Localizar Aplicações com IA
Outras línguas: English Español Français Deutsch 日本語 한국어 中文
Se você está pensando em localizar seu projeto ou apenas aprendendo como fazer isso, a IA pode ser um bom ponto de partida. Ela oferece um ponto de entrada custo-eficiente para experimentos e automações.
Neste post, vamos fazer um desses experimentos. Nós vamos:
- escolher uma aplicação open-source
- revisar e implementar os pré-requisitos
- automatizar a etapa de tradução usando IA

Se você nunca lidou com localização e gostaria de aprender, pode ser uma boa ideia começar aqui. Exceto por alguns detalhes técnicos, a abordagem é amplamente universal, e você pode aplicá-la em outros tipos de projetos.
Se você já está familiarizado com o básico e só quer ver a IA em ação, você pode querer pular para Traduza os textos ou clonar meu fork para passar pelos commits e avaliar os resultados.
Pegue o projeto
Criar uma aplicação só para um experimento de localização seria exagero, então vamos fazer um fork de algum projeto open-source. Eu escolhi Spring Petclinic, um exemplo de aplicação web que é usado para mostrar o framework Spring para Java.
gh repo fork https://github.com/spring-projects/spring-petclinic --clone=trueSe você nunca usou Spring antes, alguns trechos de código podem não ser familiares para você, mas, como eu já mencionei, esta discussão é agnóstica em relação à tecnologia. Os passos são mais ou menos os mesmos, independente da linguagem e do framework.
Internacionalização
Antes que uma aplicação possa ser localizada, ela tem que ser internacionalizada.
Internacionalização (também conhecida como i18n) é o processo de adaptar o software para suportar diferentes idiomas. Normalmente começa com a externalização das strings da UI para arquivos especiais, comumente conhecidos como bundles de recursos.
Bundles de recursos contêm os valores de texto para diferentes idiomas:
en.json:
{
"greeting": "Hello!",
"farewell": "Goodbye!"
}es.json:
{
"greeting": "¡Hola!",
"farewell": "¡Adiós!"
}Para que esses valores cheguem à UI, a UI deve ser explicitamente programada para usar esses arquivos.
Isso normalmente envolve uma biblioteca de internacionalização ou um recurso embutido na linguagem, cujo propósito é substituir os textos da UI com os valores corretos para um dado local. Exemplos de tais bibliotecas incluem i18next (JavaScript), Babel (Python), e go-i18n (Go).
Java suporta internacionalização fora da caixa, então não precisamos trazer dependências adicionais para o projeto.
Examine as fontes
O Java usa arquivos com a extensão .properties para armazenar strings localizadas para a interface do usuário.
Felizmente, já temos um monte deles no projeto. Por exemplo, aqui está o que temos para Inglês e Espanhol:
welcome=Welcome
required=is required
notFound=has not been found
duplicate=is already in use
nonNumeric=must be all numeric
duplicateFormSubmission=Duplicate form submission is not allowed
typeMismatch.date=invalid date
typeMismatch.birthDate=invalid datewelcome=Bienvenido
required=Es requerido
notFound=No ha sido encontrado
duplicate=Ya se encuentra en uso
nonNumeric=Sólo debe contener numeros
duplicateFormSubmission=No se permite el envío de formularios duplicados
typeMismatch.date=Fecha invalida
typeMismatch.birthDate=Fecha invalidaA externalização das strings da UI não é algo que todos os projetos fazem universalmente. Alguns projetos podem ter esses textos diretamente codificados na lógica da aplicação.

A externalização das strings da UI é uma boa prática com vantagens além da internacionalização. Ela torna o código mais fácil de manter e promove consistência nas mensagens da UI. Se você está começando um projeto, considere implementar i18n o mais cedo possível.
Teste executado
Vamos adicionar uma forma de alterar o local através de parâmetros de URL. Isso nos permitirá testar se tudo está totalmente externalizado e traduzido para pelo menos um idioma.
