Duplikatfinder
Andere Sprachen: English Español Français 日本語 한국어 Português Русский 中文
Der Duplikatfinder ist eine Open-Source-Anwendung zur Erkennung ähnlicher Texte in einer oder mehreren Dateien. Er kann verwendet werden, um 100%ige Duplikate sowie ähnliche, aber nicht identische Inhalte zu finden. Das Tool ist mit mehreren Formaten kompatibel, darunter Klartext, Markdown und XML.
Das Duplikatfinder-Tool kann Ihnen helfen bei:
- Plagiatserkennung
- Content-Management
- SEO-Optimierung
- Datendeduplizierung
Beispiel für doppelten Inhalt
Hier ist ein kurzes Beispiel, um Ihnen eine Vorstellung davon zu geben, was das Tool erkennt:
Anleitung
- Laden Sie die App herunter. Alternativ können Sie es selbst aus den Quellen erstellen.
- Stellen Sie sicher, dass Java 16 oder höher auf Ihrem Computer installiert ist
- Öffnen Sie im Terminal den Ordner mit der heruntergeladenen .jar-Datei
-
Führen Sie
java -jar duplicate-finder.jarmit den folgenden Parametern aus:Parameter Bedeutung Beispiel -r/--rooterforderlichRelativer oder absoluter Pfad zum Ordner, in dem Sie nach doppeltem Inhalt suchen möchten -r=./my-project/-o/--outputRelativer oder absoluter Pfad zum Ordner, in dem Sie die Analyseergebnisse speichern möchten. Wenn kein Verzeichnis angegeben ist, verwendet der Duplikatfinder das aktuelle Arbeitsverzeichnis. -o=./my-project/duplicates/-f/--fileMaskKommagetrennte Liste von Dateierweiterungen zur Analyse. Standardmäßig werden alle Dateien analysiert. -f=md,mdx-p/--parserWas als Textabschnitt betrachtet werden soll. Die folgenden Optionen sind verfügbar:
- md – ein Markdown-Element
- line – eine einzelne Textzeile
- xml – ein XML-Element
- adoc – AsciiDoc-Element
- file – der gesamte Dateiinhalt
- auto – Versuch, aus der Dateimaske abzuleiten
-i=md-l/--minLengthDie Mindestlänge (in Zeichen) für einen zu analysierenden Textabschnitt. Standard: 100 (Textfragmente kürzer als 100 Zeichen werden ignoriert) -l=150-s/--minSimilarityDer Mindestgrad der Ähnlichkeit zwischen zwei Textabschnitten, um als Duplikate betrachtet zu werden. Standard: 0.9 (90%) -s=0.85-d/--minDuplicatesDie Mindestanzahl von Duplikaten, damit eine Duplikatgruppe gemeldet wird. Standard: 1 (ein Duplikat reicht aus) -d=5-ui/--uiOb die interaktive Benutzeroberfläche verwendet werden soll oder nicht. Optionen: - none – keine Oberfläche, nur in Dateien schreiben
- swing – alte Oberfläche
- compose – neue Oberfläche, Standard
-ui=none-v/--verboseOb Fortschritt und Fehler in der Konsole protokolliert werden sollen. Verwenden Sie diese Option, wenn die Analyse zu lange dauert und Sie ein Problem vermuten. Standard: keine Protokollierung -v-m/--memoryLow-Memory-Modus - minimiert den Speicherbedarf des Duplikatfinders auf Kosten der Analysegeschwindigkeit. -m-g/--gram(fortgeschritten) N-Gramm-Länge – beeinflusst Geschwindigkeit, Speicherbedarf und Genauigkeit der Analyse. Der Unterschied hängt von den Besonderheiten des Inhalts ab. -g=10-w/--keepWhitespaceMehrfache aufeinanderfolgende Leerzeichen im geparsten Inhalt beibehalten. Standardmäßig werden Leerzeichen normalisiert, d.h. mehrere aufeinanderfolgende Leerzeichen werden als eines behandelt und angezeigt. -w-i/--inlineDen Inhalt verschachtelter Elemente in ihr umschließendes Element einbeziehen. Zum Beispiel:
<parent>Some content including <child>nested content</child></parent>Mit dieser Option wird das äußere Element als 'Some content including nested content' geparst, während es standardmäßig als 'Some content including' geparst wird.
