Junie Codes (AsciiDoc Support)
Other languages: EspañolFrançaisDeutsch日本語한국어Português中文
Last week, I talked about Duplicate Finder on Foojay Podcast hosted by Frank Delporte. We briefly touched upon implementing support for other formats, and Frank asked if I’m planning on adding AsciiDoc, as it could be useful for his technical writing at Azul.
We agreed to think about adding the support soon. At the same time I got access to Junie, a newly announced coding agent by JetBrains, which is currently in early access. After a while, a thought came to me that this is a great opportunity to try it in action. Coding agents are known to solve typical tasks well. But what about a project that is not based on a well-known framework and is outside a very common domain? As somewhat of a coding-agent skeptic, my expectations were mixed.
Here is how it went.
Installation and overview
Junie is an IntelliJ IDEA plugin. The UI adopts a familiar vertical tool window, similar to that of JetBrains AI Assistant or GitHub Copilot. Here’s what it looks like:
The minimalistic design only features a prompt field, a button for adding context, and a checkbox titled Brave Mode. This option controls whether Junie can run commands without double-checking with you. I’m not that brave yet, so I’ll try that next time.
Setting requirements
Before giving Junie the coding task, I downloaded
a topic from AsciiDoctor guide
and placed it under src/test/resources/ for Junie to use as test data and a reference.
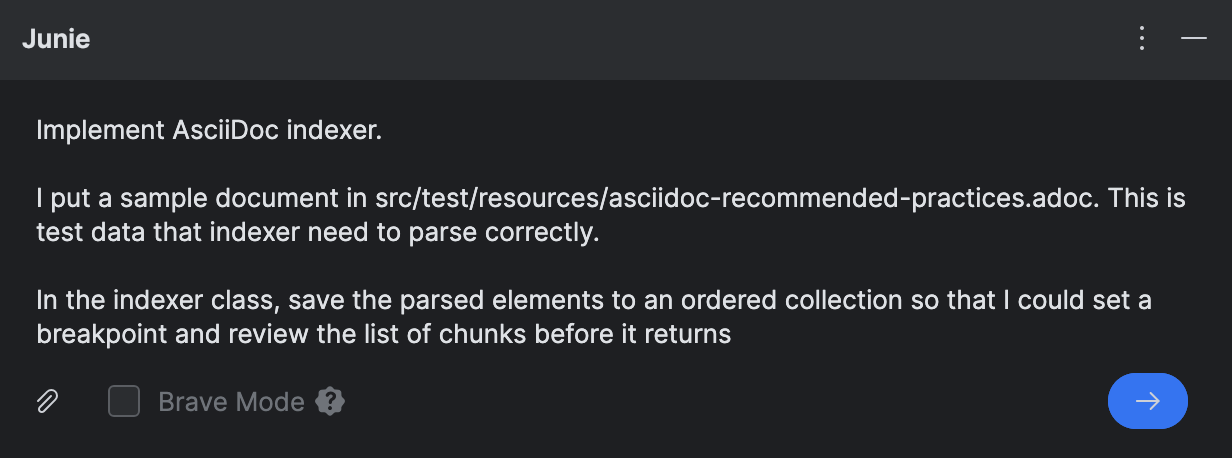
For debugging purposes, I asked Junie to add the parsed blocks to a separate collection. This is because the actual index is structured in multiple levels, which makes it inconvenient to debug. For simplicity, I’d rather view the parsed elements as a flat structure if I need to check the results at runtime.