Para alcançar isso, adicionamos a seguinte classe para gerenciar o parâmetro local:
import java.util.Locale;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public LocaleResolver localeResolver() {
SessionLocaleResolver slr = new SessionLocaleResolver();
slr.setDefaultLocale(Locale.US);
return slr;
}
@Bean
public LocaleChangeInterceptor localeChangeInterceptor() {
LocaleChangeInterceptor lci = new LocaleChangeInterceptor();
lci.setParamName("lang");
return lci;
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(localeChangeInterceptor());
}
}Agora que podemos testar diferentes locais, rodamos o servidor, e comparamos a página inicial para vários parâmetros locais:
- http://localhost:8080 – local padrão
- http://localhost:8080/?lang=es – Espanhol
- http://localhost:8080/?lang=ko – Coreano
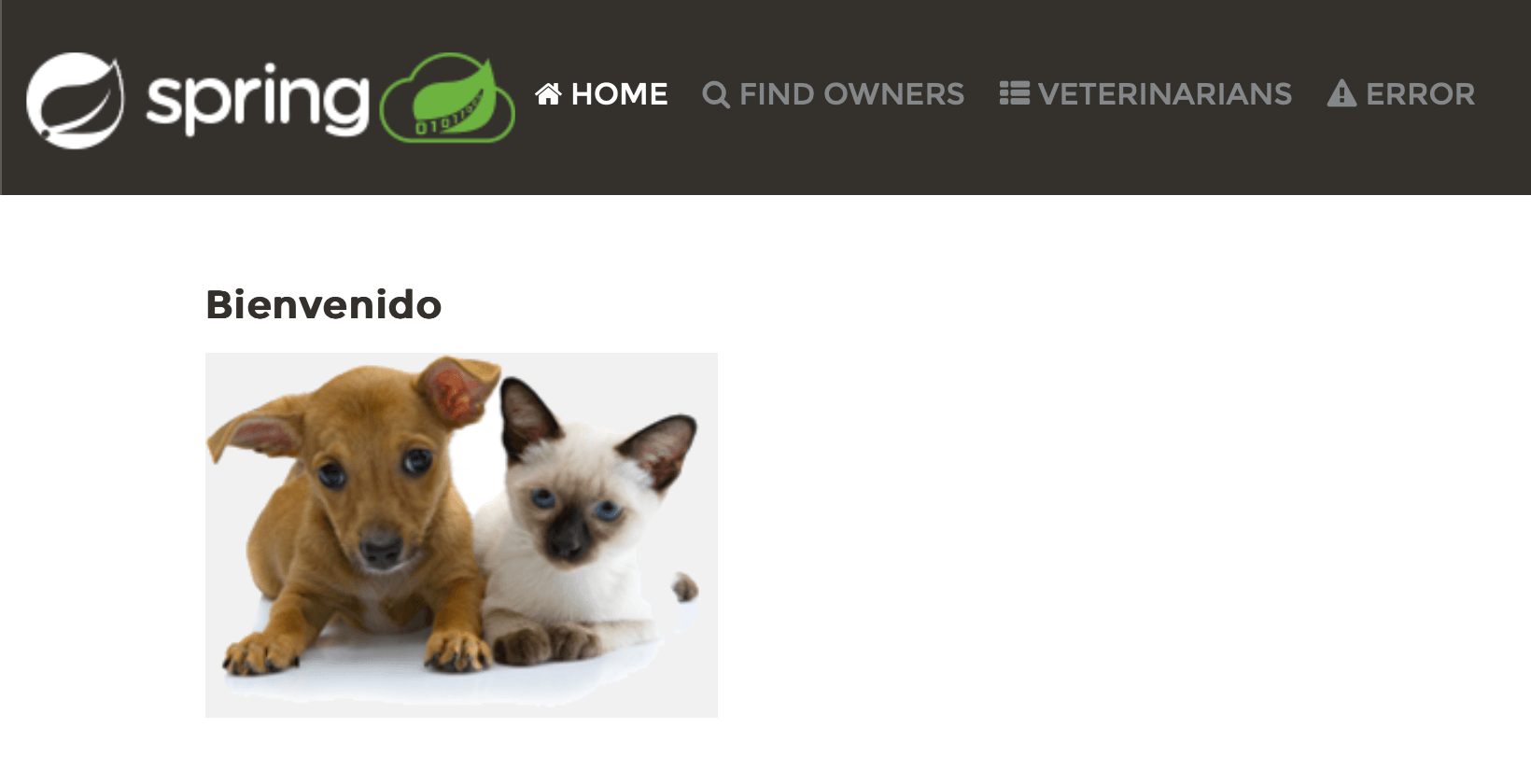
A alteração do local é refletida na UI, o que é uma boa notícia. No entanto, parece que a mudança do local só afetou uma parte dos textos. Para o Espanhol, Welcome mudou para Bienvenido, mas os links no cabeçalho permaneceram os mesmos, e as outras páginas ainda estão em inglês. Isso significa que temos algum trabalho a fazer.
