텍스트 중복 찾기: 요구 사항
다른 언어: English Español Français Deutsch 日本語 Português 中文

저는 중복 찾기 프로젝트에 대한 소개를 게시한 지 오래 되었습니다. 그래서 진도를 나가는 것이 적절해 보입니다. 프로그램 코드를 작성하기 전에 먼저 요구 사항을 나열하는 것이 합리적입니다. 이를 위한 좋은 방법은 테스트를 작성하는 것입니다. 테스트는 우리가 더 빠르게 개발할 수 있게 도와주며, 또한 코드가 사양을 준수하도록 보장합니다.

요구 사항
이 섹션에서는 제가 중복 찾기의 주요 기능에 대해 아이디어를 제시했습니다. 이들은 제 어플리케이션에 잘 작동합니다. 그러나 각 프로젝트는 다른 요구 사항이 있을 수 있으므로, 당신의 아이디어를 듣고 구현하는 것이 기쁩니다.
정확한 일치와 퍼지 일치 모두 감지
중복 감지 도구는 개별 심볼에 이르는 세밀함으로 정확한 일치와 퍼지 일치 모두를 찾을 수 있어야 합니다. 예를 들어, 다음 텍스트를 유사하게 간주해야 합니다:
This is *one of the two texts* that the duplicate finder tool should *consistently* detect.This *is an example text* that the duplicate finder tool should detect *consistently*.추가적으로, 퍼지 중복의 경우, 유사도의 정도를 측정할 수 있어야 합니다. 이렇게 하면 우리는 빠르게 중복 쌍을 평가하고 텍스트 조각이 서로 얼마나 닮았는지에 따라 그들을 정렬할 수 있습니다.
언어에 구애받지 않음
잠재적인 대상 언어가 많기 때문에, 가능한 한 많은 언어를 지원하는 것이 좋습니다. 일부 접근 방식은 추가된 매 언어에 대해 별도의 유지 관리를 필요로 할 수 있는데, 이는 전혀 확장성이 없고 많은 리소스가 필요합니다. 이상적으로, 도구는 모든 일반 언어와 호환되는 휴리스틱 또는 언어에 구애받지 않는 알고리즘을 사용해야 합니다.
구성 가능
중복을 식별하는 기준은 조절 가능해야 하며, 설정은 다음과 같은 선상에 있어야 합니다:
- 분석되는 텍스트 조각의 길이
- 중복의 수
- 유사도의 정도
일반적으로, 섹션은 더 길고 더 자주 반복되면 중복 제거에 더 이롭습니다. 그러나 이것은 특정 응용 프로그램에 따라 다르기 때문에, 이러한 임계값에 대한 제어가 가능하다면 좋을 것입니다.
정의
기본 요구 사항을 정리하였으므로, 이제 코드 정의를 마련해야 합니다. 이 단계에서 우리가 필요로 하는 것은:
이 장의 코드는 모든 미래의 사용 경우를 대비하여 완벽할 필요는 없습니다 - 우리는 항상 조정을 위해 돌아올 수 있습니다.
청크
텍스트의 단위와 관련하여, 어떤 세부 사항이 우리에게 중요한가요? 우리의 목적을 위해, 나는 조각이 포함하는 텍스트, 그것이 포함된 파일의 경로, 그 파일 내의 라인 번호, 그리고 요소의 유형에 집중하겠습니다. 소스가 단순한 일반 텍스트가 아닌 경우에 한해서요:
class Chunk(
val content: String,
val path: Path,
val lineNumber: Int,
val type: String
)이 정의는 일부 뉘앙스를 고려하지 않습니다. 예를 들어, 우리는
content 필드를 생략할 수 있습니다.
이렇게하면 RAM을 절약할 수 있지만, 대신에 요소의 내용에 접근하는 속도가 느려질 것입니다,
왜냐하면 그러면 프로그램은 매번 디스크에서 읽어야 하기 때문이지만, 단 한 번만 읽으면 됩니다.
우리는 지금 성능을 위해 싸우고 있지 않으므로, 잠재적으로 최적이 아닌 선택이라도 괜찮습니다.
인터페이스
우리는 아직 구현을 가지고 있지 않으므로, 우리는 인터페이스에 대해 프로그래밍할 것입니다. 인터페이스는 우리의 함수가 입력으로 무엇을 사용해야하고 출력으로 무엇을 반환해야하는지 정의하고, 우리를 함수의 내부로부터 추상화합니다. 이는 사실상 계약을 만들어줍니다, 이를 통해 우리는 현재 테스트를 작성할 수 있습니다, 실제 알고리즘을 코드화하지 않아도. 미래에, 이것은 또한 대체 구현을 기존 테스트와 클라이언트 코드와 호환 가능하게 만듭니다.
interface DuplicateFinder {
fun find(
root: Path,
minSimilarity: Double,
minLength: Int,
minDuplicates: Int,
fileExtensions: List<String>?
