Junie Code (Support AsciiDoc)
Autres langues : English Español Deutsch 日本語 한국어 Português 中文
La semaine derniere, j’ai parle de Duplicate Finder sur le Foojay Podcast anime par Frank Delporte. Nous avons brievement aborde l’implementation du support pour d’autres formats, et Frank a demande si je prevoyais d’ajouter AsciiDoc, car cela pourrait etre utile pour son ecriture technique chez Azul.
Nous avons convenu de reflechir a l’ajout du support prochainement. Au meme moment, j’ai obtenu l’acces a Junie, un agent de codage nouvellement annonce par JetBrains, actuellement en acces anticipe. Apres un moment, l’idee m’est venue que c’etait une excellente opportunite de l’essayer en action. Les agents de codage sont connus pour bien resoudre les taches typiques. Mais qu’en est-il d’un projet qui n’est pas base sur un framework bien connu et qui est en dehors d’un domaine tres commun ? En tant que sceptique des agents de codage, mes attentes etaient mitigees.

Voici comment ca s’est passe.
Installation et apercu
Junie est un plugin IntelliJ IDEA. L’interface adopte une fenetre d’outil verticale familiere, similaire a celle de JetBrains AI Assistant ou GitHub Copilot. Voici a quoi ca ressemble :
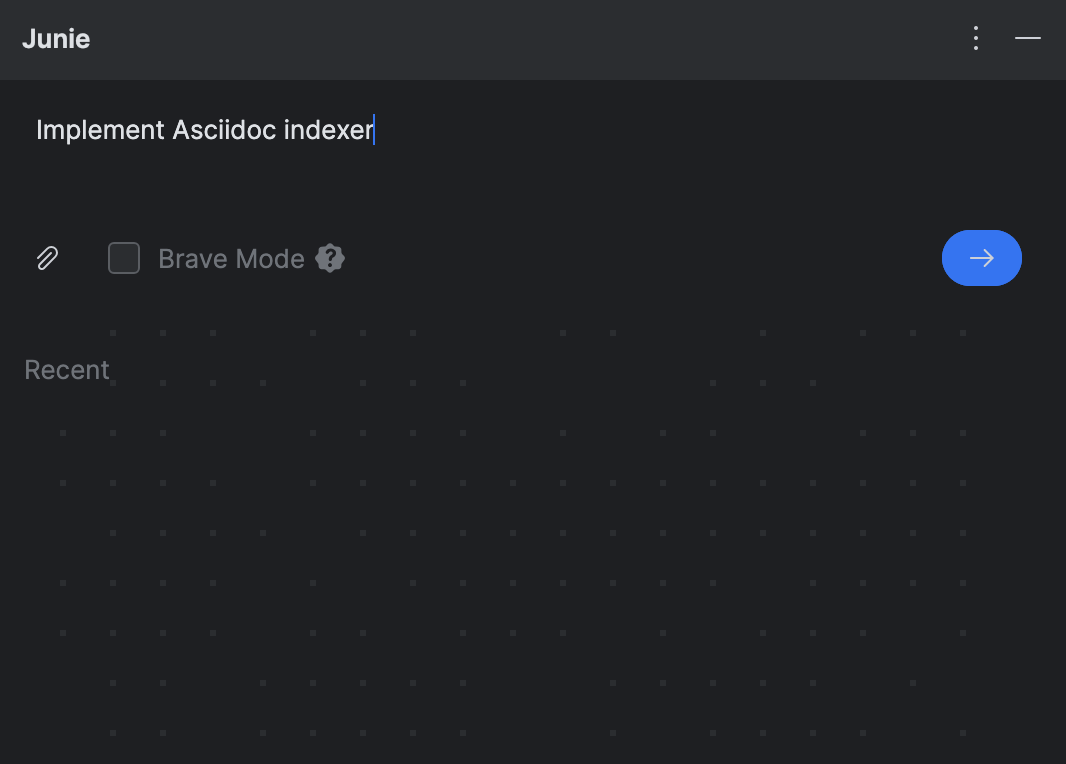
Le design minimaliste ne comporte qu’un champ de prompt, un bouton pour ajouter du contexte, et une case a cocher intitulee Brave Mode. Cette option controle si Junie peut executer des commandes sans verifier avec vous au prealable. Je ne suis pas encore si courageux, donc j’essaierai ca la prochaine fois.