‘Coding’
After you enter the prompt, Junie breaks the task down into smaller items and starts to implement them. For adding the AsciiDoc support, it came up with the following plan:
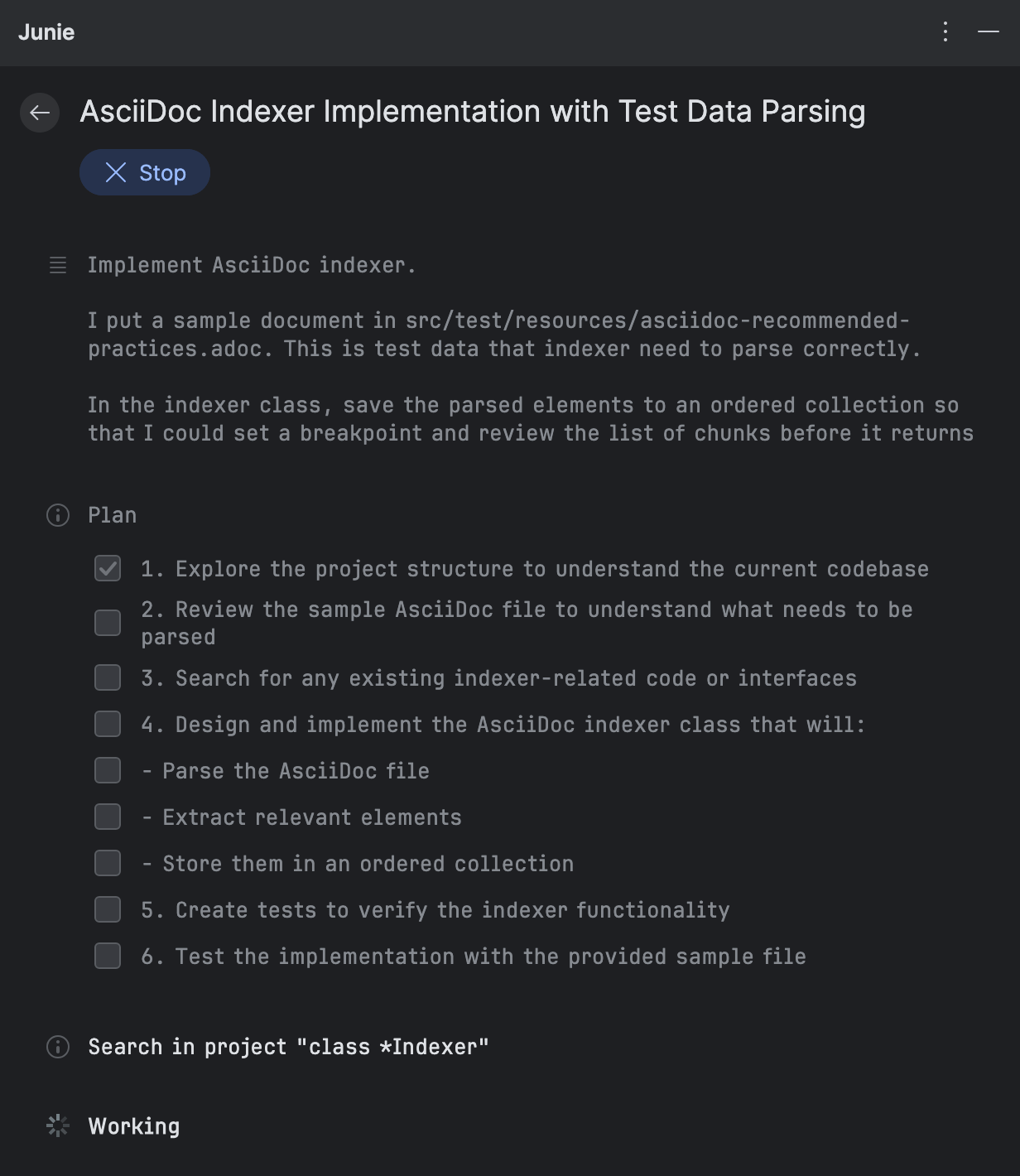
As Junie executes each item, it gives you the summary of the changes. You can review them right away, without having to wait for the entire workflow to complete:

By clicking the filenames, you can track the changes in the IntelliJ IDEA’s diff view in a similar way to viewing Git changes or Local History.