): Map<Chunk, List<Chunk>>
}위 인터페이스가 받아들이는 매개 변수의 의미입니다:
-
root– 분석할 내용이 있는 폴더 -
minSimilarity– 두 개의Chunk객체가 중복으로 간주되기 위한 최소 유사도 백분율 -
minLength– 분석될Chunk의 최소content길이 -
minDuplicates– 보고될 중복의 클러스터에 대한 최소 중복 개수 -
fileExtensions– 관련 없는 파일을 필터링하기 위한 파일 확장자 마스크
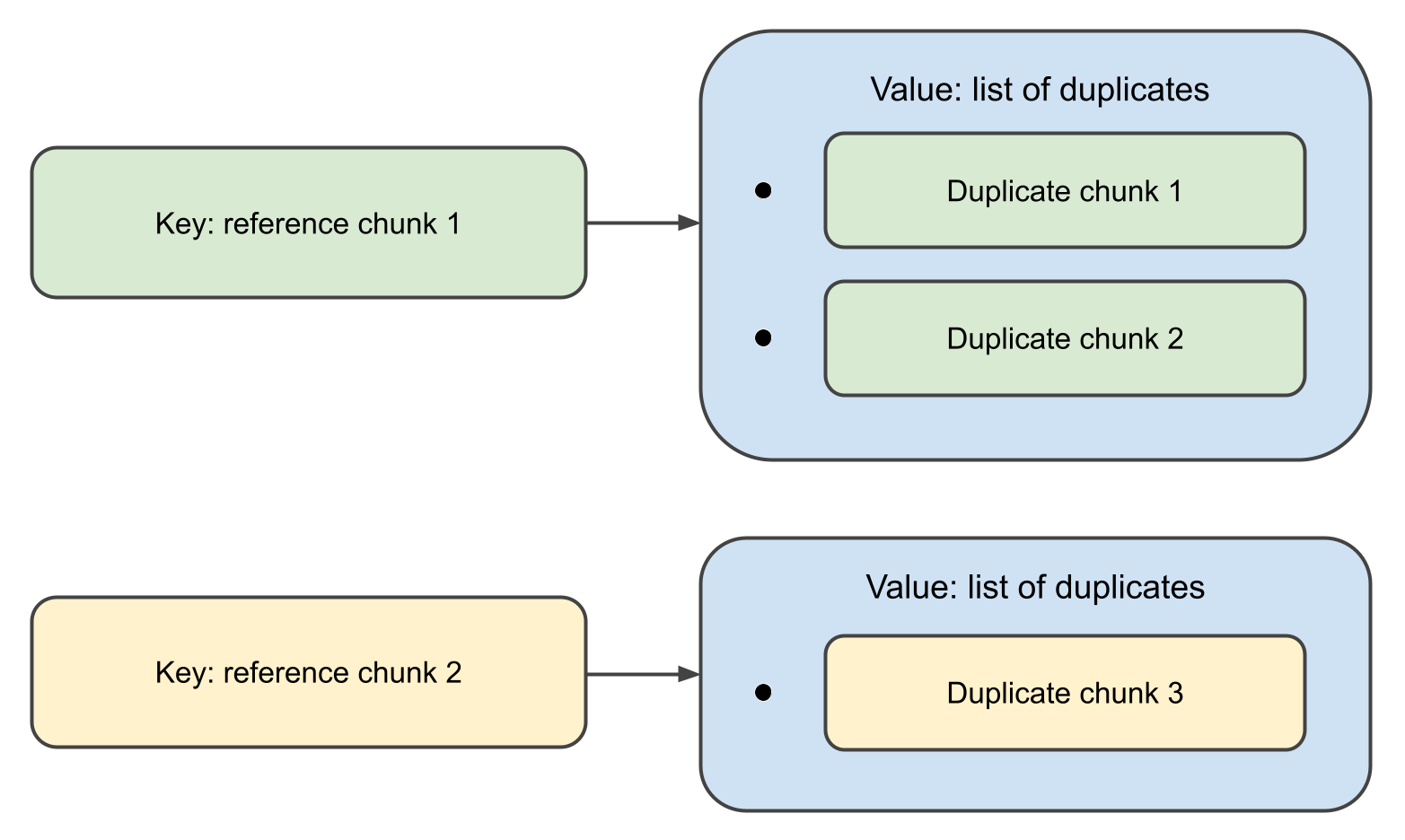
함수가 완료되면, 키가 Chunk 객체이고,
연결된 값이 그들의 중복 리스트인 맵을 반환할 것입니다.
