Skill de IA para depurar tests inestables
Otros idiomas: EnglishFrançaisDeutsch日本語한국어Português中文
Si llevas un tiempo conectado a internet, seguramente habrás oído hablar de las skills para agentes de IA. Le enseñan a tu agente a hacer esto y aquello. Puede que incluso hayas usado o escrito alguna tú mismo.
Si aún no las conoces, la idea es sencilla: en lugar de redactar instrucciones para una tarea específica cada vez, las defines una vez y las reutilizas más adelante. Una skill es el equivalente en IA a un artículo de una base de conocimiento: un documento de texto plano que vive en una ubicación localizable y describe pasos, un conjunto de convenciones o conocimiento específico de un dominio.
La mayoría de las skills que se ven en la práctica son para cosas sencillas como aplicar el estilo de código o las convenciones de mensajes de commit. Pero pueden ser mucho más potentes que eso. En este artículo, combinaremos las skills de IA, las viejas y buenas herramientas de desarrollo y un poco de pensamiento creativo para abordar una tarea notoriamente complicada: hacer que la IA encuentre de manera determinista la causa raíz de los tests inestables.
El problema
Citando la guía de CI/CD de TeamCity:
Los tests inestables se definen como tests que devuelven tanto éxitos como fallos a pesar de no haber cambios en el código ni en el propio test.
La inestabilidad socava todo el sentido de los tests: cuando un test falla, no puedes saber si algo está realmente roto. No puedes confiar plenamente en los resultados de los tests y, al mismo tiempo, no puedes ignorarlos. Esto desperdicia tanto recursos humanos como de infraestructura.
Y como si los errores subyacentes no fueran ya bastante difíciles por sí mismos, los tests inestables suelen tener la propiedad de fallar una vez de cada varios miles de ejecuciones, lo que los hace extremadamente difíciles de reproducir y depurar.
Proyecto de ejemplo
Como proyecto de ejemplo, usemos la demo de webshop de este artículo: Tus programas no son de un solo hilo. Es un proyecto de Spring Boot en el que uno de los servicios tiene un problema de TOCTOU (time-of-check to time-of-use): comprueba una condición y luego actúa en consecuencia, pero otro hilo puede cambiar el estado en el medio. En este caso concreto, a veces puede provocar números de factura duplicados y, además, hace que el test correspondiente sea inestable.
Aquí está el test problemático:
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}El test crea dos órdenes de forma concurrente y verifica que las facturas resultantes
obtengan los números INV-00001 e INV-00002 .
Debido a un error en InvoiceService ,
puede pasar o fallar de forma aleatoria.
Si usas IntelliJ IDEA, puedes comprobar si un test es realmente inestable usando la opción Run until failure en el ejecutor de tests. Deja al sospechoso girando durante un tiempo y observa si finalmente falla.
Si no supiéramos nada sobre el error subyacente y solo tuviéramos el test, ¿existe alguna herramienta que pudiera ayudarnos a encontrar la causa raíz? ¿O podemos construir una nosotros mismos? Más aún, ¿podríamos delegar tanto la construcción como el uso de la herramienta a la IA?
La intuición
Vamos a desarrollar cierta intuición para esta clase de problema.
Para producir dos tipos de resultados, la ejecución
debe seguir caminos de código distintos.
La diferencia podría ser mínima, posiblemente solo una llamada a método extra
o una rama if tomada en lugar de otra.
Pero tiene que existir; de lo contrario, el resultado sería consistente.
Así pues, si pudiéramos registrar el camino de código de una ejecución exitosa y de una fallida
y luego compararlos, el diff debería al menos apuntarnos en la dirección correcta.
E idealmente, siguiendo el árbol de llamadas, podríamos encontrar el lugar donde la ejecución se bifurca.
Esa línea debe ser exactamente donde se origina la inestabilidad.
¿Tiene sentido este razonamiento? Pongámoslo a prueba.
Construir las herramientas
¿Qué herramienta podemos usar para registrar caminos de código? Aunque no esté diseñada específicamente para tracing, la cobertura de tests puede darnos la información que buscamos.
Hay un par de herramientas de cobertura para Java entre las que elegir, como JaCoCo y la herramienta de cobertura de IntelliJ IDEA. Iremos con la de IntelliJ IDEA, porque incluye la funcionalidad de conteo de hits. Puede que necesitemos esta granularidad extra, ya que la inestabilidad podría provenir no solo de qué se ejecuta, sino también de cuántas veces.
