Buscador de Duplicados
Otros idiomas: English Français Deutsch 日本語 한국어 Português Русский 中文
El buscador de duplicados es una aplicación de código abierto para detectar texto similar en uno o más archivos. Puede usarse para encontrar duplicados al 100% así como contenido que es similar pero no idéntico. La herramienta es compatible con varios formatos, incluidos texto plano, Markdown y XML.
La herramienta de búsqueda de duplicados puede ayudarte con:
- Detección de plagios
- Gestión de contenidos
- Optimización SEO
- Desduplicación de datos
Ejemplo de contenido duplicado
Aquí tienes un ejemplo rápido para darte una idea de lo que detecta la herramienta:
Cómo usar
- Descarga la aplicación. Alternativamente, puedes construirlo tú mismo desde las fuentes.
- Asegúrate de que Java 16 o una versión posterior esté instalado en tu computadora
- En la terminal, abre la carpeta con el archivo .jar que descargaste
-
Ejecuta
java -jar duplicate-finder.jarcon los siguientes parámetros:Parámetro Significado Ejemplo -r/--rootrequeridoRuta relativa o absoluta a la carpeta donde desea buscar contenido duplicado -r=./my-project/-o/--outputRuta relativa o absoluta a la carpeta donde desea guardar los resultados del análisis. Si no se especifica ningún directorio, el buscador de duplicados utilizará el directorio de trabajo actual. -o=./my-project/duplicates/-f/--fileMaskLista separada por comas de extensiones de archivo para analizar. Por defecto, se analizan todos los archivos. -f=md,mdx-p/--parserQué considerar como un fragmento de texto. Las siguientes opciones están disponibles:
- md – un elemento de markdown
- line – una sola línea de texto
- xml – un elemento XML
- adoc – elemento AsciiDoc
- file – el contenido completo del archivo
- auto – intento de inferir de la máscara de archivo
-i=md-l/--minLengthLa longitud mínima (en caracteres) de un fragmento de texto para ser analizado. Por defecto: 100 (los fragmentos de texto más cortos que 100 caracteres se ignoran) -l=150-s/--minSimilarityEl grado mínimo de similitud entre dos fragmentos de texto para ser considerados duplicados. Predeterminado: 0.9 (90%) -s=0.85-d/--minDuplicatesEl número mínimo de duplicados para que se informe un grupo de duplicados. Predeterminado: 1 (un duplicado es suficiente) -d=5-ui/--uiSi usar la interfaz de usuario interactiva o no. Opciones: - none – sin interfaz, solo escribir en archivos
- swing – interfaz antigua
- compose – nueva interfaz, predeterminada
-ui=none-v/--verboseSi debe registrar el progreso y los errores en la consola. Use esta opción si el análisis está tomando demasiado tiempo y sospecha un problema. Por defecto: sin registro -v-m/--memoryModo de baja memoria: minimiza el uso de memoria del buscador de duplicados a costa de la velocidad de análisis. -m-g/--gramlongitud de ngrama (avanzada) – afecta la velocidad, el uso de memoria, y la precisión del análisis. La diferencia depende de las especificidades del contenido. -g=10-w/--keepWhitespaceMantén las ocurrencias de múltiples espacios consecutivos en el contenido analizado. Por defecto, los espacios en blanco se normalizan, lo que significa que varios espacios consecutivos se tratan y se muestran como uno solo. -w-i/--inlineIncluir el contenido de los elementos anidados en su elemento contenedor. Por ejemplo:
<parent>Some content including <child>nested content</child></parent>Con esta opción activada, el elemento externo se analizará como 'Some content including nested content', mientras que por defecto se analiza como 'Some content including'.
-i
Ejemplo de comando
Aquí tienes un ejemplo de cómo podría ser tu comando:
java -jar duplicate-finder.jar -r=/Users/me.user/my-site -i=md -f=md,mdx -s=0.85 -d=5 -l=200
El comando anterior hará lo siguiente:
-
-r=/Users/me.user/my-site– buscar contenido similar en '/Users/me.user/my-site' y sus subdirectorios -
-i=md– asumir que el contenido está escrito en Markdown y analizarlo según las reglas de Markdown -
-f=md,mdx– considerar solo archivos con las extensiones '.md' y '.mdx' -
-s=0.85– reportar solo coincidencias con una similitud del 85% o más -
-d=5– reportar solo textos que se duplican 5 o más veces -
-l=200– reportar solo textos que tienen 200 caracteres o más
Resultados
Según la configuración y el tamaño del proyecto, es posible que tengas que esperar un poco a que se complete el análisis. Después de eso, los resultados se abrirán en el visor de duplicados y se guardarán en la carpeta definida con la opción de línea de comandos '-o'. Si no se especifica ninguna opción, la salida se escribirá en el directorio de trabajo.
