Skill de IA para Depurar Testes Instáveis
Outras línguas: EnglishEspañolFrançaisDeutsch日本語한국어中文
Se você está conectado à internet há algum tempo, com certeza já ouviu falar de skills de agentes de IA. Elas ensinam seu agente a fazer isto e aquilo. Você pode até já ter usado ou escrito algumas você mesmo.
Se ainda não está familiarizado com elas, a ideia é simples: em vez de escrever instruções para uma tarefa específica a cada vez, você as define uma vez e as reutiliza depois. Uma skill é o equivalente em IA de um artigo de base de conhecimento: um documento de texto puro que reside em um local descobrível e descreve passos, um conjunto de convenções ou conhecimento específico de domínio.
A maioria das skills que você vê por aí servem para coisas simples, como impor estilo de código ou convenções de mensagens de commit. Mas elas podem ser muito mais poderosas do que isso. Neste artigo, vamos combinar skills de IA, boas e velhas ferramentas de desenvolvedor e um pouco de pensamento criativo para abordar uma tarefa notoriamente desafiadora: fazer com que a IA encontre deterministicamente a causa raiz de testes instáveis.
O problema
Citando o guia de CI/CD do TeamCity:
Testes instáveis são definidos como testes que retornam tanto aprovações quanto falhas, apesar de não haver mudanças no código ou no próprio teste.
A instabilidade mina todo o propósito dos testes: quando um teste falha, você não consegue dizer se algo está realmente quebrado. Você não pode confiar totalmente nos resultados dos testes e, ao mesmo tempo, não pode ignorá-los. Isso desperdiça recursos humanos e de infraestrutura.
E como se os bugs subjacentes já não fossem difíceis o bastante por si só, testes instáveis frequentemente têm essa propriedade de falhar uma vez a cada vários milhares de execuções, tornando-os extremamente difíceis de reproduzir e depurar.
Projeto de exemplo
Para o projeto de exemplo, vamos usar a demo do webshop deste artigo: Seus programas não são single-threaded. É um projeto Spring Boot, no qual um dos serviços tem um problema de TOCTOU (time-of-check to time-of-use): ele verifica uma condição e age sobre ela, mas outra thread pode mudar o estado entre uma coisa e outra. Neste caso específico, isso pode ocasionalmente causar números de fatura duplicados e também torna o teste correspondente instável.
Aqui está o teste problemático:
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}O teste cria duas ordens simultaneamente e verifica se as faturas resultantes
recebem os números INV-00001 e INV-00002 .
Por causa de um bug em InvoiceService ,
ele pode passar ou falhar aleatoriamente.
Se você usa o IntelliJ IDEA, pode testar se um teste é realmente instável usando a opção Run until failure no executor de testes. Deixe o suspeito rodando por um tempo e veja se ele eventualmente falha.
Se não soubéssemos nada sobre o bug subjacente e tivéssemos apenas o teste, existiria alguma ferramenta que pudesse nos ajudar a encontrar a causa raiz? Ou poderíamos criar uma nós mesmos? Além disso, poderíamos delegar tanto a construção quanto o uso da ferramenta para a IA?
A intuição
Vamos desenvolver uma intuição para essa classe de problema.
Para produzir dois tipos de resultados, a execução
deve seguir caminhos de código diferentes.
A diferença pode ser mínima, possivelmente apenas uma chamada de método extra
ou um ramo de if tomado em vez de outro.
Mas ela tem que estar lá; caso contrário, o resultado seria consistente.
Então, se pudéssemos registrar o caminho de código de uma execução bem-sucedida e de uma execução com falha
e depois compará-los, o diff deveria pelo menos nos apontar a direção certa.
E, idealmente, seguindo a árvore de chamadas, poderíamos encontrar o lugar onde a execução se divide.
Essa linha deve ser exatamente onde a instabilidade se origina.
Esse raciocínio faz sentido? Vamos colocá-lo à prova.
Construindo as ferramentas
Que ferramenta podemos usar para registrar caminhos de código? Embora não seja projetada especificamente para tracing, a cobertura de testes pode nos dar a informação que buscamos.
Há algumas ferramentas de cobertura para Java entre as quais escolher, como o JaCoCo e a ferramenta de cobertura do IntelliJ IDEA. Vamos usar a do IntelliJ IDEA, porque ela inclui a funcionalidade de contagem de hits. Podemos precisar dessa granularidade extra porque a instabilidade pode vir não só do que é executado, mas também de quantas vezes.
