文本重复查找器
阅读其他语言: EnglishEspañolFrançaisDeutsch日本語한국어Português
这篇文章是关于开发重复查找工具的。有关下载和使用说明,请参阅 此页面
在大型团队中从事技术文档工作的任何人都肯定了解内容重复的问题。即使手头有最好的工具和实践,克服重复从根本上讲也是相当困难的。
随着项目规模的增长,重复的内容将开始出现。这对于包含许多类似产品或功能的大项目尤其如此。
定义一次:
<p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>其他地方重用:
<TroubleshootingNote/><p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>
<!-- same meaning, slightly different wording-->
<p>
In case of problems, consult the troubleshooting guide
or contact support
</p>反对重复的思想通常被称为DRY原则。尽管它主要与编程相关,但在文档中也高度推崇这一特性。
项目介绍
现代创作工具通常具有内容重用的功能,使得技术约束不再是主要问题。另一方面,真正的挑战在于发现重复内容。在你提取某些内容以供重用之前,你需要知道要提取什么。
如果你是一个程序员,你的IDE可能会为你突出显示重复的代码:
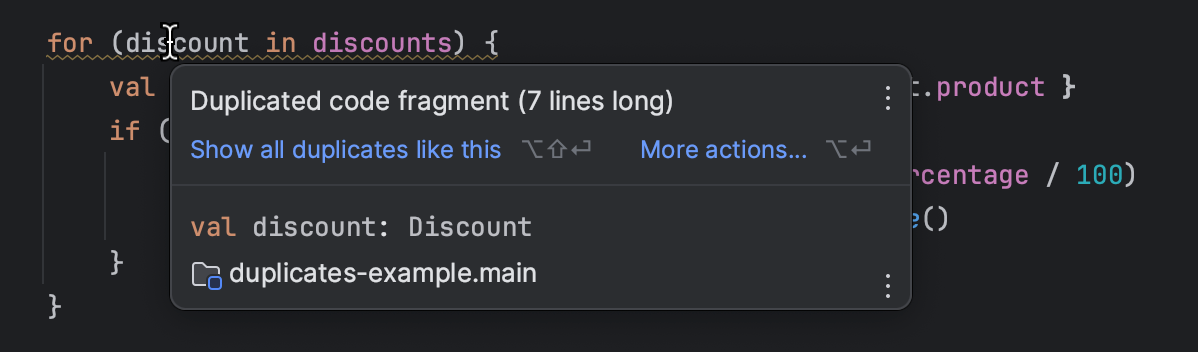
不幸的是,同样的功能不适用于文档,因为它依赖于比较抽象语法树(AST)。这种方法对于文本处理并不理想。
我正在进行的一个项目是实现一个文档用的重复查找器。该工具能够快速找到非精确的,或者说模糊的匹配,比如上面不良做法的例子。
当前进度
撰写本文时,该项目还在进行中,但已经有了一个可工作的原型:
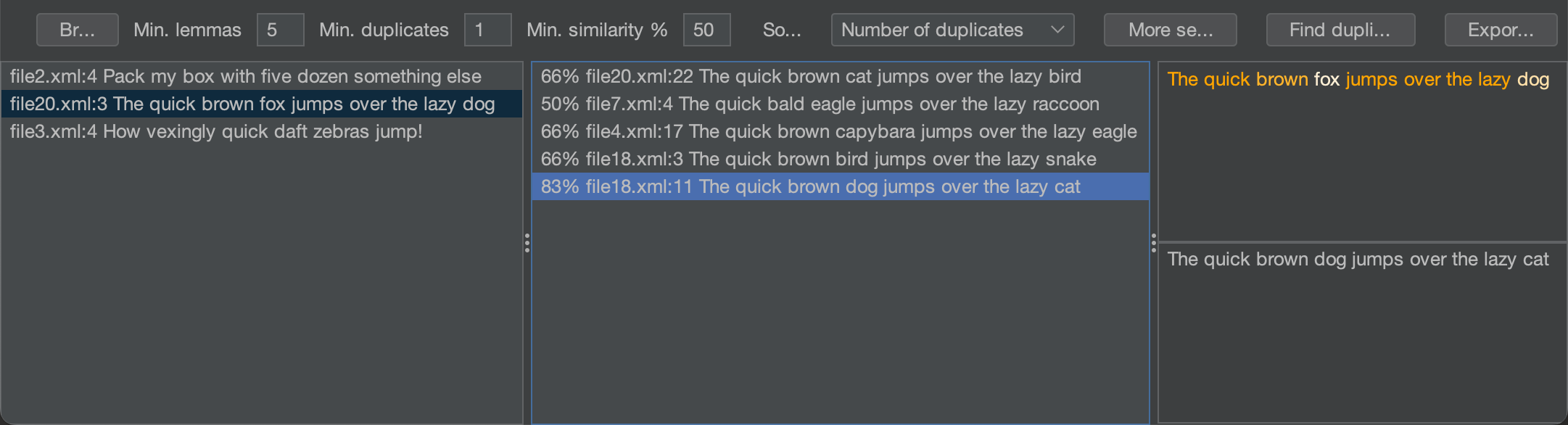
该算法在我的MBP M1上分析大约6千个源文件的项目不到30秒,我计划进一步改进它,以便在编辑器中键入时即时高亮显示重复项。
这个原型已经帮助我和我的同事在实际项目中找到了很多重复内容,因此我对结果和未来的改进感到非常兴奋。
下一步
在接下来的文章中,我将逐步介绍算法,并进行基准测试以评估其性能。如果你对编程感兴趣,欢迎你跟随编码。
或者,你可以关注项目的进展并在项目完成时使用最终成果。一旦完成,此功能将在我的同事们制作的出色写作工具Writerside中可用。
我希望项目描述能引起你的共鸣,你会发现整个过程的讲解很有用。
下篇文章见!