使用AI本地化应用程序
阅读其他语言: English Español Français Deutsch 日本語 한국어 Português
无论您是在考虑将项目进行本地化,还是仅仅在学习如何操作,AI可能是一个不错的起点。 它为实验和自动化提供了成本效益高的入门点。
在本文中,我们将通过一个这样的实验来逐步了解。我们将:
- 选择一个开源应用程序
- 审查并实施先决条件
- 使用AI自动翻译阶段

如果您从未处理过本地化并且想学习,从这里开始可能是个好主意。 除了少数技术细节外,这种方法在很大程度上是通用的, 您可以将其应用于其他类型的项目中。
如果您已经熟悉基础知识,只想看AI的实际应用, 您可以跳转到 翻译文本 或克隆我的 分支,浏览提交 并评估结果。
获取项目
仅仅为了一个本地化实验而创建一个应用程序可能会有些过度, 所以让我们fork一些开源项目。我选择了Spring Petclinic, 这是一个示例Web应用程序,用于展示Spring框架的Java版本。
gh repo fork https://github.com/spring-projects/spring-petclinic --clone=true如果您之前没有使用过Spring,某些代码片段可能对您来说不太熟悉,但正如我已提到的, 这次讨论是与技术无关的。无论使用哪种语言和框架,步骤大致相同。
国际化
在应用程序可以被本地化之前,它必须先进行国际化。
国际化(也拼写为i18n)是调整软件以支持不同语言的过程。 这通常始于将用户界面字符串外部化到特殊文件中,这些文件通常被称为 资源包(resource bundles)。
资源包保存了不同语言的文本值:
en.json:
{
"greeting": "Hello!",
"farewell": "Goodbye!"
}es.json:
{
"greeting": "¡Hola!",
"farewell": "¡Adiós!"
}为了让这些值出现在用户界面中,用户界面必须明确编程以使用这些文件。
这通常涉及一个国际化库或内置的语言功能,其目的是用给定区域设置的正确值替换用户界面文本。 这类库的例子包括 i18next(JavaScript)、Babel(Python)和go-i18n(Go)。
Java本身支持国际化,所以我们不需要为项目引入额外的依赖项。
检查源码
Java使用 .properties 扩展名的文件来存储用户界面的本地化字符串。
幸运的是,项目中已经有一堆这样的文件了。 例如,我们为英语和西班牙语准备了以下内容:
welcome=Welcome
required=is required
notFound=has not been found
duplicate=is already in use
nonNumeric=must be all numeric
duplicateFormSubmission=Duplicate form submission is not allowed
typeMismatch.date=invalid date
typeMismatch.birthDate=invalid datewelcome=Bienvenido
required=Es requerido
notFound=No ha sido encontrado
duplicate=Ya se encuentra en uso