Definir les exigences
Avant de donner la tache de codage a Junie, j’ai telecharge
un sujet du guide AsciiDoctor
et je l’ai place sous src/test/resources/ pour que Junie l’utilise comme donnees de test et reference.
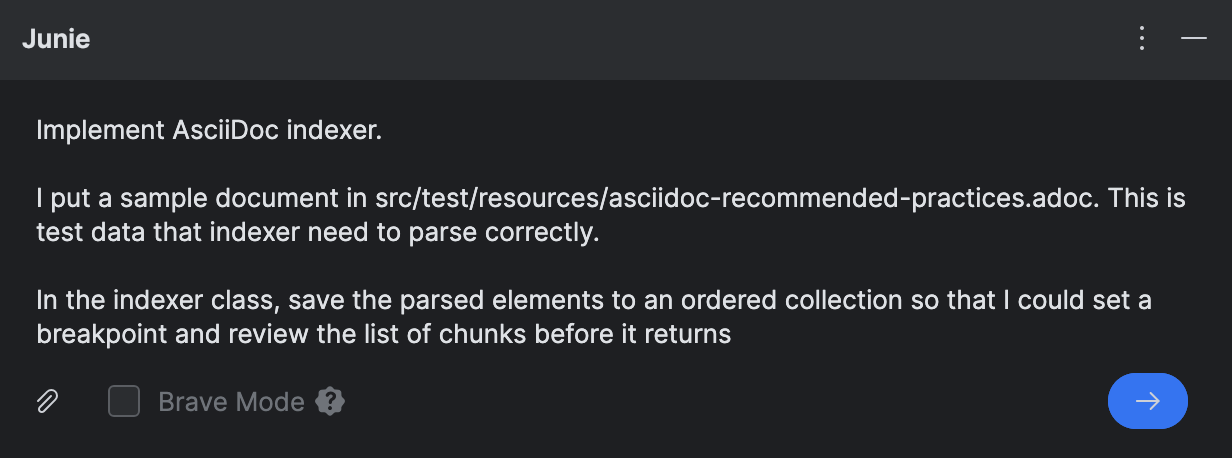
A des fins de debogage, j’ai demande a Junie d’ajouter les blocs parses dans une collection separee. C’est parce que l’index reel est structure en plusieurs niveaux, ce qui le rend peu pratique a deboguer. Pour simplifier, je prefere voir les elements parses comme une structure plate si j’ai besoin de verifier les resultats a l’execution.