Ejecutar la cobertura desde la línea de comandos
La herramienta de cobertura de IntelliJ IDEA tiene una interfaz familiar, pero necesitamos una forma de ejecutarla programáticamente. Por suerte, la cobertura también puede recopilarse desde la línea de comandos adjuntando el agente de cobertura a la JVM mediante Maven Surefire:
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*"El flag -Didea.coverage.calculate.hits=true
le indica al agente que registre el número de invocaciones por línea en lugar de simplemente una máscara booleana de hit/no-hit.
Después de que el test termine, los resultados se escriben en un archivo binario .ic .
Hasta aquí todo bien, pero necesitamos el reporte en un formato legible para humanos (y para la IA).
Añadir salida de texto
Por suerte, el agente de cobertura de IntelliJ es de código abierto. Vamos a clonar el proyecto y pedirle a la IA que añada un reporter de texto que convierta los reportes binarios a texto plano.
El agente crea una nueva clase llamada TextCoverageStatistics .
Tras compilar el proyecto y ejecutar el reporter contra nuestro archivo .ic ,
obtenemos algo como esto:
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...La primera parte del reporte ofrece una visión general: cuántas líneas, ramas y métodos fueron cubiertos en todo el proyecto. Debajo de eso, hay un desglose por clase mostrando las mismas métricas para cada clase individualmente.
Después le siguen los conteos de hits por línea para cada clase:
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...Para cada línea que el agente de cobertura instrumentó, vemos cuántas veces se ejecutó y si se tomó alguna rama. El reporte real es más largo, pero te haces una idea. Ahora tenemos una representación en texto de qué líneas se ejecutaron, y exactamente cuántas veces.
Esta es la materia prima que necesitamos para el diff. ¡Hasta aquí todo bien!
Hacer un diff de los reportes
En teoría, los reportes obtenidos contienen la información necesaria, y un desarrollador muy decidido podría revisarlos detenidamente y encontrar el error. Pero no estamos aquí para tareas mundanas como esa, ¿verdad?
Mejoremos la herramienta para que reciba múltiples variaciones de reportes y muestre el diff. La forma más controlable sería hacerlo “ladrillo a ladrillo”, pero creo que aquí podemos delegar todo a la IA con seguridad, incluida la automatización:
El script resultante ejecuta el test en un bucle hasta que ocurran ambas cosas:
- obtenemos al menos una ejecución exitosa y una fallida.
- ha pasado el número de ejecuciones especificado.
Ambas condiciones son importantes, porque los fallos en los tests pueden ser muy poco frecuentes y el número de ejecuciones especificado podría no ser suficiente. Al mismo tiempo, puede haber variaciones de mayor granularidad dentro de las ejecuciones de éxito y fallo, así que también queremos capturarlas.
Una vez recopilados los reportes, el script resume las líneas que presentan variaciones entre ejecuciones. Así es como se ve:
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)Todas las variaciones tienen el mismo patrón: la diferencia no está en qué líneas se ejecutaron, sino en cuántas veces. Como esperábamos, ¡la funcionalidad de conteo de hits del agente de cobertura de IntelliJ IDEA ha demostrado ser útil!
Las líneas variantes apuntan a un bloque de inicialización perezosa en InvoiceService
y a sus efectos secundarios en InvoiceNumberGenerator
e Invoice .
La variación en los conteos de hits significa que la inicialización a veces se ejecuta más de una vez,
lo que no debería ocurrir. Eso es exactamente de donde proviene la inestabilidad.
Si te perdiste el artículo que describe el problema, aquí está el motivo por el que la doble inicialización causa este error.
El método createGenerator() consulta a la base de datos
por el último número de factura usado y crea un contador que empieza a partir de ese valor.
Cuando dos hilos entran ambos en el bloque if (generator == null)
antes de que cualquiera de los dos termine, cada uno lee el mismo número de la base de datos
y crea su propio generador empezando desde el mismo valor.
El resultado son números de factura duplicados.
El diff de cobertura nos ha apuntado a la misma condición de carrera TOCTOU que se discute con más detalle en el artículo anterior. Pero lo novedoso de nuestro enfoque actual es que no depende únicamente de la experiencia humana y es fácilmente accesible para la IA.
Convertirlo en una skill
Ahora bien, yo diría que las modificaciones asistidas por IA en herramientas de código abierto para ayudarte a resolver la tarea que tienes entre manos, todo en cuestión de minutos, son ya por sí mismas asombrosas. Pero mantengamos la vista en la imagen general.
Esto es lo que hemos hecho hasta ahora: empezamos con una intuición: los tests inestables toman caminos de código distintos, y el análisis de cobertura puede revelar dónde divergen. Luego convertimos esa intuición en un procedimiento concreto y repetible. ¿Esto justifica un artículo de base de conocimiento, o quizá una skill para un agente de IA? ¡Sí!