After all items are completed, Junie proceeds with writing the tests and then prompts you to run them:
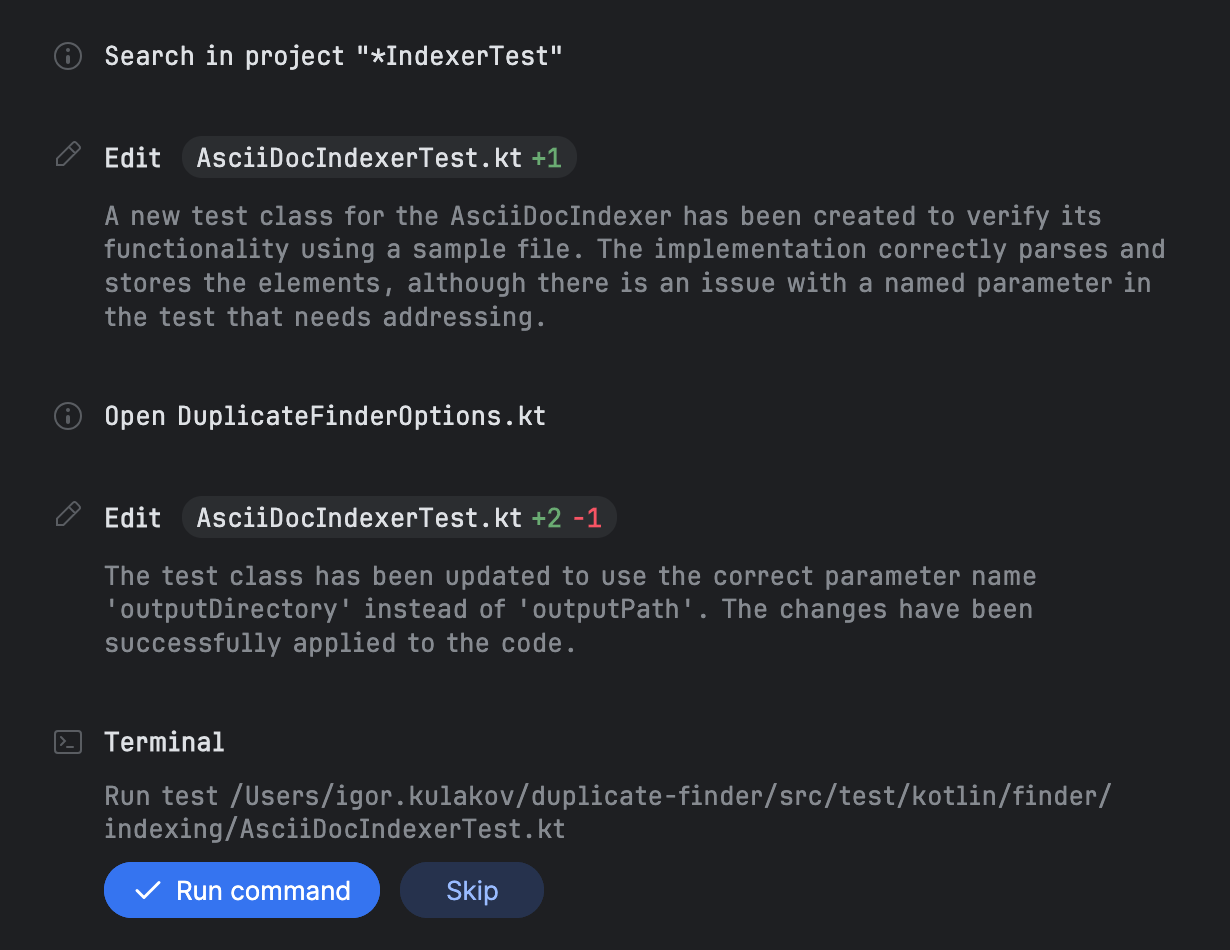
In this task, I gave Junie test data and explicitly requested tests. However, it appears that Junie generates them along with the test data by default. I experimented by running tasks without mentioning tests, and Junie created them anyway.
After running the tests, which were successful in this case, Junie provides the summary of what has been done:

Code quality
Upon reviewing the code and tests, I found them well-structured and neat. What I really liked is that Junie changed not just the code required for the project to compile, but also took the extra step to introduce other meaningful changes in the context of the task.
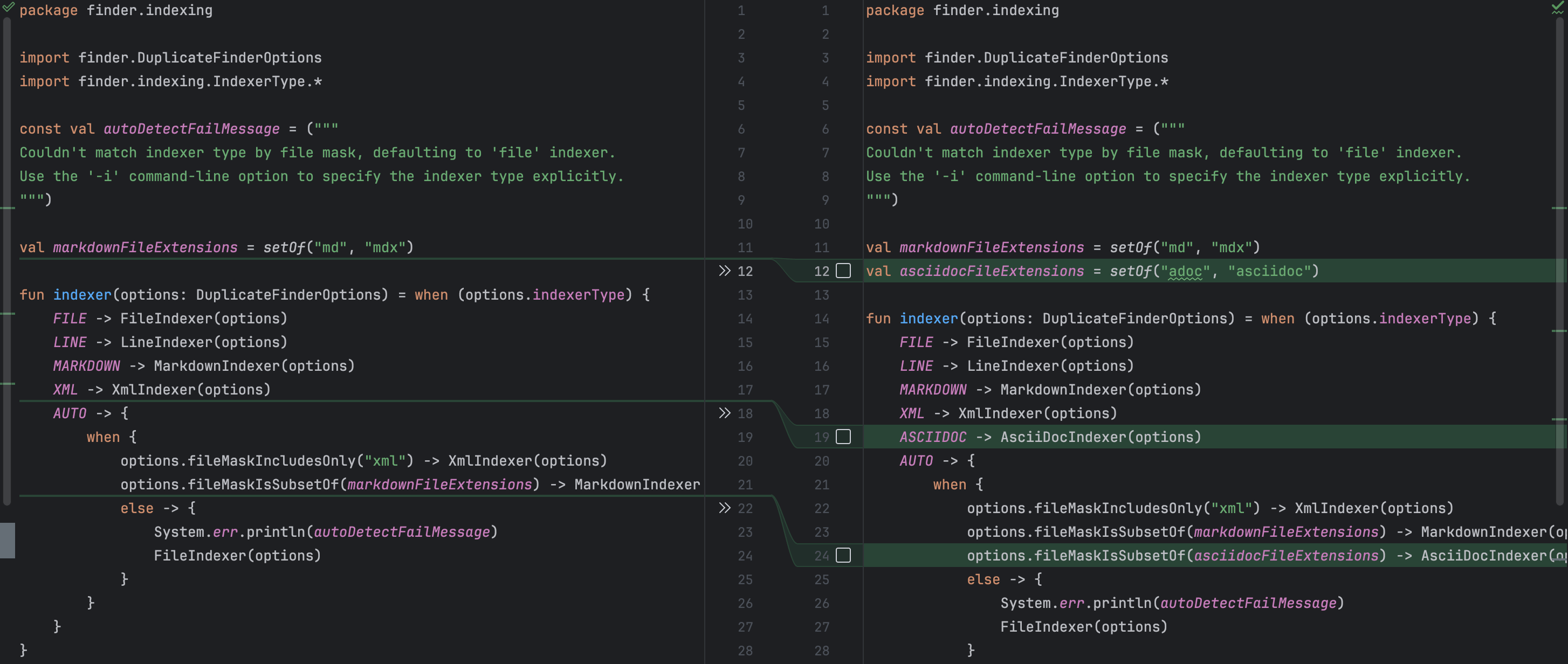
For instance, it slipped my mind to mention that the new indexer must be exposed in the command-line args. This oversight wouldn’t cause a compilation error, still it doesn’t make sense for the end user if they cannot access the feature. Junie