Modificar modelos
O projeto Spring Petclinic gera páginas usando modelos Thymeleaf, então vamos inspecionar os arquivos de modelos.
De fato, alguns dos textos estão codificados, então precisamos modificar o código para se referir aos bundles de recursos ao invés disso.
Felizmente, Thymeleaf tem bom suporte para arquivos .properties do Java,
então podemos incorporar referências para as chaves do bundle de recursos correspondente direto no modelo:
<h2>Find Owners</h2><h2 th:text='#{heading.find.owners}'>Find Owners</h2>heading.find.owners=Find OwnersO texto anteriormente codificado ainda está lá, mas agora ele serve como um valor fallback, que só será usado se houver um erro ao buscar a mensagem localizada apropriada.
O restante dos textos são externalizados de maneira semelhante; no entanto, há vários lugares que requerem atenção especial. Por exemplo, alguns dos avisos vêm do mecanismo de validação e têm que ser especificados usando parâmetros de anotação do Java:
@Column(name = "first_name")
@NotBlank
private String firstName;@Column(name = "first_name")
@NotBlank(message = "{field.validation.notblank}")
private String firstName;Em alguns lugares, a lógica tem que ser alterada:
<h2>
<th:block th:if="${pet['new']}">New </th:block>Pet
</h2>No exemplo acima, o modelo usa uma condição. Se o atributo new estiver presente,
New é adicionado ao texto da UI.
Consequentemente, o texto resultante é ou New Pet ou Pet dependendo da presença do atributo.
Isso pode quebrar a localização para alguns locais, por causa do acordo
entre o substantivo e o adjetivo. Por exemplo, em Espanhol, o adjetivo seria
Nuevo ou Nueva
dependendo do gênero do substantivo, e a lógica existente não conta com essa distinção.
Uma possível solução para esta situação é fazer a lógica ainda mais sofisticada. Geralmente é uma boa ideia se afastar de lógicas complicadas sempre que possível, então eu fui com a separação dos ramos ao invés disso:
<h2>
<th:block th:if="${pet['new']}" th:text="#{pet.new}">New Pet</th:block>
<th:block th:unless="${pet['new']}" th:text="#{pet.update}">Pet</th:block>
</h2>Ramos separados também simplificarão o processo de tradução e a manutenção futura do código.
O formulário New Pet tem um truque também. Seu dropdown Type é criado passando a coleção de tipos de animais para o modelo selectField.html :
<input th:replace="~{fragments/selectField :: select (#{pet.type}, 'type', ${types})}" />Diferentemente dos outros textos da UI, os tipos de pets são parte do modelo de dados da aplicação. Eles são originados de um banco de dados em tempo de execução. A natureza dinâmica desses dados nos impede de extrair diretamente os textos para um bundle de recursos.
Há novamente várias maneiras de lidar com isso. Uma maneira é construir dinamicamente a chave do bundle de recursos no modelo:
<option th:each="item : ${items}"
th:value="${item}"
th:text="${item}">dog</option><option th:each="item : ${items}"
th:value="${item}"
th:text="#{'pettype.' + ${item}}">dog</option>Nessa abordagem, em vez de renderizar diretamente cat na UI, prefixamos com pettype. , que resulta em
pettype.cat . Então usamos essa string como uma chave para buscar o texto da UI localizado:
pettype.bird=bird
pettype.cat=cat
pettype.dog=dogpettype.bird=pájaro
pettype.cat=gato
pettype.dog=perro
Você pode ter notado que acabamos de modificar o template de um componente reutilizável. Como os componentes reutilizáveis são destinados a atender vários clientes, não é correto trazer a lógica do cliente para eles.
