Junie编码(AsciiDoc支持)
阅读其他语言: English Español Français Deutsch 日本語 한국어 Português
上周,我在 Foojay播客节目 上,由 Frank Delporte 主持的节目中,谈到了重复查找器。 我们简单谈及了对其他格式的支持,Frank 询问我是否计划添加AsciiDoc,因为这对他在Azul的技术写作有所帮助。
我们同意考虑尽快添加该支持。 同时我获得了对Junie的使用权限, 这是JetBrains新推出的一款编码代理,目前处于早期访问阶段。 过了一会儿,我意识到这是一个很好的机会来尝试使用它。 众所周知,编码代理可以很好地解决典型任务。 但是对于一个不基于知名框架并且在非常常见领域之外的项目呢? 作为一个编码代理持有人,我的期望是混合的。

以下是我的使用过程。
安装和概述
Junie是一个IntelliJ IDEA插件。 用户界面采用了类似于JetBrains AI助手 或GitHub Copilot的熟悉的垂直工具窗口。下面是它的样子:
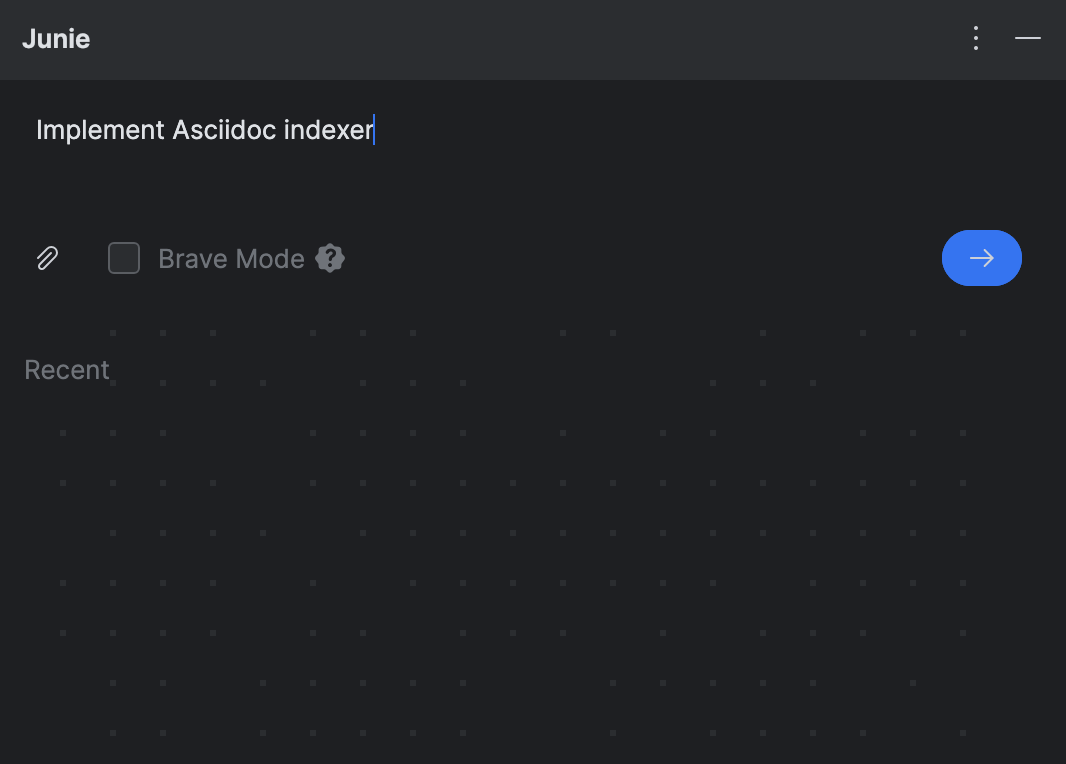
极简的设计只有一个提示字段,一个添加上下文的按钮, 和一个名为Brave Mode的复选框。这个选项控制了 Junie是否可以在不先与您确认的情况下执行命令。 我还没有那么大胆,所以下次我会尝试它。
设置需求
在分配编码任务给Junie之前,我下载了
一个来自AsciiDoctor指南的主题