‘Codage’
Apres avoir entre le prompt, Junie decompose la tache en elements plus petits et commence a les implementer. Pour l’ajout du support AsciiDoc, il a elabore le plan suivant :
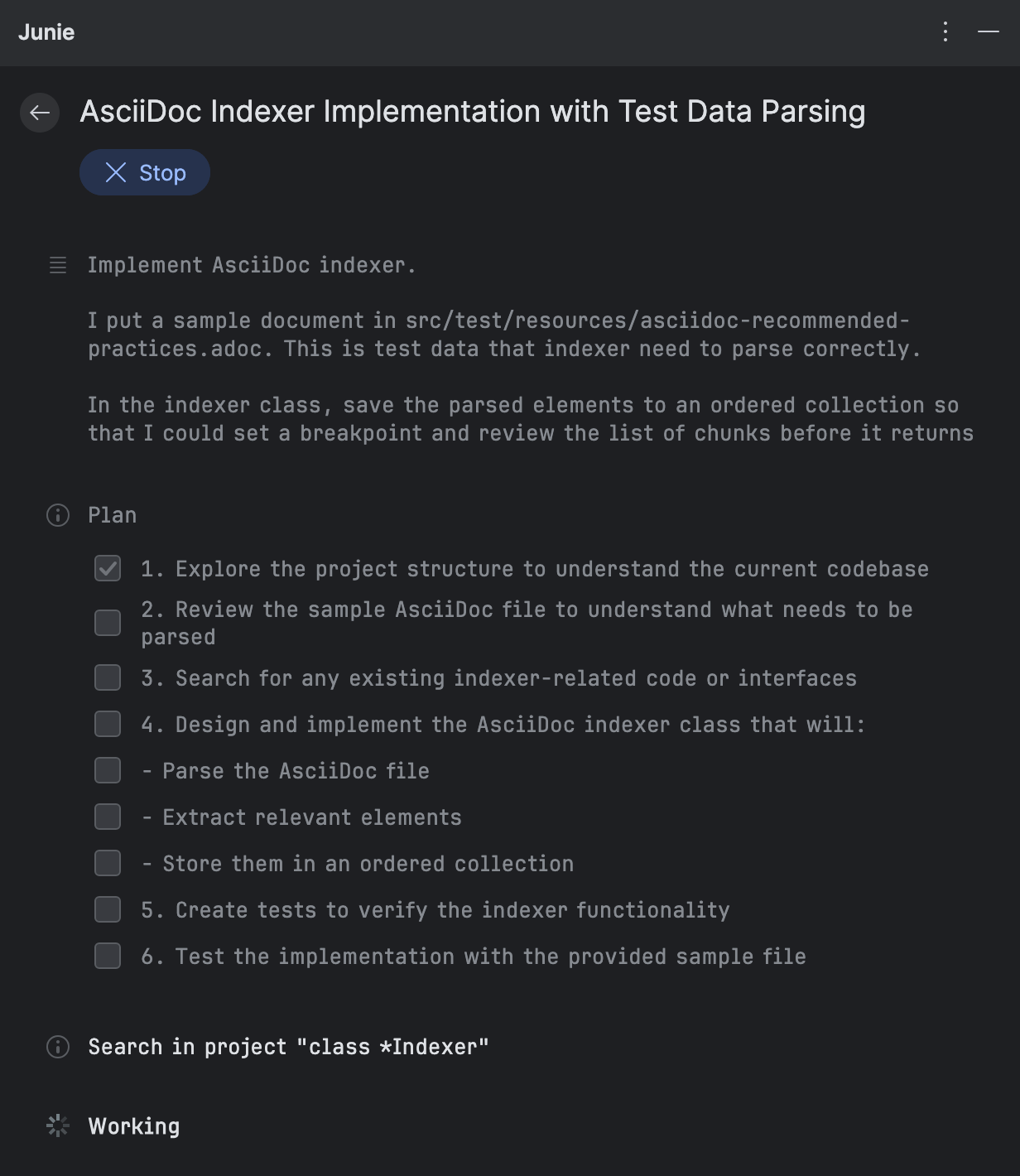
Au fur et a mesure que Junie execute chaque element, il vous donne le resume des changements. Vous pouvez les examiner immediatement, sans avoir a attendre que l’ensemble du flux de travail soit termine :

En cliquant sur les noms de fichiers, vous pouvez suivre les changements dans la vue diff d’IntelliJ IDEA de maniere similaire a la visualisation des changements Git ou de Local History.
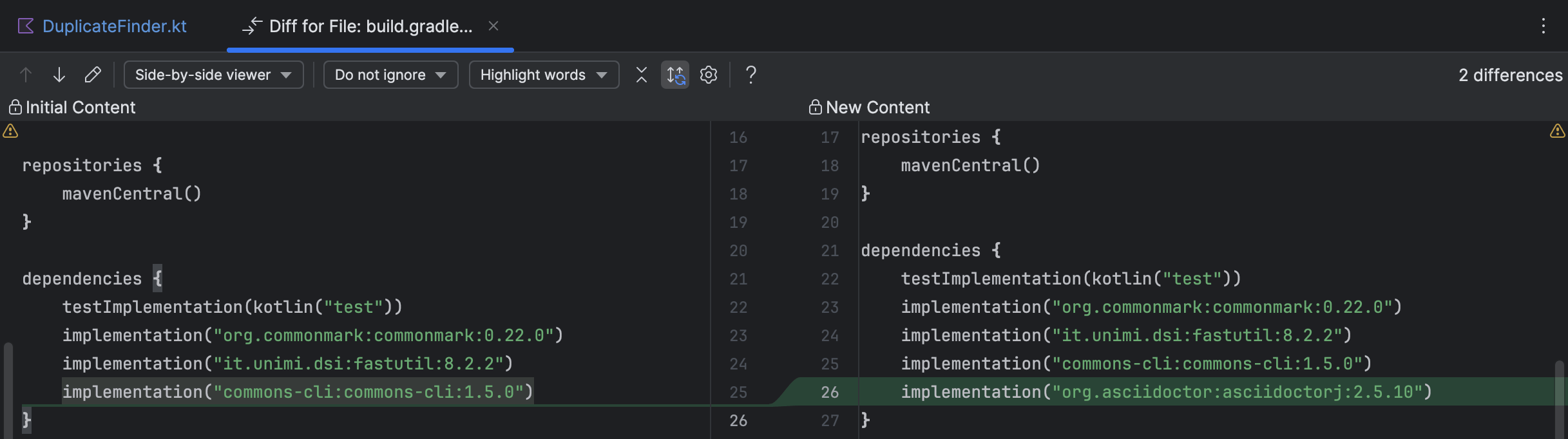
Une fois tous les elements termines, Junie procede a l’ecriture des tests puis vous invite a les executer :
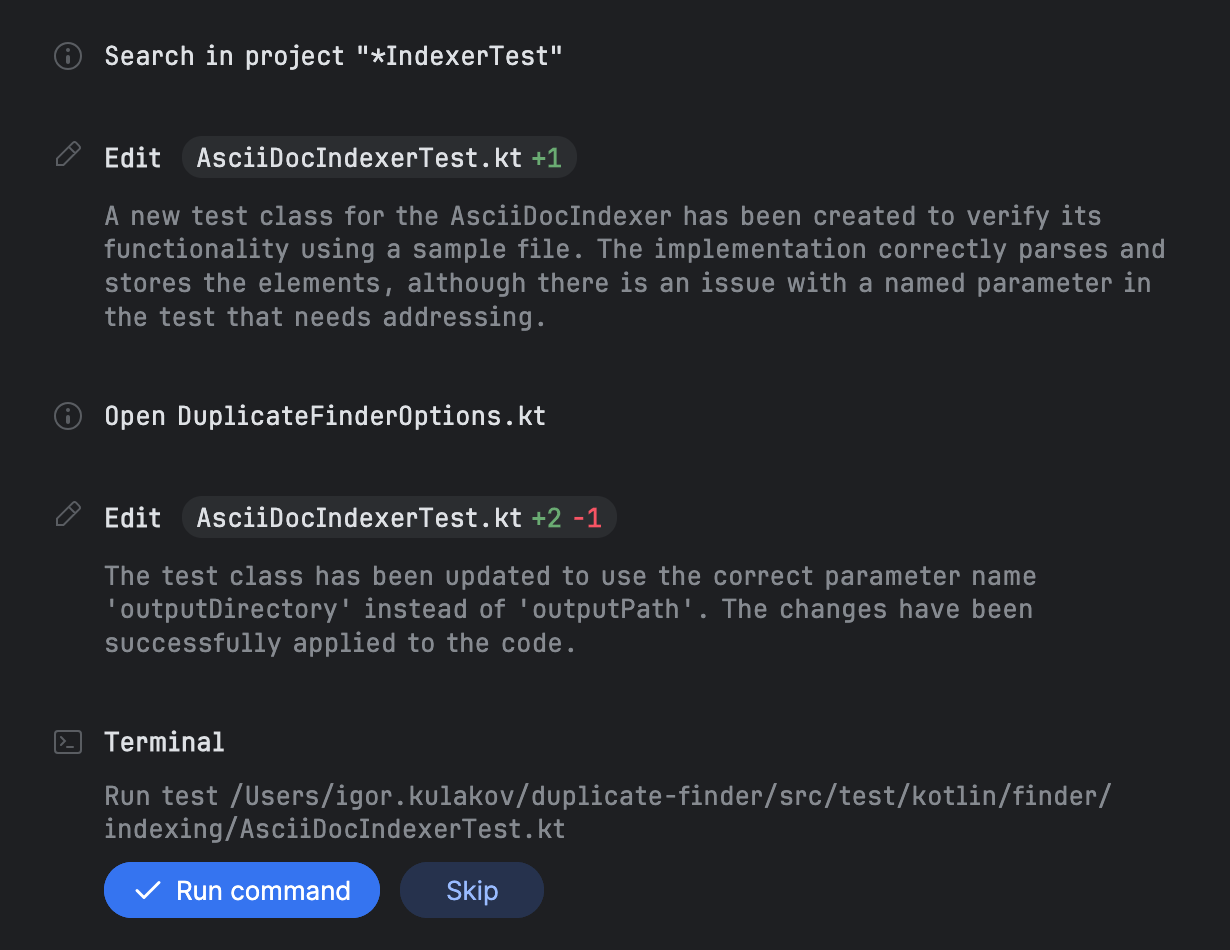
Dans cette tache, j’ai donne a Junie des donnees de test et j’ai explicitement demande des tests. Cependant, il apparait que Junie les genere avec les donnees de test par defaut. J’ai experimente en executant des taches sans mentionner les tests, et Junie les a crees quand meme.
