自我剖析 IntelliJ IDEA
阅读其他语言: English Español Français Deutsch 日本語 한국어 Português
与上一篇文章类似,这篇也将稍显元编程意味。 显然,你可以用 IntelliJ IDEA 去剖析另一个进程, 但你是否知道 IntelliJ IDEA 也能自我剖析?

如果你正在编写一个 IntelliJ IDEA 插件,并需要解决与插件性能相关的问题, 这个功能就非常有用。此外,无论你是插件作者与否,这个场景都可能引起你的兴趣, 因为我将要介绍的剖析策略并不局限于 IntelliJ IDEA —— 你可以用它来排查其他类型项目中类似的瓶颈问题,使用其他工具亦然。
问题所在
本文将探讨我几年前偶然发现的一个相当有趣的性能瓶颈。
在 IntelliJ IDEA 中进行一个侧边项目时,我发现为某些具有特定短名称的类(如 A )查找测试 导航 (Navigate) | 测试 (Test)
异常缓慢,通常耗时超过2分钟。

这个瓶颈的存在似乎并不取决于项目的大小——
即使在仅包含一个名为 A 的类的项目中,
导航仍然会花费很长时间。
在庞大的 IntelliJ IDEA 单体仓库中,我从未遇到过与该特性相关的延迟,因此在一个几乎为空的项目中出现的减速显得尤为奇怪。
