AI를 이용한 애플리케이션 지역화
다른 언어: English Español Français Deutsch 日本語 Português 中文
프로젝트를 지역화하려고 생각하고 있거나 어떻게 하는지 배우고 싶은 경우, AI가 좋은 시작점이 될 수 있습니다. 실험 및 자동화에 대한 비용 효율적인 진입점을 제공합니다.
이 글에서는 이러한 실험 중 하나를 살펴보겠습니다. 다음과 같은 일을 할 것입니다.
- 오픈소스 애플리케이션 선택
- 사전 요건 검토 및 구현
- AI를 사용하여 번역 단계 자동화

지역화에 대해 처음 다루어 보는 경우 여기서 시작하는 것이 좋을 수 있습니다. 몇 가지 기술적인 세부 사항을 제외하면 접근 방식은 대체로 보편적이며, 다른 유형의 프로젝트에 적용할 수 있습니다.
기본 사항에 이미 익숙하고 그냥 AI가 어떻게 작동하는지 보고 싶은 경우, 텍스트 번역 으로 건너뛰거나 내 fork를 클론하여 커밋을 빠르게 살펴보고 결과를 평가할 수 있습니다.
프로젝트 가져오기
지역화 실험을 위해 새로운 애플리케이션을 만드는 것은 오버킬일 수 있으므로, 어떤 오픈소스 프로젝트를 포크합시다. 나는 Spring Petclinic, Java의 Spring 프레임워크를 보여주는 예제 웹 앱을 선택했습니다.
gh repo fork https://github.com/spring-projects/spring-petclinic --clone=trueSpring을 사용해 본 적이 없다면, 일부 코드 스니펫이 익숙하지 않을 수 있습니다. 하지만 이미 언급했듯이, 이 논의는 기술 중립적입니다. 언어와 프레임워크에 관계없이 단계는 대체로 동일합니다.
Internationalization
애플리케이션을 지역화하기 전에 국제화해야 합니다.
국제화 (또는 i18n)은 소프트웨어가 다른 언어를 지원하게끔 적응시키는 과정입니다. 일반적으로 UI 문자열을 리소스 번들이라고 하는 특별한 파일로 외부화하는 것으로 시작합니다.
리소스 번들은 다른 언어에 대한 텍스트 값을 보유합니다:
en.json:
{
"greeting": "Hello!",
"farewell": "Goodbye!"
}es.json:
{
"greeting": "¡Hola!",
"farewell": "¡Adiós!"
}이 값들이 UI로 나아가기 위해서는, UI가 명시적으로 이 파일들을 사용하도록 프로그래밍되어야 합니다.
이는 일반적으로 국제화 라이브러리 또는 내장 언어 기능을 포함하며, 그 목적은 UI 텍스트를 주어진 로케일에 대한 올바른 값으로 대체하는 것입니다. 이러한 라이브러리의 예로는 i18next (JavaScript), Babel (Python), 그리고 go-i18n (Go)가 있습니다.
Java는 박스에서 국제화를 지원하므로, 프로젝트에 추가 종속성을 가져올 필요가 없습니다.
소스 검토
Java는 사용자 인터페이스의 지역화된 문자열을 저장하기 위해 .properties 확장 파일을 사용합니다.
다행히도, 이미 몇 개의 파일들이 프로젝트에 있습니다. 예를 들어, 영어와 스페인어에 대해 우리가 가진 것은 다음과 같습니다:
welcome=Welcome
required=is required
notFound=has not been found
duplicate=is already in use
nonNumeric=must be all numeric
duplicateFormSubmission=Duplicate form submission is not allowed
typeMismatch.date=invalid date
typeMismatch.birthDate=invalid datewelcome=Bienvenido
required=Es requerido
notFound=No ha sido encontrado
duplicate=Ya se encuentra en uso
nonNumeric=Sólo debe contener numeros
duplicateFormSubmission=No se permite el envío de formularios duplicados
typeMismatch.date=Fecha invalida
typeMismatch.birthDate=Fecha invalidaUI 문자열을 외부화하는 것은 모든 프로젝트가 보편적으로 하는 것은 아닙니다. 일부 프로젝트는 이런 텍스트를 직접 애플리케이션 로직에 하드 코딩할 수 있습니다.

UI 텍스트를 외부화하는 것은 국제화 이상의 장점이 있는 좋은 관행입니다. 코드 유지 보수를 용이하게 하며, UI 메시지의 일관성을 증진합니다. 프로젝트를 시작하는 경우 가능한 한 빨리 i18n을 구현해야 합니다.
테스트 실행
URL 매개변수를 통해 로케일을 변경하는 방법을 추가해봅시다. 이렇게 하면 전부 외부화되고 적어도 한 언어로 번역되었는지 테스트할 수 있습니다.
