Détecteur de Doublons
Autres langues : English Español Deutsch 日本語 한국어 Português Русский 中文
Le détecteur de doublons est une application open-source pour détecter du texte similaire dans un ou plusieurs fichiers. Il peut être utilisé pour trouver des doublons à 100% ainsi que du contenu similaire mais pas identique. L'outil est compatible avec plusieurs formats, notamment le texte brut, Markdown et XML.
L'outil de détection de doublons peut vous aider avec :
- Détection de plagiat
- Gestion de contenu
- Optimisation SEO
- Déduplication de données
Exemple de contenu en double
Voici un exemple rapide pour vous donner une idée de ce que l'outil détecte :
Comment utiliser
- Téléchargez l'application. Alternativement, vous pouvez le compiler vous-même à partir de les sources.
- Assurez-vous que Java 16 ou une version ultérieure est installée sur votre ordinateur
- Dans le terminal, ouvrez le dossier contenant le fichier .jar que vous avez téléchargé
-
Exécutez
java -jar duplicate-finder.jaravec les paramètres suivants :Paramètre Signification Exemple -r/--rootrequisChemin relatif ou absolu vers le dossier où vous souhaitez rechercher du contenu en double -r=./my-project/-o/--outputChemin relatif ou absolu vers le dossier où vous souhaitez enregistrer les résultats de l'analyse. Si aucun répertoire n'est spécifié, le détecteur de doublons utilisera le répertoire de travail actuel. -o=./my-project/duplicates/-f/--fileMaskListe d'extensions de fichiers séparées par des virgules à analyser. Par défaut, tous les fichiers sont analysés. -f=md,mdx-p/--parserCe qui doit être considéré comme un fragment de texte. Les options suivantes sont disponibles :
- md – un élément markdown
- line – une seule ligne de texte
- xml – un élément XML
- adoc – élément AsciiDoc
- file – le contenu du fichier entier
- auto – tenter de déduire du masque de fichier
-i=md-l/--minLengthLa longueur minimale (en caractères) pour qu'un fragment de texte soit analysé. Par défaut : 100 (les fragments de texte de moins de 100 caractères sont ignorés) -l=150-s/--minSimilarityLe degré minimum de similarité entre deux fragments de texte pour être considérés comme des doublons. Par défaut : 0.9 (90%) -s=0.85-d/--minDuplicatesLe nombre minimum de doublons pour qu'un groupe de doublons soit signalé. Par défaut : 1 (un doublon suffit) -d=5-ui/--uiUtiliser ou non l'interface interactive. Options : - none – pas d'interface, écriture dans les fichiers uniquement
- swing – ancienne interface
- compose – nouvelle interface, par défaut
-ui=none-v/--verboseAfficher la progression et les erreurs dans la console. Utilisez cette option si l'analyse prend trop de temps et que vous soupçonnez un problème. Par défaut : pas de journalisation -v-m/--memoryMode basse mémoire - minimise l'empreinte mémoire du détecteur de doublons au détriment de la vitesse d'analyse. -m-g/--gram(avancé) longueur du n-gramme – affecte la vitesse, l'empreinte mémoire et la précision de l'analyse. La différence dépend des spécificités du contenu. -g=10-w/--keepWhitespaceConserver les occurrences de plusieurs espaces consécutifs dans le contenu analysé. Par défaut, les espaces sont normalisés, ce qui signifie que plusieurs caractères d'espacement consécutifs sont traités et affichés comme un seul. -w-i/--inlineInclure le contenu des éléments imbriqués dans leur élément englobant. Par exemple :
<parent>Some content including <child>nested content</child></parent>Avec cette option, l'élément externe sera analysé comme 'Some content including nested content', alors que par défaut il est analysé comme 'Some content including'.
-i
Exemple de commande
Voici un exemple de ce à quoi votre commande pourrait ressembler :
java -jar duplicate-finder.jar -r=/Users/me.user/my-site -i=md -f=md,mdx -s=0.85 -d=5 -l=200
La commande ci-dessus effectuera les actions suivantes :
-
-r=/Users/me.user/my-site– rechercher du contenu similaire dans '/Users/me.user/my-site' et ses sous-répertoires -
-i=md– supposer que le contenu est écrit en Markdown et l'analyser selon les règles Markdown -
-f=md,mdx– ne considérer que les fichiers avec les extensions '.md' et '.mdx' -
-s=0.85– signaler uniquement les correspondances avec une similarité de 85% ou plus -
-d=5– signaler uniquement les textes dupliqués 5 fois ou plus -
-l=200– signaler uniquement les textes de 200 caractères ou plus
Résultats
Selon les paramètres et la taille du projet, vous devrez peut-être attendre un peu que l'analyse se termine. Ensuite, les résultats s'ouvriront dans le visualiseur de doublons et seront enregistrés dans le dossier défini par l'option '-o'. Si aucune option n'est spécifiée, la sortie est écrite dans le répertoire de travail.