并把它放在src/test/resources/下让Junie作为测试数据和参考。
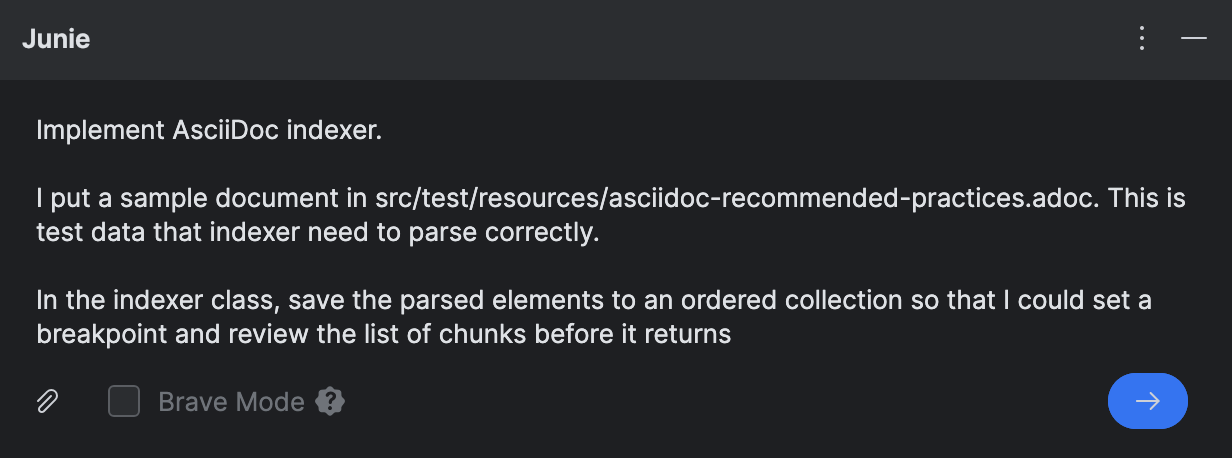
出于调试的目的,我要求Junie将解析的块添加到一个单独的集合。这是因为 实际的索引结构分成了多个层次,这使得它难以调试。 为了简单起见,我更愿意将解析的元素作为平面结构来查看,如果我需要在运行时检查结果的话。
‘编码’
输入提示之后,Junie将任务分解成更小的项目并开始实现它们。 为了添加AsciiDoc的支持,它制定了如下计划:
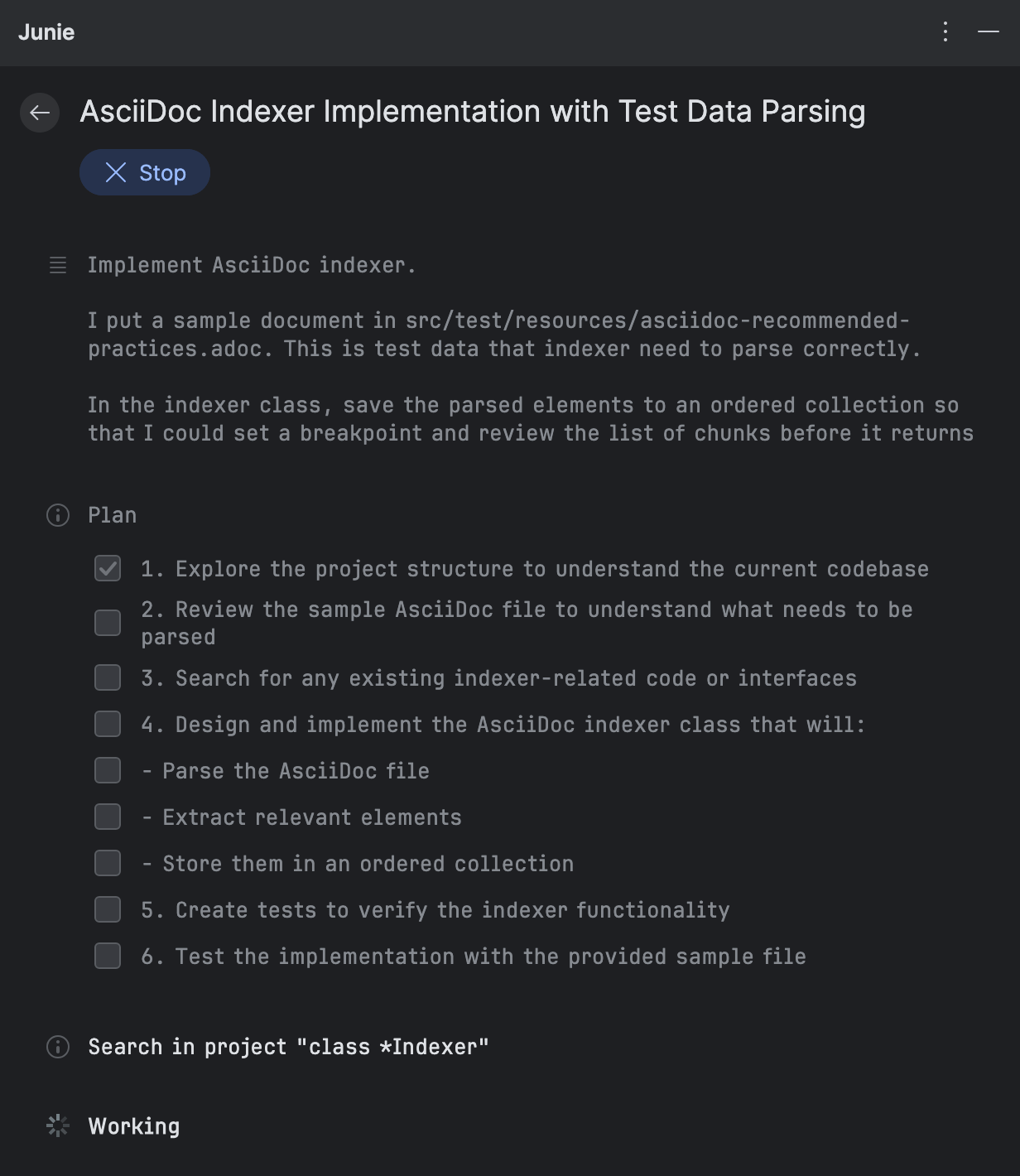
当Junie执行每个项目时,它都会给你提供变更的总结。你可以立即查看这些变更, 无需等待整个工作流程完成:

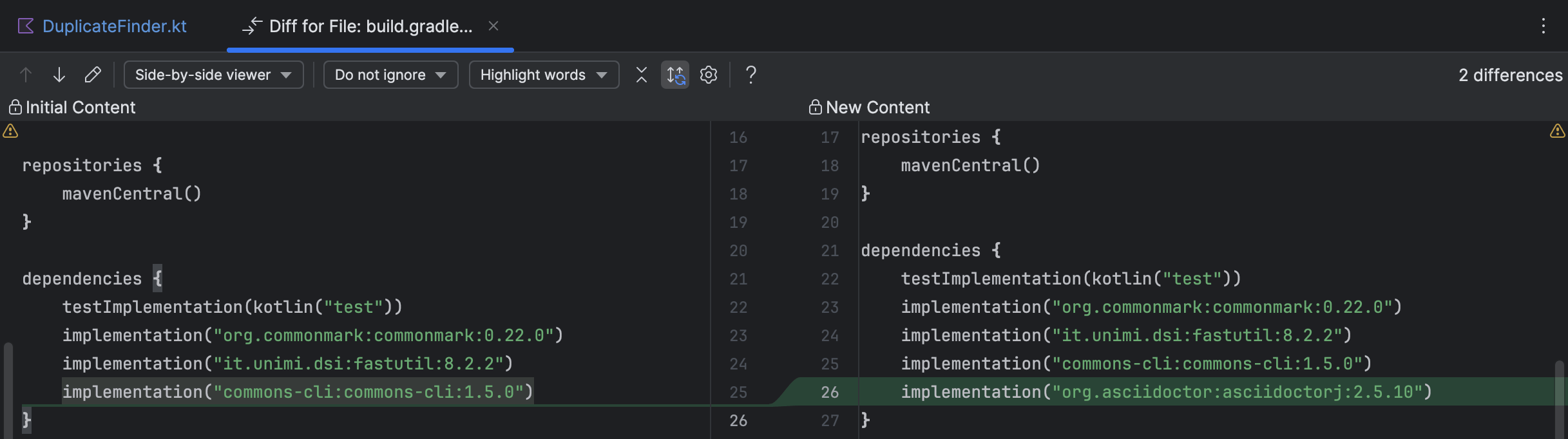
通过点击文件名,你可以在IntelliJ IDEA的差异视图中跟踪变更,就像 查看Git变更或者本地历史记录 (Local History)一样。
完成所有项目后,Junie会编写测试然后提示你运行它们:
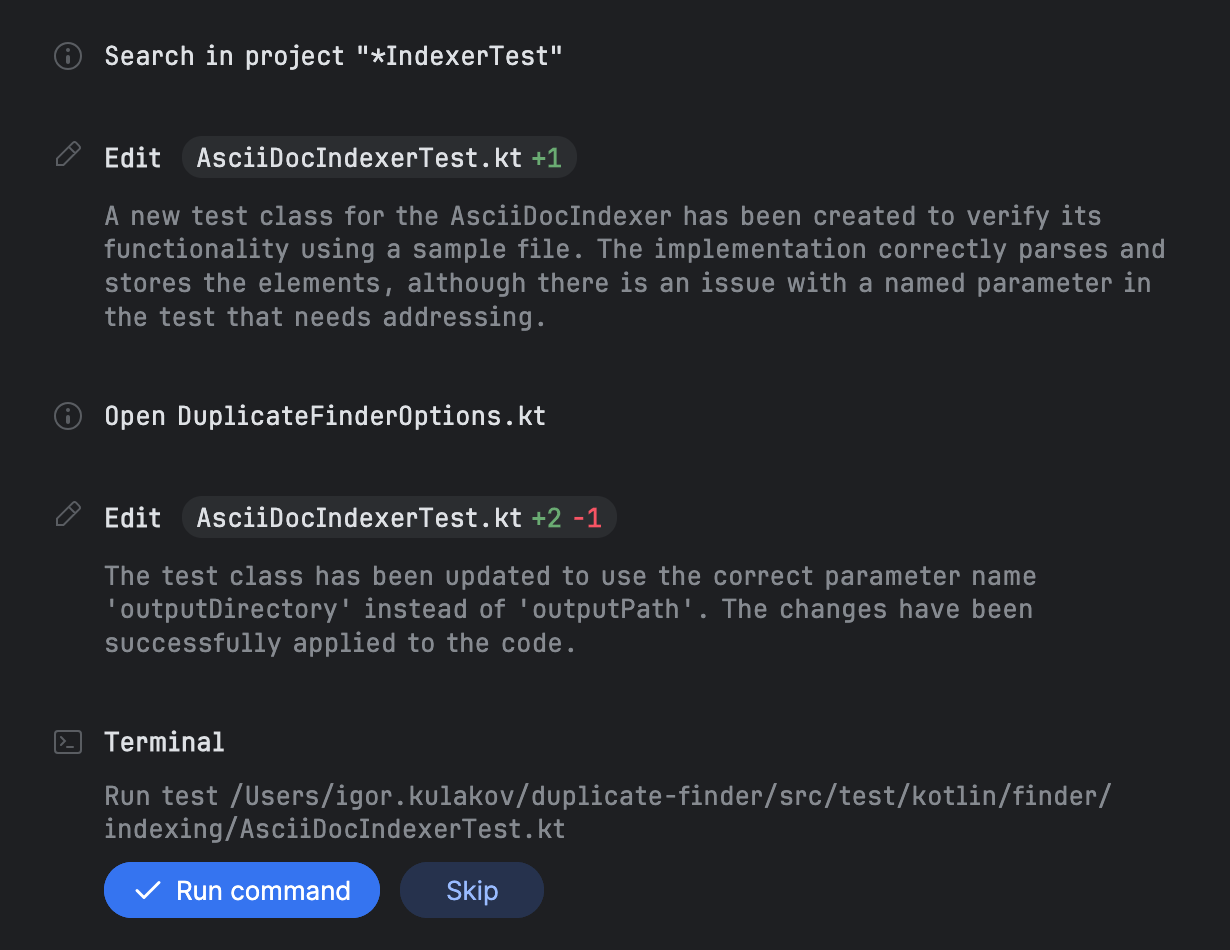
在这个任务中,我给Junie提供了测试数据并明确要求进行测试。然而,似乎Junie默认生成它们 和测试数据。我试着执行没有提到测试的任务,但是Junie还是创建了它们。 为了运行测试,Junie使用 IntelliJ IDEA的运行 (Run)工具窗口。
