LLMs + Sortie Structurée comme Service de Traduction
Autres langues : English Español Deutsch 日本語 한국어 Português 中文
Dans un article précédent dédié à la localisation d’une application avec l’IA, nous avons discuté de l’automatisation de la traduction des chaînes d’interface utilisateur. Pour cette tâche, j’avais choisi un outil de traduction plutôt qu’un LLM, basé sur le raisonnement suivant :
…Je prévoyais d’utiliser le GPT3.5 Turbo d’OpenAI, mais comme ce n’est pas strictement un modèle de traduction, il nécessite un effort supplémentaire pour configurer le prompt. De plus, ses résultats tendent à être moins stables, j’ai donc choisi un service de traduction dédié qui m’est venu à l’esprit en premier…
Plus tard cette année-là, plusieurs fournisseurs de LLM ont introduit la fonctionnalité de sortie structurée, rendant les LLMs significativement plus adaptés au cas d’utilisation discuté. Aujourd’hui, nous allons examiner plus en détail le problème et comment cette fonctionnalité le résout.

Le problème
Les LLMs sont intrinsèquement non-déterministes, ce qui signifie qu’ils peuvent produire des sorties différentes pour la même entrée. Cette aléatoriété rend les LLMs “créatifs”, mais elle réduit également leur fiabilité lorsqu’il est requis de suivre un format de sortie spécifique.
Considérons le cas d’utilisation de la traduction comme exemple. Une solution naïve serait de décrire le format requis dans le prompt :
> Translate 'cat' to Dutch. ONLY GIVE A TRANSLATION AND NOTHING ELSE.Cela fonctionne, bien qu’occasionnellement, un LLM se trompera dans les instructions :
> Certainly, allow me to provide the translation for you.
The word 'cat' is translated as 'kat' in Dutch. Sometimes, female cats may also be referred to as 'poes'.Puisque l’application attend un seul mot en réponse, tout autre chose qu’un seul mot pourrait conduire à des erreurs ou des données corrompues. Même avec des vérifications supplémentaires et des tentatives de réessai, de telles incohérences compromettent la fiabilité du flux de travail.
Qu’est-ce que la sortie structurée
La sortie structurée résout les problèmes de formatage incohérent en vous permettant de définir un schéma pour la réponse. Par exemple, vous pouvez demander une structure comme celle-ci :
{
"word": "cat",
"target_locale": "nl",
"translation_1": "kat",
"translation_2": "poes"
}Sous le capot, l’implémentation de la sortie structurée peut varier entre les modèles. Les approches courantes incluent :
- l’utilisation d’une machine à états finis pour suivre les transitions entre les tokens et élaguer les chemins de génération qui violent le schéma fourni
- modifier les probabilités des tokens candidats pour diminuer la probabilité de sélectionner des options non conformes
- affiner le modèle avec un jeu de données axé sur la reconnaissance des schémas JSON et d’autres formats de données structurées
Ces mécanismes supplémentaires aident à atteindre une fiabilité plus élevée par rapport à simplement ajouter des instructions de format au prompt.
Code
Mettons à jour le script de traduction. Pour commencer, nous allons définir l’objet qui représente le schéma :
response_format={
"type": "json_schema",
"json_schema": {
"name": "translation_service",
"schema": {
"type": "object",
"required": [
"word",
"translation"
],
"properties": {
"word": {
"type": "string",
"description": "The word that needs to be translated."
},
"translation": {
"type": "string",
"description": "The translation of the word in the target language."
}
},
"additionalProperties": False
},
"strict": True
}
}Ensuite, nous pouvons utiliser l’objet schéma dans la fonction qui effectue la requête :
def translate_property_llm(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {openai_key}',
}
url = 'https://api.openai.com/v1/chat/completions'
data = {
'model': 'gpt-4o-mini',
'response_format': response_format,
'messages': [
{'role': 'system',
'content': f'Translate "{value}" to {target_lang}. '
f'Only provide the translation without any additional text or explanation.'},
{'role': 'user', 'content': value}
],
}
response = requests.post(url, headers=headers, data=json.dumps(data))
try:
content_json = json.loads(response.json()["choices"][0]["message"]["content"])
return content_json["translation"]
except (json.JSONDecodeError, KeyError) as e:
raise ValueError(f"Failed to parse translation response: {str(e)}")C’est tout pour le codage ! Pour plus de contexte, vous êtes invité à explorer et expérimenter avec le projet dans le dépôt GitHub.