이를 달성하기 위해, 로케일 매개변수를 관리하기 위해 다음 클래스를 추가합니다:
import java.util.Locale;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public LocaleResolver localeResolver() {
SessionLocaleResolver slr = new SessionLocaleResolver();
slr.setDefaultLocale(Locale.US);
return slr;
}
@Bean
public LocaleChangeInterceptor localeChangeInterceptor() {
LocaleChangeInterceptor lci = new LocaleChangeInterceptor();
lci.setParamName("lang");
return lci;
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(localeChangeInterceptor());
}
}이제 다른 로케일을 테스트할 수 있게 되었으므로, 서버를 실행하고 여러 로케일 매개변수에 대한 홈페이지를 비교해봅니다:
- http://localhost:8080 – 기본 로케일
- http://localhost:8080/?lang=es – 스페인어
- http://localhost:8080/?lang=ko – 한국어
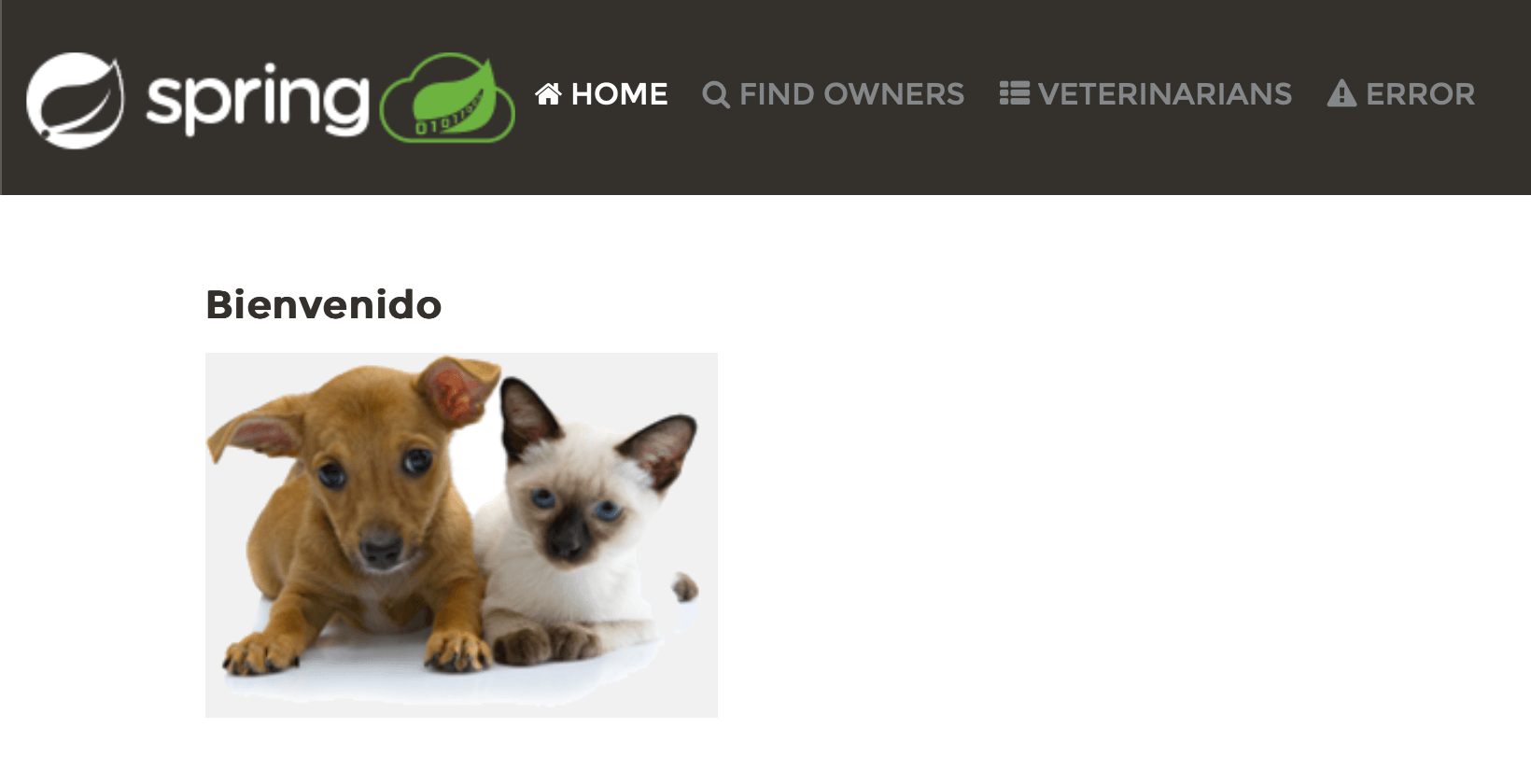
로케일 변경이 UI에 반영되는 것을 확인할 수 있습니다. 좋은 소식입니다. 그러나 로케일 변경은 일부 텍스트에만 영향을 준 것 같습니다. 스페인어의 경우, Welcome이 Bienvenido로 바뀌었지만, 헤더의 링크는 같은 것으로 유지되었으며, 다른 페이지들은 여전히 영어입니다. 이는 우리가 해야 할 일이 있다는 것을 의미합니다.