En la misma sesión del agente, pidámosle al agente que:
- Se asegure de que todos los scripts sean autocontenidos y ejecutables.
- Documente todo el procedimiento en un archivo
SKILL.md, paso a paso, para que otro agente pueda seguirlo sin contexto previo.
El agente empaqueta todo y escribe una guía que describe cuándo aplicar la skill, qué herramientas se necesitan y qué pasos seguir.
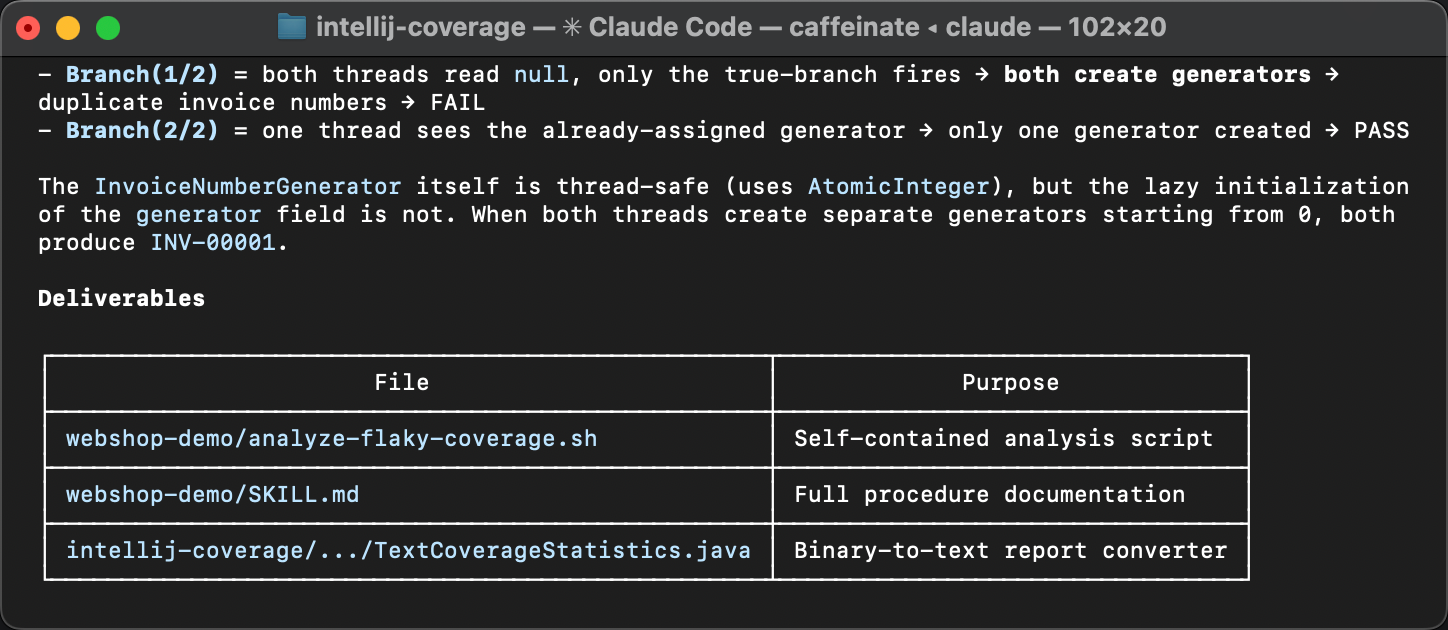
El único ajuste durante la revisión fue alinear la skill con la especificación. La skill original carecía del meta en el frontmatter. Los agentes son buenos resolviendo skills que omiten detalles menores, pero el meta es importante para la descubribilidad. Sin él, una skill podría ni siquiera ser elegida por un agente en primer lugar.
Probar la skill
Para verificar que la skill realmente funciona, iniciemos una sesión nueva del agente.
Sin calentamiento, sin pistas. En su lugar, formulémoslo deliberadamente de una manera muy general,
algo como Find and fix the cause of flakiness in InvoiceServiceTest.