为什么会这样?更重要的是,如果在你的项目中遇到类似问题,应如何应对?
重现环境
我最初为 JetBrains 内部撰写这篇文章, 然而,直到最近我才萌生了将其公开的想法。 幸运的是,随着时间的推移,文章并没有过时,问题似乎不再能在当前版本的 IntelliJ IDEA 和更新的硬件上复现。
由于无法在我的工作环境中重现延迟,我发现自己不得不翻出旧笔记本电脑, 并安装早期版本 的 IntelliJ IDEA。如果你想在你的 IDE 中跟进调查,请确保克隆 IntelliJ IDEA Community Edition 存储库, 这将简化你的导航和调试过程。
我们还需要确保拥有一个包含以下类的空项目:
public class A {
public static void main(String[] args) {
System.out.println("I like tests");
}
}IntelliJ Profiler
如你所知,IntelliJ IDEA 集成了 JVM 剖析器。 你可以通过剖析器附加 启动应用程序。 或者,你可以将剖析器附加到已运行的进程中,这就是我们将要做的。
为此,请转到分析器 (Profiler) 工具窗口,在那里找到相应的进程。如果你没有在列表中看到你的 IDE, 请确保在进程 (Process) 旁的菜单中检查显示开发工具 (Show Development Tools)。当你点击一个进程时,IntelliJ IDEA 会提供集成的性能分析工具,这些工具允许你:
所有这些工具都在 文档 中有所介绍,而本文将专注于剖析器。
我们需要在问题发生之前就将其附加。例如,如果问题是由调用某个 API 引起的,先将剖析器附加到进程,然后重现导致问题的事件。

理想情况下,我们应该在重现问题之前立即附加剖析器。 如果你的应用忙于做其他事情而非仅仅等待输入,这种方法将帮助你最小化无关的 样本。
根据问题代码执行所需的时间,多次重现问题也可能有意义, 这样剖析器可以收集更多样本用于分析。这将使问题在最终报告中更加突出。
当你卸载剖析器或终止进程时,IntelliJ IDEA 会自动打开生成的 快照。
分析报告
为了分析快照,你有几种不同的 视图 可供选择。 你可以查看调用树、特定方法的统计信息、每个线程的 CPU 负载、GC 活动等等。
对于当前问题,让我们从时间线 (Timeline) 视图开始,看看是否能发现任何异常:
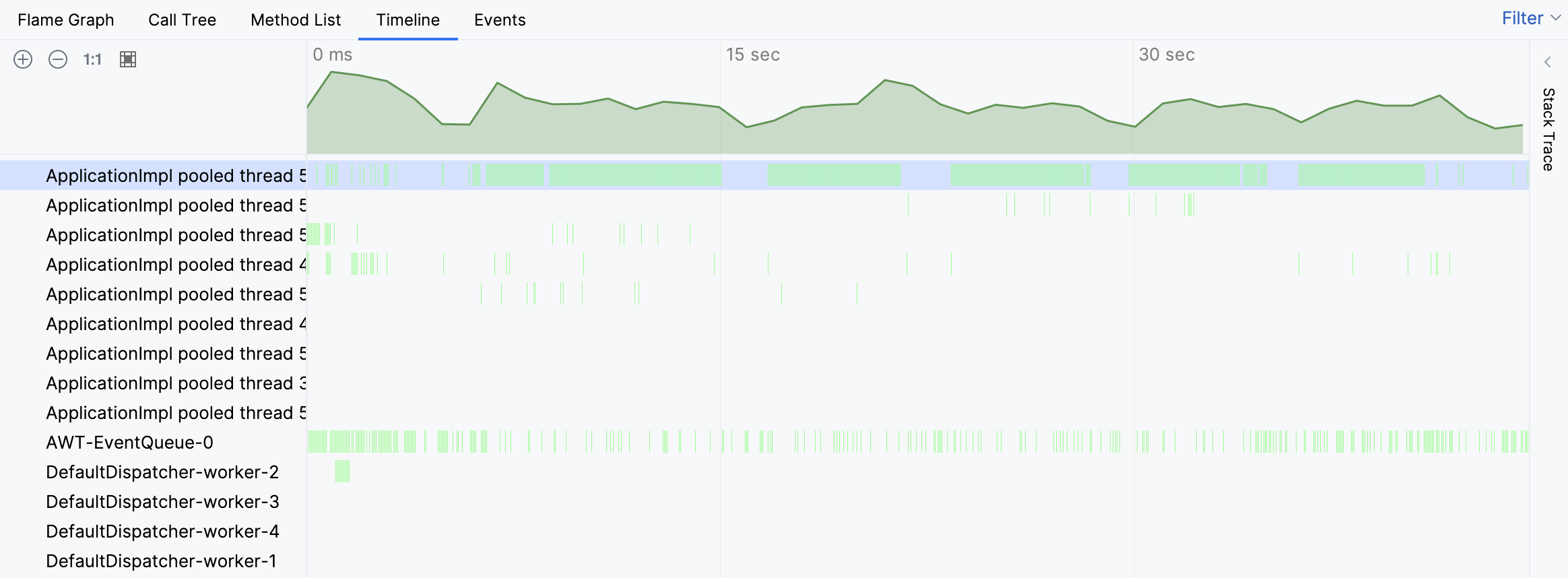
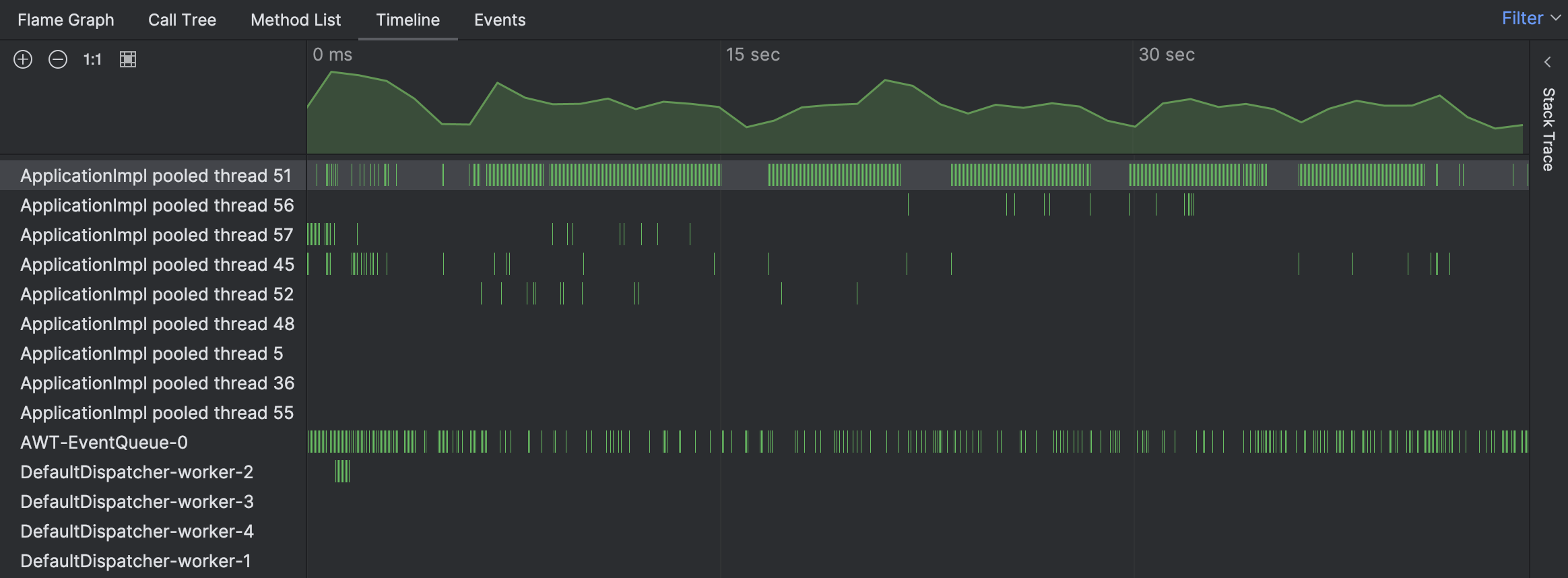
确实,时间轴表明其中一个线程异常繁忙。绿色条块对应于为特定线程收集的样本。通过点击任意这些条块,我们可以看到对应样本的堆栈跟踪。