Neste caso específico, o componente de lista suspensa fica ligado aos tipos de animais de estimação, o que é problemático para qualquer pessoa que queira usá-lo para qualquer outra coisa.
Esse defeito estava lá desde o início - veja dog como o texto padrão das opções.
Nós apenas propagamos esse defeito ainda mais.
Isso não deve ser feito em projetos reais e precisa de refatoração.
Obviamente, há mais código de projeto para internacionalizar; no entanto, o resto dele está alinhado com os exemplos acima. Para uma revisão completa de todas as minhas mudanças, você está convidado a examinar os commits no meu fork.
Adicione chaves ausentes
Depois de substituir todo o texto da UI por referências às chaves do conjunto de propriedades, devemos nos certificar de introduzir todas essas novas chaves. Não precisamos traduzir nada neste ponto, basta adicionar as chaves e textos originais ao arquivo messages.properties .
IntelliJ IDEA suporta bem Thymeleaf. Ele detecta se um template faz referência a uma propriedade ausente, então você pode identificar os que estão faltando sem muita verificação manual:
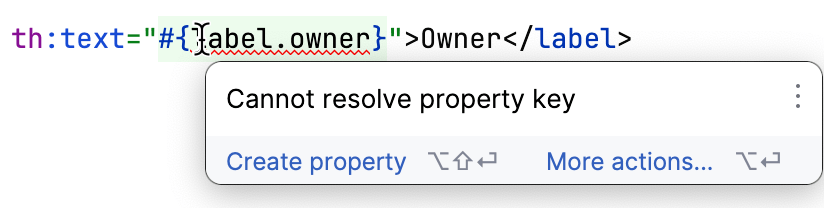
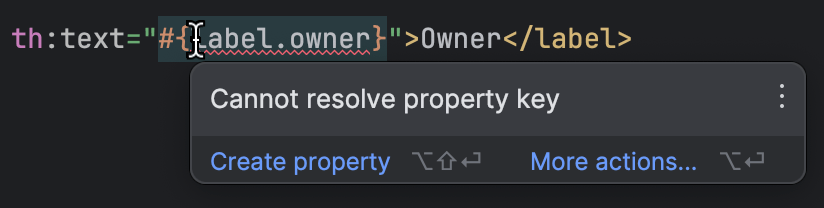
Com todas as preparações feitas, chegamos à parte mais interessante do trabalho. Temos todas as chaves, e temos todos os valores para o inglês. De onde obtemos valores para os outros idiomas?
Traduza os textos
Para traduzir os textos, criaremos um script que usa um serviço de tradução externo. Há muitos serviços de tradução disponíveis, e muitas maneiras de escrever um script desse tipo. Eu fiz as seguintes escolhas para a implementação:
- Python como linguagem de programação, porque permite programar tarefas pequenas muito rapidamente.
- DeepL como serviço de tradução. Originalmente, eu planejava usar o GPT3.5 Turbo da OpenAI, mas como ele não é estritamente um modelo de tradução, requer um esforço extra para configurar o prompt. Além disso, os resultados tendem a ser menos estáveis, então escolhi um serviço de tradução dedicado que surgiu primeiro na minha cabeça.
Eu não fiz uma pesquisa extensa, então essas escolhas são um pouco arbitrárias. Sinta-se à vontade para experimentar e descobrir o que melhor se adapta a você.