运行测试后,如果本次测试成功的话,Junie会提供完成任务的总结:

代码质量
在审阅代码和测试时,我发现它们结构良好并且整洁。 我真的很喜欢的一点是,Junie不仅改变了为了让项目编译的所需的代码, 还额外采取了一步来引入任务上下文所需的其他有意义的变更。
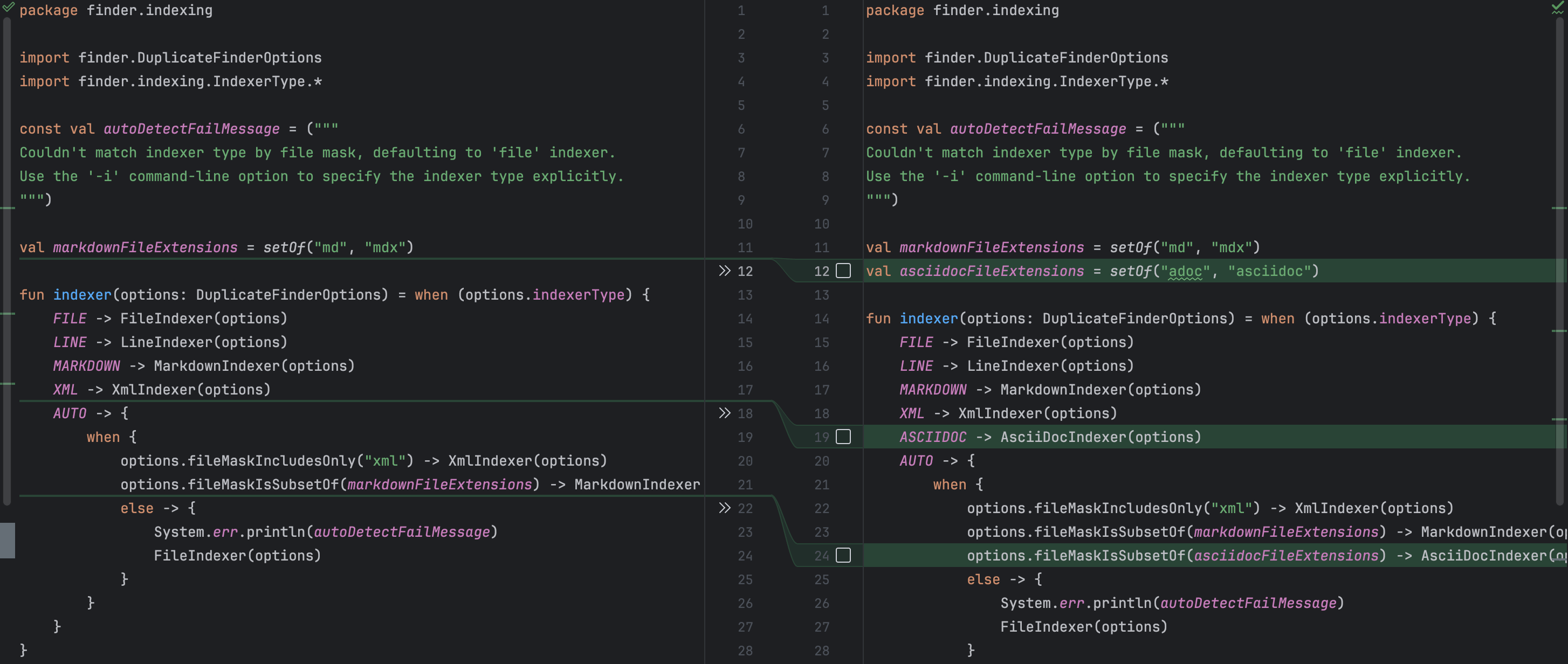
例如,我忘记了提到新的索引器必须在命令行参数中暴露出来。 这个疏忽不会导致编译错误,然而如果最终用户 无法访问该功能就没有意义了。 Junie意识到了这一点,并添加了对应 的命令行选项和描述。它还正确地更新了工厂方法, 以便客户代码可以获取新索引器的实例。 同时,没有任何不必要的变更,这也是个好消息!