recognized that and added the corresponding command-line option together with a description. It also correctly updated the factory method, so that the client code could get an instance of the new indexer. At the same time, there were no unnecessary changes, which is also great!
Everything’s good so far, but it appears that more work still needs to be done.
Correcting the implementation
One area where coding agents are not yet fully autonomous is identifying potential problems at runtime. Technically, the implementation is correct, and it passes all the tests. The results of the parsing are consistent, as seen in the Evaluate dialog.
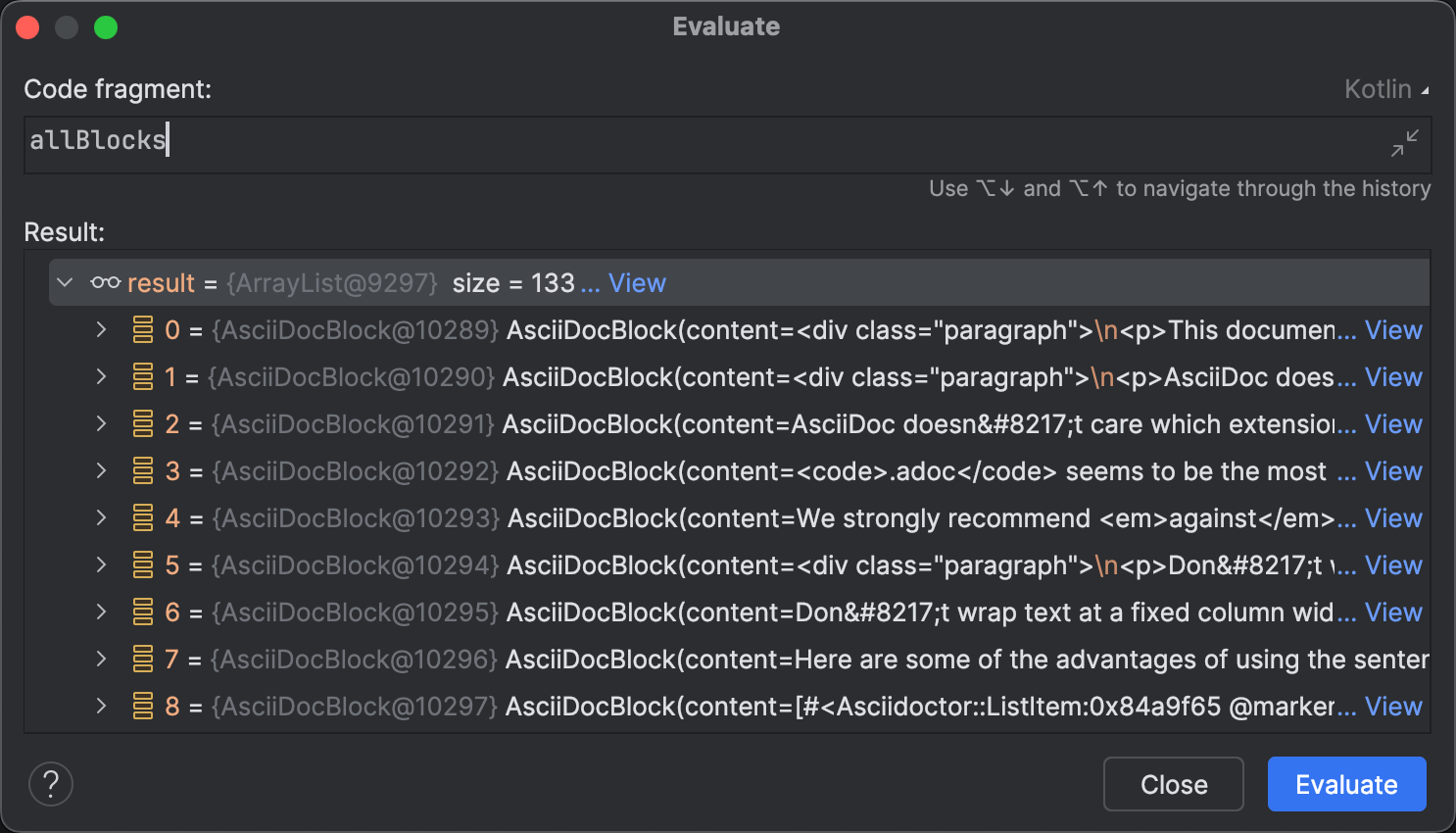
Evaluate Expression has a lot of interesting use-cases beyond exploring collections. For example, you can use it to prototype and apply fixes to a running program or arbitrarily modify the program behavior
Everything looks fine, except processing a single file is taking
a surprisingly long time. Looking into it, I also found out that parsing a batch of ~35 files always fails