Apres avoir execute les tests, qui ont reussi dans ce cas, Junie fournit le resume de ce qui a ete fait :

Qualite du code
En examinant le code et les tests, je les ai trouves bien structures et soignes. Ce que j’ai vraiment apprecie, c’est que Junie a change non seulement le code requis pour que le projet compile, mais a egalement fait l’effort supplementaire d’introduire d’autres changements significatifs dans le contexte de la tache.
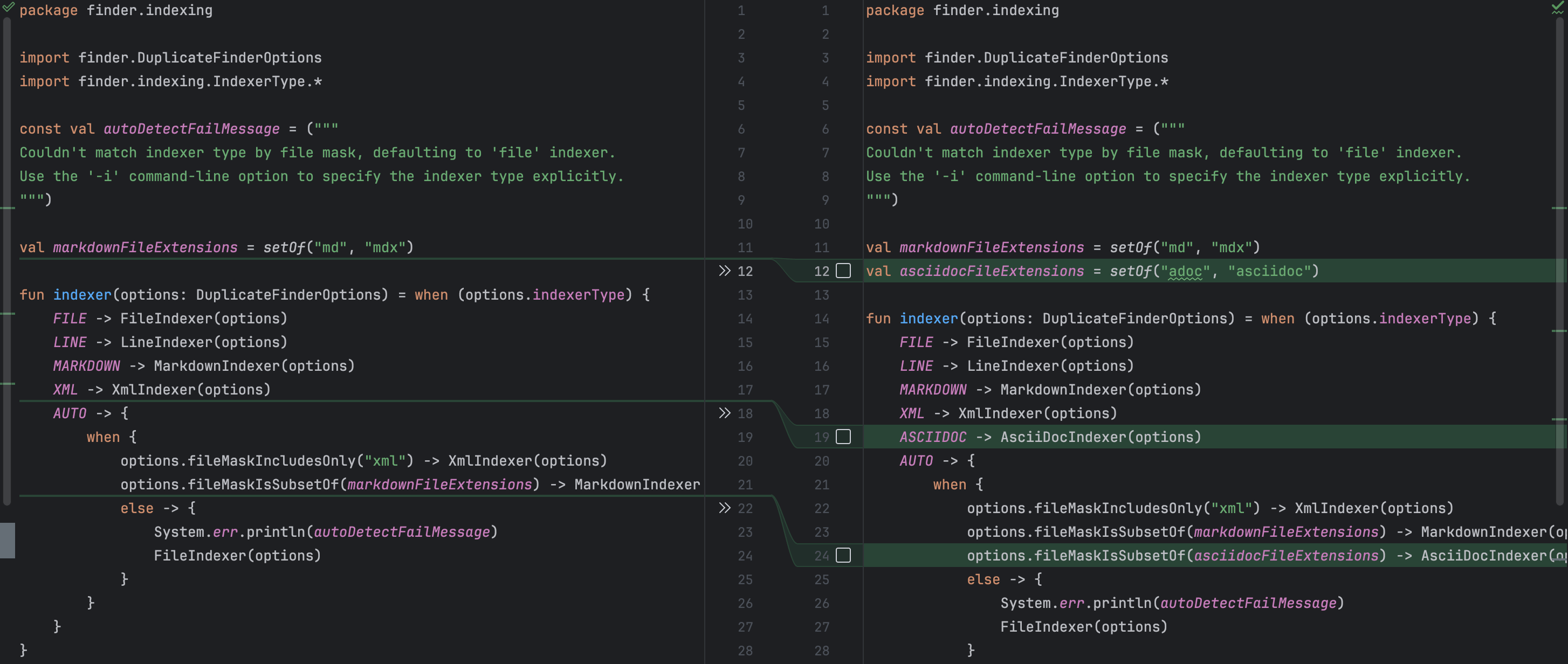
Par exemple, j’avais oublie de mentionner que le nouvel indexeur doit etre expose dans les arguments de ligne de commande. Cet oubli ne causerait pas d’erreur de compilation, mais ca n’a pas de sens pour l’utilisateur final s’il ne peut pas acceder a la fonctionnalite. Junie a reconnu cela et a ajoute l’option de ligne de commande correspondante avec une description. Il a egalement correctement mis a jour la methode factory, pour que le code client puisse obtenir une instance du nouvel indexeur. En meme temps, il n’y avait pas de changements inutiles, ce qui est aussi super !
