Duplicate Finder
На других языках: EnglishEspañolFrançaisDeutsch日本語한국어Português中文
Duplicate finder — это приложение с открытым исходным кодом для поиска похожих фрагментов текста в одном или нескольких файлах. Его можно использовать для обнаружения 100% дубликатов, а также контента, который схож, но не идентичен. Инструмент совместим с разными форматами, включая plaintext, Markdown и XML.
Он может помочь вам с:
- Обнаружением плагиата
- Управлением контентом
- SEO-оптимизацией
- Дедупликацей данных
Пример дублированного контента
Вот краткий пример того, что инструмент помогает обнаружить:
Как использовать
- Скачайте приложение или соберите его из исходников.
- Убедитесь, что на вашем компьютере установлена Java 16 или выше
- В терминале откройте папку с загруженным .jar файлом
-
Выполните
java -jar duplicate-finder.jarсо следующими параметрами:Параметр Описание Пример -r/--rootобязательноОтносительный или абсолютный путь к папке, в которой вы хотите искать дублирующийся контент -r=./my-project/-o/--outputОтносительный или абсолютный путь к папке, в которой вы хотите сохранить результаты анализа. Если папка не указана, находилка дубликатов будет использовать текущую директорию. -o=./my-project/duplicates/-f/--fileMaskСписок расширений файлов для анализа, разделённый запятыми. По умолчанию анализируются все файлы. -f=md,mdx-p/--parserЧто считать фрагментом текста. Доступны следующие варианты:
- md – элемент markdown
- line – одна строка текста
- xml – элемент XML
- adoc – элемент AsciiDoc
- file – содержимое всего файла
- auto – (по умолчанию) попытаться определить по расширениям файлов из опции fileMask
-i=md-l/--minLengthМинимальное количество символов во фрагменте текста для анализа. По умолчанию: 100 (фрагменты текста короче 100 символов не рассматриваются). -l=150-s/--minSimilarityМинимальная степень сходства между двумя фрагментами текста для того, чтобы они считались дубликатами. По умолчанию: 0.9 (90%). -s=0.85-d/--minDuplicatesМинимальное количество дубликатов фрагмента текста для того, чтобы эта группа дубликатов попала в отчёт. По умолчанию: 1 (одного дубликата достаточно). -d=5-ui/--uiИспользовать ли интерактивный интерфейс. Варианты: - none – без интерфейса, только запись в файлы
- swing – старый интерфейс
- compose – новый интерфейс, по умолчанию
-ui=none-v/--verboseПисать сообщения о ходе выполнения и ошибках в консоль. Используйте эту опцию, если анализ занимает слишком много времени и вы подозреваете наличие проблемы. По умолчанию: без сообщений в консоли -v-m/--memoryРежим низкого потребления памяти - снижает использование памяти за счет скорости анализа -m-g/--gram(для тёртых калачей) длина ngram – влияет на скорость, использование памяти и точность анализа. Эффект будет разным в зависимости от контента. -g=10-w/--keepWhitespaceСохранять ли последовательные пробелы в анализируемом тексте. По умолчанию пробелы нормализуются – несколько последовательных пробелов рассматриваются и отображаются как один. -w-i/--inlineВключать содержимое вложенных элементов в во внешний элемент. Например:
<parent>Some content including <child>nested content</child></parent>С этой опцией внешний элемент будет содержать 'Some content including nested content', в то время как по умолчанию он интерпретируется как 'Some content including'.
-i
Пример команды
Вот пример того, как может выглядеть команда:
java -jar duplicate-finder.jar -r=/Users/me.user/my-site -i=md -f=md,mdx -s=0.85 -d=5 -l=200
Приведенная выше команда будет:
-
-r=/Users/me.user/my-site– искать похожий контент в '/Users/me.user/my-site' и вложенных папках -
-i=md– предполагать, что контент написан на Markdown, и анализировать его по правилам Markdown -
-f=md,mdx– учитывать только файлы с расширениями '.md' и '.mdx' -
-s=0.85– сообщать только о совпадениях со степенью схожести 85% или выше -
-d=5– сообщать только о текстах, дублирующихся 5 или более раз -
-l=200– сообщать только о текстах длиной 200 символов или больше
Результаты
В зависимости от настроек программы и размера проекта, возможно, анализ займет какое-то время. После этого результаты откроются в окне просмотра дубликатов и сохранятся в папке, указанной через опцию '-o'. Если папка не была указана, находилка дубликатов запишет результаты в текущую директорию.