-i
Befehlsbeispiel
Hier ist ein Beispiel, wie Ihr Befehl aussehen könnte:
java -jar duplicate-finder.jar -r=/Users/me.user/my-site -i=md -f=md,mdx -s=0.85 -d=5 -l=200
Der obige Befehl führt Folgendes aus:
-
-r=/Users/me.user/my-site– nach ähnlichem Inhalt in '/Users/me.user/my-site' und seinen Unterverzeichnissen suchen -
-i=md– davon ausgehen, dass der Inhalt in Markdown geschrieben ist und ihn nach Markdown-Regeln analysieren -
-f=md,mdx– nur Dateien mit den Erweiterungen '.md' und '.mdx' berücksichtigen -
-s=0.85– nur Übereinstimmungen mit einer Ähnlichkeit von 85% oder höher melden -
-d=5– nur Texte melden, die 5-mal oder öfter dupliziert wurden -
-l=200– nur Texte mit 200 Zeichen oder mehr melden
Ergebnisse
Je nach Einstellungen und Projektgröße müssen Sie möglicherweise etwas warten, bis die Analyse abgeschlossen ist. Danach werden die Ergebnisse im Duplikat-Viewer geöffnet und im mit der Option '-o' definierten Ordner gespeichert. Wenn keine Option angegeben ist, wird die Ausgabe in das Arbeitsverzeichnis geschrieben.
Hier sehen Sie, was im Duplikat-Viewer angezeigt wird:
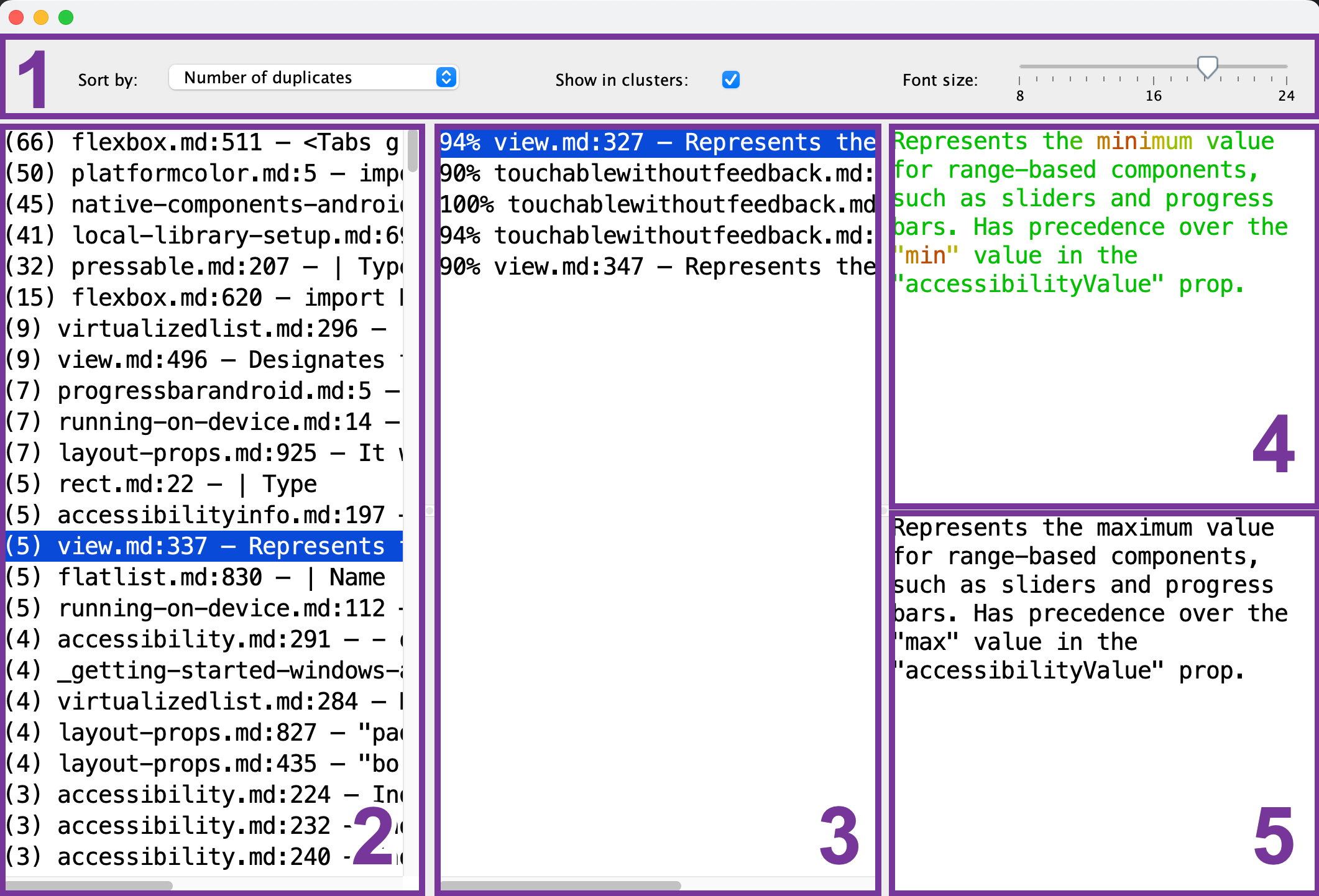
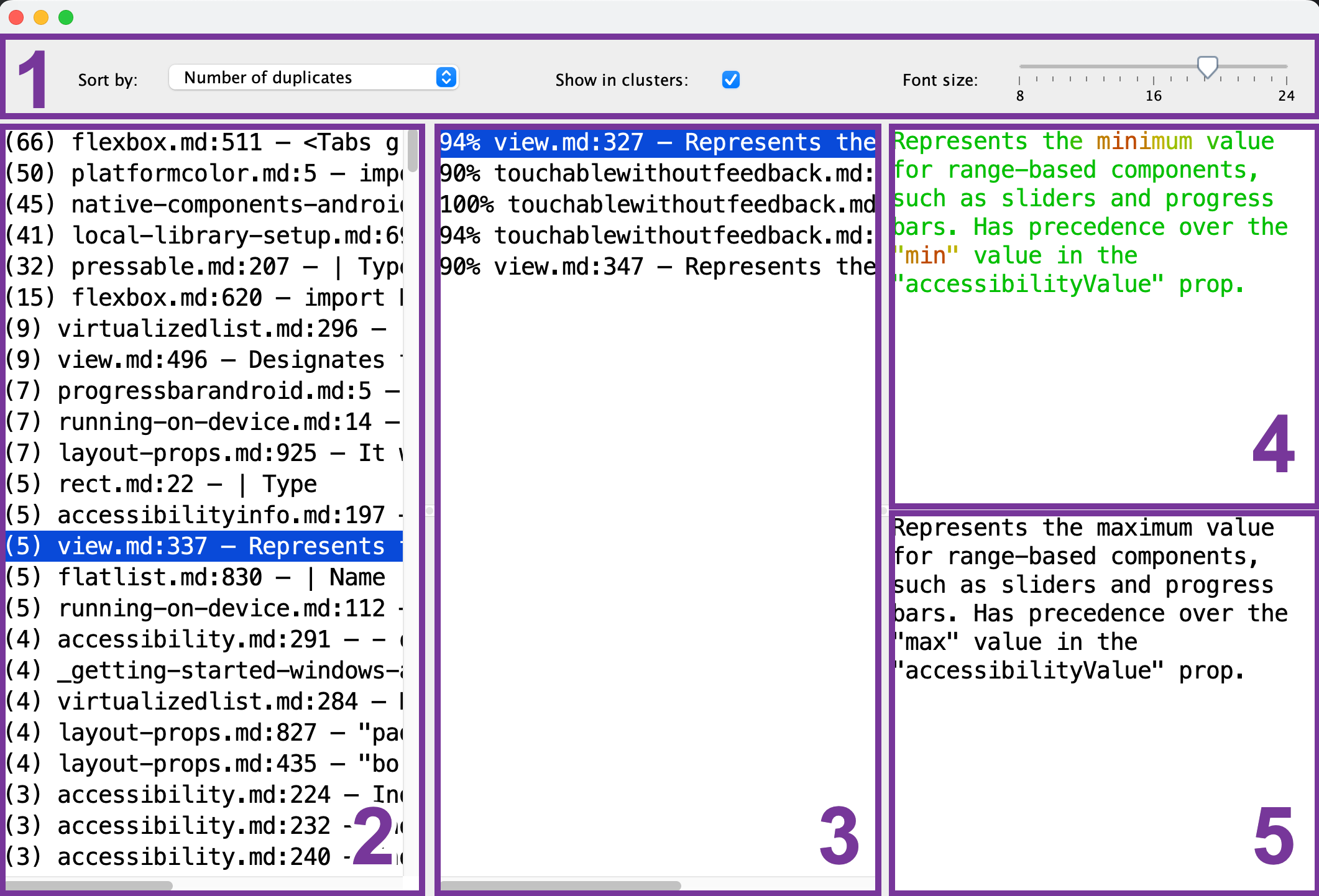
- Symbolleiste: Konfigurieren Sie die Schriftgröße, Sortierreihenfolge und ob Sie nur einen einzelnen Referenz-Chunk (2) für jede Duplikatgruppe sehen möchten.
- Referenz-Chunk-Liste: Wählen Sie den Chunk aus, der als Referenz für den Vergleich dient.
- Duplikat-Chunk-Liste: Nachdem Sie den Referenz-Chunk (2) ausgewählt haben, zeigt diese Liste die ähnlichen Chunks an. Um ein Duplikat anzuzeigen, wählen Sie es aus der Liste.
- Referenz-Chunk-Vorschau: Nachdem Sie den Referenz-Chunk (2) ausgewählt haben, können Sie seinen Inhalt hier anzeigen. Gemeinsame Teile werden grün angezeigt, während unterschiedliche Teile rot angezeigt werden. Je mehr Duplikat-Chunks (3) einen gemeinsamen Teil haben, desto grüner wird er erscheinen.
- Duplikat-Chunk-Vorschau: Nachdem Sie den Duplikat-Chunk (3) ausgewählt haben, erscheint hier seine Vorschau. Sie können sie für einen schnellen Vergleich mit dem ausgewählten Referenz-Chunk (4) verwenden.
Mehr erfahren & Kontakt
Wenn Sie sich für die Entwicklung dieses Tools interessieren, schauen Sie sich die zugehörige Blog-Serie an:
- Duplikatfinder für Text
- Duplikatfinder für Text: Anforderungen
- Junie programmiert (AsciiDoc-Unterstuetzung)
- Duplikatfinder für Text: Algorithmus
Für Feedback können Sie mich über die Kontaktdaten in der Fußzeile dieser Seite erreichen. Ich freue mich über Ihre Anregungen und Feature-Wünsche.
Lizenz
Der Code ist unter der MIT-Lizenz lizenziert, was bedeutet, dass Sie ihn für jeden Zweck frei verwenden, forken und modifizieren können.