到目前为止一切都很好,但似乎还需要做更多的工作。
校正实现
编码代理在完全自主地识别运行时可能的问题方面尚未完全达标。 从技术上讲,实现是正确的,且通过了所有测试。 解析结果是一致的,如在评估对话框所见。
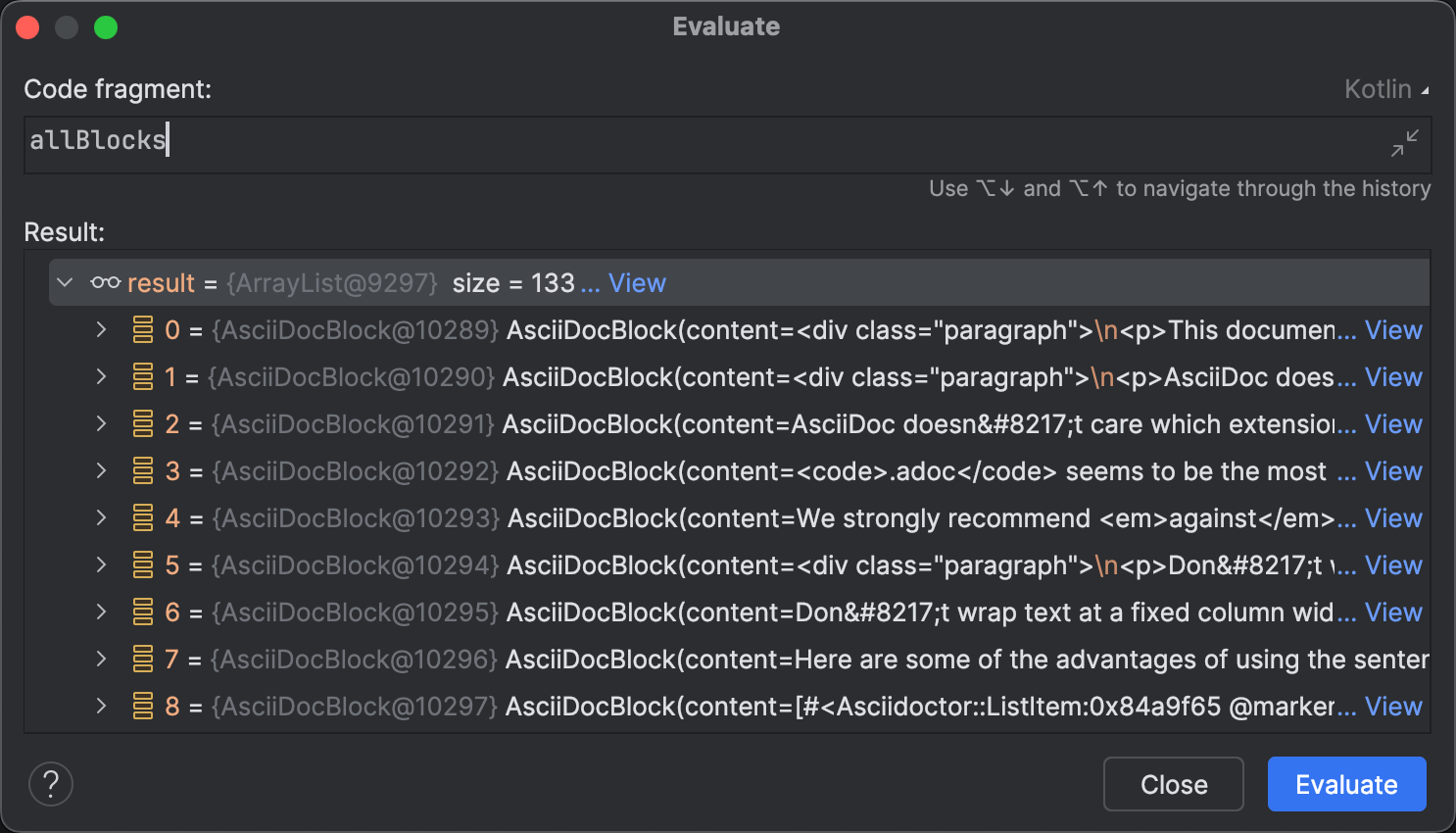

对表达式求值 (Evaluate Expression) 除了探索集合之外,它还有许多有趣的用途。例如,您可以使用它来在不重新启动程序的情况下构建和应用修补程序 或者 任意修改其状态
一切看起来都很好,只是处理单个文件花费了令人惊讶的长时间。看看这个问题,我还发现解析一批大约35个文件总是失败