with an OutOfMemoryError .
Upon analyzing the implementation, I didn’t find any obvious flaws such as inefficient loops or leaking resources.
Running the app with -XX:+HeapDumpOnOutOfMemoryError gave me a heap dump, which
revealed numerous JRuby types with huge retained sizes.
This hinted at the library as a possible source of the problem.
Of course, this guess might not be accurate, giving us a fascinating opportunity for profiling (or reading documentation). Anyway, changing a JRuby dependency for a simple Kotlin implementation would very likely speed things up. So, I decided to ask Junie to rewrite the implementation using a custom parser.
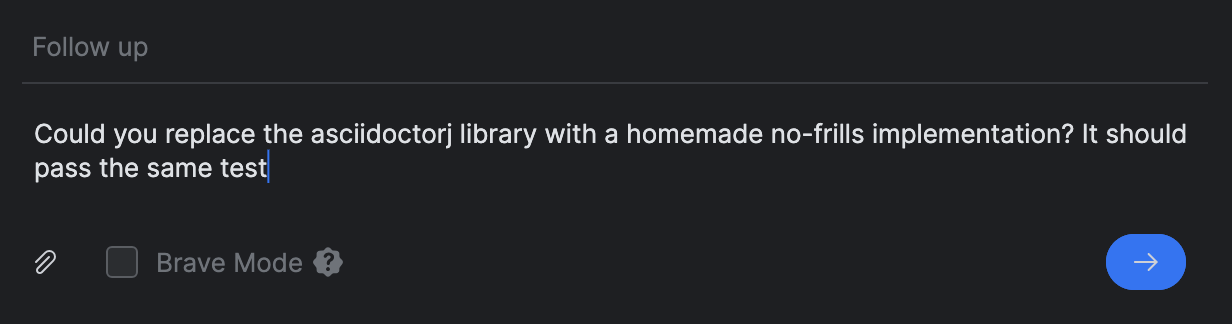
Rather than starting a new task, I used the Follow up prompt for that:
Results
Junie revised the implementation as requested. Although I’m not very familiar with the AsciiDoc format, the parsing seems to be largely correct at the first glance. There is some room for improvement in parsing of the preamble, and likely something else, but it does its job.