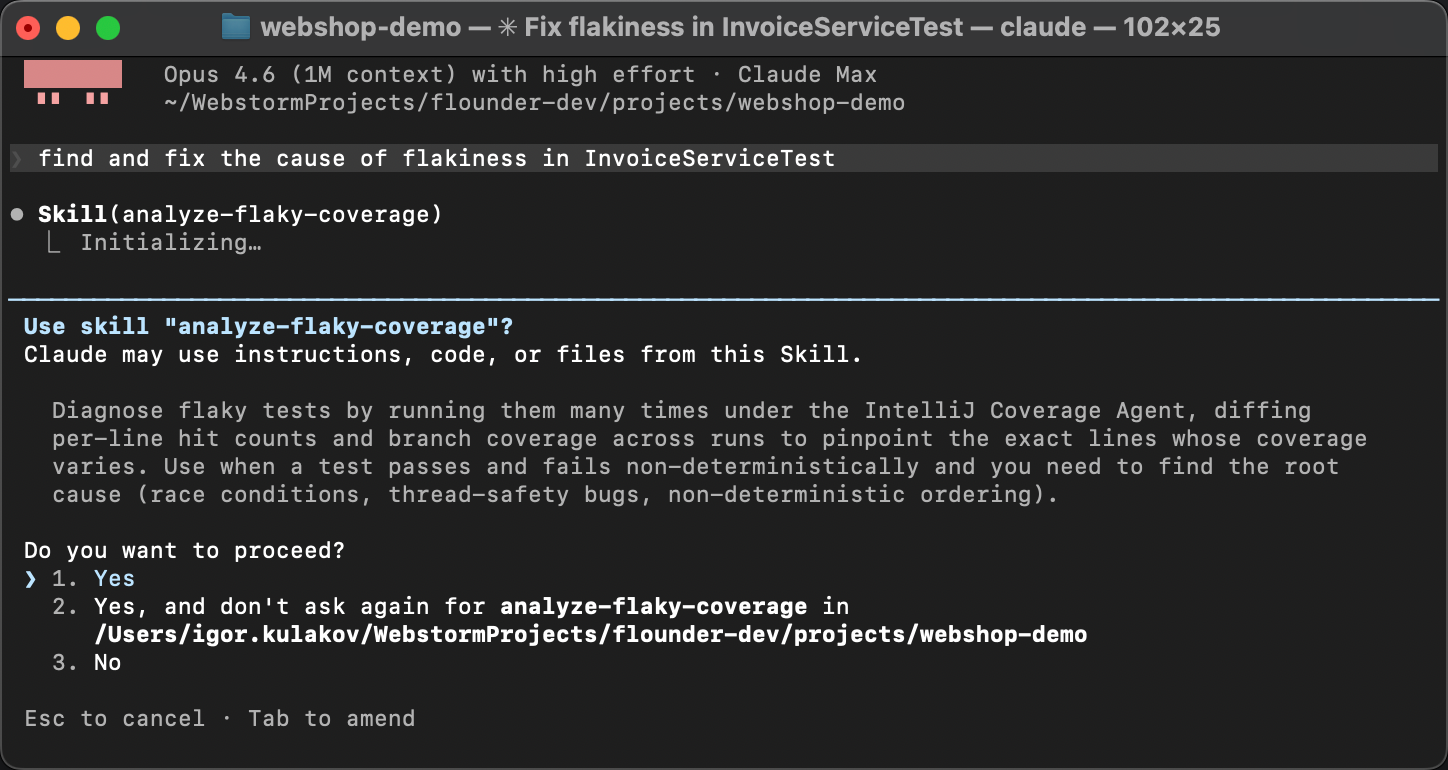
El agente empareja la descripción de la skill en SKILL.md con la descripción del problema,
descubre las instrucciones y las ejecuta: corre el script de cobertura, lee el diff
e identifica la condición de carrera.
En lugar de adivinar, sigue los pasos establecidos
y llega a la misma conclusión cada vez. ¡Tan determinista como puede llegar a ser una IA generativa!
Resumen
Los cambios que hicimos al agente de cobertura ya están publicados con la nueva versión 1.0.774. Y la skill está disponible aquí.
En este artículo, partimos de una intuición sobre los tests inestables, construimos herramientas a medida en torno a un agente de cobertura de código abierto, lo usamos para encontrar una condición de carrera y empaquetamos todo el procedimiento como una skill de IA reutilizable. Puedes usar esta skill para encontrar tests inestables en tus propios proyectos, pero espero que esta publicación transmita la idea más amplia.
Las skills de IA te permiten enseñarle a los agentes a resolver virtualmente cualquier cosa, siempre que puedas encadenar interfaces de texto. Muchos problemas difíciles de programación pueden descomponerse en otros más simples y resolverse usando herramientas familiares. Y con la IA orquestando todo esto, incluso podemos hacer que el proceso sea agradable. Como sucedía mucho antes de la IA, la curiosidad es el único requisito real.
¡Feliz depuración!