Executar a cobertura pela linha de comando
A ferramenta de cobertura do IntelliJ IDEA tem uma UI familiar, mas precisamos de uma forma de iniciá-la programaticamente. Felizmente, a cobertura também pode ser coletada pela linha de comando anexando o agente de cobertura à JVM via Maven Surefire:
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*"A flag -Didea.coverage.calculate.hits=true
diz ao agente para registrar contagens de invocação por linha em vez de apenas uma máscara booleana de hit/não-hit.
Após o término do teste, os resultados são gravados em um arquivo binário .ic .
Até aqui tudo bem, mas precisamos do relatório em um formato legível por humanos (e por IA).
Adicionar saída de texto
Felizmente, o agente de cobertura do IntelliJ é open-source. Vamos clonar o projeto e pedir para a IA adicionar um reporter de texto que converte relatórios binários em texto puro.
O agente cria uma nova classe chamada TextCoverageStatistics .
Depois de compilar o projeto e executar o reporter contra nosso arquivo .ic ,
obtemos algo assim:
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...A primeira parte do relatório dá uma visão geral de alto nível: quantas linhas, ramos e métodos foram cobertos em todo o projeto. Abaixo disso, há um detalhamento por classe mostrando as mesmas métricas para cada classe individualmente.
Em seguida, vêm as contagens de hits por linha para cada classe:
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...Para cada linha que o agente de cobertura instrumentou, vemos quantas vezes ela foi executada e se algum ramo foi tomado. O relatório real é mais longo, mas você entende a ideia. Agora temos uma representação textual de quais linhas foram executadas e exatamente quantas vezes.
Esta é a matéria-prima de que precisamos para o diff. Até aqui, tudo bem!
Comparar os relatórios
Supostamente, os relatórios obtidos contêm a informação necessária e um desenvolvedor muito determinado poderia analisá-los e encontrar o bug. Mas não estamos aqui para tarefas mundanas como essa, certo?
Vamos aprimorar a ferramenta para que ela receba múltiplas variações de relatório e apresente o diff. A maneira mais controlável seria fazer um “tijolo” de cada vez, mas acho que aqui podemos seguramente delegar a coisa toda para a IA, incluindo a automação:
O script resultante executa o teste em loop até que ambas as condições a seguir aconteçam:
- obtemos pelo menos uma execução bem-sucedida e uma com falha.
- o número especificado de execuções foi atingido.
Ambas as condições são importantes porque falhas de teste podem ser muito raras, e o número especificado de execuções pode não ser suficiente. Ao mesmo tempo, pode haver variações mais finas dentro das execuções pass e fail, então também queremos capturá-las.
Depois que os relatórios são coletados, o script resume as linhas que apresentam variações entre as execuções. Aqui está como isso se parece:
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)Todas as variações têm o mesmo padrão: a diferença não está em quais linhas foram executadas, mas em quantas vezes. Como esperávamos, a funcionalidade de contagem de hits do agente de cobertura do IntelliJ IDEA se mostrou útil!
As linhas variantes apontam para um bloco de inicialização preguiçosa em InvoiceService
e seus efeitos colaterais em InvoiceNumberGenerator
e Invoice .
A variação nas contagens de hits significa que a inicialização às vezes roda mais de uma vez,
o que não deveria acontecer. É exatamente daí que vem a instabilidade.
Se você perdeu o artigo que descreve o problema, eis por que a inicialização dupla causa esse bug.
O método createGenerator() consulta o banco de dados
em busca do último número de fatura usado e cria um contador começando a partir desse valor.
Quando duas threads entram no bloco if (generator == null)
antes que qualquer uma delas termine, cada uma lê o mesmo número do banco de dados
e cria seu próprio gerador começando a partir do mesmo valor.
O resultado são números de fatura duplicados.
O diff de cobertura nos apontou exatamente para a mesma condição de corrida TOCTOU discutida em mais detalhe no artigo anterior. Mas o que há de novo em nossa abordagem atual é que ela não depende exclusivamente da expertise humana e é facilmente acessível para a IA.
Transformando isso em uma skill
Eu diria que modificações em ferramentas open-source assistidas por IA para ajudar você a resolver a tarefa em questão, tudo em minutos, já são incríveis por si só. Mas vamos manter os olhos no quadro maior.
Eis o que fizemos até agora: começamos com uma intuição: testes instáveis seguem caminhos de código diferentes, e a análise de cobertura pode revelar onde eles divergem. Em seguida, transformamos essa intuição em um procedimento concreto e repetível. Isso justifica um artigo de base de conhecimento, ou talvez uma skill de agente de IA? Sim!