nonNumeric=Sólo debe contener numeros
duplicateFormSubmission=No se permite el envío de formularios duplicados
typeMismatch.date=Fecha invalida
typeMismatch.birthDate=Fecha invalida外部化 UI 字符串并非所有项目都会普遍进行的操作。 某些项目可能将这些文本直接硬编码到应用程序逻辑中。

外部化 UI 文本是一种良好的实践,其优势不仅仅在于国际化。 它使代码更易于维护,并促进 UI 消息的一致性。 如果你正在启动一个项目,考虑尽早实现 i18n。
测试运行
让我们添加一种通过 URL 参数改变区域设置的方式。 这将使我们能够测试是否一切都已完全外部化并至少翻译成一种语言。
为了实现这一点,我们添加以下类来管理区域设置参数:
import java.util.Locale;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public LocaleResolver localeResolver() {
SessionLocaleResolver slr = new SessionLocaleResolver();
slr.setDefaultLocale(Locale.US);
return slr;
}
@Bean
public LocaleChangeInterceptor localeChangeInterceptor() {
LocaleChangeInterceptor lci = new LocaleChangeInterceptor();
lci.setParamName("lang");
return lci;
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(localeChangeInterceptor());
}
}现在我们可以测试不同的区域设置了,我们启动服务器,并比较多个区域设置参数下的主页:
- http://localhost:8080 – 默认区域设置
- http://localhost:8080/?lang=es – 西班牙语
- http://localhost:8080/?lang=ko – 韩语
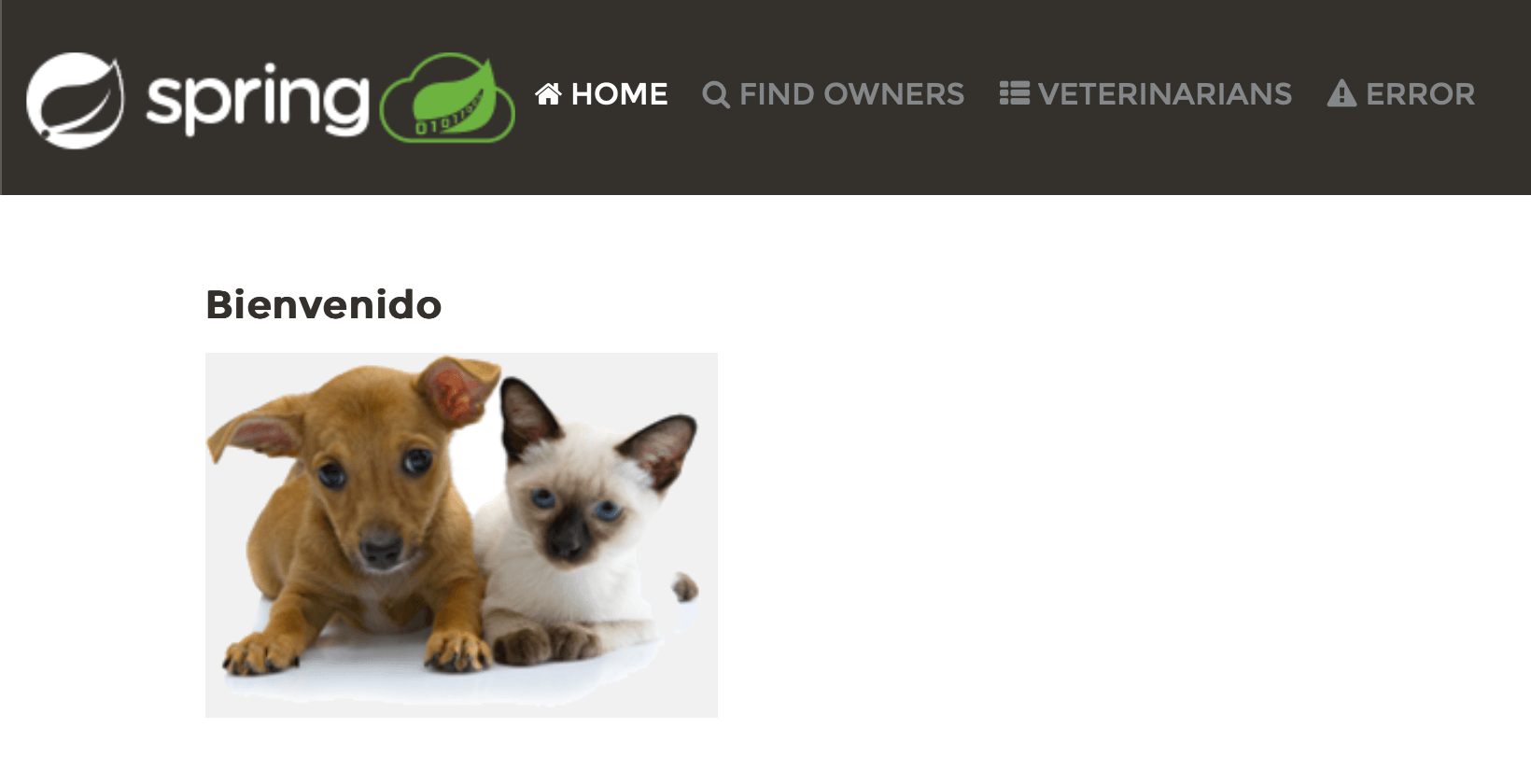
更改区域设置后,UI 中有所反映,这是个好消息。 然而,似乎更改区域设置只影响了一部分文本。 对于西班牙语,Welcome 已更改为 Bienvenido, 但头部的链接保持不变, 其他页面仍然是英文。这意味着我们还有一些工作要做。
修改模板
Spring Petclinic 项目使用 Thymeleaf 模板 来生成页面,让我们检查一下模板文件。
确实,有些文本是硬编码的,所以我们需要修改代码以引用 资源包中的内容。
幸运的是,Thymeleaf 对 Java .properties 文件有很好的支持,
因此我们可以在模板中直接加入对相应资源包键的引用:
<h2>Find Owners</h2><h2 th:text='#{heading.find.owners}'>Find Owners</h2>heading.find.owners=Find Owners之前硬编码的文本仍然存在,但现在它充当了一个备选值,只有在检索适当本地化消息时出错的情况下才会使用。