Comparaison avec l’approche précédente
Le processus de traduction a pris un peu plus de temps pour la version mise à jour par rapport à celle basée sur le service de traduction. Cela dit, le code fourni est l’exemple fonctionnel le plus simple, et nous pourrions le rendre beaucoup plus rapide en envoyant les requêtes de manière asynchrone.
En termes de dépenses, la traduction vers 5 locales m’a coûté moins de 0,01$, ce qui est plus de 10 fois moins cher que la version précédente :
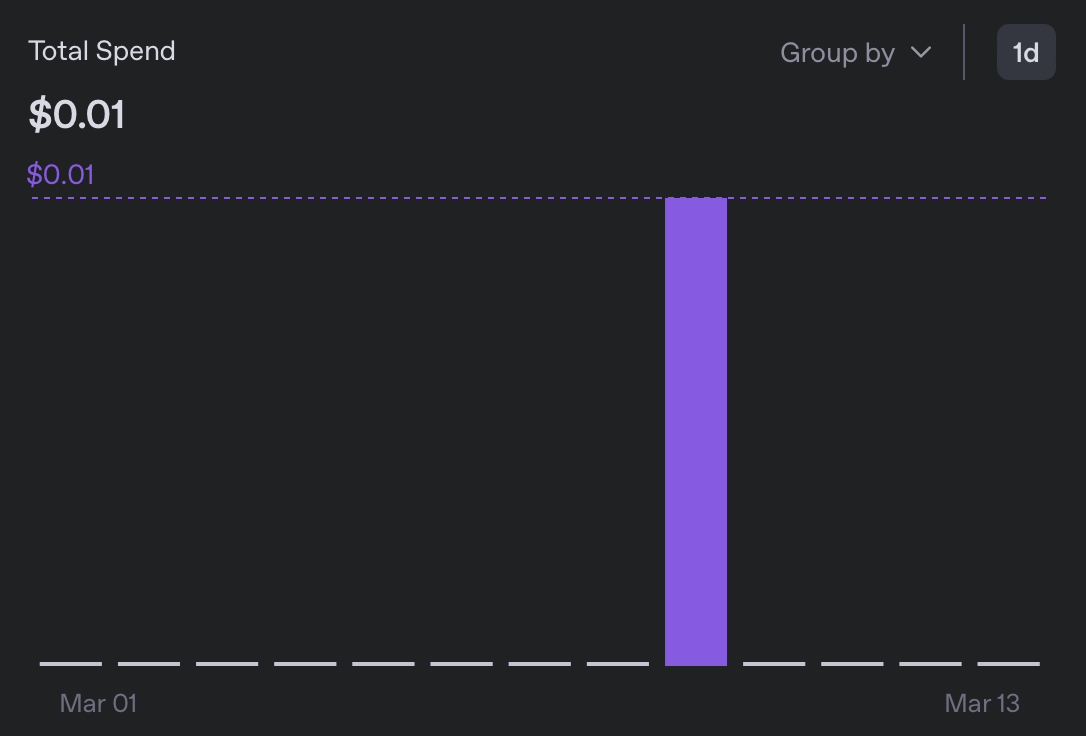
En parcourant les bundles de messages résultants, je n’ai rien remarqué de suspect. Bien que je ne puisse lire aucune des langues nouvellement ajoutées, le formatage semble bon, et je n’ai pas rencontré d’occurrences de ‘Bien sûr, je vais traduire ça pour vous’
Pourquoi c’est important
Bien que l’expérience décrite aborde un problème de niche, elle met en lumière un aspect plus large et plus significatif des grands modèles de langage. Bien qu’ils puissent ou non surpasser les services spécialisés dans la résolution d’une tâche particulière, ce qui est vraiment remarquable chez les LLMs est leur capacité à servir de solution rapide et pratique et d’alternative polyvalente aux outils plus spécialisés.
En tant que personne n’ayant qu’une familiarité de base avec l’apprentissage automatique, j’évitais des classes entières de tâches, parce que même une solution médiocre nécessitait une expertise que je n’avais pas. Maintenant, cependant, il est devenu incroyablement facile d’assembler des classificateurs, des services de traduction, des LLMs-comme-juge, et d’innombrables autres applications.
Bien sûr, la qualité reste une considération, mais de manière réaliste, nous n’avons pas besoin d’une perfection à 100% pour de nombreux problèmes de toute façon. Une raison de moins de ne pas bidouiller !
Conclusion
Je n’ai pas pu penser à une manière significative de conclure cet article, alors voici une photo du chat que j’ai rencontré aujourd’hui (non générée par IA !) :