템플릿 수정
Spring Petclinic 프로젝트는 Thymeleaf 템플릿을 사용하여 페이지를 생성하므로, 템플릿 파일을 살펴봅시다.
실제로 일부 텍스트가 하드코딩되어 있으므로, 코드를 수정하여 리소스 번들을 참조하도록 해야 합니다.
다행히도, Thymeleaf는 Java .properties 파일을 잘 지원하므로,
템플릿에 바로 해당 리소스 번들 키를 참조할 수 있습니다:
<h2>Find Owners</h2><h2 th:text='#{heading.find.owners}'>Find Owners</h2>heading.find.owners=Find Owners이전에 하드 코딩된 텍스트는 여전히 존재하지만 이제 백업 값으로 사용되며, 이는 적절한 로컬화된 메시지를 검색하는 데 오류가 발생할 경우에만 사용됩니다.
나머지 텍스트는 비슷한 방식으로 외부화되지만, 일부 위치는 특별한 주의가 필요합니다. 예를 들어, 일부 경고는 검증 엔진에서 나오므로 Java 주석 매개변수를 사용하여 지정해야 합니다:
@Column(name = "first_name")
@NotBlank
private String firstName;@Column(name = "first_name")
@NotBlank(message = "{field.validation.notblank}")
private String firstName;몇몇 장소에서는 로직을 변경해야 합니다:
<h2>
<th:block th:if="${pet['new']}">New </th:block>Pet
</h2>위의 예에서 템플릿은 조건을 사용합니다. new 속성이 있으면,
UI 텍스트에 New가 추가됩니다.
그 결과, 속성의 존재 여부에 따라 결과 텍스트는 New Pet 또는 Pet이 됩니다.
이는 일부 지역에 대한 로컬라이제이션을 방해할 수 있습니다. 이는 명사와 형용사 사이의 일치 때문입니다. 예를 들어, 스페인어에서 형용사는
Nuevo 또는 Nueva
이며, 이는 명사의 성별에 따라 달라지며, 기존의 로직은 이 구별을 고려하지 않습니다.
이 상황에 대한 한 가지 가능한 해결책은 로직을 더욱 복잡하게 만드는 것입니다. 일반적으로 가능한 한 복잡한 로직을 피하는 것이 좋지만, 따라서 나는 대신 분기를 분리하는 것을 선택했습니다:
<h2>
<th:block th:if="${pet['new']}" th:text="#{pet.new}">New Pet</th:block>
<th:block th:unless="${pet['new']}" th:text="#{pet.update}">Pet</th:block>
</h2>분리된 분기는 또한 번역 과정을 단순화하고 코드베이스의 미래 유지보수를 용이하게 합니다.
New Pet 폼에도 트릭이 있습니다. 그것의 Type 드롭다운은 selectField.html 템플릿에 애완동물 타입의 컬렉션을 전달함으로써 생성됩니다:
<input th:replace="~{fragments/selectField :: select (#{pet.type}, 'type', ${types})}" />다른 UI 텍스트와 달리, 애완동물 타입은 애플리케이션의 데이터 모델의 일부입니다. 그들은 런타임에 데이터베이스에서 출처를 가집니다. 이 데이터의 동적인 성격은 우리가 텍스트를 직접 속성 번들로 추출하는 것을 방지합니다.
이를 처리하는 데는 여러 가지 방법이 있습니다. 한 가지 방법은 템플릿에서 속성 번들 키를 동적으로 구성하는 것입니다:
<option th:each="item : ${items}"
th:value="${item}"
th:text="${item}">dog</option><option th:each="item : ${items}"
th:value="${item}"
th:text="#{'pettype.' + ${item}}">dog</option>이 접근법에서는 UI에서 cat 을 직접 렌더링하는 대신 pettype. , 으로 접두사를 붙여
pettype.cat 을 얻습니다. 그런 다음 이 문자열을 사용하여 로컬화된 UI 텍스트를 검색하는 키로 사용합니다:
pettype.bird=bird
pettype.cat=cat
pettype.dog=dogpettype.bird=pájaro
pettype.cat=gato
pettype.dog=perro
재사용 가능한 컴포넌트의 템플릿을 수정했다는 것을 주목했을지 모릅니다. 재사용 가능한 컴포넌트는 여러 클라이언트에게 서비스를 제공하기 위해 만들어졌기 때문에, 클라이언트 로직을 끌어들이는 것은 올바르지 않습니다.