其余的文本以类似的方式外部化;然而, 有一些地方需要特别注意。 例如,一些警告来自验证引擎,必须使用 Java注解参数指定:
@Column(name = "first_name")
@NotBlank
private String firstName;@Column(name = "first_name")
@NotBlank(message = "{field.validation.notblank}")
private String firstName;在几个地方,逻辑需要改变:
<h2>
<th:block th:if="${pet['new']}">New </th:block>Pet
</h2>在上面的例子中,模板使用了一个条件判断。如果 new 属性存在,
则向界面文本添加 New。因此,根据属性是否存在,最终的文本会是 New Pet
或者 Pet。
这种情况可能会因为名词和形容词的一致性问题而破坏某些地区的本地化。例如,在西班牙语中,形容词会根据名词的性别变为
Nuevo 或 Nueva ,
而当前的逻辑并没有考虑到这种区别。
解决这种情况的一个可能方案是使逻辑更加复杂化。通常来说,尽可能避免复杂的逻辑是一个好主意, 所以我选择了解耦分支的方式来处理:
<h2>
<th:block th:if="${pet['new']}" th:text="#{pet.new}">New Pet</th:block>
<th:block th:unless="${pet['new']}" th:text="#{pet.update}">Pet</th:block>
</h2>将不同条件的分支分开,也将简化翻译过程及未来代码库的维护工作。
New Pet表单也有一个技巧。其Type下拉菜单是通过将 宠物类型的集合传递给 selectField.html 模板来创建的:
<input th:replace="~{fragments/selectField :: select (#{pet.type}, 'type', ${types})}" />与其它UI文本不同,宠物类型是应用程序数据模型的一部分。 它们在运行时从数据库中获取。 此数据的动态性质阻止我们直接将文本提取到属性包中。
处理这个问题有多种方法。一种方法是在模板中动态构建属性包键:
<option th:each="item : ${items}"
th:value="${item}"
th:text="${item}">dog</option><option th:each="item : ${items}"
th:value="${item}"
th:text="#{'pettype.' + ${item}}">dog</option>在这种方法中,我们不是直接在UI中渲染 cat ,而是给它加上前缀 pettype. ,这样就变成了
pettype.cat 。然后我们使用这个字符串作为键来获取本地化的UI文本:
pettype.bird=bird
pettype.cat=cat
pettype.dog=dogpettype.bird=pájaro
pettype.cat=gato