Tout va bien jusqu’ici, mais il apparait que plus de travail doit encore etre fait.
Corriger l’implementation
Un domaine ou les agents de codage ne sont pas encore entierement autonomes est l’identification des problemes potentiels a l’execution. Techniquement, l’implementation est correcte, et elle passe tous les tests. Les resultats du parsing sont coherents, comme on peut le voir dans la boite de dialogue Evaluate.
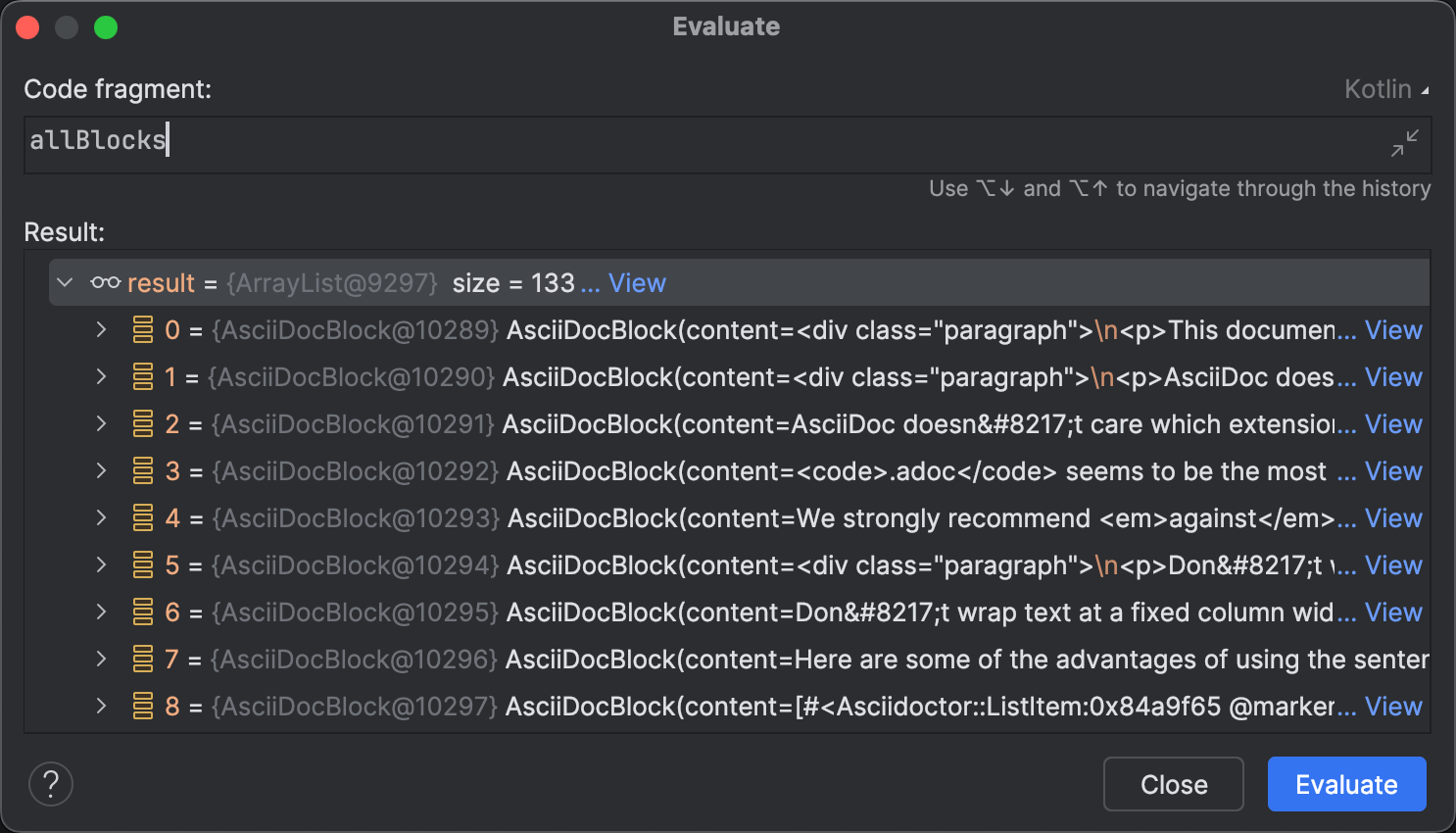

Evaluate Expression a beaucoup de cas d’utilisation interessants au-dela de l’exploration de collections. Par exemple, vous pouvez l’utiliser pour prototyper et appliquer des correctifs a un programme en cours d’execution ou modifier arbitrairement le comportement du programme
Tout semble bien, sauf que le traitement d’un seul fichier prend
un temps etonnamment long. En examinant cela, j’ai aussi decouvert que le parsing d’un lot d’environ 35 fichiers echoue toujours
avec une OutOfMemoryError .
En analysant l’implementation, je n’ai pas trouve de defauts evidents tels que des boucles inefficaces ou des fuites de ressources.