이 특정 경우에서, 드롭다운 리스트 컴포넌트는 애완동물 타입에 묶여 있어, 그것을 다른 목적으로 사용하려는 사람에게 문제가 됩니다.
이 결점은 처음부터 있었습니다 - 옵션의 기본 텍스트로 dog 을 참조하세요.
우리는 이 결점을 더욱 확산했습니다.
이는 실제 프로젝트에서는 하지 말아야 할 일이며 리팩토링이 필요합니다.
물론, 국제화하려는 프로젝트 코드는 더 있습니다. 하지만 그것의 대부분은 위의 예제와 일치합니다. 내가 한 모든 변경 사항에 대한 완전한 검토를 원한다면, 나의 포크에서 커밋을 확인하실 수 있습니다.
누락된 키 추가
모든 UI 텍스트를 속성 번들 키에 대한 참조로 교체한 후에 우리는 이 새로운 키를 모두 도입해야 합니다. 이 시점에는 아무것도 번역할 필요가 없습니다, 그저 키와 원문들을 messages.properties 파일에 추가하세요.
IntelliJ IDEA는 Thymeleaf를 잘 지원합니다. 템플릿이 참조하는 누락된 속성을 감지하므로, 많은 수동 검사 없이 누락된 키들을 찾을 수 있습니다:
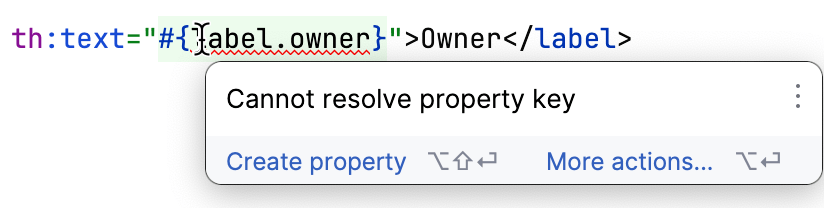
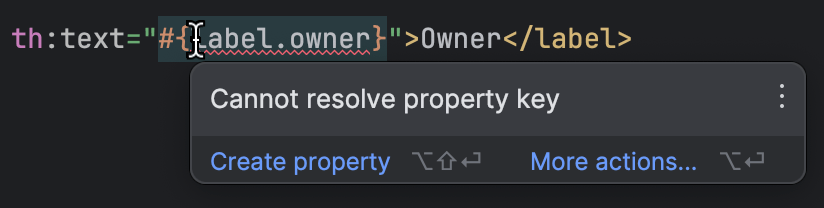
모든 준비가 완료되면 우리는 일의 가장 흥미로운 부분에 도달하게 됩니다. 우린 모든 키들을 가지고 있고, 영어에 대한 모든 값들을 가지고 있습니다. 다른 언어에 대한 값들은 어디서 얻을 수 있을까요?
텍스트 번역
텍스트를 번역하는 데 있어서, 우리는 외부 번역 서비스를 사용하는 스크립트를 만들 예정입니다. 번역 서비스는 많은 종류가 있으며, 해당 스크립트를 작성하는 방법도 여러 가지입니다. 다음과 같은 것들을 구현을 위한 선택으로 선택했습니다:
- 프로그래밍 언어로는 Python, 왜냐하면 이는 작은 작업들을 빠르게 프로그래밍 하는 것을 허용하기 때문입니다
- 번역 서비스로는 DeepL입니다. 원래는 OpenAI의 GPT3.5 Turbo를 사용하려고 계획했었지만, 이는 엄밀히 말하면 번역 모델이 아니므로, 프롬프트를 설정하는 데 추가적인 노력이 필요합니다. 또한, 결과는 덜 안정적이기 때문에, 마음이 먼저 떠오른 전용 번역 서비스를 선택했습니다
나는 확장된 연구를 하지 않았으므로, 이러한 선택들은 다소 임의적입니다. 가장 잘 맞는 것을 찾기 위해 실험하고 발견하는 것을 자유롭게 느껴주세요.