Running the updated Duplicate Finder on AsciiDoctor’s own help detected some duplicates! The analysis took 350 milliseconds on my laptop:
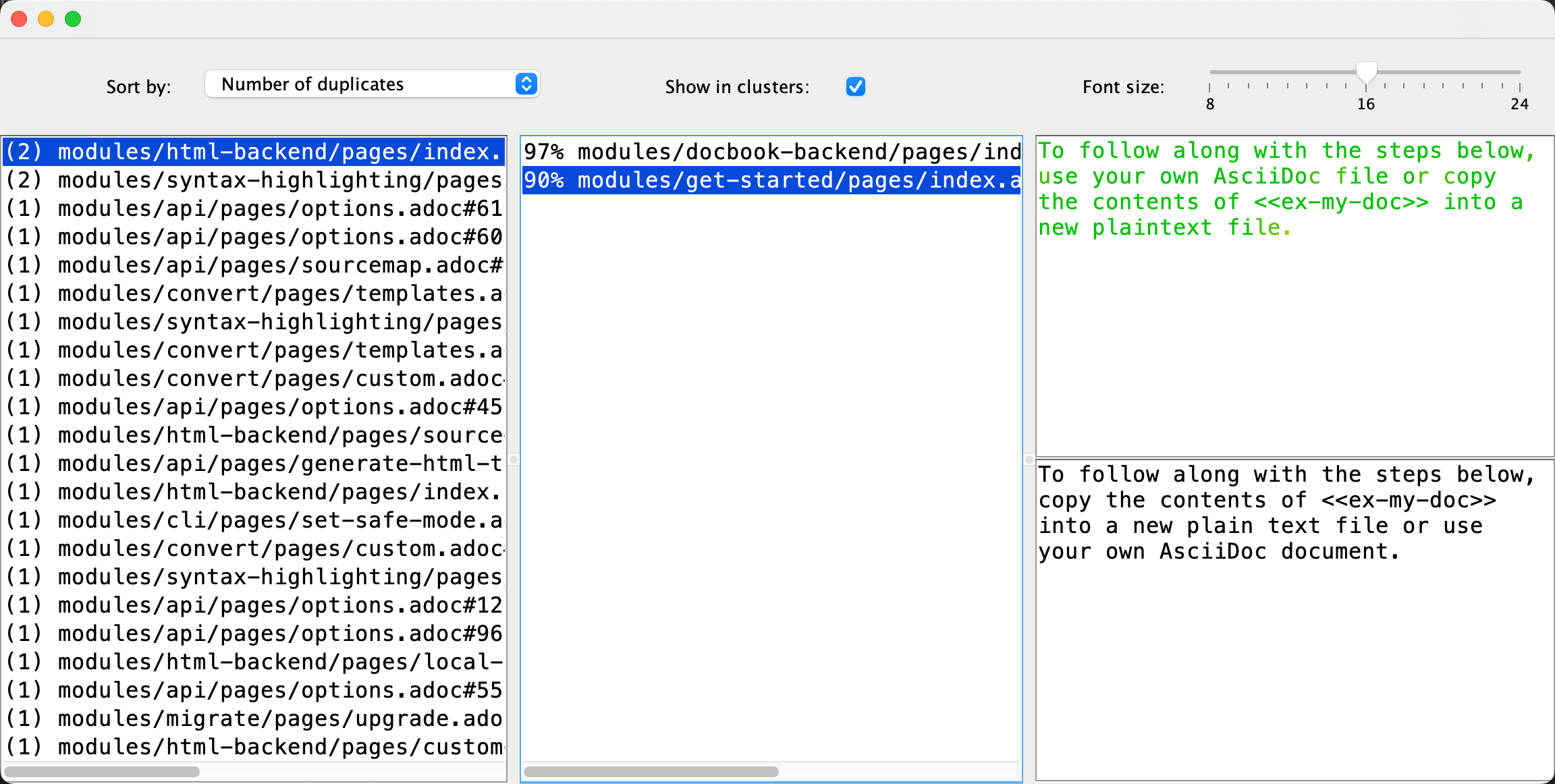
The project with the committed changes is on my GitHub. To try the new version of the app, you can find the instructions and the download link on the Duplicate Finder page. Overall, the implementation might not be perfect, and it definitely requires more thorough checking, but still I’m very impressed by what you can get done in 5 minutes nowadays.
If you’d like to try out Junie yourself, you can sign up for EAP here.