pettype.dog=perro您可能已经注意到,我们刚刚修改了一个可重用组件的模板。 由于可重用组件旨在服务于多个客户,因此将其引入客户端逻辑是不正确的。
在这种特定情况下,下拉列表组件变得与宠物类型绑定,这对于想要将其用于其他任何目的的人来说都是有问题的。
这个缺陷从一开始就存在——请参见 dog 作为选项的默认文本。
我们只是将这个缺陷进一步传播了。
在实际项目中不应这样做,需要进行重构。
当然,项目代码中还有更多需要国际化的内容;然而,其余部分大多与上述示例一致。 为了完整审查我对所有更改的修改,欢迎您查看 我在fork中的提交。
添加缺失的键
在将所有UI文本替换为属性捆绑包键的引用后,我们必须确保引入所有这些新键。此时我们不需要翻译任何内容,只需将这些键和原始文本添加到messages.properties文件中。
IntelliJ IDEA对Thymeleaf有很好的支持。它会检测模板是否引用了缺失的属性,这样您就可以在不进行大量手动检查的情况下发现缺失的键:
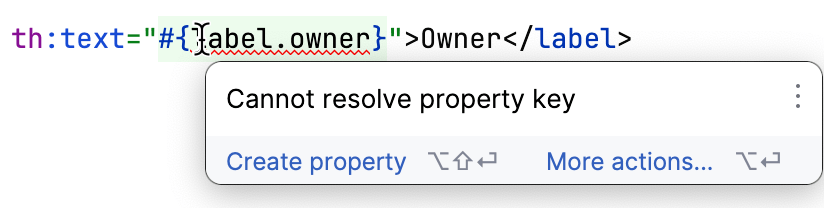
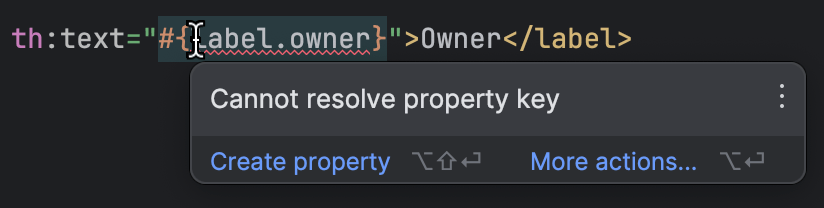
完成所有准备工作后,我们进入了工作中最有趣的部分。我们已经有了所有键,也有了英语的所有值。其他语言的值从哪里来呢?
翻译文本
为了翻译文本,我们将创建一个脚本,该脚本使用外部翻译服务。有许多可用的翻译服务,以及多种编写此类脚本的方法。我对实现做出了以下选择:
- 编程语言选择Python,因为它可以让你非常快速地编写小型任务
- DeepL作为翻译服务。最初,我计划使用OpenAI的GPT3.5 Turbo,但由于它严格来说不是一个翻译模型,因此需要额外的努力来配置提示。此外,其结果往往不够稳定,所以我选择了首先想到的专用翻译服务DeepL。
我没有做广泛的研究,所以这些选择有些随意。请随意尝试并发现最适合您的方法。

如果决定使用下面的脚本,你需要在DeepL上创建一个账户,并通过 DEEPL_KEY 环境变量将你的个人API密钥传递给脚本
以下是脚本:
import os
import requests
import json
deepl_key = os.getenv('DEEPL_KEY')
properties_directory = "../src/main/resources/messages/"
def extract_properties(text):
properties = {}
for line in text:
line = line.strip()
if line and not line.startswith('#') and '=' in line:
key_value = line.split('=')
key = key_value[0].strip()
value = key_value[1].strip()
if key and value:
properties[key] = value
return properties
def missing_properties(properties_file, properties_checklist):
with open(properties_file, 'r') as f:
text = f.readlines()
present_properties = extract_properties(text)