아래 스크립트를 사용하는 것을 결정하게 된다면, DeepL과 계정을 만들어야 하며
개인 API 키를 DEEPL_KEY 환경 변수를 통해 스크립트에 전달해야 합니다
스크립트는 아래와 같습니다:
import os
import requests
import json
deepl_key = os.getenv('DEEPL_KEY')
properties_directory = "../src/main/resources/messages/"
def extract_properties(text):
properties = {}
for line in text:
line = line.strip()
if line and not line.startswith('#') and '=' in line:
key_value = line.split('=')
key = key_value[0].strip()
value = key_value[1].strip()
if key and value:
properties[key] = value
return properties
def missing_properties(properties_file, properties_checklist):
with open(properties_file, 'r') as f:
text = f.readlines()
present_properties = extract_properties(text)
missing = {k: v for k, v in properties_checklist.items() if k not in present_properties.keys()}
return missing
def translate_property(value, target_lang):
headers = {
'Content-Type': 'application/json',
'Authorization': f'DeepL-Auth-Key {deepl_key}',
'User-Agent': 'LocalizationScript/1.0'
}
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()["translations"][0]["text"]
def populate_properties(file_path, properties_checklist, target_lang):
with open(file_path, 'a+') as file:
properties_to_translate = missing_properties(file_path, properties_checklist)
for key, value in properties_to_translate.items():
new_value = translate_property(value, target_lang)
property_line = f"{key}={new_value}\n"
print(property_line)
file.write(property_line)
with open(properties_directory + 'messages.properties') as base_properties_file:
base_properties = extract_properties(base_properties_file)
languages = [
# configure languages here
"nl", "es", "fr", "de", "it", "pt", "ru", "ja", "zh", "fi"
]
for language in languages:
populate_properties(properties_directory + f"messages_{language}.properties", base_properties, language)
스크립트는 기본 속성 번들에서 ( messages.properties ) 키를 추출하고 언어별 번들에서 그들의 번역을 찾습니다. 만약 특정 키가 번역이 누락되었다면, 스크립트는 DeepL API에서 번역을 요청하고 속성 번들에 추가합니다.
나는 10개의 대상 언어를 지정했지만, DeepL 그것들을 지원하는 한, 목록을 수정하거나 선호하는 언어를 추가할 수 있습니다.
스크립트는 번역을 위한 텍스트를 50개 씩 배치로 보낼 수 있도록 추가 최적화할 수 있습니다. 여기서는 형태를 간단하게 유지하기 위해 이를 수행하지 않았습니다.
나중에, 저는 구조화된 출력을 사용하는 LLM으로 스크립트를 업데이트했습니다. 여기서 결과를 확인해보세요.
스크립트 실행
10개 언어에 대해 스크립트를 실행하는 데 대략 5분이 걸렸습니다. 사용량 대시보드는 8348 문자를 보여주며, 이는 유료 플랜에 있었다면 €0.16의 비용을 발생했을 것입니다.