사실, 위의 정의는 과도하게 장황합니다. 단일 함수와 몇 개의 호출자에 대한 인터페이스를 소개하는 것은 너무 많습니다. 코틀린은 이를 처리하는 세련된 방법을 가지고 있습니다. 첫 급 함수를 사용하는 것입니다:
val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()이 선언은 중복 찾기가
Path, DuplicateFinderOptions 를 받아서
Map<Chunk, List<Chunk>> 를 출력하는 함수이며,
함수 자체는 아직 구현되지 않았다는 것을 의미합니다.
이것은 대규모 프로젝트에 대한 최선의 스타일이 아닐 수 있지만, 우리의 것처럼 작은 것들에서는,
잘 작동합니다.
테스트 데이터
중복 찾기는 텍스트 데이터를 사용해야 하므로, 테스트도 일부 텍스트를 분석해야 합니다. 이는 우리가 모퍼지 중복이 포함된 일부 예를 준비해야 함을 의미합니다. 이제 중복부터 시작하겠습니다:
val EXACT_MATCH = "This is an exact match. It will be inserted in the test data as-is."
val FUZZY_MATCH_TEMPLATE = "This is a fuzzy match. It will be inserted in the test data with minor changes." FUZZY_MATCH_TEMPLATE 뒤의 아이디어는 우리가 그것을 사용해 실제 퍼지 일치를 프로그래밍 방식으로 산출하는 것입니다:
val fuzzyMatches = listOf(
"123 $FUZZY_MATCH_TEMPLATE",
"234 $FUZZY_MATCH_TEMPLATE",
"$FUZZY_MATCH_TEMPLATE 567",
"$FUZZY_MATCH_TEMPLATE 789",
FUZZY_MATCH_TEMPLATE.removeRange(5, 10),
FUZZY_MATCH_TEMPLATE.removeRange(10, 15)
)다음으로, 우리는 무작위 영어 단어로 구성된 텍스트를 생성합니다:
fun generateTestData(
wordsFile: String,
outputDir: String,
numOutputFiles: Int,
linesPerFile: Int,
wordsPerLine: Int
) {
val words = File(wordsFile).readLines()
.map { it.trim() }
.filter { it.isNotEmpty() }
repeat(numOutputFiles) { fileIndex ->
val outputFile = Path.of(outputDir).resolve("test_data_${fileIndex + 1}")
val fileContent = StringBuilder().apply {
repeat(linesPerFile) {
val line = (1..wordsPerLine).joinToString(" ") { words.random() }
append(line + "\n")
}
}
outputFile.writeText(fileContent.toString())
}
}마지막으로, 우리는 EXACT_MATCH
와 fuzzyMatches 를 생성된 텍스트에 랜덤하게 주입합니다:
fun injectDuplicates(testDataDir: String) = Files.list(Path.of(testDataDir)).toList().apply {
random().also { println("Exact match 1 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
random().also { println("Exact match 2 inserted in file: ${it.fileName}") }.appendText("$EXACT_MATCH\n")
fuzzyMatches.forEach { random().appendText("$it\n") }
}테스트
이미 언급했듯이, 이 시점에서 테스트의 주요 목표는 사양을 정의하는 것이므로, 테스트 스위트를 완성하는 데 너무 많은 시간을 낭비하지 않겠습니다. 대신, 우리는 미래의 코드가 요구 사항을 준수하도록 보장하는 데 충분한 만큼만 써보겠습니다.
테스트 클래스의 코드입니다:
const val WORDS_FILE = "./src/test/resources/words"
const val TEST_DATA_DIR = "./src/test/data"
const val NUM_TEST_FILES = 100
const val LINES_PER_FILE = 100
const val WORDS_PER_LINE = 20
private val duplicateFinder: (Path, DuplicateFinderOptions) -> Map<Chunk, List<Chunk>> = TODO()
class DuplicateFinderTest {
@BeforeTest
fun setup() {
generateTestData(
WORDS_FILE,
TEST_DATA_DIR,
NUM_TEST_FILES,
LINES_PER_FILE,
WORDS_PER_LINE
)
injectDuplicates(TEST_DATA_DIR)
}
@Test
fun test() {
val options = DuplicateFinderOptions(
minSimilarity = 0.9,
minLength = 20,
minDuplicates = 1
)
val report = duplicateFinder(Path.of(TEST_DATA_DIR), options)
val duplicates = report.duplicates
assert(fuzzyMatches.all { it in duplicates.texts() })
assert(EXACT_MATCH in duplicates.texts())
}
}
private fun Map<Chunk, List<Chunk>>.texts() = (keys + values.flatten()).map { it.content }다음 단계
인터페이스를 정의하고 테스트를 작성하여 요구 사항을 정륩했습니다. 시리즈의 다음 게시물에서는 실제 알고리즘을 구현하고 어떻게 성능을 발휘하는지 살펴볼 것입니다. 곧 뵙겠습니다!