missing = {k: v for k, v in properties_checklist.items() if k not in present_properties.keys()}
return missing
def translate_property(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'DeepL-Auth-Key {deepl_key}',
'User-Agent': 'LocalizationScript/1.0'
}
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()["translations"][0]["text"]
def populate_properties(file_path, properties_checklist, target_lang):
with open(file_path, 'a+') as file:
properties_to_translate = missing_properties(file_path, properties_checklist)
for key, value in properties_to_translate.items():
new_value = translate_property(value, target_lang)
property_line = f"{key}={new_value}\n"
print(property_line)
file.write(property_line)
with open(properties_directory + 'messages.properties') as base_properties_file:
base_properties = extract_properties(base_properties_file)
languages = [
# configure languages here
"nl", "es", "fr", "de", "it", "pt", "ru", "ja", "zh", "fi"
]
for language in languages:
populate_properties(properties_directory + f"messages_{language}.properties", base_properties, language)
脚本从默认属性包( messages.properties )中提取键, 并在特定语言的包中查找它们的翻译。 如果发现某个键缺少翻译,脚本将向DeepL API请求翻译, 并将其添加到属性包中。
我指定了10种目标语言,但您可以修改列表或添加您偏好的语言,只要DeepL 支持它们即可。
为了保持简单,我没有在这里实现,但脚本可以进一步优化以批量发送50个文本进行翻译。
后来,我更新了脚本,使用了具有结构化输出的LLM。 你可以在这里查看结果。
运行脚本
跨10种语言运行脚本大约花费了我5分钟时间。 使用情况仪表板显示了8348个字符,如果我们使用付费计划, 这将花费€0.16。
结果,生成了以下文件:
- messages_fi.properties
- messages_fr.properties