Executer l’application avec -XX:+HeapDumpOnOutOfMemoryError m’a donne un dump du heap, qui
a revele de nombreux types JRuby avec d’enormes tailles retenues.
Cela a suggere la bibliotheque comme source possible du probleme.
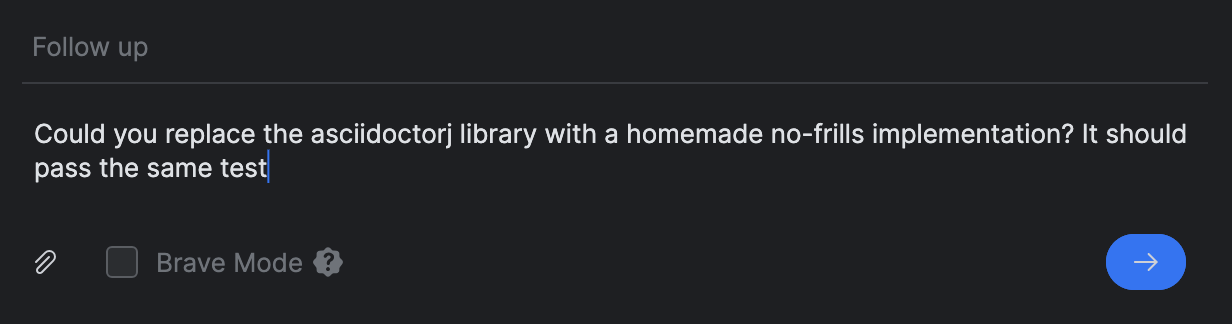
Bien sur, cette supposition pourrait ne pas etre exacte, nous donnant une opportunite fascinante pour le profilage (ou la lecture de documentation). Quoi qu’il en soit, remplacer une dependance JRuby par une implementation Kotlin simple accelererait tres probablement les choses. J’ai donc decide de demander a Junie de reecrire l’implementation en utilisant un parseur personnalise.
Plutot que de commencer une nouvelle tache, j’ai utilise le prompt Follow up pour cela :
Resultats
Junie a revise l’implementation comme demande. Bien que je ne sois pas tres familier avec le format AsciiDoc, le parsing semble etre largement correct au premier regard. Il y a de la place pour l’amelioration dans le parsing du preambule, et probablement autre chose, mais il fait son travail.