Na mesma sessão do agente, vamos pedir ao agente para:
- Garantir que todos os scripts sejam autocontidos e executáveis.
- Documentar o procedimento inteiro em um arquivo
SKILL.md, passo a passo, para que outro agente possa segui-lo sem qualquer contexto prévio.
O agente empacota tudo e escreve um guia que descreve quando aplicar a skill, quais ferramentas são necessárias e quais passos seguir.
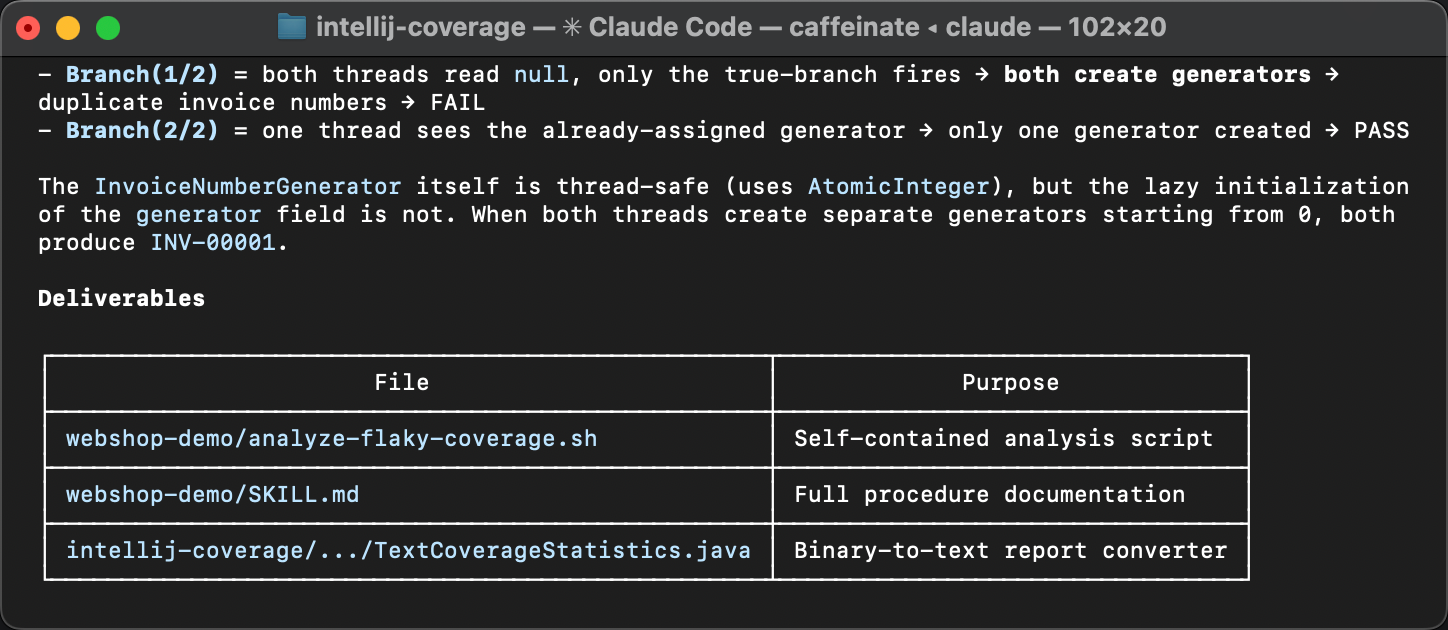
O único ajuste durante a revisão foi alinhar a skill com a especificação. A skill original não tinha o meta no frontmatter. Os agentes são bons em corrigir skills que omitem detalhes menores, mas o meta é importante para a descobribilidade. Sem ele, uma skill pode nem ser escolhida por um agente em primeiro lugar.
Testando a skill
Para verificar se a skill realmente funciona, vamos iniciar uma nova sessão de agente.
Sem aquecimento, sem dicas. Em vez disso, vamos deliberadamente formular o pedido de uma forma bem genérica,
algo como Find and fix the cause of flakiness in InvoiceServiceTest.