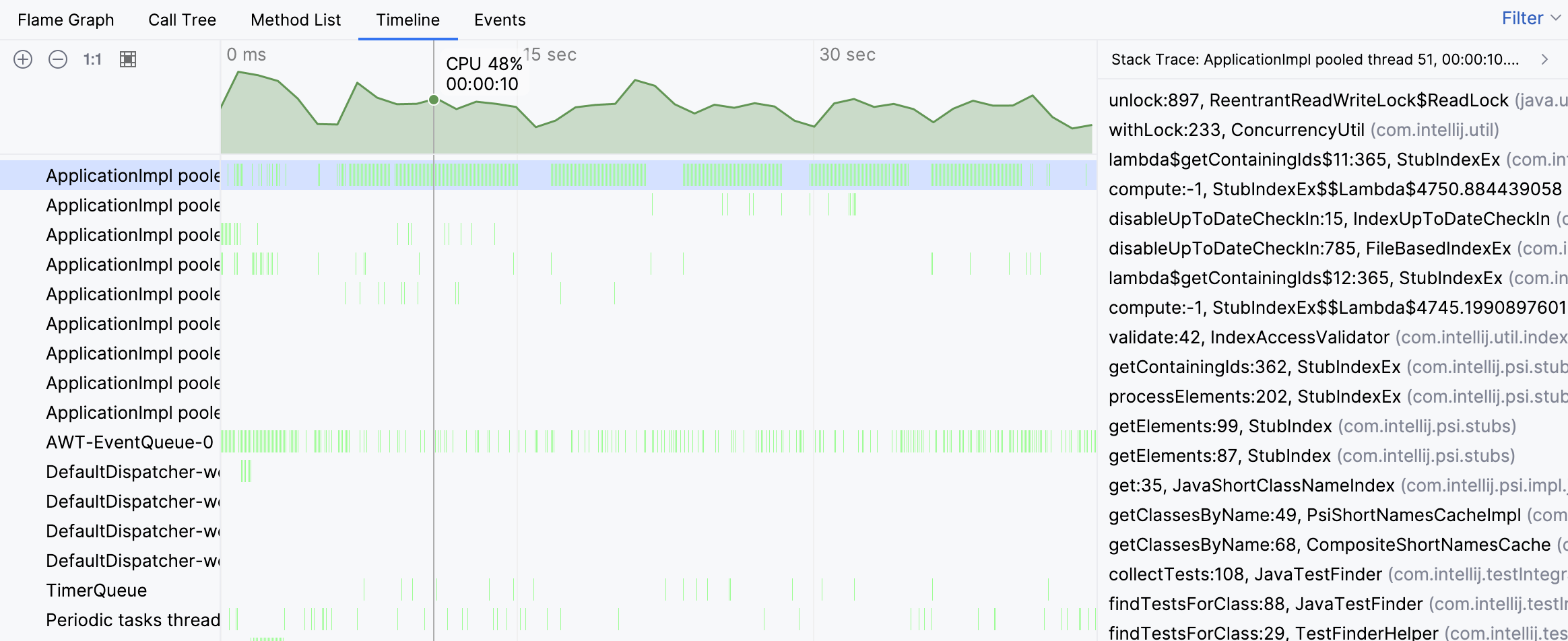
堆栈跟踪表明,该线程的活动与查找测试有关。然而,我们仍未看到全貌。让我们导航到火焰图中的繁忙线程:

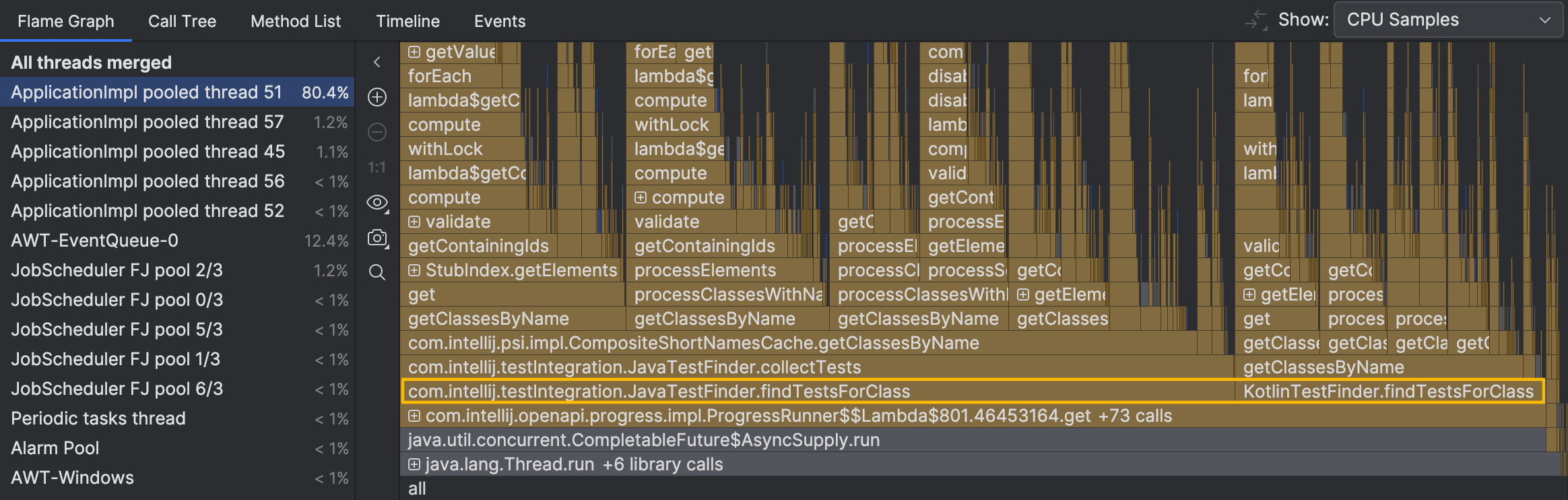
可能与问题相关的两个方法, JavaTestFinder.findTestsForClass() 和 KotlinTestFinder.findTestsForClass() ,
正好位于图的底部。我们不考虑它们下面折叠的方法,因为它们没有显著的自耗时或分支。它们控制流程而不是进行密集计算。
为了验证这些方法是否真的与减速有关,我们可以剖析一个非问题案例:为一个具有更现实名称的类(例如, ClassWithALongerName )
查找测试。然后,我们将使用 差异视图 查看这些方法的变化。


较新的快照中, JavaTestFinder.findTestsForClass() 和 KotlinTestFinder.findTestsForClass() 的样本减少了 93-95%。其他方法的运行时间变化不大。看来我们的方向是正确的。
下一个问题是为什么会这样。让我们尝试用调试器找出原因。
为什么会有如此巨大的差异?