Estos son los pasos que verá en el visor de duplicados:
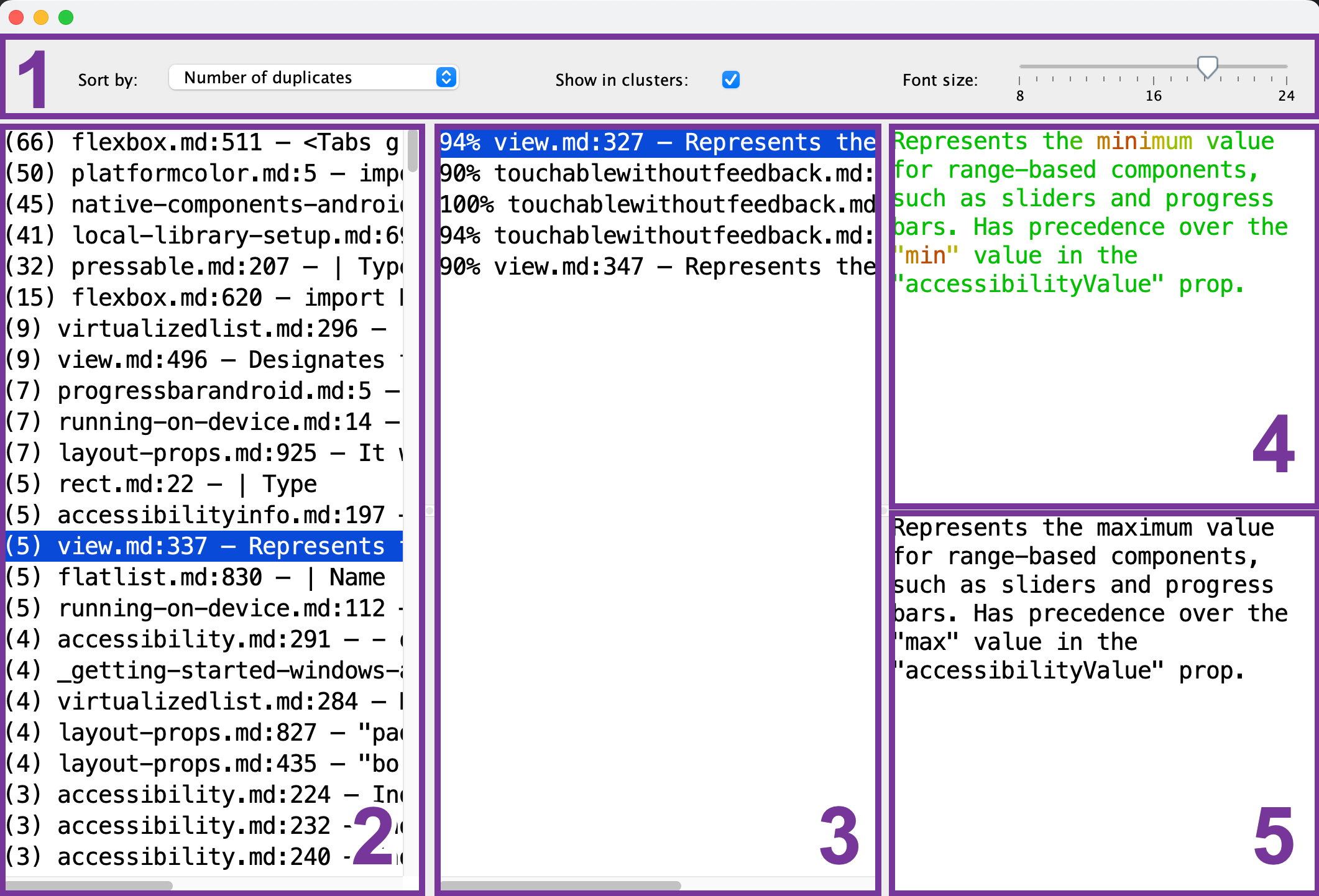
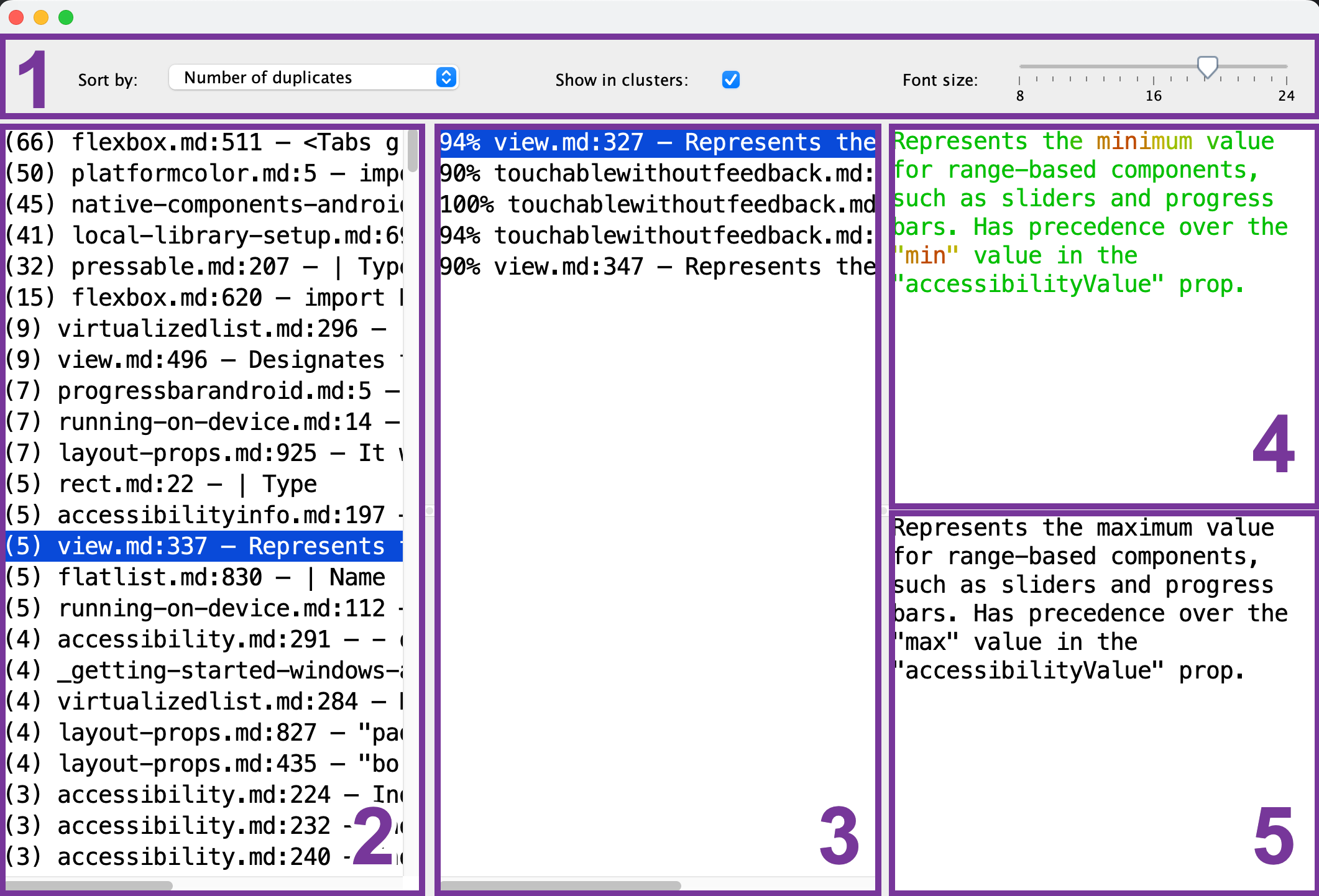
- Barra de herramientas: configure el tamaño de fuente, el orden de clasificación y si desea ver solo un fragmento de referencia (2) para cada uno de los grupos de duplicados.
- Lista de fragmentos de referencia: seleccione el fragmento que servirá como referencia para la comparación.
- Lista de fragmentos duplicados: después de seleccionar el fragmento de referencia (2), esta lista mostrará los fragmentos que son similares a él. Para previsualizar un duplicado, selecciónelo de la lista.
- Vista previa del fragmento de referencia: una vez que haya seleccionado el fragmento de referencia (2), puede previsualizar su contenido aquí. Las partes comunes se muestran en verde, mientras que las diferentes se muestran en rojo. Cuantos más fragmentos duplicados (3) tengan esta parte en común, más verde se verá.
- Vista previa del fragmento duplicado: después de seleccionar el fragmento duplicado, su vista previa aparecerá aquí. Puede usarlo para una comparación rápida con el fragmento de referencia seleccionado (4).
Más información y contacto
Si está interesado en el desarrollo de esta herramienta, consulte la serie de blogs relacionada:
- Buscador de Duplicados para Textos
- Buscador de Duplicados de Texto: Requisitos
- Junie Codifica (Soporte AsciiDoc)
- Buscador de Duplicados de Texto: Algoritmo
Para comentarios, puede comunicarse utilizando los contactos en el pie de página de esta página. Estaré encantado de escuchar sus opiniones y solicitudes de funciones.
Licencia
El código está licenciado bajo la licencia MIT, lo que significa que eres libre de usarlo para cualquier propósito, así como de bifurcarlo y modificarlo.