重複ファインダー
他の言語: EnglishEspañolFrançaisDeutsch한국어PortuguêsРусский中文
重複検出ツールは、1つ以上のファイル内の類似したテキストを検出するためのオープンソースアプリケーションです。 完全に同一の重複や、似ているが同じではないコンテンツを見つけることができます。 このツールはプレーンテキスト、Markdown、XMLなど複数の形式に対応しています。
重複検出ツールは以下の点でお役に立てます:
- 盗作の検出
- コンテンツ管理
- SEO最適化
- データの重複排除
重複コンテンツ例
こちらはツールが検出する内容を把握するための簡単な例です:
使い方
- アプリをダウンロード または、以下のソースから自分でビルドすることができます ソース.
- コンピューターに Java 16 以降がインストールされていることを確認してください
- ターミナルで、ダウンロードした .jar ファイルがあるフォルダーを開きます
-
次のコマンドを実行します:
java -jar duplicate-finder.jar以下のパラメーターを指定します:パラメータ 意味 例 -r/--root必須重複コンテンツを検索するフォルダーの相対パスまたは絶対パス -r=./my-project/-o/--output解析結果を保存したいフォルダへの相対パスまたは絶対パスです。 ディレクトリが指定されていない場合、重複検出ツールは現在の作業ディレクトリを使用します。 -o=./my-project/duplicates/-f/--fileMask解析するファイル拡張子のカンマ区切りリストです。デフォルトでは、すべてのファイルが解析されます。 -f=md,mdx-p/--parserテキストチャンクとして考慮する内容。以下のオプションが利用可能です:
- md – マークダウン要素
- line – テキストの1行
- xml – XML要素
- adoc – AsciiDoc 要素
- file – ファイル全体の内容
- auto – ファイルマスクから推測を試みる
-i=md-l/--minLengthテキストが分析されるための最小長さ(文字数)。 デフォルト値: 100 (100文字未満のテキスト片は無視されます) -l=150-s/--minSimilarity2つのテキストチャンクが重複と見なされるための最小類似度。 デフォルト: 0.9 (90%) -s=0.85-d/--minDuplicates重複グループが報告されるための最小重複数です。デフォルト値:1(1つの重複で十分) -d=5-ui/--uiインタラクティブ UI を使用するかどうか。オプション: - none – UI なし、ファイルへの書き込みのみ
- swing – 古い UI
- compose – 新しい UI、デフォルト
-ui=none-v/--verbose進行状況とエラーをコンソールに記録するかどうか。 分析に時間がかかりすぎて問題があると思われる場合は、このオプションを使用してください。 デフォルト:記録なし -v-m/--memory低メモリモード - 分析速度を犠牲にして、重複ファインダーのメモリ使用量を最小限に抑えます。 -m-g/--gram(上級) ngram の長さ – 速度、メモリ使用量、分析の正確性に影響します。違いはコンテンツの詳細に依存します。 -g=10-w/--keepWhitespace解析された内容で連続する複数の空白を保持します。デフォルトでは、空白は正規化され、連続する複数の空白文字は1つとして扱われ、表示されます。 -w-i/--inlineネストされた要素の内容を囲む要素に含めます。例えば:
<parent>Some content including <child>nested content</child></parent>このオプションを有効にすると、外側の要素は 'Some content including nested content' として解析され、デフォルトでは 'Some content including' として解析されます。
-i
コマンド例
コマンドの例は以下のようになります:
java -jar duplicate-finder.jar -r=/Users/me.user/my-site -i=md -f=md,mdx -s=0.85 -d=5 -l=200
上記のコマンドは以下を実行します:
-
-r=/Users/me.user/my-site– '/Users/me.user/my-site' およびそのサブディレクトリ内の類似コンテンツを検索 -
-i=md– Markdownで書かれていることを想定し、Markdownの規則に従って解析 -
-f=md,mdx– '.md' と '.mdx' 拡張子を持つファイルのみを考慮 -
-s=0.85– 85% 以上の類似性がある一致のみを報告 -
-d=5– 5回以上重複するテキストのみを報告 -
-l=200– 200文字以上のテキストのみを報告
結果
設定やプロジェクトの規模によっては、分析が完了するまで少し待つ必要があります。 その後、結果は重複ビューアで開き、コマンドラインオプション「-o」で定義されたフォルダーに保存されます。 オプションが指定されていない場合、出力は作業ディレクトリに書き込まれます。
以下は、重複ビューアに出てくるステップです:
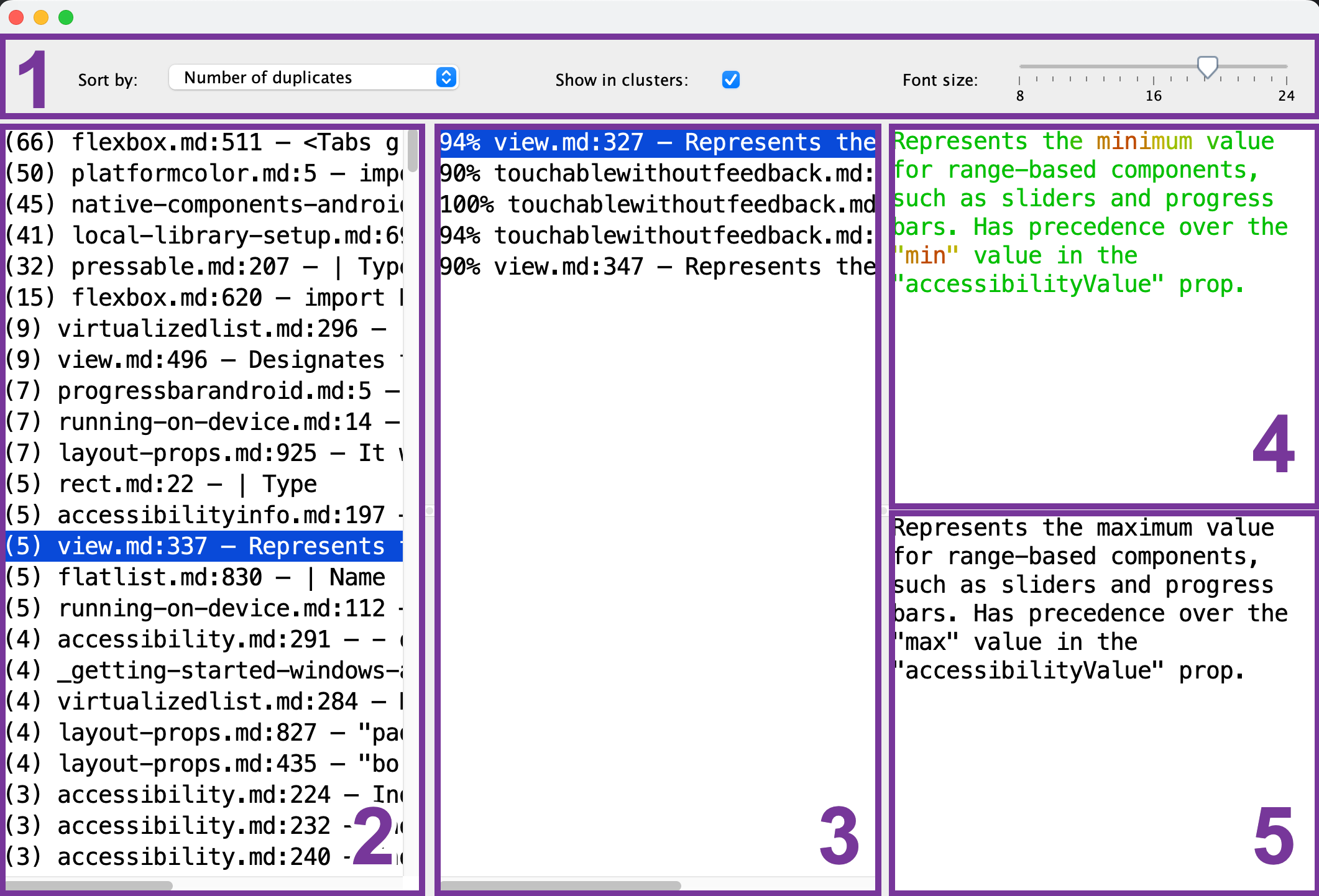
- ツールバー:フォントサイズ、並べ替え順序、および各重複グループに対して単一の参照チャンク(2)を 見るかどうかを設定します。
- 参照チャンクリスト:比較の参照として使用するチャンクを選択します。
- 重複チャンクリスト: 参照チャンク(2)を選択した後、このリストにはそれに似たチャンクが表示されます。 重複をプレビューするには、リストから選択してください。
- 参照チャンクプレビュー: 参照チャンク(2)を選択した後、その内容をここでプレビューできます。 共通部分は緑色で表示され、一致しない部分は赤色で表示されます。より多くの重複チャンク(3)が共通部分を持つ場合、より緑色に表示されます。
- 重複チャンクプレビュー: 重複チャンク(3)を選択すると、そのプレビューがここに表示されます。 選択した参照チャンク(4)とのクイック比較に使用できます。
詳細情報とお問い合わせ
このツールの開発に興味がある場合は、関連するブログ記事シリーズをご覧ください:
フィードバックがある場合は、このページの下部に記載された連絡先をご利用ください。ご意見や機能のリクエストをお聞きできると嬉しいです。
ライセンス
コードはMITライセンスの下にライセンスされています。これにより、任意の目的で自由に使用したり、フォークしたり、変更したりすることができます。