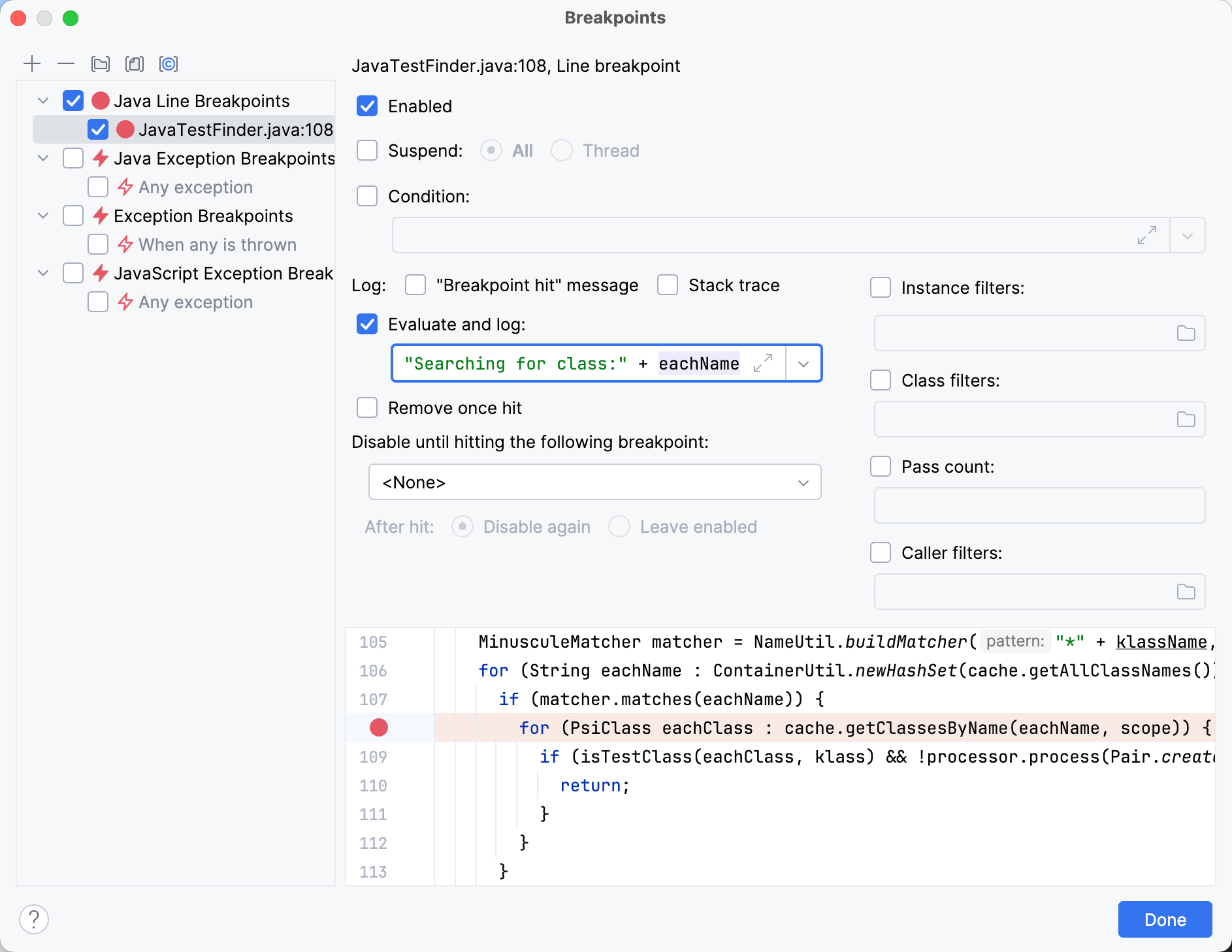
在 findTestsForClass() 设置断点,并稍微通过代码单步执行,我们来到以下位置:
MinusculeMatcher matcher = NameUtil.buildMatcher("*" + klassName, NameUtil.MatchingCaseSensitivity.NONE);
for (String eachName : ContainerUtil.newHashSet(cache.getAllClassNames())) {
if (matcher.matches(eachName)) {
for (PsiClass eachClass : cache.getClassesByName(eachName, scope)) {
if (isTestClass(eachClass, klass) && !processor.process(Pair.create(eachClass, TestFinderHelper.calcTestNameProximity(klassName, eachName)))) {