결과적으로, 아래 파일들이 생성됩니다:
- messages_fi.properties
- messages_fr.properties
- messages_it.properties
- messages_ja.properties
- messages_nl.properties
- messages_pt.properties
- messages_ru.properties
- messages_zh.properties
또한, 누락된 속성들이 추가되었습니다:
- messages_de.properties
- messages_es.properties
하지만 실제 번역에 대해서는 어떤가요? 우리는 이미 그것들을 볼 수 있을까요?
결과 확인
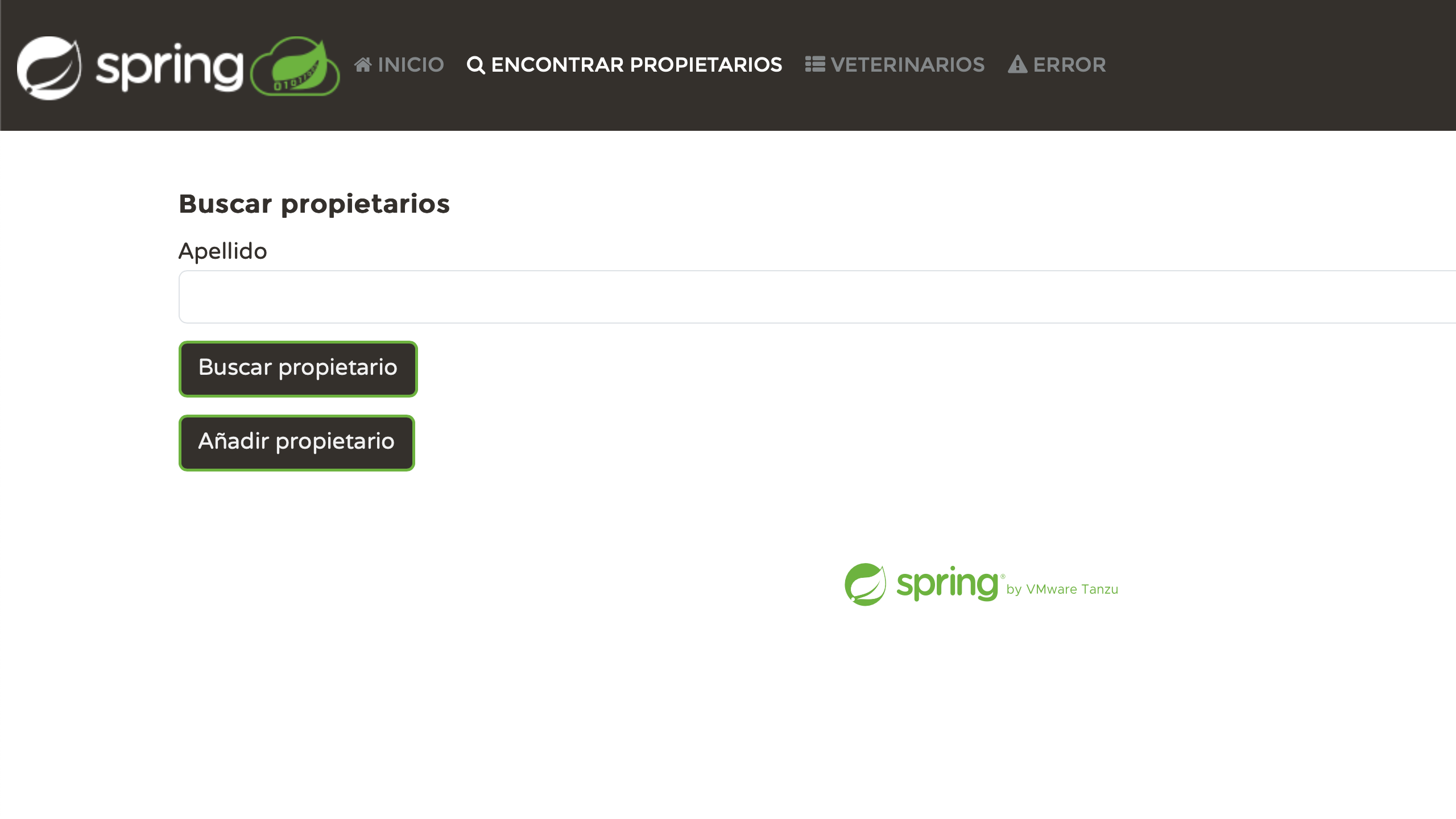
어플리케이션을 다시 시작하고 다른 lang 파라미터 값들을 사용하여 테스트합시다. 예를 들면:
- http://localhost:8080/?lang=es
- http://localhost:8080/?lang=nl
- http://localhost:8080/?lang=zh
- http://localhost:8080/?lang=fr
개인적으로는 각 페이지가 올바르게 로컬라이즈된 것을 보는 것은 매우 만족스럽습니다. 우리는 몇몇 노력을 기울였고, 이제 그것이 보상을 주고 있습니다:

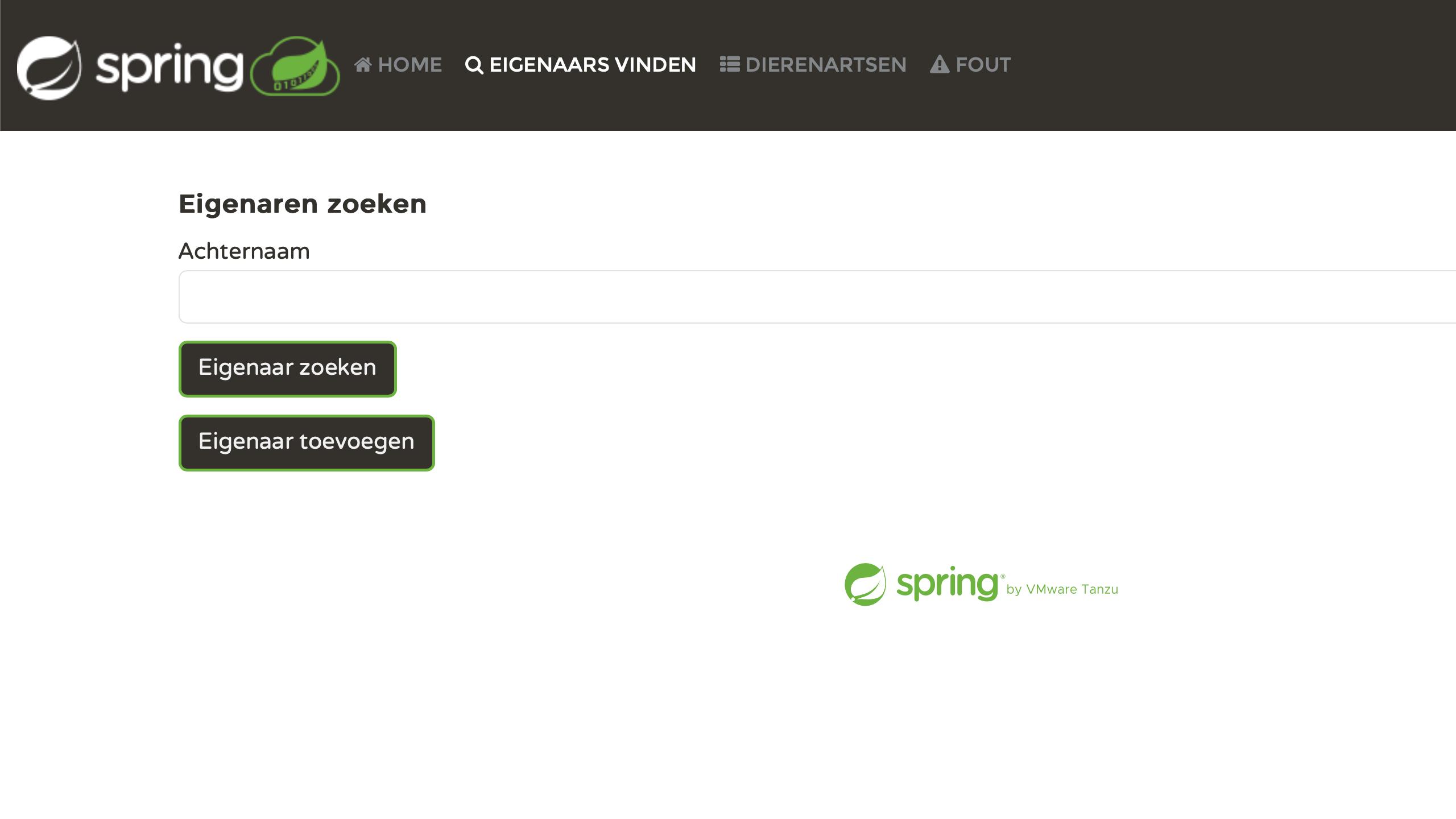

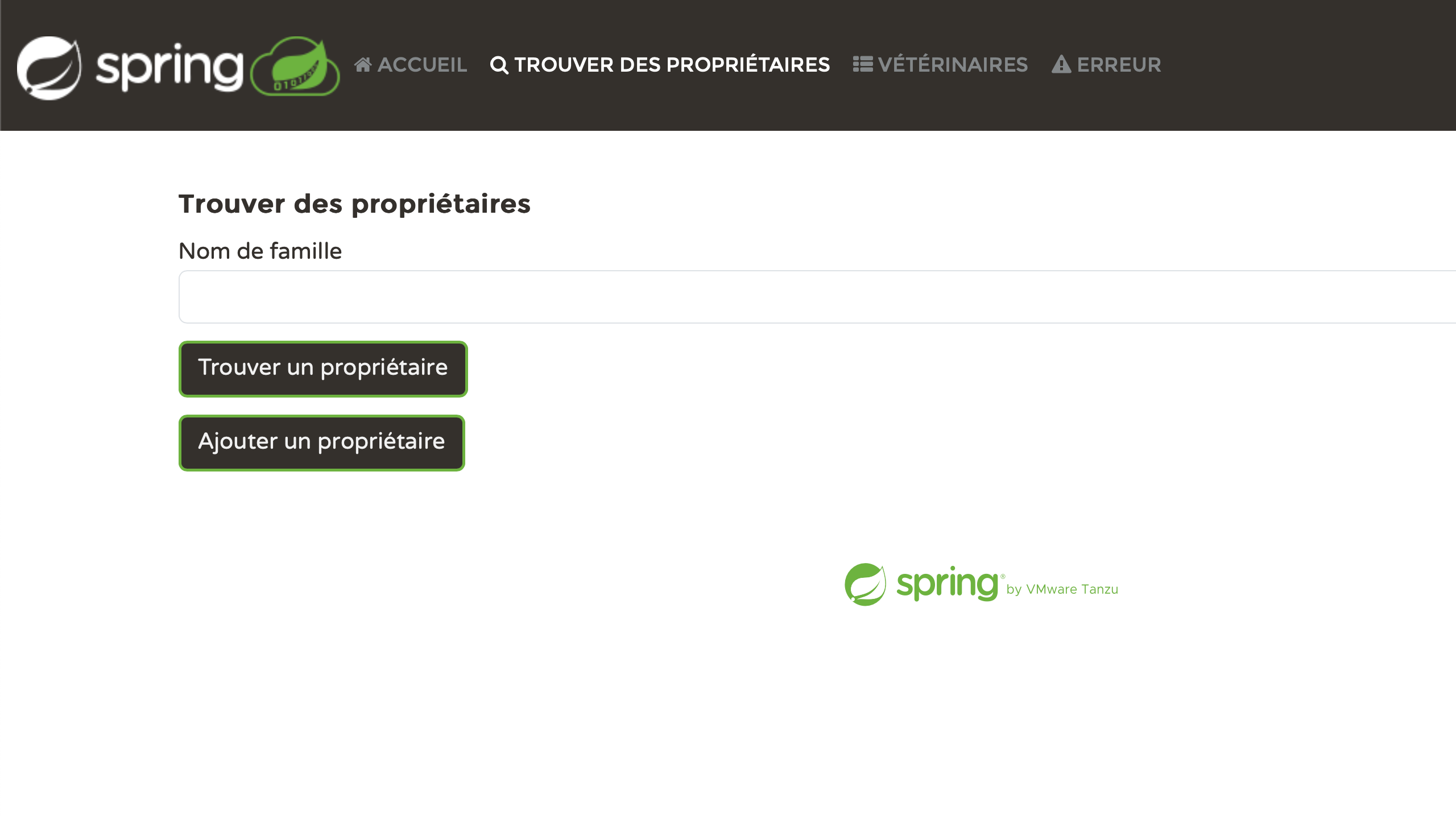
문제점 다루기
결과는 인상적입니다. 그러나 심하게 살펴보면, 부족한 맥락으로 인해 발생하는 실수를 발견할 수 있을 것입니다. 예를 들면:
visit.update = Visit Visit 은 명사와 동사 둘 다 될 수 있습니다. 추가 맥락이 없으면 번역
서비스는 일부 언어에서 잘못된 번역을 생성합니다.
이는 수동 편집을 통해, 또는 번역 작업흐름을 조정함으로써 해결될 수 있습니다. 하나의 가능한 해결책은 .properties 파일에서 주석을 사용하여 맥락을 제공하는 것입니다:
# Noun. Heading. Displayed on the page that allows the user to edit details of a veterinary visit
visit.update = Visit우리는 번역 스크립트를 수정하여 이와 같은 주석들을 파싱하고 이것들을 context 파라미터로 전달할 수 있습니다.
url = 'https://api-free.deepl.com/v2/translate'
data = {
'text': [value],
'source_lang': 'EN',
'target_lang': target_lang,
'preserve_formatting': True,
'context': context
}우리가 더 깊게 파고들고 더 많은 언어를 고려하면, 우리는 개선해야 할 더 많은 것들을 찾을 수 있을 것입니다. 이는 반복적인 과정입니다.
이 과정에서 하나의 필수적인 것이 있다면, 그것은 리뷰와 테스팅입니다. 자동화를 개선하든 그 출력을 편집하든, 우리는 품질 통제와 평가를 실시하는 것이 필요하다는 것을 발견할 것입니다.
범위를 벗어난 것들
Spring 펫 클리닉은 간단하지만 현실적인 프로젝트이며, 우리가 방금 해결한 문제들과 같습니다. 물론, 로컬라이제이션은 이 기사의 범위를 벗어난 많은 도전을 제시합니다. 포함되지 않는 것들은:
- 대상 문법 규칙에 맞게 템플릿 조정
- 통화, 날짜, 숫자 형식
- 다른 독서 패턴, 예를 들어 RTL
- 변동하는 텍스트 길이에 대한 UI 적응
이러한 각 주제는 자체적으로 작성을 필요로 합니다. 더 읽고 싶다면, 이러한 주제들을 개별 게시물에서 다루게 되면 기쁠 것입니다.
요약
좋아요, 이제 우리 애플리케이션의 로컬라이제이션을 완료했으니, 우리가 배운 것을 되짚어 보아요:
- 로컬라이제이션은 단순히 텍스트 번역 뿐만 아니라 관련 자산, 하위시스템, 프로세스에도 영향을 미칩니다
- AI는 로컬라이제이션의 일부 단계에서 매우 효율적이지만, 인간의 감독과 테스팅은 최고의 결과를 달성하기 위해 여전히 필요합니다
- 자동 번역의 품질은 여러 요인에 따라 다르며, 맥락의 가용성과, LLMs의 경우, 적절하게 작성된 프롬프트를 포함합니다
이 기사를 즐겁게 읽었기를 바랍니다, 그리고 제가 귀하의 피드백을 듣기를 기대합니다! 추가 질문이 있거나, 제안하거나, 그냥 대화를 나누고 싶다면, 망설이지 말고 연락해 주세요.
미래의 게시물에서 여러분을 보게 되어 기쁩니다!