并带有一个 OutOfMemoryError 。
在分析实现时,我没有找到任何明显的问题,如效率低下的循环或泄漏的资源。
使用 -XX:+HeapDumpOnOutOfMemoryError 运行应用程序可以给我一个堆转储,其中显示出大量的JRuby类型具有巨大的保留尺寸。
这暗示了这个库可能是问题的来源。
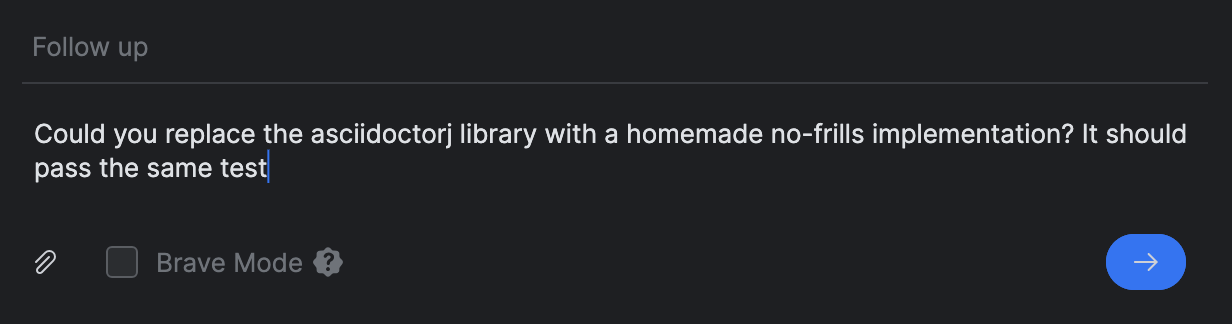
当然,这个猜测可能不准确,为我们提供了一个引人入胜 的剖析 (或阅读文档)的机会。 无论如何,将JRuby依赖项改为简单的Kotlin实现很可能会加快速度。 所以,我决定要求Junie使用自定义解析器来重写实现。