return;
}
}
}
}代码使用正则表达式过滤了当前缓存中的短名称。 对于每个得到的字符串,它都会搜索对应的类。
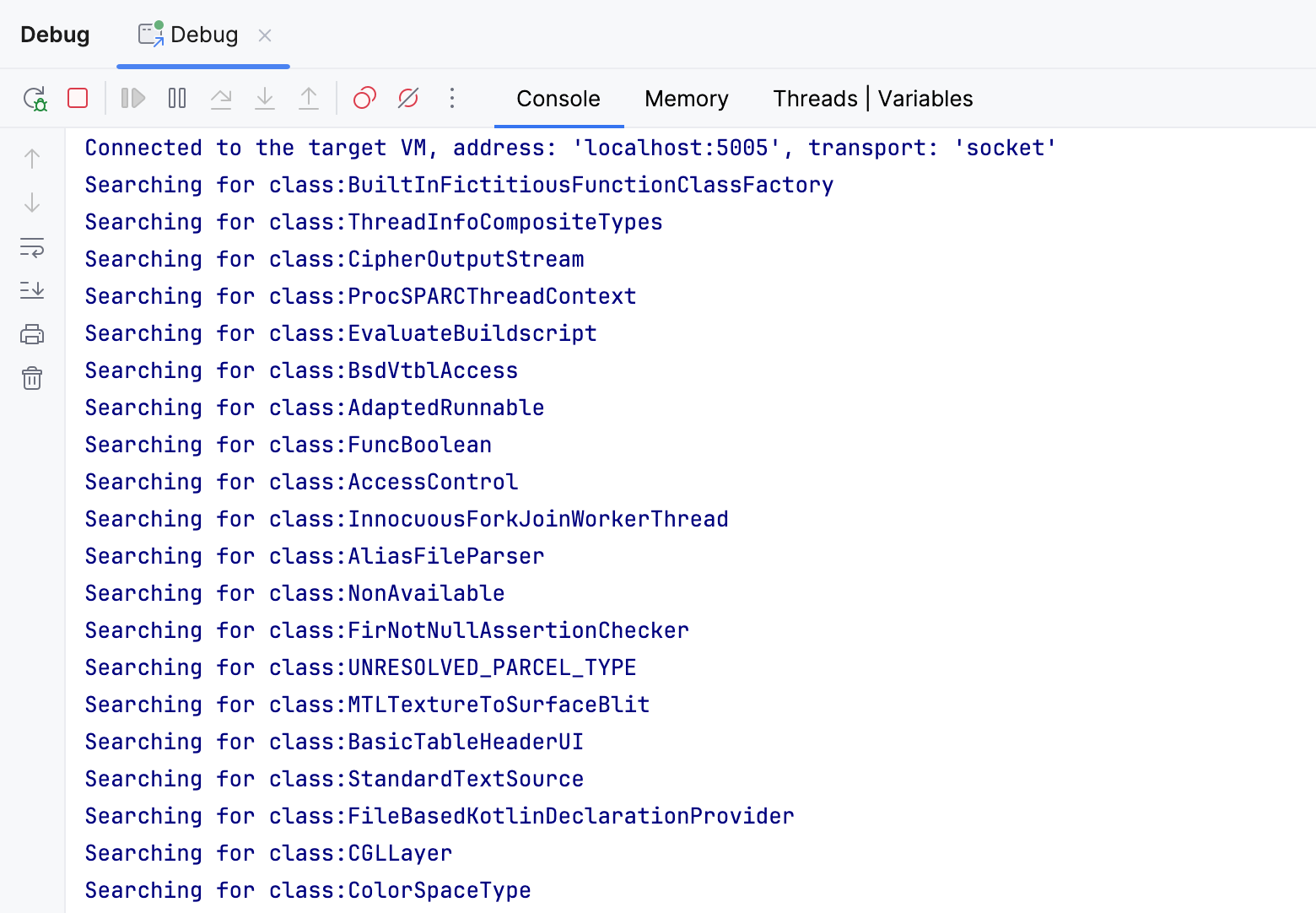
通过在条件后记录类名,我们获得了所有通过该条件的类。
当我执行程序时,它记录了大约25000个类,对于一个空项目来说,这是一个惊人的数字!
记录的类名显然来自其他地方,并非我的“Hello World”项目。
谜团解开:IntelliJ IDEA 花费很长时间寻找类 A 的测试,
因为它检查了所有缓存的类,包括依赖项、JDK,甚至是其他项目的类。
它们中的太多通过了过滤器,因为它们的名称中都包含
字母 A。
对于更长和更现实的类名,这种效率低下可能会被忽视,
仅仅因为这些名称中的大多数会被正则表达式过滤掉。
解决方案?
不幸的是,我没有找到一个简单可靠的解决方案来解决这个问题。 一种潜在的策略是将依赖项排除在搜索范围之外。 乍一看这似乎是可行的,但存在依赖项可能包含测试的情况。 这种情况并不经常发生,但这种方法仍然会破坏对这类依赖项的功能。
另一种方法是引入一个*.java文件掩码,以过滤掉编译过的类。
虽然这对Java有效,但对于用其他语言(如Kotlin)编写的测试就变得有问题了。
即使我们添加了所有可能的语言,这个功能对于新支持的语言也会悄悄失败,
从而增加了维护和调试的开销。
无论采用哪种方法,修复这一问题都值得单独写一篇文章,所以我们目前不进行实现。 但我们确实发现了性能下降的根本原因,这也是使用剖析器的目的所在。
分享快照
在结束之前,还有一件事值得一提。 你是否注意到我使用了一个在不同计算机上拍摄的快照? 而且,这个快照不仅仅来自另一台机器。 操作系统和IntelliJ IDEA的版本也是不同的。
关于剖析器一个常被忽视的优点是数据分享的便利性。 快照被写入到一个文件中, 你可以将其发送给其他人(或从他人那里接收)。 与其他工具(如调试器)不同,你不需要一个完整的复现场景就开始分析。 实际上,你甚至不需要一个可编译的项目来进行分析。
不要只听我说,自己尝试一下。这是快照: idea64_exe_2024_07_22_113311.jfr