Se você decidir usar o script abaixo, precisa criar uma conta no DeepL
e passar a sua chave API pessoal para o script através da variável de ambiente DEEPL_KEY
Este é o script:
import os
import requests
import json
deepl_key = os.getenv('DEEPL_KEY')
properties_directory = "../src/main/resources/messages/"
def extract_properties(text):
properties = {}
for line in text:
line = line.strip()
if line and not line.startswith('#') and '=' in line:
key_value = line.split('=')
key = key_value[0].strip()
value = key_value[1].strip()
if key and value:
properties[key] = value
return properties
def missing_properties(properties_file, properties_checklist):
with open(properties_file, 'r') as f:
text = f.readlines()
present_properties = extract_properties(text)
missing = {k: v for k, v in properties_checklist.items() if k not in present_properties.keys()}
return missing
def translate_property(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'DeepL-Auth-Key {deepl_key}',
'User-Agent': 'LocalizationScript/1.0'
}
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()["translations"][0]["text"]
def populate_properties(file_path, properties_checklist, target_lang):
with open(file_path, 'a+') as file:
properties_to_translate = missing_properties(file_path, properties_checklist)
for key, value in properties_to_translate.items():
new_value = translate_property(value, target_lang)
property_line = f"{key}={new_value}\n"
print(property_line)
file.write(property_line)
with open(properties_directory + 'messages.properties') as base_properties_file:
base_properties = extract_properties(base_properties_file)
languages = [
# configure languages here
"nl", "es", "fr", "de", "it", "pt", "ru", "ja", "zh", "fi"
]
for language in languages:
populate_properties(properties_directory + f"messages_{language}.properties", base_properties, language)
O script extrai as chaves do conjunto de propriedades padrão ( messages.properties ) e busca suas traduções nos bundles específicos do local. Se ele descobre que uma determinada chave está sem tradução, o script solicita a tradução da API do DeepL e adiciona ao conjunto de propriedades.
Eu especifiquei 10 idiomas de destino, mas você pode modificar a lista ou adicionar seus idiomas preferidos, desde que o DeepL suporte-os.
O script pode ser ainda mais otimizado para enviar os textos para tradução em lotes de 50. Eu não fiz isso aqui para manter as coisas simples.
Mais tarde, atualizei o script para usar um LLM com saída estruturada. Você pode verificar os resultados aqui.
Execute o script
Executar o script em 10 idiomas levou cerca de 5 minutos para mim. O painel de uso mostra 8348 caracteres, que teriam custado € 0,16 se estivéssemos em um plano pago.
Como resultado, os seguintes arquivos aparecem:
- messages_fi.properties
- messages_fr.properties
- messages_it.properties
- messages_ja.properties
- messages_nl.properties
- messages_pt.properties
- messages_ru.properties
- messages_zh.properties
Além disso, propriedades ausentes são adicionadas a:
- messages_de.properties
- messages_es.properties