Executer le Duplicate Finder mis a jour sur l’aide d’AsciiDoctor elle-meme a detecte quelques doublons ! L’analyse a pris 350 millisecondes sur mon laptop :
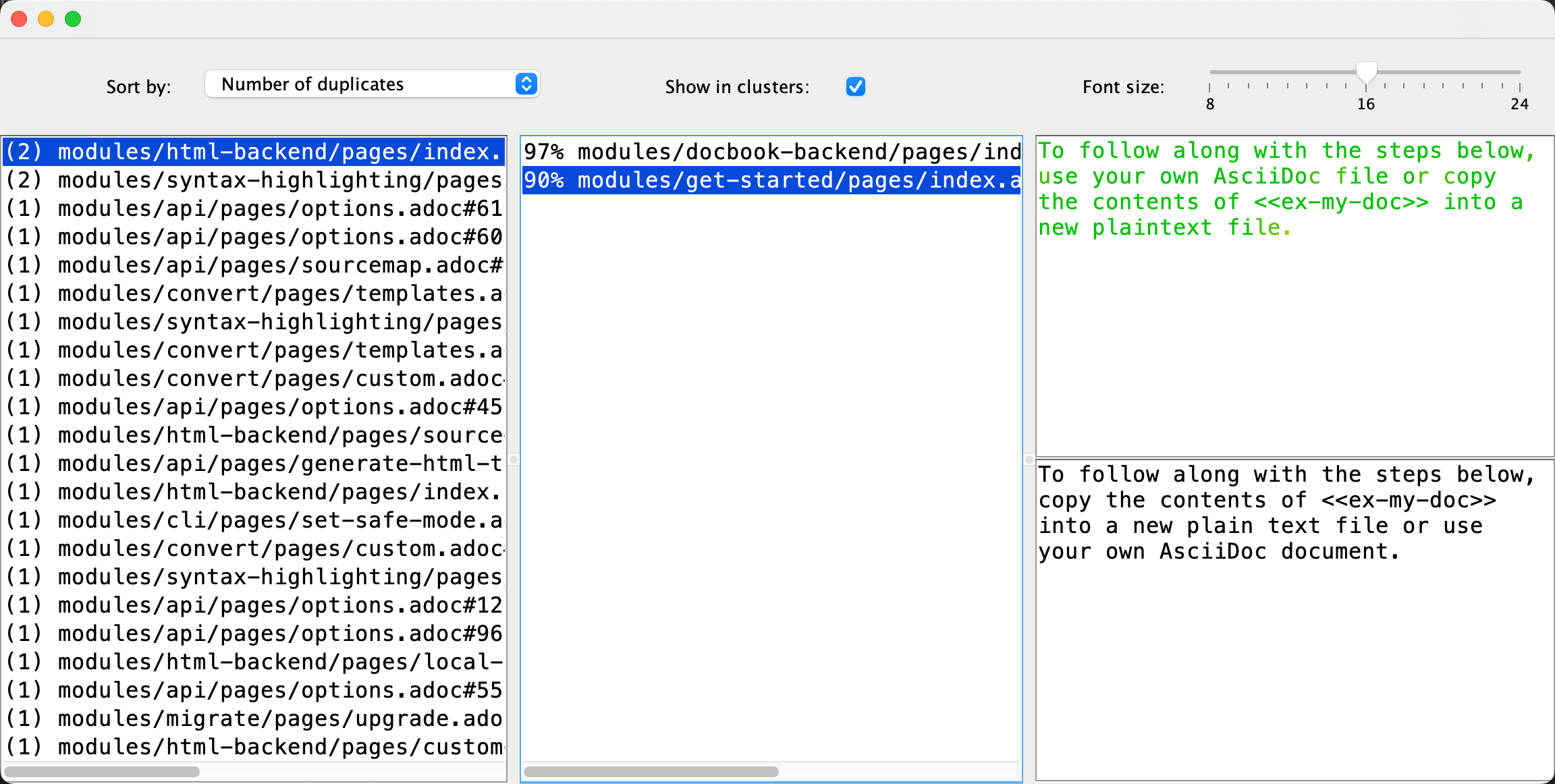
Le projet avec les changements commites est sur mon GitHub. Pour essayer la nouvelle version de l’application, vous pouvez trouver les instructions et le lien de telechargement sur la page Duplicate Finder. Dans l’ensemble, l’implementation n’est peut-etre pas parfaite, et elle necessite certainement une verification plus approfondie, mais je suis quand meme tres impressionne par ce qu’on peut accomplir en 5 minutes de nos jours.
Si vous souhaitez essayer Junie vous-meme, vous pouvez vous inscrire a l’EAP ici.