Вот что вы увидите в окне просмотра дубликатов:
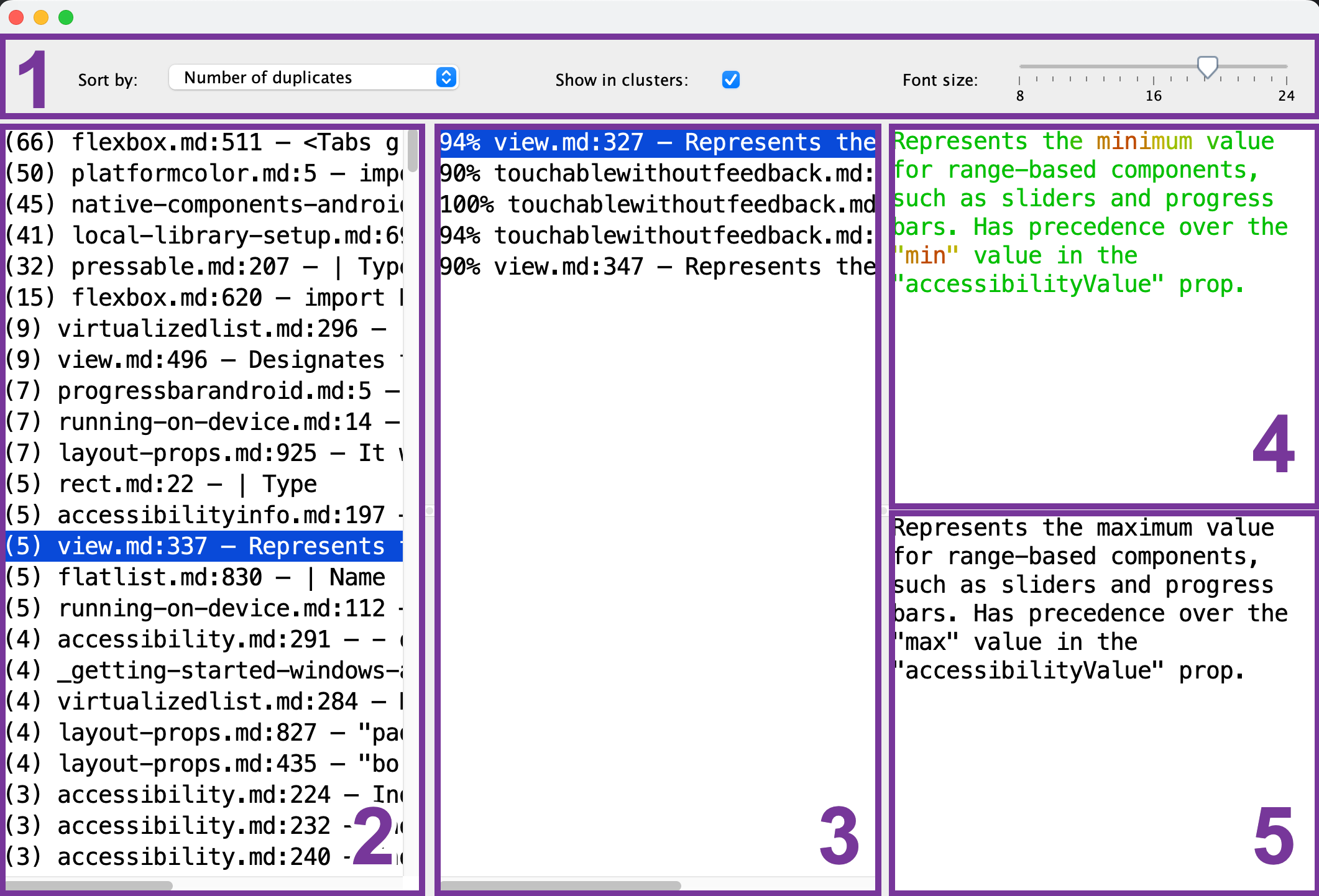
- Панель инструментов: здесь вы можете настроить размера шрифта, сортировку и как показываются группы дубликатов – по одному эталонному фрагменту (2) на каждую группу дубликатов, либо все сразу.
- Список эталонных фрагментов: здесь вы выбираете фрагмент, для которого будут показаны дубликаты, и который будет служить эталоном для сравнения.
- Список дубликатов: после того, как вы выбрали эталонный фрагмент (2), в этом списке будут показаны фрагменты, которые на него похожи. Чтобы посмотреть дубликат, выберите его из списка.
- Панель для просмотра эталонного фрагмента: после того, как вы выбрали эталонный фрагмент (2), его содержимое будет показано здесь. Схожие части показаны зелёным, а различающиеся - красным. Чем больше дубликатов (3) схожи в какой-то части, тем ближе к зеленому будет ее цвет.
- Панель для просмотра дубликата: после того, как вы выбрали дубликат (3), его содержимое будет показано здесь. Используйте эту панель для быстрого сравнения с выбранным эталонным фрагментом (4).
Узнать больше
Если вас заинтересовало то, как работает и разрабатывается находилка дубликатов, почитайте связанные блог посты:
- Duplicate Finder for Text
- Duplicate Finder for Text: Requirements
- Junie Codes (AsciiDoc Support)
- Duplicate Finder for Text: Algorithm
Вы можете связаться со мной, используя контакты внизу этой страницы. Буду рад услышать ваши мысли и идеи.
Лицензия
Код распространяется под лицензией MIT, что означает, что вы можете свободно использовать его для любых целей, а также форкать и дорабатывать его.