
- a unidade básica de texto que representará as duplicatas potenciais
- a interface para o localizador de duplicatas
O código deste capítulo não precisa ser abrangente e prever todos os usos futuros – sempre podemos voltar para fazer ajustes.
Chunk
Quando se trata de uma unidade de texto, quais detalhes são importantes para nós? Para nossos propósitos, eu fico com o texto que um fragmento contém, o caminho para o arquivo que o contém, seu número de linha, e o tipo do elemento – caso a fonte não seja apenas texto simples:
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)Essa definição não leva em consideração alguns detalhes. Por exemplo, podemos deixar de fora o
campo content .
Isso nos economizaria alguma RAM, mas a compensação seria a velocidade de acesso ao conteúdo do elemento,
porque então o programa teria que lê-lo do disco todas as vezes, em vez de apenas uma.
Não estamos lutando por performance agora, então uma escolha potencialmente subótima está ok.
Interface
Ainda não temos uma implementação, então vamos programar contra uma interface. A interface define o que nossa função deve receber como entrada e o que deve retornar como saída, nos abstraindo dos detalhes internos da função. Isso efetivamente cria um contrato, permitindo-nos escrever testes agora, sem codificar o algoritmo real. No futuro, isso também tornará as implementações alternativas compatíveis com os testes e código de cliente existentes.
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}Aqui está o significado dos parâmetros que a interface aceita:
-
root– a pasta com o conteúdo a ser analisado -
minSimilarity– a porcentagem mínima de semelhança para dois objetosChunkserem considerados duplicatas -
minLength– comprimento mínimo docontentpara umChunkser analisado -
minDuplicates– número mínimo de duplicatas para que um cluster de duplicatas seja relatado -
fileExtensions– máscara de extensão de arquivo para filtrar arquivos irrelevantes
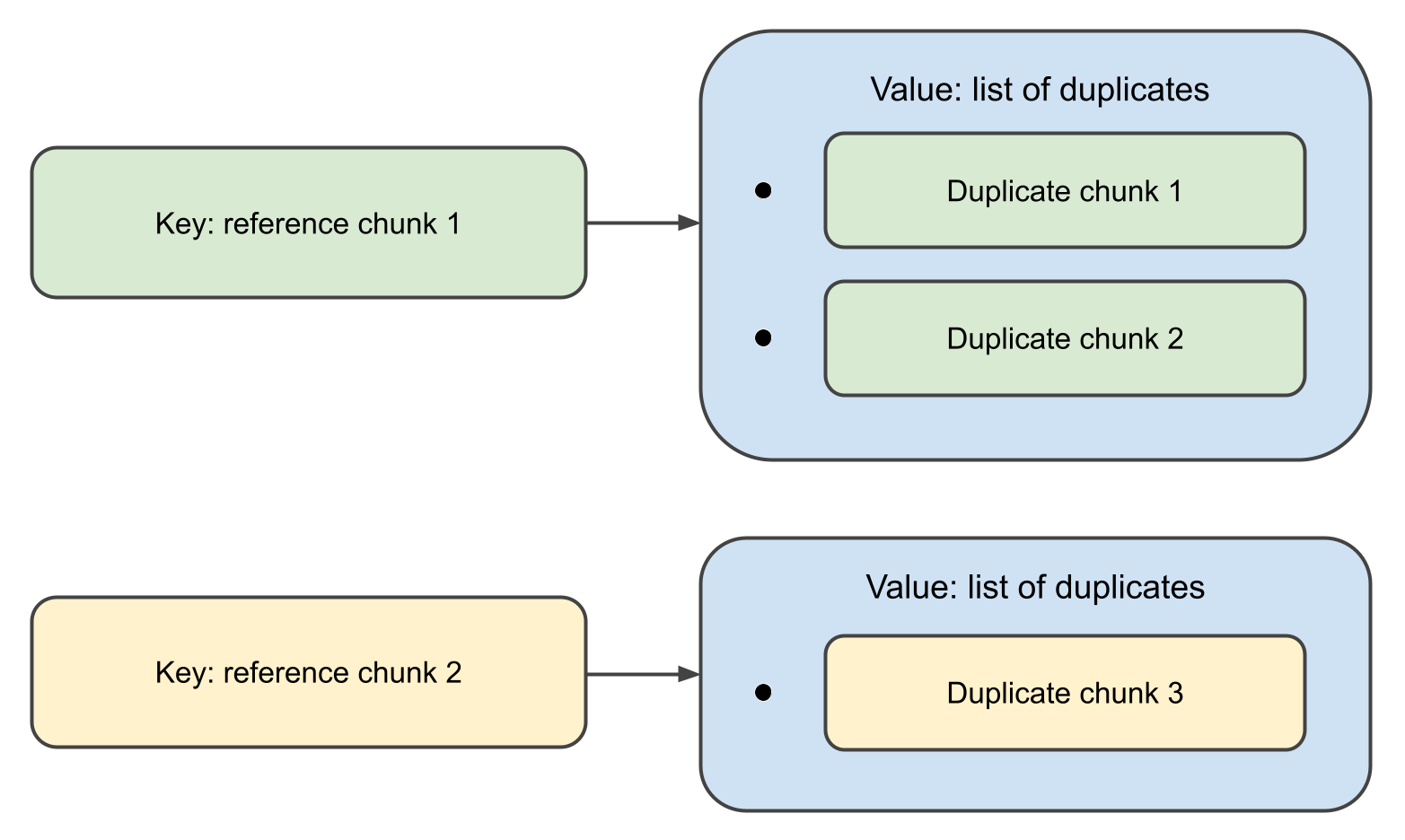
Quando a função completa, ela retornará um mapa,
onde as chaves são objetos Chunk e os valores associados são listas de suas duplicatas.
Na verdade, a definição acima é desnecessariamente verbosa. Introduzir uma interface apenas para uma única função e alguns chamadores é demais. Kotlin tem uma maneira elegante de lidar com isso usando funções de primeira classe:
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()Esta declaração significa que o localizador de duplicatas é uma função que recebe
Path, DuplicateFinderOptions e retorna
Map<Chunk, List<Chunk>> ,
e que a função em si ainda não está implementada.
Isso pode não ser o melhor estilo para projetos grandes, mas em menores como o nosso,
funciona muito bem.
Dados de teste
Como o localizador de duplicatas deve trabalhar com dados de texto, os testes também precisarão de textos para analisar. Isso significa que precisamos preparar alguns exemplos contendo duplicatas aproximadas. Vamos começar com as duplicatas:
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes."A ideia por trás do FUZZY_MATCH_TEMPLATE
é que usaremos isso para produzir programaticamente as correspondências aproximadas reais:
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)Em seguida, geraremos um texto composto de palavras aleatórias em inglês:
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}Por fim, injetaremos aleatoriamente a EXACT_MATCH
e as fuzzyMatches no texto gerado:
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}Testes
Como já mencionado, o objetivo principal dos testes nesta etapa é definir a especificação, então não vamos perder muito tempo aperfeiçoando o conjunto de testes. Em vez disso, escreveremos o suficiente para garantir que o código futuro esteja de acordo com os requisitos.
Este é o código da classe de teste:
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }Próximos passos
Estabelecemos os requisitos definindo a interface e escrevendo os testes. No próximo post da série, implementaremos o algoritmo real e veremos como ele se sai. Até breve!