我没有开始新的任务,而是使用了 Follow up提示来完成这个任务:
结果
Junie按照请求修改了实现。虽然我对AsciiDoc格式不是很熟悉,但是一眼看去,解析大部分是正确的。对于序言的解析还有一些改进的空间,可能还有其他方面,但它已经能够完成工作了。
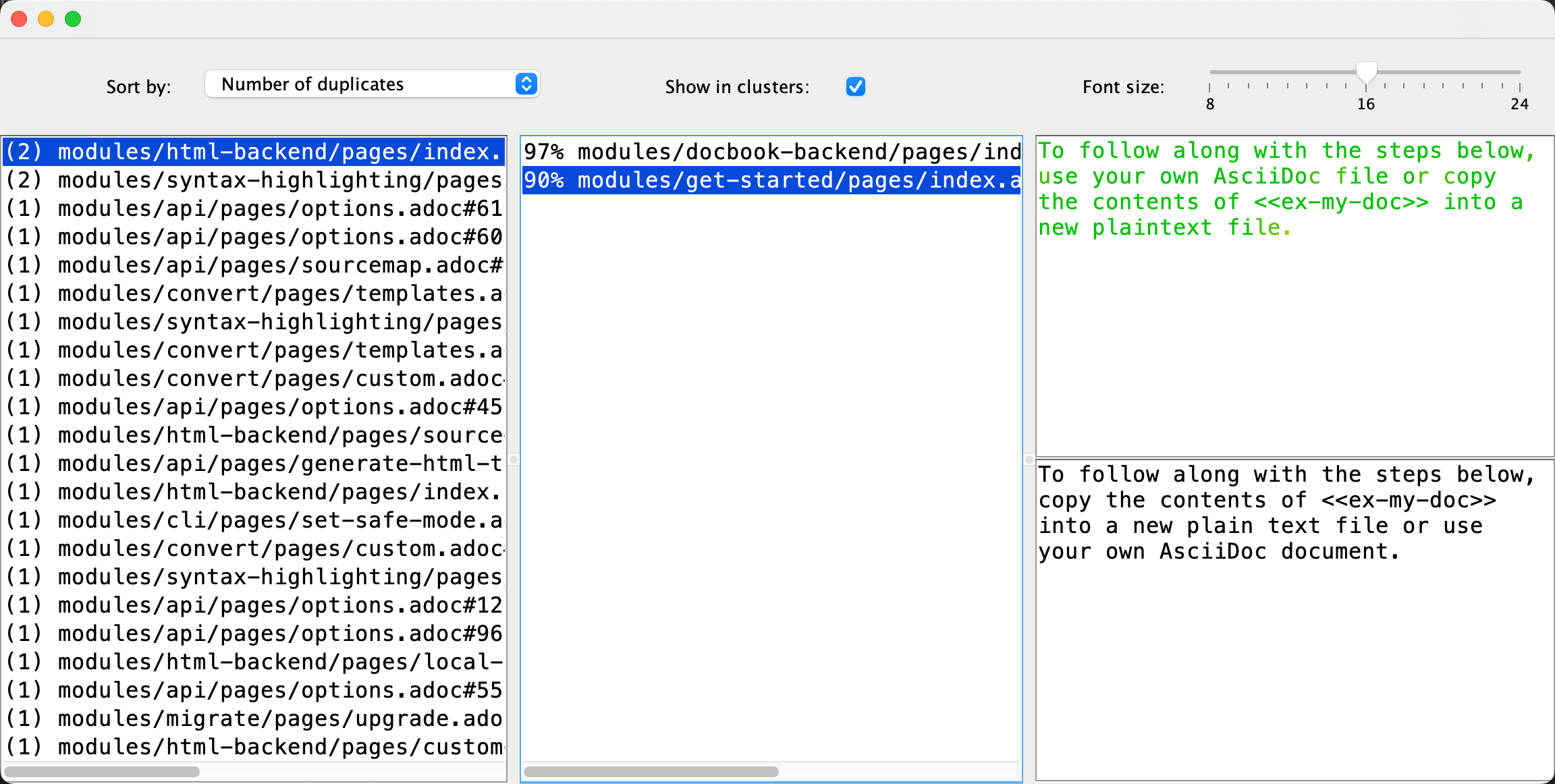
在AsciiDoctor自己的帮助文档上运行更新后的重复查找器检测到了一些重复项! 在我的笔记本电脑上,分析只花费了350毫秒:
带有提交更改的项目在我GitHub上。 要试用新版本的应用程序,您可以在重复查找器页面找到说明和下载链接。 总的来说,这个实现可能并