Mas e as traduções reais? Já podemos vê-las?
Verifique os resultados
Vamos reiniciar o aplicativo e testá-lo usando diferentes valores do parâmetro lang . Por exemplo:
- http://localhost:8080/?lang=es
- http://localhost:8080/?lang=nl
- http://localhost:8080/?lang=zh
- http://localhost:8080/?lang=fr
Pessoalmente, acho muito satisfatório ver cada página devidamente localizada. Nós nos esforçamos um pouco, e agora está dando certo:

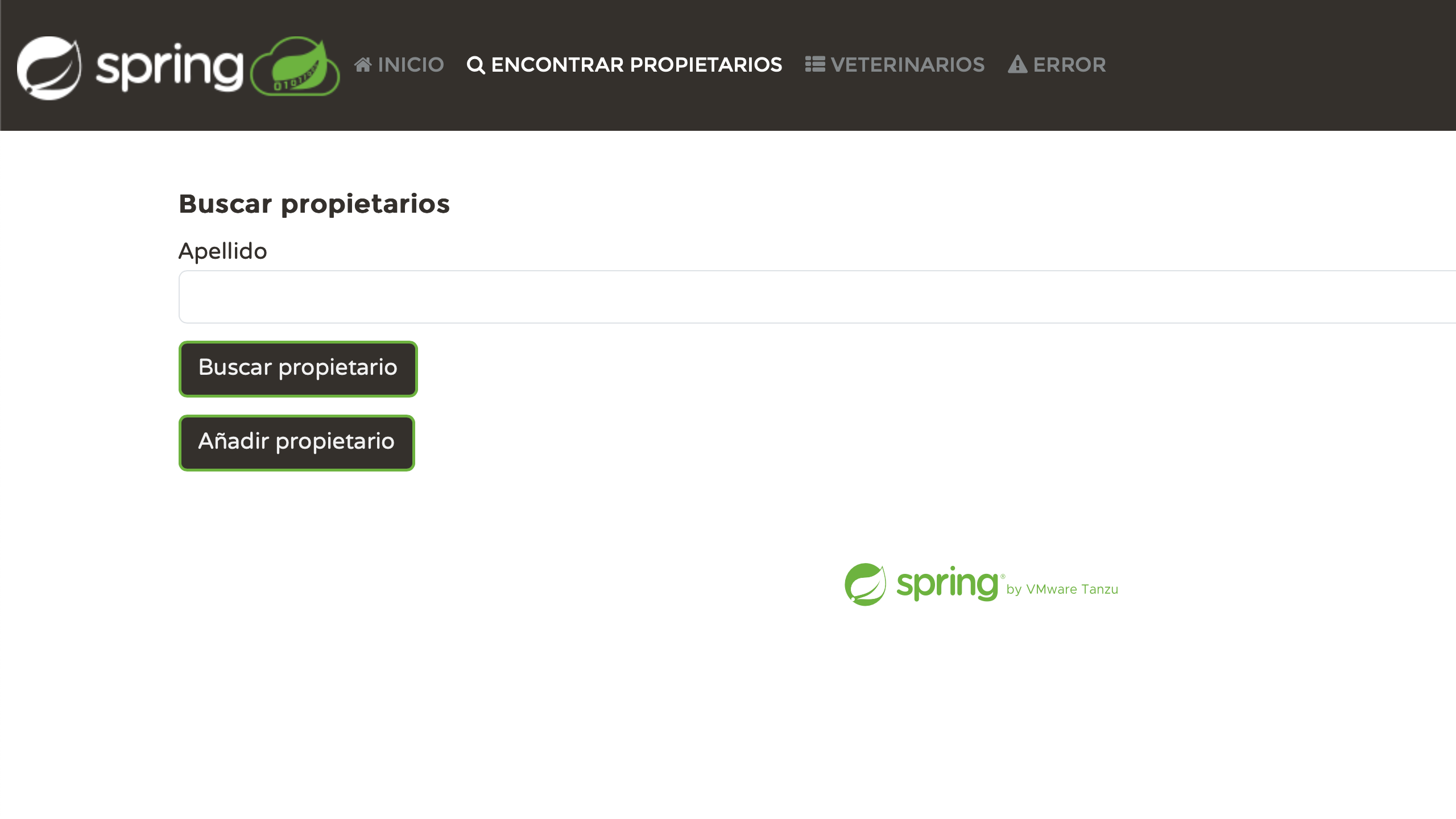
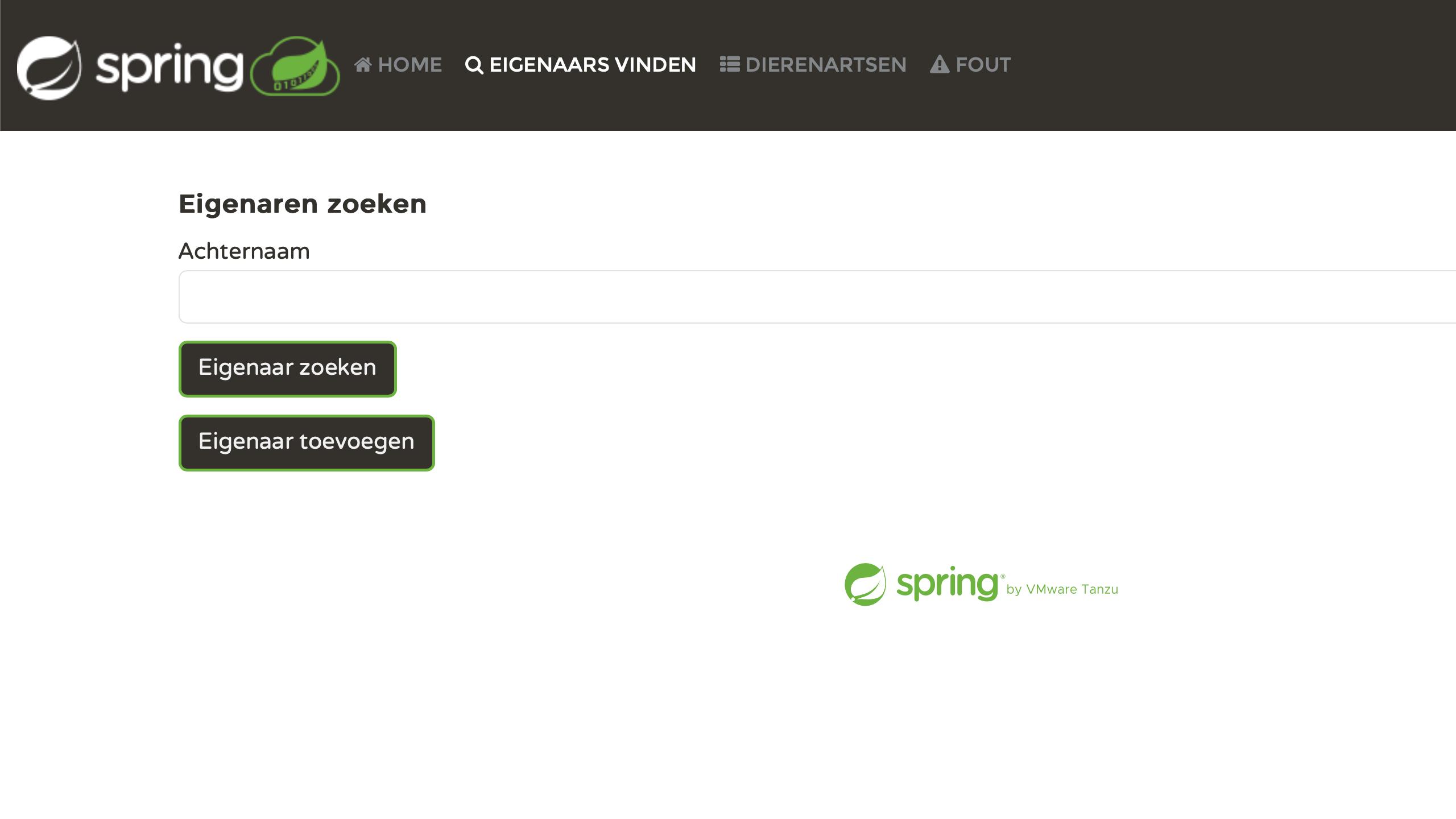

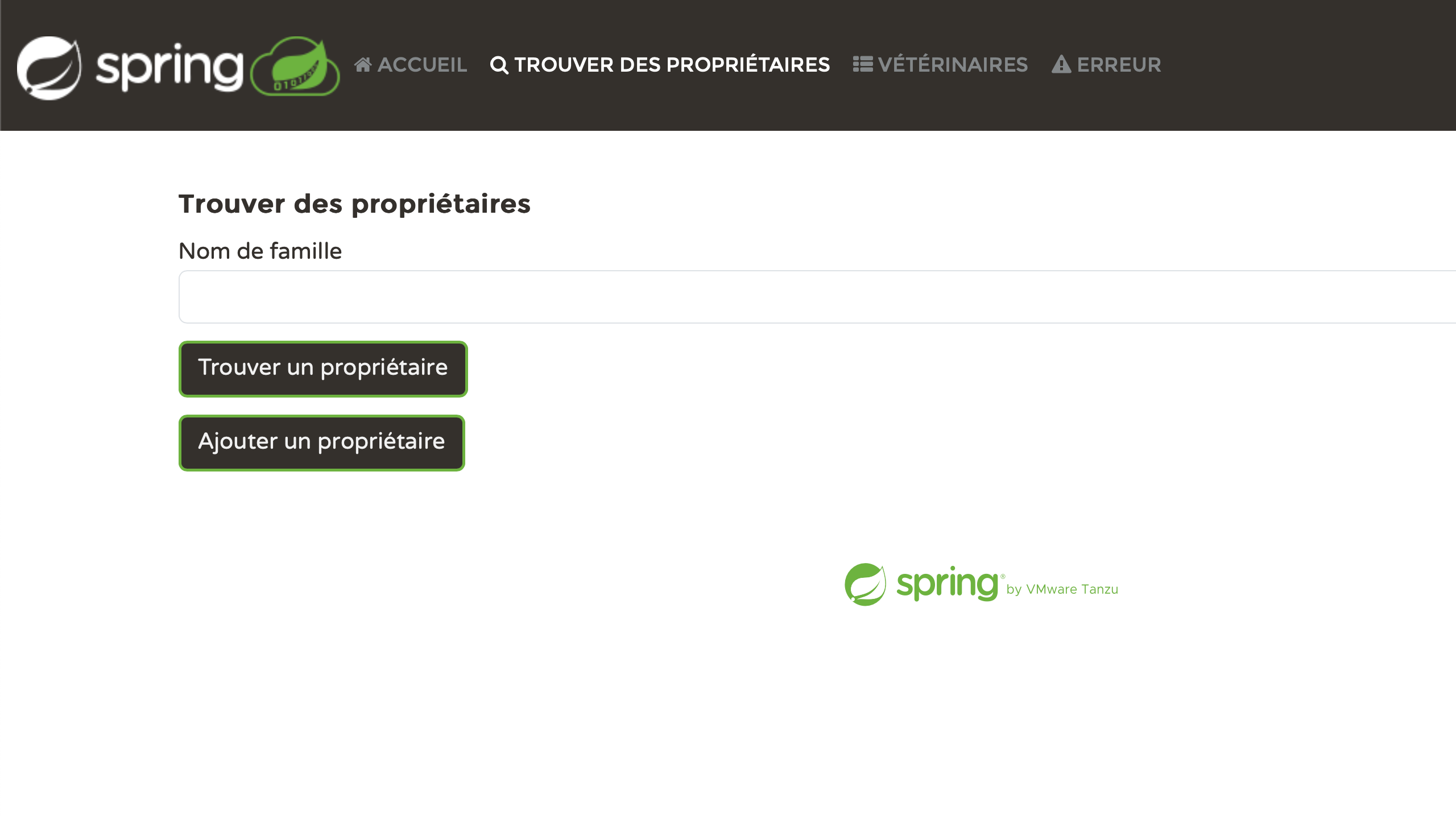
Resolva os problemas
Os resultados são impressionantes. No entanto, se você observar de perto, poderá descobrir erros que surgem devido à falta de contexto. Por exemplo:
visit.update = Visit Visit pode ser um substantivo ou um verbo. Sem contexto adicional, o serviço de tradução produz uma tradução incorreta em alguns idiomas.
Isso pode ser resolvido por meio de edição manualmente ou ajustando o fluxo de trabalho de tradução. Uma possível solução é fornecer contexto nos arquivos .properties usando comentários:
# Noun. Heading. Displayed on the page that allows the user to edit details of a veterinary visit
visit.update = VisitPodemos então modificar o script de tradução para analisar esses comentários e passá-los com
o parâmetro context :
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True,
'context': context
}Conforme aprofundamos e consideramos mais idiomas, podemos descobrir mais coisas que precisam ser melhoradas. Este é um processo iterativo.