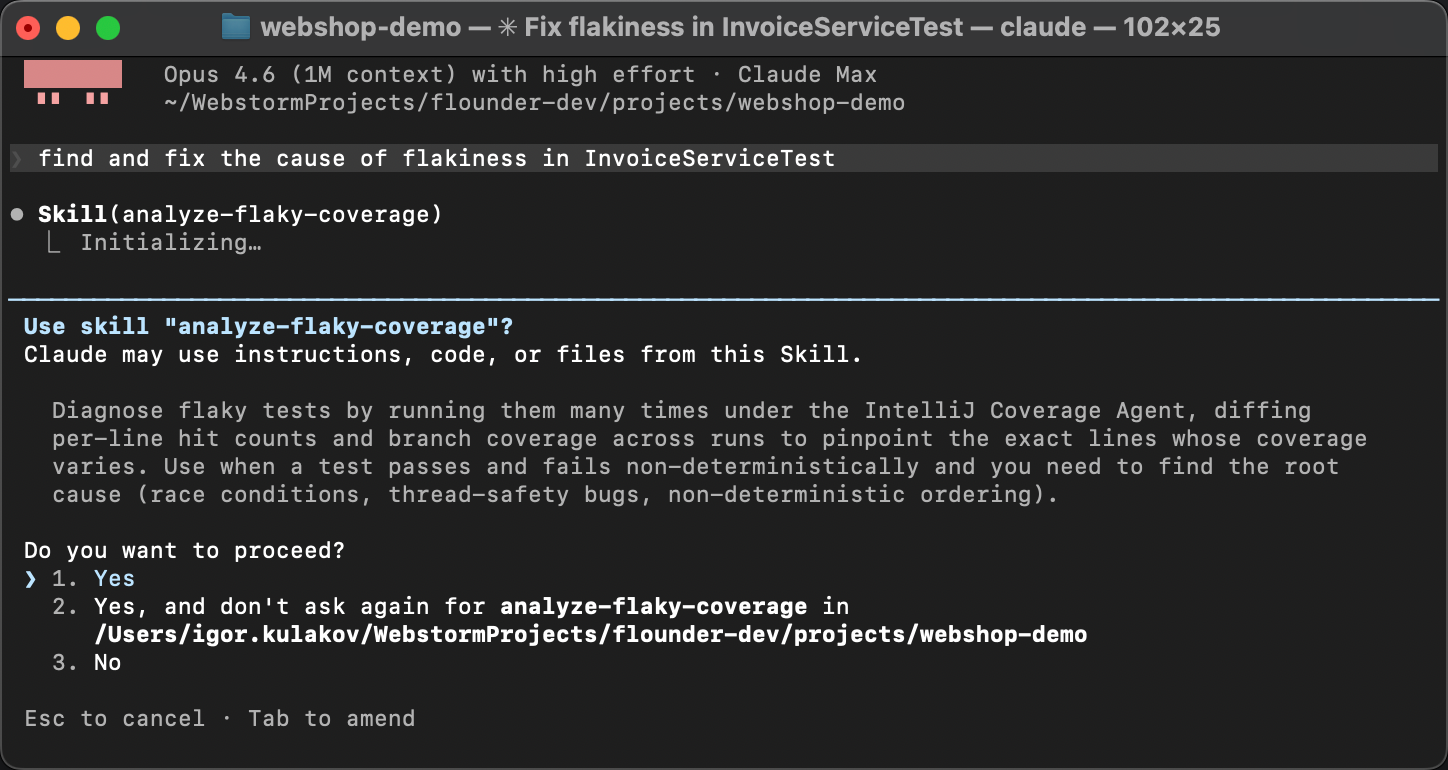
O agente combina a descrição da skill em SKILL.md com a descrição do problema,
descobre as instruções e as executa: ele roda o script de cobertura, lê o diff
e identifica a condição de corrida.
Em vez de adivinhar, ele segue os passos estabelecidos
e chega à mesma conclusão todas as vezes. Tão determinístico quanto a IA generativa pode ser!
Resumo
As mudanças que fizemos no agente de cobertura já foram publicadas com a nova versão 1.0.774. E a skill está disponível aqui.
Neste artigo, começamos com uma intuição sobre testes instáveis, construímos uma ferramenta personalizada em torno de um agente de cobertura open-source, usamos essa ferramenta para encontrar uma condição de corrida e empacotamos o procedimiento inteiro em uma skill de IA reutilizável. Você pode usar essa skill para encontrar testes instáveis em seus próprios projetos, mas espero que esta publicação transmita a ideia maior.
As skills de IA permitem que você ensine os agentes a resolver virtualmente qualquer coisa, desde que você consiga empilhar interfaces de texto. Muitos problemas de programação difíceis podem ser quebrados em outros mais simples e resolvidos usando ferramentas familiares. E com a IA orquestrando tudo isso, podemos até tornar o processo prazeroso. Como acontecia muito antes da IA, a curiosidade é o único pré-requisito real.
Boas depurações!