- messages_it.properties
- messages_ja.properties
- messages_nl.properties
- messages_pt.properties
- messages_ru.properties
- messages_zh.properties
同时,缺失的属性也被添加到了:
- messages_de.properties
- messages_es.properties
但实际翻译效果如何?我们能立即看到吗?
检查结果
让我们重新启动应用程序,并使用不同的 lang 参数值进行测试。例如:
- http://localhost:8080/?lang=es
- http://localhost:8080/?lang=nl
- http://localhost:8080/?lang=zh
- http://localhost:8080/?lang=fr
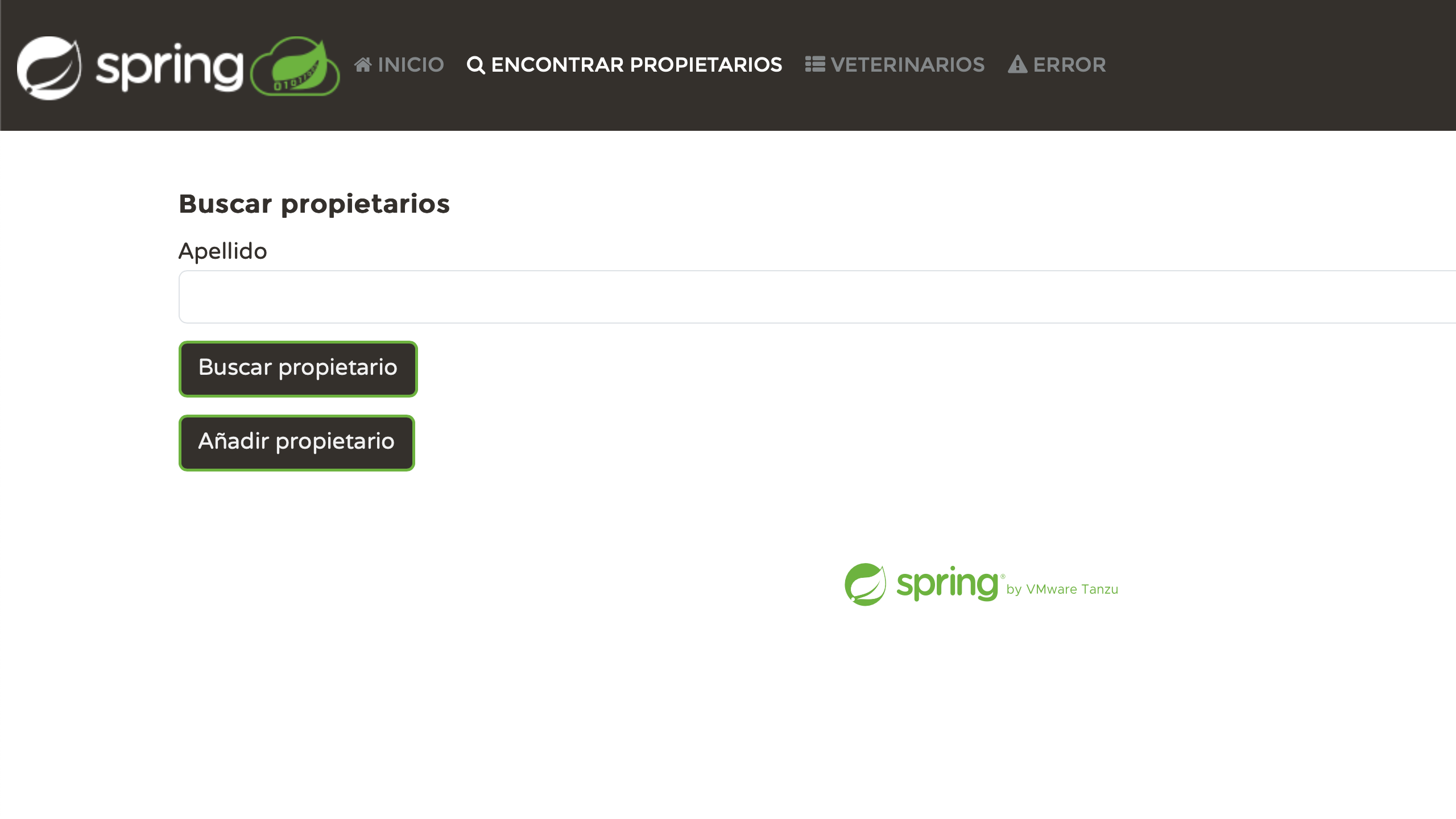
就个人而言,看到每个页面正确地进行了本地化,我感到非常满意。 我们付出了一些努力,现在正得到回报:


解决问题
结果令人印象深刻。然而,如果你仔细观察,可能会发现由于缺少上下文而产生的错误。例如:
visit.update = Visit Visit 既可以作名词也可以作动词。如果没有额外的上下文信息,翻译服务在某些语言中会产生不正确的翻译。
这个问题可以通过手动编辑或调整翻译工作流程来解决。 一种可能的解决方案是在 .properties 文件中使用注释提供上下文信息:
# Noun. Heading. Displayed on the page that allows the user to edit details of a veterinary visit
visit.update = Visit然后我们可以修改翻译脚本以解析这样的注释,并将其与 context 参数一起传递:
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True,
'context': context
}随着我们深入研究并考虑更多的语言,我们可能会发现更多需要改进的地方。 这是一个迭代的过程。
如果在这个过程中有一件事是不可或缺的,那就是审查和测试。无论 我们是改进自动化还是编辑其输出,都会发现进行质量控制和评估是必要的。
超出范围
Spring Petclinic是一个简单但又现实的项目,就像我们刚刚解决的问题一样。 当然,本地化还存在许多超出本文范围的挑战,包括:
- 适应目标语法规则的模板
- 货币、日期和数字格式
- 不同的阅读模式,如從右至左書寫
- 为不同长度的文本调整UI
每个主题都值得单独撰写文章。 如果你想了解更多,我很乐意在单独的文章中涵盖这些主题。
总结
好了,现在我们已经完成了应用程序的本地化,是时候回顾一下我们学到的知识了:
- 本地化不仅仅是翻译文本 - 它还影响相关的资源、子系统和流程
- 尽管人工智能在本地化的某些阶段非常高效, 人工监督和测试仍然是获得最佳结果所必需的
- 自动翻译的质量取决于多种因素,包括上下文的可用性,以及在LLMs的情况下,正确编写提示
希望你喜欢这篇文章,我期待收到你的反馈! 如果你有后续问题、建议,或者只是想聊天,请随时联系我。
期待在未来的文章中与你再见!