Voici ce que vous verrez dans le visualiseur de doublons :
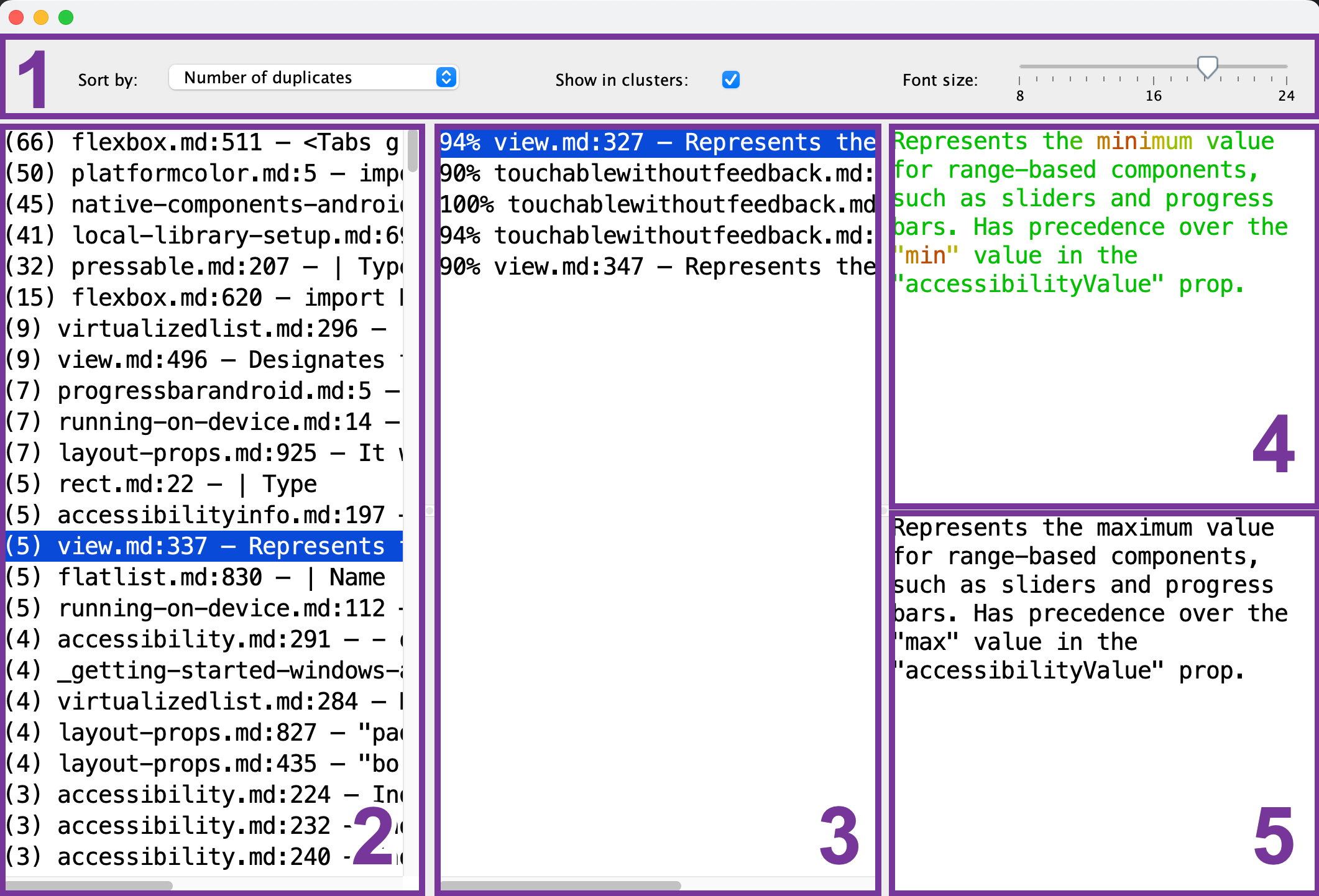
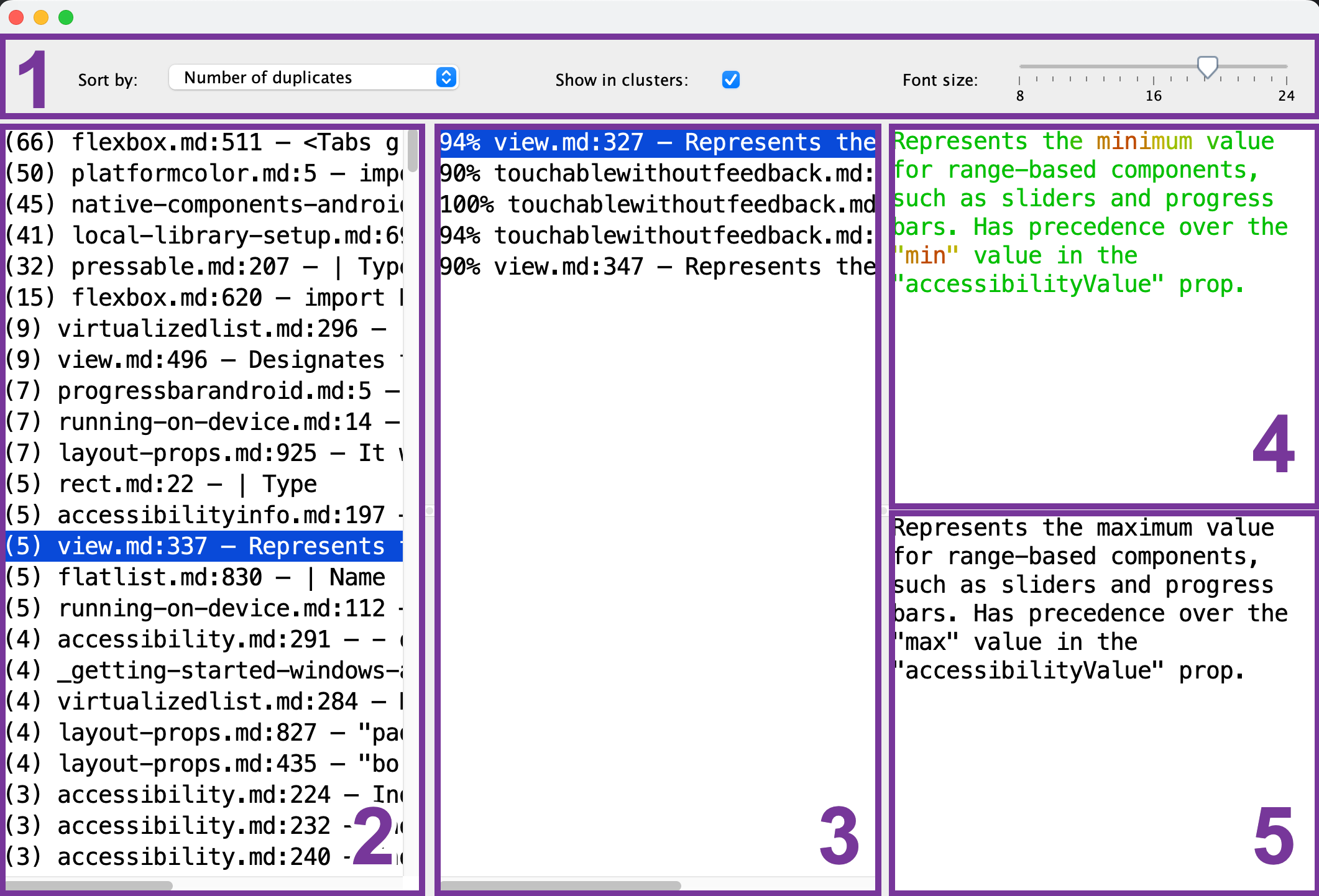
- Barre d'outils : configurez la taille de police, l'ordre de tri et si vous souhaitez voir un seul fragment de référence (2) pour chaque groupe de doublons.
- Liste des fragments de référence : sélectionnez le fragment qui sert de référence pour la comparaison.
- Liste des fragments en double : après avoir sélectionné le fragment de référence (2), cette liste affichera les fragments similaires. Pour prévisualiser un doublon, sélectionnez-le dans la liste.
- Aperçu du fragment de référence : après avoir sélectionné le fragment de référence (2), vous pouvez prévisualiser son contenu ici. Les parties communes sont affichées en vert, tandis que les parties différentes sont affichées en rouge. Plus les fragments en double (3) ont des parties communes, plus ils apparaîtront en vert.
- Aperçu du fragment en double : après avoir sélectionné le fragment en double (3), son aperçu apparaîtra ici. Vous pouvez l'utiliser pour une comparaison rapide avec le fragment de référence sélectionné (4).
En savoir plus et contact
Si vous êtes intéressé par le développement de cet outil, consultez la série d'articles de blog associée :
- Detecteur de Doublons pour Texte
- Detecteur de Doublons pour Texte : Exigences
- Junie Code (Support AsciiDoc)
- Detecteur de Doublons pour Texte : Algorithme
Pour vos commentaires, vous pouvez me contacter en utilisant les coordonnées en bas de cette page. Je serai heureux d'entendre vos avis et demandes de fonctionnalités.
Licence
Le code est sous licence MIT, ce qui signifie que vous êtes libre de l'utiliser à n'importe quelle fin, ainsi que de le forker et de le modifier.