Se há uma coisa que é indispensável neste processo, é a revisão e o teste. Independentemente do fato de melhorarmos a automação ou editarmos seu resultado, descobriremos que é necessário realizar controle de qualidade e avaliação.
Além do escopo
Spring Petclinic é um projeto simples, mas realista, assim como os problemas que acabamos de resolver. Claro, a localização apresenta muitos desafios que estão além do escopo deste artigo, incluindo:
- adaptação de templates às regras gramaticais do idioma alvo.
- formatos de moeda, data e número.
- padrões de leitura diferentes, como RTL
- adaptação da UI para variações no comprimento do texto
Cada um desses tópicos merece um artigo próprio. Se você gostaria de ler mais, ficarei feliz em cobrir esses tópicos em postagens separadas.
Resumo
Bem, agora que terminamos de localizar nosso aplicativo, é hora de refletir sobre o que aprendemos:
- A localização não é apenas sobre traduzir textos - ela também afeta ativos relacionados, subsistemas e processos.
- Embora a IA seja muito eficiente em alguns estágios da localização, a supervisão e o teste humano ainda são necessários para obter os melhores resultados.
- A qualidade das traduções automáticas depende de vários fatores, incluindo a disponibilidade de contexto e, no caso dos LLMs, um prompt bem escrito.
Espero que você tenha gostado deste artigo, e adoraria ouvir sua opinião! Se você tiver perguntas de acompanhamento, sugestões, ou apenas quiser bater papo, não hesite em entrar em contato.
Estou ansioso para vê-lo nas futuras postagens!